




 本文介绍如何使用BeautifulSoup库解析HTML和XML文件,并提取所需信息。文章详细解释了如何创建标签树,以及如何利用find_all()等方法进行标签查找。
本文介绍如何使用BeautifulSoup库解析HTML和XML文件,并提取所需信息。文章详细解释了如何创建标签树,以及如何利用find_all()等方法进行标签查找。
Beautifulsoup库:该库是python语言写的,主要功能是将html、xml格式的数据对象解析成“标签树”,并进行遍历和维护。
一、通过Beautifulsoup将数据变成标签树
Beautifulsoup标签树的集中基本元素如下:

二、提取标签树中的信息
soup.标签名1 获取第一个标签名=标签名1的整条标签信息
1、以下为查看标签、标签名、父标签、标签属性、标签的非属性字符串、标签类型、、、
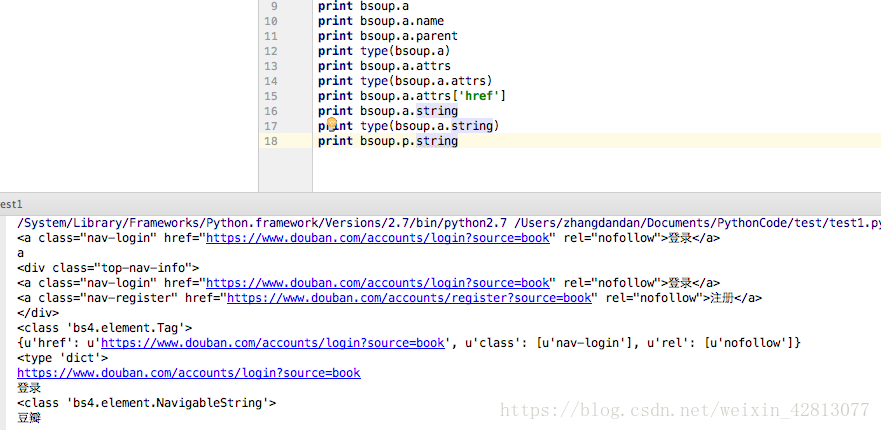
2、find_all()
用来查找标签元素:soup.find_all(name,attrs,string,**kwargs),返回一个列表类型的查找结果
soup.a.parent是tag类型的数据;soup.a.contents返回的是list类型的数据;soup.a.children返回的是一个迭代对象,只能通过for循环使用,不能直接通过索引来读取其中的内容
3、取出非子节点中的非属性字符串下图所示:
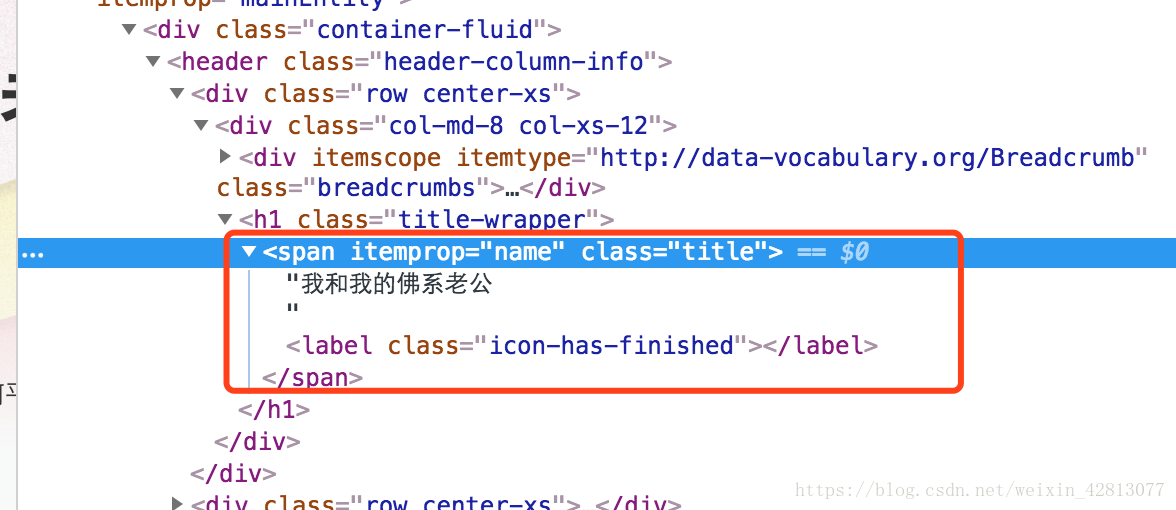
name_tag = soup.find(‘span’,itemprop=’name’)
name = name_tag2.contents[0]
BeautifulSoup库学习笔记
最新推荐文章于 2020-12-19 10:11:29 发布

















 2042
2042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









