



 本文受开发音频信号替代特征提取方法启发,分析利用深层网络结构从频域音乐音频数据中提取特征。开发基于图像的ImageNet深度网络模型,从音乐声谱图学习特征数据。还探讨用音源分离工具预处理音效,将提取特征用于训练分类器对音乐数据分类,对比结果显示输入源分离的更深层次网络效果最佳。
本文受开发音频信号替代特征提取方法启发,分析利用深层网络结构从频域音乐音频数据中提取特征。开发基于图像的ImageNet深度网络模型,从音乐声谱图学习特征数据。还探讨用音源分离工具预处理音效,将提取特征用于训练分类器对音乐数据分类,对比结果显示输入源分离的更深层次网络效果最佳。
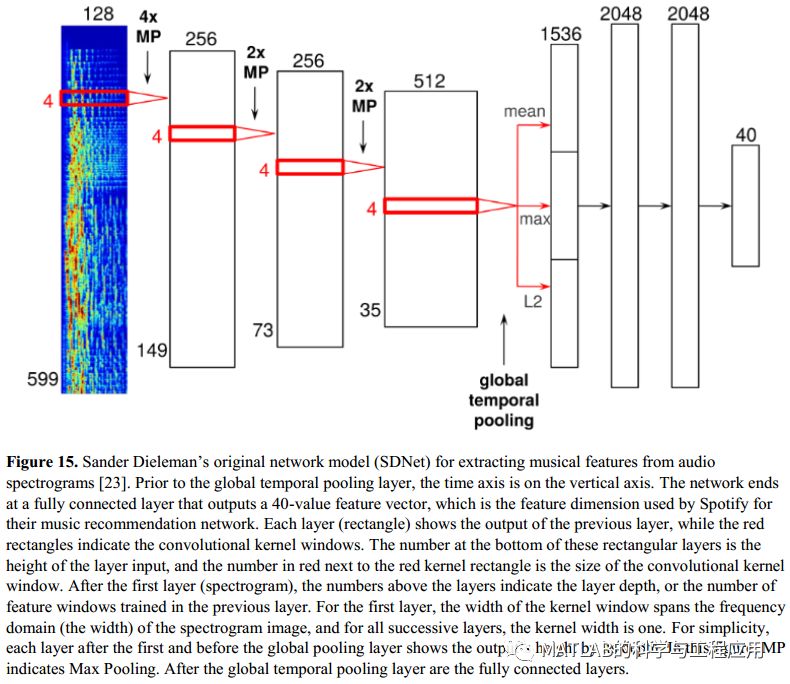
本文为美国罗彻斯特理工学院(作者:Madeleine Daigneau)的硕士论文,共67页。
音乐是一种反映和表达情感的手段。个人对音乐的偏好因人而异,会受情境和环境因素的影响。本研究在尝试开发音频信号替代特征提取方法的启发下,分析了利用深层网络结构从频域表现出来的音乐音频数据中提取特征。基于图像的网络模型被设计成对图像特征具有鲁棒性和精确性的学习者。因此,本研究开发了基于图像的ImageNet深度网络模型,实现从音乐声谱图中学习特征数据。
本研究亦探讨在训练网络模型前,利用音源分离工具对音效进行预处理。源分离的使用允许网络模型对突出音轨特征的学习,并使用这些功能改进分类结果。从数据中提取的特征用于突出音轨的特征,然后以此训练分类器,以风格流派和自动标记分类对音乐数据进行识别。将每个模型的结果与最先进的音乐曲目分类和标签预测方法进行了对比,结果表明,采用输入源分离的更深层次的网络可以获得最佳效果。
Music is a means of reflecting and expressing emotion. Personal preferences in music vary between individuals, influenced by situational and environmental factors. Inspired by attempts to develop alternative feature extraction methods for audio signals, this research analyzes the use of deep network structures for extracting features from musical audio data represented in the frequency domain. Image-based network models are designed to be robust and accurate learners of image features. As such, this research develops image-based ImageNet deep network models to learn feature data from music audio spectrograms. This research also explores the use of an audio source separation tool for preprocessing the musical audio before training the network models. The use of source separation allows the network model to learn features that highlight individual contributions to the audio track, and use those features to improve classification results. The features extracted from the data are used to highlight characteristics of the audio tracks, which are then used to train classifiers that categorize the musical data for genre and autotag classifications. The results obtained from each model are contrasted with state-of-the-art methods of classification and tag prediction for musical tracks. Deeper networks with input source separation are shown to yield the best results.
1 引言
1.1 音乐信息检索
1.2 深度网络
1.3 音频/音乐信息
2 项目背景
2.1 音乐与深度学习
2.2 数据集
3 研究方法
3.1 研究框架
3.2 音频预处理
3.3 深度学习模型
3 研究结果
3.1 音乐流派分类
3.2 标签预测
4 未来研究工作展望
5 结论
完整资料领取请加QQ群免费下载:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









