



 本文探讨了如何使用交叉熵函数作为损失函数,通过反向传播算法调整神经网络权重,以实现对异或逻辑运算的有效学习。具体展示了通过BackpropCE函数训练含有四个隐藏节点、三个输入节点和一个输出节点的神经网络的过程。
本文探讨了如何使用交叉熵函数作为损失函数,通过反向传播算法调整神经网络权重,以实现对异或逻辑运算的有效学习。具体展示了通过BackpropCE函数训练含有四个隐藏节点、三个输入节点和一个输出节点的神经网络的过程。
示例:交叉熵函数
Example: Cross Entropy Function
本节将回顾反向传播算法示例。
This section revisits the back-propagationexample.
但本节是从交叉熵函数推导出的学习规则。
But this time, the learning rule derivedfrom the cross entropy function is used.
考虑由四个隐藏节点、三个输入节点和一个输出节点组成的单隐藏层神经网络的训练。
Consider the training of the neural networkthat consists of a hidden layer with four nodes, three input nodes, and asingle output node.
隐藏节点和输出节点的激活函数采用sigmoid函数。
The sigmoid function is employed for theactivation function of the hidden nodes and output node.
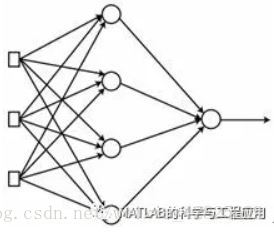
图3-13 具有四个隐藏节点、三个输入节点和一个输出节点的单隐藏层神经网络Neuralnetwork with a hidden layer with four nodes, three input nodes, and a singleoutput node
训练数据包含如下表中所示的四个元素,与前面章节中使用的数据相同。
The training data contains the same fourelements as shown in the following table.

当我们忽略每个输入数据中的第三个数时,该训练数据集呈现异或逻辑运算。
When we ignore the third numbers of theinput data, this training dataset presents a XOR logic operation.
每个输入数据的最右边的数字是正确的输出。
The bolded rightmost number of each elementis the correct output.
交叉熵函数(Cross Entropy Function)
BackpropCE函数利用交叉熵训练XOR数据。
The BackpropCE function trains the XOR datausing the cross entropy function.
该函数采用神经网络的权值训练数据,并返回调整后的权值。
It takes the neural network’s weights andtraining data and returns the adjusted weights.
[W1W2] = BackpropCE(W1, W2, X, D)
其中W1和W2分别为输入-隐藏层和隐藏-输出层的权值矩阵。
where W1 and W2 are the weight matrices forthe input-hidden layers and hidden-output layers, respectively.
此外,X和D分别是数据的输入和正确输出矩阵。
In addition, X and D are the input andcorrect output matrices of the data, respectively.
以下程序清单为BackpropCE.m文件的详细内容,该文件实现了BackpropCE函数的功能。
The following listing shows theBackpropCE.m file, which implements the BackpropCE function.
function [W1, W2] = BackpropCE(W1, W2, X,D)
alpha = 0.9;
N = 4;
for k = 1:N
x = X(k, ?’; % x = a column vector
d = D(k);
v1 = W1*x;
y1 = Sigmoid(v1);
v = W2*y1;
y = Sigmoid(v);
e = d - y;
delta = e;
e1 = W2’*delta;
delta1 = y1.*(1-y1).*e1;
dW1 = alphadelta1x’;
W1 = W1 + dW1;
dW2 = alphadeltay1’;
W2 = W2 + dW2;
end
end
该代码根据训练数据,使用增量规则计算权重更新(dW和dW2),并且使用这些值调整神经网络的权重。
This code pulls out the training data,calculates the weight updates (dW1 and dW2) using the delta rule, and adjuststhe neural network’s weights using these values.
到目前为止,以上过程与前面的示例几乎相同。
So far, the process is almost identical tothat of the previous example.
——本文译自Phil Kim所著的《Matlab Deep Learning》
更多精彩文章请关注微信号:

















 2964
2964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









