



树形图
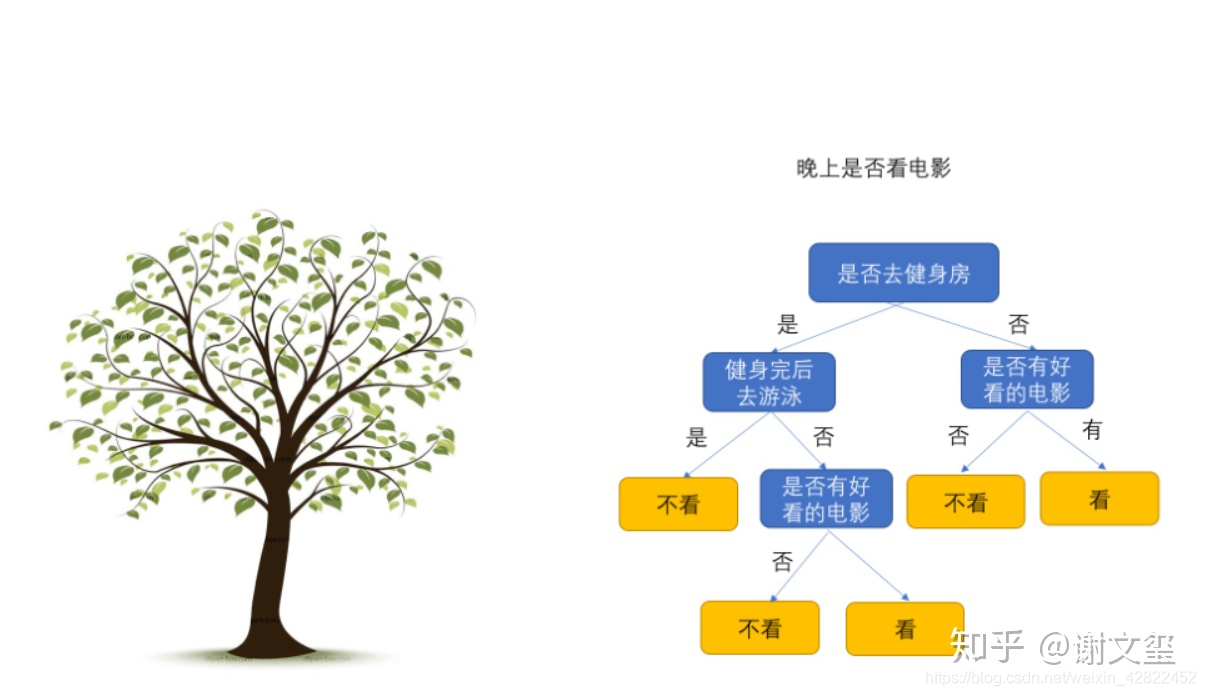
决策树三部分:
1.内部节点
2.叶节点
3.边
内部节点
构建决策树就是一个递归的选择内部节点,计算划分条件的边,最后到达叶子节点,不断降低数据的不确定性的过程。信息熵(information entropy)是度量样本集合纯度(purity)最常用的一种指标。
特征选择
ID3应用信息增益准则选择特征,递归地构建决策树.
C4.5应用信息增益比来选择特征。
CART分类树采用基尼指数(Gini index)选择特征。
CART回归树遍历n个特征及其m个取值最小化损失函数。注:分切点选择:先排序,二分
信息增益
信息增益 = entroy(前) - entroy(后)
信息增益比
信息增益比 = 惩罚参数 * 信息增益
基尼指数
基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率
叶节点
剪枝
**过拟合:**在训练数据上能够获得比其他假设更好的拟合,但是在训练数据外的数据集上却不能很好的拟合数据。
过拟合原因:
原因1:样本问题
(1)样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系;
(2)样本抽取错误,包括(但不限于)样本数量太少,抽样方法错误,抽样时没有足够正确考虑业务场景或业务特点,等等导致抽出的样本数据不能有效足够代表业务逻辑或业务场景;
(3)建模时使用了样本中太多无关的输入变量。
原因2:构建决策树的方法问题
在决策树模型搭建中,对于决策树的生长没有合理的限制和修剪的话,决策树的自由生长有可能每片叶子里只包含单纯的事件数据或非事件数据,可以想象,这种决策树当然可以完美匹配(拟合)训练数据,但是一旦应用到新的业务真实数据时,效果是一塌糊涂。
针对原因1的解决方法:
合理、有效地抽样,用相对能够反映业务逻辑的训练集去产生决策树;
针对原因2的解决方法(主要):
**剪枝:**提前停止树的增长或者对已经生成的树按照一定的规则进行后剪枝。剪枝的依据是:极小化决策树的整体损失函数或者代价函数。
**(1)先剪枝(prepruning):**在决策树生成过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能提升,则停止划分并将当前节点标记为叶节点
**(2)后剪枝(postpruning):**先从训练集生成一颗完整的决策树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换为叶节点能带来决策树泛化性能提升,则将该子树替换为叶节点
问题1.信息增益比相对信息增益有什么好处?
信息增益偏向选择分支多的属性,容易导致过拟合。信息增益比率通过引入一个被称作分裂信息(Split information)的项来惩罚取值较多的Feature。
ID3,C4.5&CART
信息增益&信息增益比计算实例


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









