




 本文介绍了解决使用Scrapy爬取百度贴吧时遇到的表情符号问题的方法。对于Python2,提供了过滤表情符号的代码;而对于Python3,则建议在创建数据库表时将字段设置为utf8mb4字符集。
本文介绍了解决使用Scrapy爬取百度贴吧时遇到的表情符号问题的方法。对于Python2,提供了过滤表情符号的代码;而对于Python3,则建议在创建数据库表时将字段设置为utf8mb4字符集。
今天笔者分享一下使用scrapy爬取百度贴吧的时候遇到的表情问题,一直未解决因为表情入库的问题再网上查了好久,从网上看到修改数据库字段的编码格式,但是一直修改的有问题,最终修改了好久才得解决,今天分享下来方便其他人如果遇到这类的问题。
python2的解决方法直接上代码如下:def filter_emoji(desstr, restr=''):
'''
过滤表情
'''
try:
co = re.compile(u'[\U00010000-\U0010ffff]')
except re.error:
co = re.compile(u'[\uD800-\uDBFF][\uDC00-\uDFFF]')
return co.sub(restr, desstr)
# safe_name = self.filter_emoji(item['lzhu_name']) //字段的过滤
# safe_title = self.filter_emoji(item['title']) //字段的过滤python3的解决方法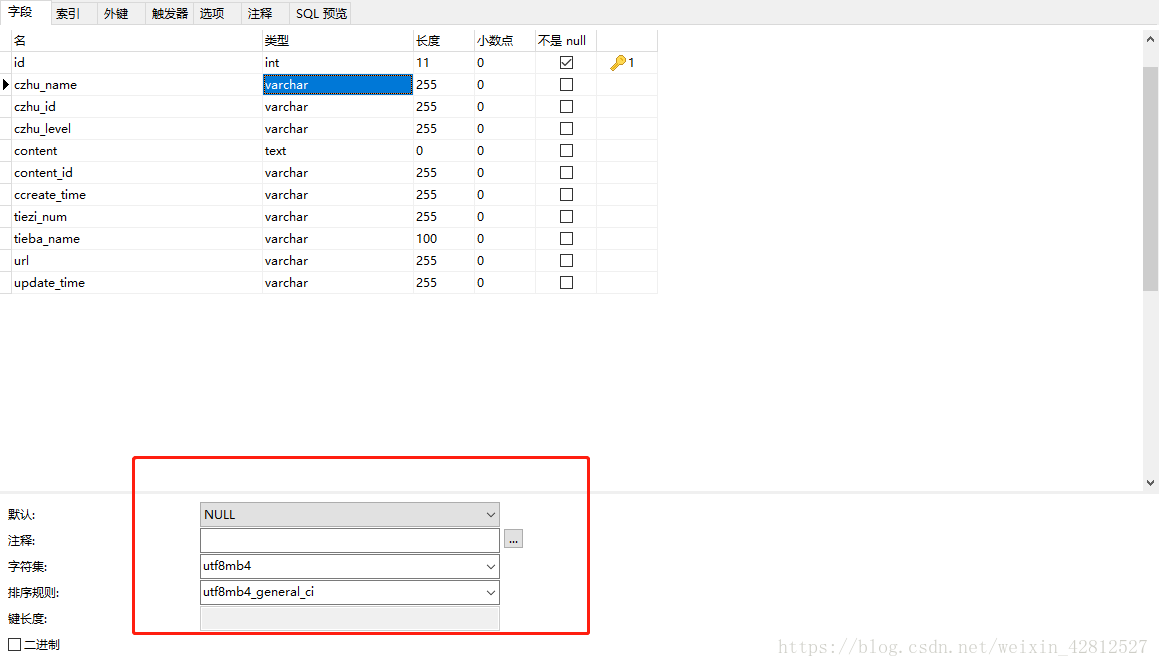
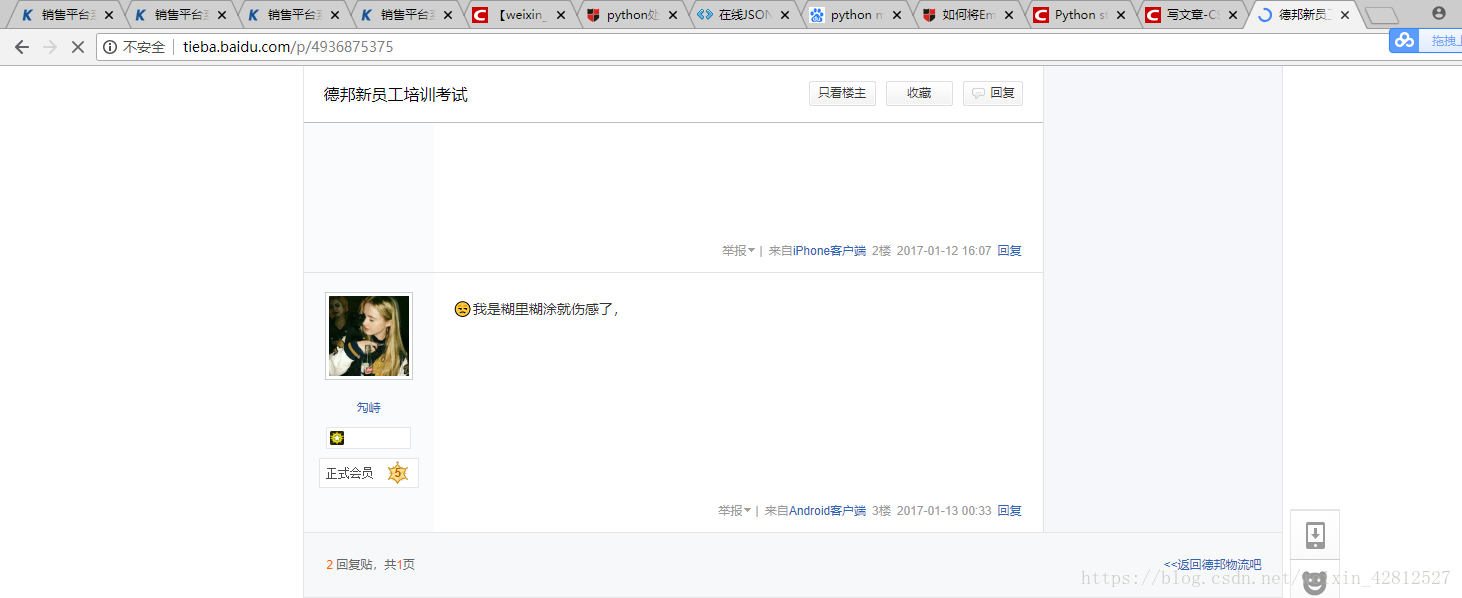
建表的时候是每一个字段都设置成utf8mb4字符集,保存即可,当然存到数据库中的数据并不能去除表情而是表情变成了如下图:

网页链接可以分享给你自己看: http://tieba.baidu.com/p/4936875375
好分享结束,希望能帮到你。

















 5193
5193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









