






 本文对比分析了MSV(支撑向量机)和SoftmaxClassifier两种分类器的损失函数特性。MSV对边界样本敏感,仅考虑边界点;而SoftmaxClassifier认为所有样本同等重要,损失函数中包含所有点。文中详细解释了两种函数的评价指标及正则化权重,如L2和L1规则,并讨论了它们对参数分布的影响。
本文对比分析了MSV(支撑向量机)和SoftmaxClassifier两种分类器的损失函数特性。MSV对边界样本敏感,仅考虑边界点;而SoftmaxClassifier认为所有样本同等重要,损失函数中包含所有点。文中详细解释了两种函数的评价指标及正则化权重,如L2和L1规则,并讨论了它们对参数分布的影响。
支撑向量机的损失函数:
数据损失部分:![]()
例子:

L的最小值是0,最大值是无穷。
存在问题:

也就是,不同权值,得到的评价函数一样,实际上一般参数比较分散比较好,所以要加入涉及参数平均分布的评价指标,如下:

可以看到有L2、L1等多种规则化权重。
一般使用L2,是参数均匀分布的权重得分更高。
最终的到如下MSV损失函数:
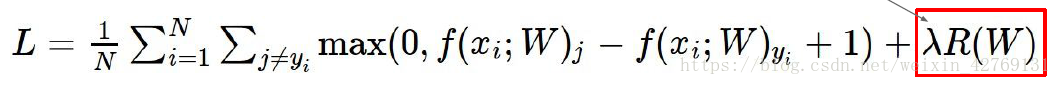
损失函数=数据损失+正则损失。
Softmax Classifier分类器的损失函数:
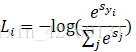
L的最小值是0,最大值是无穷,无穷更容易。
总结:

可以看到两种不同的损失评价函数对同一分类得到不同的数值,这主要是因为,MSV主要对分类边界的样本比较敏感,所以只考虑边界的点。而Softmax Classifier分类对内部的点同等的重要,所以损失函数中,被淘汰的点也要计算入损失函数中。
最优化:
这里讲的比较笼统,只讲了梯度下降法,以后补充。

















 2166
2166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









