







Spark on windows
参考文献:https://blog.youkuaiyun.com/youchuikai/article/details/67049801

jdk配置
JAVA_HOME = E:\DevTool\Java\jdk1.7.0_80
scala配置
SCALA_HOME = E:\DevTool\scala-2.10.6
maven配置
MAVEN_HOME = E:\DevTool\apache-maven-3.0.4
hadoop配置
HADOOP_HOME = E:\DevTool\hadoop-common-2.2.0-bin-master
spark配置
SPARK_HOME = E:\DevTool\spark-1.6.0-bin-hadoop2.6
终极path配置
%JAVA_HOME%\bin;%SCALA_HOME%\bin;%MAVEN_HOME%\bin;%SPARK_HOME%\bin;%HADOOP_HOME%\bin;
新建一个maven项目
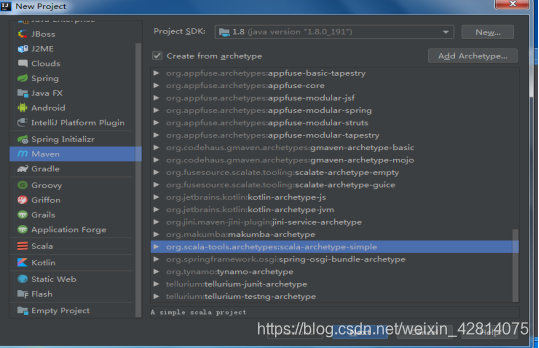
这里注意改一下仓库,根据个人情况
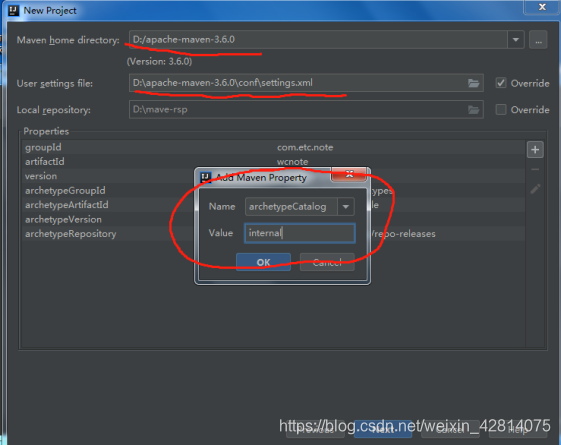
版本及依赖
<properties>
<scala.version>2.10.7</scala.version>
<spark.version>1.6.3</spark.version>
</properties>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
把jar包加载一下
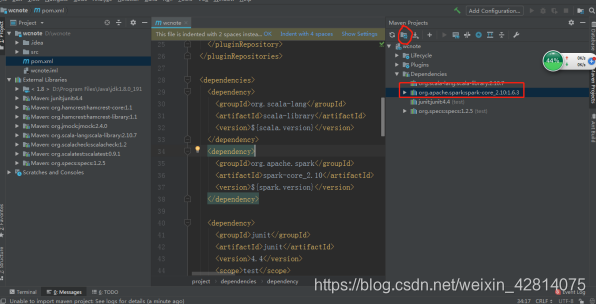
这里设置一下版本信息
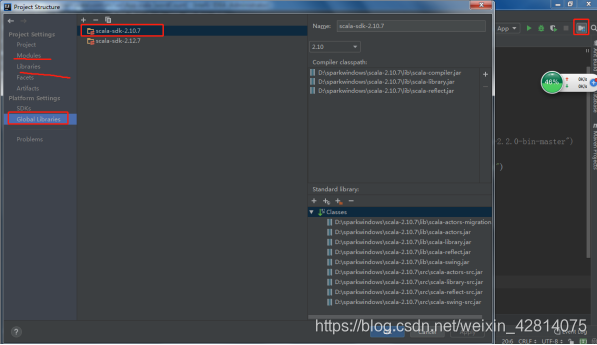
接下来就可以输入代码测试
package com.etc.wc
import org.apache.spark.{SparkConf, SparkContext}
/**
* Hello world!
*
*/
object App {
def main(args: Array[String]): Unit = {
// System.setProperty("hadoop.home.dir", "D:\\sparkwindows\\hadoop-common-2.2.0-bin-master")
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
val rowRdd = sc.textFile("D:\\sparklocal.txt")
val resultRdd = rowRdd.flatMap(line => line.split("\\s+"))
.map(word => (word, 1)).reduceByKey(_ + _)
for (data <- resultRdd){
println(data)
}
}
}
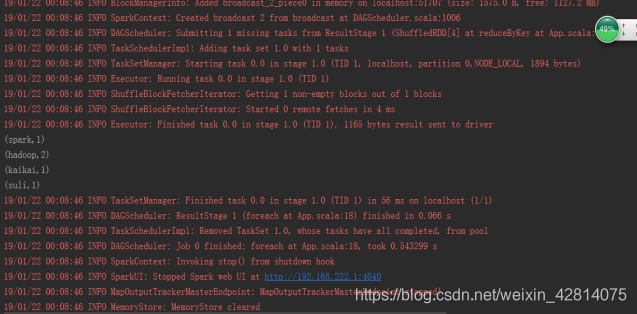
正常来讲结果是这样的

















 1320
1320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









