




这篇分享的是如下图所示简单的验证码的识别,解决简单的验证码的问题:

# coding=utf-8
import requests
import pytesseract
from PIL import Image
from io import BytesIO
captcha_url = '验证码路径'
captcha_content = requests.get(url=captcha_url)
captcha_content = captcha_content.content
# 用自字节读出图片
image = Image.open(BytesIO(captcha_content))
# 转化为灰度图
imgry = image.convert('L')
table = [0 if i < 140 else 1 for i in range(256)]
# 使字体更加突出的显示
out = imgry.point(table,'1')
# out.show()
captcha = pytesseract.image_to_string(out)
captcha = captcha.strip()
captcha = captcha.upper()
print captcha
当然笔者分享的仅仅是简单的验证码识别,后期学习的过程中也可以学习机器学习来实现验证码的识别。
后续分享来了,日期:2019-06-27 20:22。
今天分享一下,优化一下验证码识别的思路【个人认为,如果有错误可以提出来】。
一、前沿:我们都知道图片的三通道rgb,今天分享一个小小的知识点。大佬看到了错误可以指正出来。
二、识别验证码如下:

大家可以看一下字体和干扰线之间三通道的区别,可以通过截图来看。
字体的三通道值如下图:
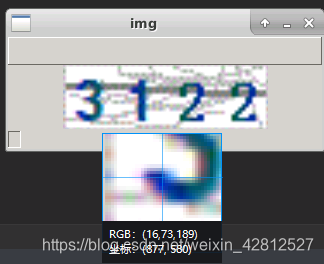
干扰线的三通道值如下图:
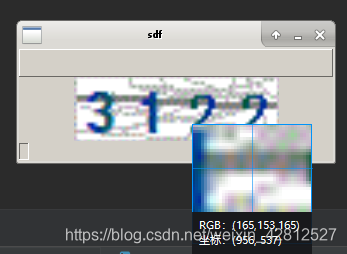
我们会发现,明显干扰线的rgb值波动很小,而字体的干扰线值波动是如此之大,那么何不考虑用方差来让方差小的变为255白色呢?这样的话不是更好,所以来试试这个思路,思路如下:
import cv2
import numpy as np
img = cv2.imread(r'D:\captcha.jpg')
h, w, c = img.shape
for i in range(h):
for j in range(w):
if np.var(img[i, j, :]) < 500: # 这个方差是需要自己调节的。
img[i, j, :] = 255 # 把小于500的调节成 255白色背景
cv2.imshow('img', img)
cv2.waitKey(0)
查看结果如下:
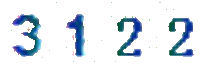
这样的话识别是不是更加好点呢?代码如下
import cv2
import numpy as np
import pytesseract
def read_cv():
img = cv2.imread(r'D:\captcha.jpg')
h, w, c = img.shape
for i in range(h):
for j in range(w):
if np.var(img[i, j, :]) < 500: # 这个方差是自己调节的。
img[i, j, :] = 255
captcha = pytesseract.image_to_string(img)
captcha = captcha.strip()
captcha = captcha.upper()
print(captcha)
if __name__ == '__main__':
read_cv()
附:另外的思路,当我们的验证码图片背景是一种颜色而验证码的字体是另外一种颜色的话,可以通过均值来去掉。当然我们去掉过后如果发现灰度图不好颜色过浅可以通过腐蚀膨胀来进行调节。仅仅是思路。

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









