




 本文详细介绍了Mask R-CNN模型,该模型在Faster R-CNN基础上增加了一个预测分割Masks的分支,实现了目标检测和实例分割的精确匹配。通过RoIAlign层提升了分割精度,同时在COCO数据集上展示了优秀的性能,并可应用于人体关键点检测等领域。
本文详细介绍了Mask R-CNN模型,该模型在Faster R-CNN基础上增加了一个预测分割Masks的分支,实现了目标检测和实例分割的精确匹配。通过RoIAlign层提升了分割精度,同时在COCO数据集上展示了优秀的性能,并可应用于人体关键点检测等领域。
Mask R-CNN
目录
1 概述
基于Fast/Faster R-CNN、FCN的基础网络,迅速推动了目标检测和语义分割的发展。实例分割是具有挑战性的,因为它需要正确地检测到所有物体,并且对每一个实例进行精确的分割。我们的方法叫做Mask R-CNN,它是由Faster R-CNN拓展而来,增加了一个分支来预测ROI(感兴趣区域)上的分割Masks。这个分支是基于FCN的网络,和现有的分类和边框回归网络是并行的。其结构如图1-1所示。
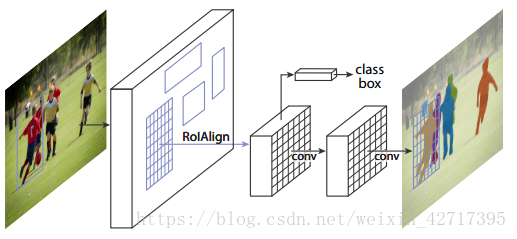
图1-1 实例分割Mask R-CNN框架示意图
我们提出了一个RoIAlign无量化误差的层,来精确的保留提取的空间位置信息。这个看似细微的改变,把Mask的精确度提升了10%-50%。我们的网络在GPU上处理每帧图像需要200ms,利用COCO数据集在8-GPUs上训练需要花费两天的时间。最后,我们在COCO的关键点数据集上进行了人体姿态判别的实验。Mask R-CNN可以看作为一个灵活的框架,并且应用在其他复杂的任务上面。
2 模型设计
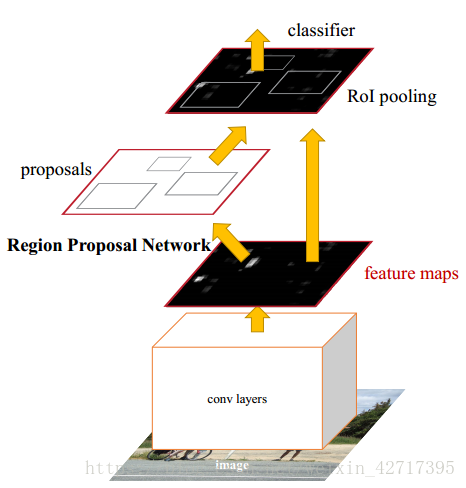
图2-1 Faster R-CNN结构示意图
如图2-1所示,Faster R-CNN由两个阶段构成。第一个阶段是RPN(Region Proposal Network),是为了产生候选的目标边框。第二个关键的阶段,使用RoIPool对每一个候选边框进行分类和回归。
Mask R-CNN继承了Faster R-CNN的结构,第一个阶段单独使用。在第二个阶段中,在预测类别和边框偏差的同时,对每一个RoI输出二值化的Mask。每一个RoI输出的二值化Mask维度为,共K个类别。设置其分辨率为m*m是为了保证目标的空间维度。先前的方法都是通过全连接层来进行mask预测,我们的全卷积代表需要更少的参数,并且更加的准确。

图2-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 539
539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









