




经常看到类似下面的代码
for i,(images,target) in enumerate(train_loader):
# 1. input output
images = images.cuda(non_blocking=True)
target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True)
outputs = model(images)
loss = criterion(outputs,target)
# 2. backward
optimizer.zero_grad() # reset gradient
loss.backward()
optimizer.step() 这三条经常一起出现:梯度清零,反向传播求梯度,更新参数
# 2. backward
optimizer.zero_grad() # reset gradient
loss.backward()
optimizer.step() 很多资料说梯度不清零会累加,我一开始想的是:求出新梯度不就直接赋值给变量(覆盖原来变量的值吗?)怎么会累加呢?
然后我做了个实验验证了一下:
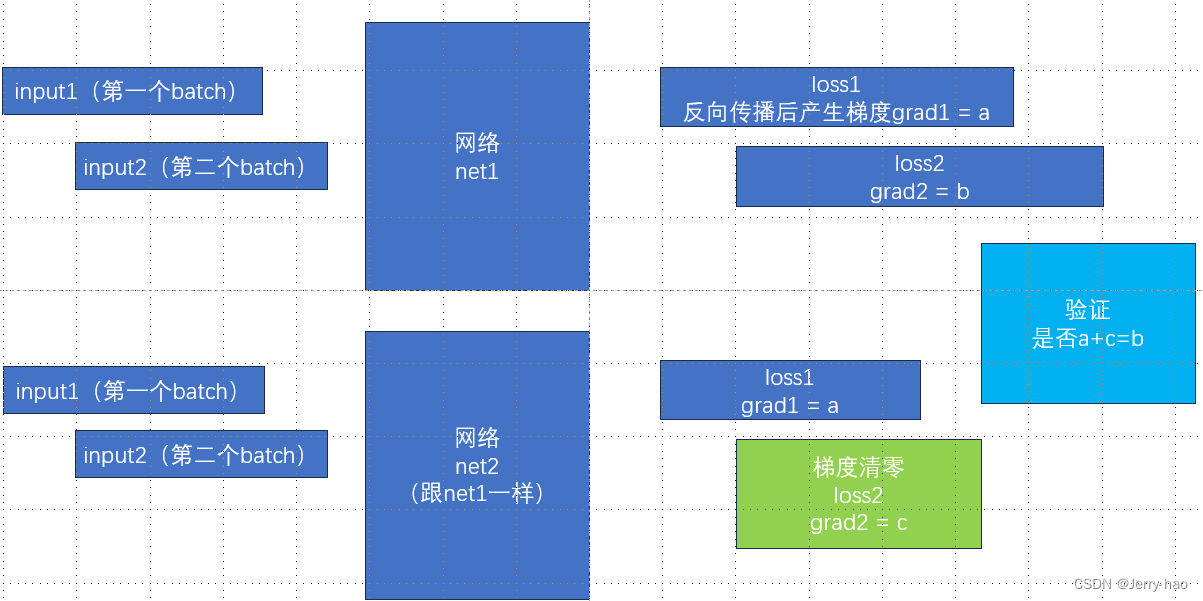
代码如下:
import torch
import torch.nn as nn
import copy
# 创建网络
net1 = nn.Linear(10, 1)
net2 = copy.deepcopy(net1)
# 创建优化器
optimizer1 = torch.optim.SGD(net1.parameters(), lr=0.01)
optimizer2 = torch.optim.SGD(net2.parameters(), lr=0.01)
# 定义输入
inputs1 = [-0.4507, 1.5306, 1.6414, -1.4976, -0.4955, 0.8670, 1.7535, 0.6661, -1.1307, 0.6601]
inputs1 = torch.Tensor(inputs1)
# print("1---inputs1",inputs1)
inputs2 = [-0.7951, 1.0476, 0.3908, 1.0368, -0.4870, 0.2596, 0.2631, 0.6549, -0.9619, -0.1810]
inputs2 = torch.Tensor(inputs2)
# print("1---inputs2",inputs2)
#定义标签
targets 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4628
4628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









