




在学习原子变量之初,学过很多它的操作,但是很多都是在内置类型(int、long等)上进行的学习和实验。这次由于工作需要,要使用 atomic 来包装自定义类型,因此打算好好探究一番,把它彻底搞懂。
当要使用 atomic 包装自定义类型的时候首先肯定会产生疑问——C++是否支持这样使用?
于是乎,去 cppreference 上搜了一下(C++17版本、其他的版本也支持),发现允许使用 atomic 包装平凡拷贝(TriviallyCopyable)的自定义类型。这时候又会有一个疑惑什么是平凡拷贝?如何确定自己定义的类型是不是平凡拷贝的?
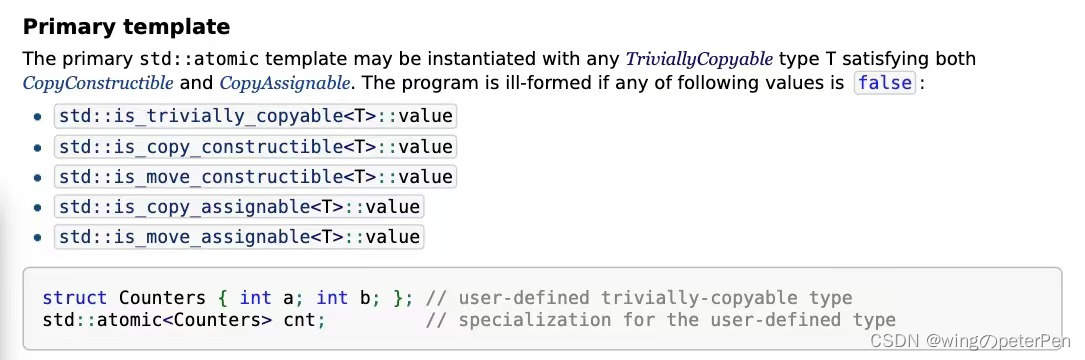
从图中可以看出如果你不确定你自定义的结构是否是 TriviallyCopyable 的,你可以拿上面五个值打印一下,当全部为 true 时,那么恭喜你,你定义的结构体是 TriviallyCopyable 的,可以使用 atomic 来包装它。至于具体的平凡拷贝的定义可以去 cppreference 上查一下,此处不再展开(下文会简单提到如何看一个类型是不是 TriviallyCopyable 的)。
场景分析
目前程序中存在两种线程即: mertrics_thread (下文称为 M 线程,其作用是将全局变量中的值进行上报并在上报之后进行复位,数量为 1) 、worker_thread(下文称为 W 线程,其作用是采集某些工作函数运行耗时和次数并将其更新到全局变量中,数量为 3),还存在一个全局变量(用于记录采集到的值)。首先定义全局变量类型 Counters
struct Counters{
uint64_t a;
int b;
};
如果我们不对其加以修饰就直接实例化它,并使用起来,那么必然会造成数据竞争。因此我们需要用 atomic 包装它,即定义一个全局变量 counter_atomic
std::atomic<Counters> counter_atomic;
前文提到 atomic 包装的变量必须是 TriviallyCopyable 的,我们可以拿上面的五个 value 来看一下我们定义的结构是否满足
int main() {
std::cout << std::is_trivially_copyable<Counters>::value << std::endl;
std::cout << std::is_copy_constructible<Counters>::value << std::endl;
std::cout << std::is_move_constructible<Counters>::value << std::endl;
std::cout << std::is_copy_assignable<Counters>::value << std::endl;
std::cout << std::is_move_assignable<Counters>::value << std::endl;
return 0;
}
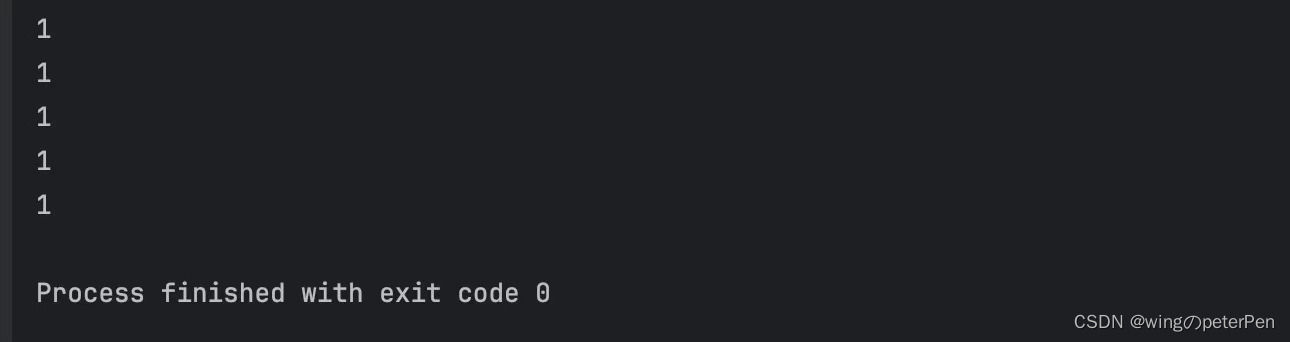
从输出可以发现,其是 TriviallyCopyable 的,那么如何保证我们定义的结构是 TriviallyCopyable 的呢?在我看来只要其内部的值全是内置类型,然后不要去自己捣鼓构造函数、拷贝和移动相关的函数就行了。(这里就是前面提到的下文啦!!!)
实现
前置知识
实现必然涉及到原子变量的 CAS 操作,exchange()、 compare_exchange_strong()、compare_exchange_weak() 这几个函数。
首先来看 exchange, 其函数签名是
_Tp exchange(_Tp __d, memory_order __m = memory_order_seq_cst)
其使用场景是将原子变量包装的值更新为 __d, 并返回原子变量之前保存的值。这个函数正好满足 M 线程中需要进行的 “读取——复位” 的操作。
然后来看两个 “比较——交换” 函数,它们的函数签名是
bool compare_exchange_strong(_Tp& __e, _Tp __d, memory_order __m = memory_order_seq_cst)
bool compare_exchange_weak(_Tp& __e, _Tp __d, memory_order __m = memory_order_seq_cst)
其使用场景是:有一个期望值 __e,将其与原子变量中存储的值进行比较,当相等时,就把 __d 存储到原子变量中,并返回 true;当不相等时,就把原子变量中存储的值赋给 __e,并返回 false。
_strong、_weak 的区别在于后者可能在某些平台上存在 Spurious Failure 问题,即 _weak 版本可能会在 __e 的值和原子变量中存储的值相等时,返回 false(仅在某些平台上会这样,X86 上面不会这样子)。_strong 在遇到 Spurious Failure 问题时会进行重试,即其在内部存在一个循环来弥补 _weak 的不足。本质原因还是在某些平台上面使用一系列指令来实现 CAS 原语,而在 x86 这样的机器上面,直接使用一条指令来实现 CAS 原语。
#include <iostream>
#include <atomic>
#include <chrono>
#include <thread>
struct Counters{
uint64_t a = 0;
int b = 0;
};
std::atomic<Counters> counters_atomic;
void metrics_report(){
while(true) {
// 取出 counters_atomic 中的值,并进行复位
Counters new_counters;
Counters old_counters = counters_atomic.exchange(new_counters);
// 模拟指标上报,将采集到的 old_counters 上报上去。
// 每间隔 3s 上报一次采集到的信息
std::cout << " a: " << old_counters.a << " b: " << old_counters.b << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(3));
}
}
void worker(){
while(true){
uint64_t start_time = 1000000;
// 模拟工作线程的耗时操作
std::this_thread::sleep_for(std::chrono::milliseconds (500));
uint64_t end_time = 3000000;
uint64_t diff_time = end_time - start_time;
Counters old_val = counters_atomic.load();
Counters new_val;
do{
new_val = old_val;
new_val.a += diff_time;
new_val.b += 2;
}while(!counters_atomic.compare_exchange_strong(old_val, new_val));
}
}
int main() {
std::thread worker_a(worker);
std::thread worker_b(worker);
std::thread worker_c(worker);
std::thread metrics_thread(metrics_report);
worker_a.join();
worker_b.join();
worker_c.join();
metrics_thread.join();
return 0;
}

















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









