



 本文讨论了Hadoop架构与MPP架构的优劣,介绍了ClickHouse、Impala和Spark在数据仓库中的角色,以及Hive的元数据管理。还涵盖了Kafka、NiFi在实时数据处理中的应用,以及Hudi、HBase和HDFS的选择,以及批处理与流处理框架的区别。
本文讨论了Hadoop架构与MPP架构的优劣,介绍了ClickHouse、Impala和Spark在数据仓库中的角色,以及Hive的元数据管理。还涵盖了Kafka、NiFi在实时数据处理中的应用,以及Hudi、HBase和HDFS的选择,以及批处理与流处理框架的区别。
数仓架构(即席查询)
总体来说,Hadoop架构在数据量较低的情况下,运行速度远不及MPP架构,但数据量一旦超过某个量级,Hadoop架构在吞吐量方面将非常有优势。有些大数据数据仓库产品也采用混合架构,以融合两者的优点,例如Impala、Presto等都是基于HDFS的MPP分析引擎,仅利用HDFS实现分区容错性,放弃MapReduce计算模型,在面向OLAP场景时可实现更好的性能,降低延迟。
ClickHouse进行轻量化数仓搭建【计算引擎:Hive VS ClickHouse】
ClickHouse适合简单的DW之上的即席查询。而Spark由于其分布式特性,导致其任务启动时间很长,因此不适合实现即席查询,但是对于大数据量的join等复杂查询时具备非常大的优势。
ClickHouse的优化重点在如何提高单机的处理能力,而Spark的优化重点在于如何提高分布式的协作效率。
ClickHouse与Hive的区别,终于有人讲明白了-clickhouse与hive 区别
impala刷新invalidate metadata VS refresh
invalidate metadata的特点就是异步性和全量性。invalidate metadata比起refresh而言要重量级得多,并且它造成impalad之间查询不一致也会更严重。因此,也几乎禁止使用不带表名的invalidate metadata语句。
refresh的特点是同步性和增量性。并且,它的执行是围绕单表以及单表的分区进行的,因此它更轻量级,也更适合分区元数据或数据文件更改之后的刷新。
正确使用Impala的invalidate metadata与refresh语句-优快云博客
查看HDFS路径命令
查询报错:该分区文件或目录不存在
hdfs dfs -ls hdfs://nameservice1/user/hive/warehouse/adl.db/a_gq_workdat_stat/
什么场景需要使用NiFi从Kafka中获取实时数据?
以下是一些可能需要使用NiFi从Kafka中获取实时数据的场景:
1.数据集成:如果你有一个Kafka集群作为数据源,希望将实时数据集成到其他系统或数据库中,可以使用NiFi来接收Kafka中的数据,并根据需要将其转换为不同的格式或协议,然后将其发送到目标系统中。
2.数据处理和分析:如果你需要对实时数据进行处理、转换、清洗、分析等操作,可以使用NiFi来接收Kafka中的数据,并利用NiFi的各种处理器和操作符来实现这些处理任务。例如,可以使用NiFi的JSON解析器来解析JSON格式的数据,然后将其转换为不同的格式或进行其他处理。
3.数据监控和报警:如果你需要实时监控数据的变化,并在某些情况下触发报警或通知,可以使用NiFi来接收Kafka中的数据,并使用NiFi的各种处理器和操作符来实现数据监控和报警功能。例如,可以使用NiFi的条件表达式来检查数据是否符合某个特定条件,并触发报警或通知操作。
4.数据流管理:如果你需要对数据流进行管理和控制,例如对数据进行过滤、路由、聚合等操作,可以使用NiFi来实现这些功能。NiFi提供了各种处理器和操作符,可以方便地对数据进行处理和管理。
总之,如果你需要将实时数据从一个系统传输到另一个系统,或者需要对实时数据进行处理、分析、监控等操作,可以考虑使用NiFi来实现这些功能。
实时数据可以由kafka直接输入数据服务api?
实时数据可以通过Kafka直接输入到数据服务API。
Kafka是一种分布式流处理平台,可以用于构建实时数据管道和流应用程序。它可以接受来自不同数据源的实时数据,并将其传输到不同的目标系统中。Kafka提供了一种高吞吐量、可扩展、可靠的方式,将数据从一个端点传输到另一个端点。
当实时数据通过Kafka输入到数据服务API时,Kafka将作为数据传输的中间件,将数据从源头发送到目标系统。数据服务API可以是一个独立的服务或者一个数据处理平台,用于接收Kafka传输的数据、处理数据、并将结果反馈回Kafka或其他目标系统。
例如,数据服务API可以使用一些常见的数据处理和机器学习框架(如Apache Flink、Apache Spark、TensorFlow等)来处理接收到的实时数据。这些框架可以对数据进行清洗、转换、分析、挖掘等操作,将处理后的数据用于业务决策、预警预测等应用中。
总之,通过Kafka直接输入实时数据到数据服务API是一种常见的实践,可以帮助企业快速构建高效、可靠的实时数据分析应用。
实时数据由Kafka传入数据服务API的中间,什么时候需要加入TDengine?
Kafka-Nifi/CDC-TDengine-数据服务API
在实时数据分析中,可以在以下情况下考虑加入TDengine:
数据存储和查询:当实时数据量较大,需要高效地进行数据存储和查询时,可以将TDengine作为存储和查询引擎。TDengine针对时序数据进行了优化,能够高效地存储和处理大量数据,并提供了高效的查询功能。通过将实时数据存储在TDengine中,用户可以快速获取和分析这些数据。
数据处理和计算:当需要实时对大量数据进行处理和计算时,可以在TDengine中加入数据处理和计算逻辑。TDengine支持多线程、分布式查询,可以快速处理高并发的数据读取请求,从而满足实时数据处理的需求。
高可用性和稳定性:当实时数据分析系统需要高可用性和稳定性时,可以将TDengine作为高可用性的存储和查询引擎。TDengine采用了主从复制和自动故障转移机制,保证了系统的高可用性。当部分组件发生故障时,整个系统仍能正常运行,从而提供了稳定可靠的服务。
日志分析:当需要处理海量的日志数据,通过实时分析和挖掘日志数据,发现潜在的问题和优化点时,可以将TDengine作为日志分析引擎。TDengine可以用于实时监控系统的运行状态和性能指标,可以在系统出现故障或性能下降时,快速发现和解决问题。
总之,在实时数据分析中,根据具体需求和场景,可以在不同的环节中加入TDengine,以提供更高效、可靠、稳定的数据存储、查询、处理、监控等功能。
spark streming和flink,storm的区别
Spark Streaming、Flink和Storm都是流处理框架,但它们之间有一些区别。
Spark Streaming是一个批处理框架,它将数据流切分成细粒度的batch进行处理。它支持容错和批处理,但是它不支持低延迟和Exactly-once保证。
Flink同时支持流处理和批处理。一条数据被处理完以后,序列化到缓存后,以固定的缓存块为单位进行网络数据传输,缓存块设为0为流处理,缓存块设为较大值为批处理。Flink在低延迟和数据顺序方面(利用水印)等都相对Spark Streaming更具优势。
Storm只支持流处理任务,数据是一条一条的源源不断地处理。而MapReduce、Spark只支持批处理任务。
Spark和MR,谁处理的数据量更大?
Spark和MR都是分布式计算框架,但是它们的处理数据的能力有所不同。一般来说,Spark处理数据的能力是MR的十倍以上 。Spark基于内存,而MR基于磁盘(HDFS) 。此外,Spark中除了基于内存计算外,还有DAG有向无环图来切分任务的执行先后顺序。而MR中只有map、reduce和join。
因此,如果你需要处理大量数据,那么Spark可能是更好的选择。但是如果你需要处理的数据量较小,则MR可能更适合你的需求。
Spark Standalone和YARN的区别如下
- Yarn模式只需要一个节点,然后提交作业即可,不需要启动Spark集群的(不需要启动Master和Worker)。
Standalone模式需要在Spark集群上的每个节点都需要部署Spark,然后需要启动Spark集群(需要Master和Worker进程节点)。
大数据入Hdfs还是Hudi
Hudi是一个开源的大数据存储和处理工具,可以基于HDFS之上管理大型分析数据集,可以对数据进行插入、更新、增量消费等操作,主要目的是高效减少摄取过程中的数据延迟。Hudi非常轻量级,可以作为lib与Spark、Flink进行集成 。
HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,是Hadoop生态系统中的重要组成部分之一。它是一个高度容错性的系统,适合在廉价硬件上部署并进行大规模数据处理。
HBase VS TDengine
HBase 不适用于大范围扫描查询,性能比较差
HBase 不支持聚合查询,大跨度时间范围查询数据量太大,图表无法渲染
HBase 部署需要依赖 ZooKeeper,运维成本高
HDFS分布式文件存储
问题:文件大小不一,不利于统一管理
解决:设定统一的管理单位,block块,默认大小256M(可以修改)
Hive计算引擎
Hive支持MapReduce、Tez和Spark 三种计算引擎。
Hive元数据
描述数据的数据,例如数据表的大小是100KB,数据表是数据,表大小是数据的数据。
Hive元数据包括hive库信息、表信息(表的属性、表的名称、表的列、分区及其属性)以及表数据所在的目录等。
默认是存储在derby中的,但是我们一般会修改其存储在关系型数据库比如MYSQL中(其可以在hive配置中修改),在关系型数据库中会有一个hive库,存放相应的表。
元数据和主数据的区别
元数据和主数据是两个不同的概念,但它们都与数据管理、数据处理和信息系统有关。
元数据(Metadata)是描述其它数据的数据,或者说是用于提供某种资源的有关信息的结构数据。它主要用于识别资源、评价资源、追踪资源在使用过程中的变化,以及实现信息资源的有效发现、查找、一体化组织和对使用资源的有效管理。
主数据(Master Data)是指具备高业务价值的,能够在企业内跨各个业务部门被重复使用的数据,是单一、准确、权威的数据来源。主数据是项目的最关键、最核心的数据,重点用来解决异构系统之间关键数据的不一致、不正确、不完整等问题,主数据是信息系统建设和大数据分析的基础。
总的来说,元数据主要关注数据的描述和组织,而主数据则更侧重于跨业务部门的数据共享和一致性。
Q:Hive分区表创建后,未放数据,目录存在吗?
A:不存在
Hive实际工作中为什么很少用分桶进行数据存储
Hive的分桶和分区都是优化查询和数据管理的重要手段,不过在实际工作中,分桶的使用相对较少。它们都是一种通过改变表的存储模式来优化表的方式。分区是将表按照某个字段的值划分成不同的目录进行存储,而分桶则是将表按照某个字段的hashcode值划分成不同的文件进行存储。
分桶的优点包括:
- 可以进行抽样查询;
- 可以对数据进行随机分发,从而避免数据倾斜的问题;
- 可以提高MapReduce任务的并行度,从而提高处理效率。
然而,在实际应用中,分桶的使用并不广泛,原因可能包括:
- 分桶需要提前设定好分桶数量和字段,这可能会限制其灵活性;
- 分桶可能增加数据的管理和查询复杂性;
- 对于某些特定的查询需求,使用分区可能更为简单和有效。
批处理架构和MPP架构
批处理架构(如 MapReduce)与MPP架构的异同点,以及它们各自的优缺点是什么呢?
相同点:
首先相同点,批处理架构与MPP架构都是分布式并行处理,将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
不同点:
批处理架构和MPP架构的不同点可以举例来说:我们执行一个任务,首先这个任务会被分成多个task执行,对于MapReduce来说,这些tasks被随机的分配在空闲的Executor上;而对于MPP架构的引擎来说,每个处理数据的task被绑定到持有该数据切片的指定Executor上。
正是由于以上的不同,使得两种架构有各自优势也有各自缺陷:
批处理的优势:
对于批处理架构来说,如果某个Executor执行过慢,那么这个Executor会慢慢分配到更少的task执行,批处理架构有个推测执行策略,推测出某个Executor执行过慢或者有故障,则在接下来分配task时就会较少的分配给它或者直接不分配。
MPP的缺陷:
对于MPP架构来说,因为task和Executor是绑定的,如果某个Executor执行过慢或故障,将会导致整个集群的性能就会受限于这个故障节点的执行速度(所谓木桶的短板效应),所以MPP架构的最大缺陷就是——短板效应。另一点,集群中的节点越多,则某个节点出现问题的概率越大,而一旦有节点出现问题,对于MPP架构来说,将导致整个集群性能受限,所以一般实际生产中MPP架构的集群节点不易过多。
批处理的缺陷:
任何事情都是有代价的,对于批处理而言,会将中间结果写入到磁盘中,这严重限制了处理数据的性能。
MPP的优势:
MPP架构不需要将中间数据写入磁盘,因为一个单一的Executor只处理一个单一的task,因此可以简单直接将数据stream到下一个执行阶段。这个过程称为pipelining,它提供了很大的性能提升。
举个例子:要实现两个大表的join操作,对于批处理而言,如Spark将会写磁盘3次(第一次写入:表1根据join key进行shuffle;第二次写入:表2根据join key进行shuffle;第三次写入:Hash表写入磁盘), 而MPP只需要一次写入(Hash表写入)。这是因为MPP将mapper和reducer同时运行,而MapReduce将它们分成有依赖关系的tasks(DAG),这些task是异步执行的,因此必须通过写入中间数据共享内存来解决数据的依赖。
批处理架构和MPP架构融合:
两个架构的优势和缺陷都很明显,并且它们有互补关系,如果我们能将二者结合起来使用,是不是就能发挥各自最大的优势。目前批处理和MPP也确实正在逐渐走向融合,也已经有了一些设计方案,一旦技术成熟,可能会风靡大数据领域,我们拭目以待!
异常关闭虚拟机出现的无法开启虚拟机和xshell连不上虚拟机问题
首先说一下笔者的情况,由于电脑电量耗尽,且没有关闭虚拟机,出现的情况。
1 首先是无法开启虚拟机的问题
找到虚拟机的所在目录,会出现尾缀为.lck的文件夹,显示的是当前日期,删除即可。
2 .xshell连不上问题
1.此电脑 > 单击鼠标右键 > 管理 > 服务 > VMware NAT service没有启动;
2.服务中的VMware NAT service没有设置为开机自启动,并手动启动问题得到解决。
存储方式:ORC VS Parquet
百度安全验证 https://baijiahao.baidu.com/s?id=1771269673009473565&wfr=spider&for=pc
https://baijiahao.baidu.com/s?id=1771269673009473565&wfr=spider&for=pc
ORC和Parquet都是列式存储格式,用于高效地存储和查询大规模数据。相比于Parquet,ORC在写入和读取方面更加高效,支持动态结构和嵌套数据类型,适用于存储非常规数据和半结构化数据。而Parquet在支持跨平台查询和集成方面表现更好,被广泛应用于多种开源和商业分布式计算和分析系统中。不同的应用场景下,可以根据需求选择最合适的存储格式。
Hive默认的存储方式是行存储,这种格式为文本文件格式(TEXTFILE)。在创建Hive表时,如果不指定存储格式,就会采用这种格式。文本文件中每一行数据被视为一条记录,并且可以使用任何分隔符进行分隔。这种格式使得数据共享、查看和编辑非常方便。然而,需要注意的是,Hive也支持其他多种存储格式,包括二进制序列化文件(SequenceFile)、列式存储的ORC文件和Parquet文件等。
Hive内/外部表应用场景
在Hive中,内部表和外部表是两种不同的表格类型。内部表的数据存储在Hive的默认仓库中,而外部表的数据存储在指定的位置,不加载到Hive的默认仓库中。因此,当需要在其他应用程序中使用数据,或者避免数据被修改或丢失时,建议使用外部表。
具体来说,当你需要创建外部表时,需要在建表语句中使用EXTERNAL关键字,并明确指定数据文件的存储路径。例如:CREATE EXTERNAL TABLE table_name (column1 string, column2 string) LOCATION '/AUTO/PATH';。而如果你没有使用EXTERNAL关键字,那么创建的将是一个内部表,其数据会被存储在Hive的默认仓库中。
总的来说,选择内部表还是外部表取决于你的具体需求和数据处理任务。例如,如果你正在进行数据分析并且需要频繁地修改数据,那么内部表可能是更好的选择。反之,如果你正在处理大量的数据并且不希望修改原始数据,那么外部表可能更适合你的需求。
补充:自建数据表并能自我控制,采用内部表
增加季度,目录层级增加,但分区数量不变

各组件(YARN、HDFS)资源管理
YARN:内存(memory),CPU(VCores)
HDFS:磁盘
CPU内核查询命令
grep 'processor' /proc/cpuinfo | sort -u | wc -l
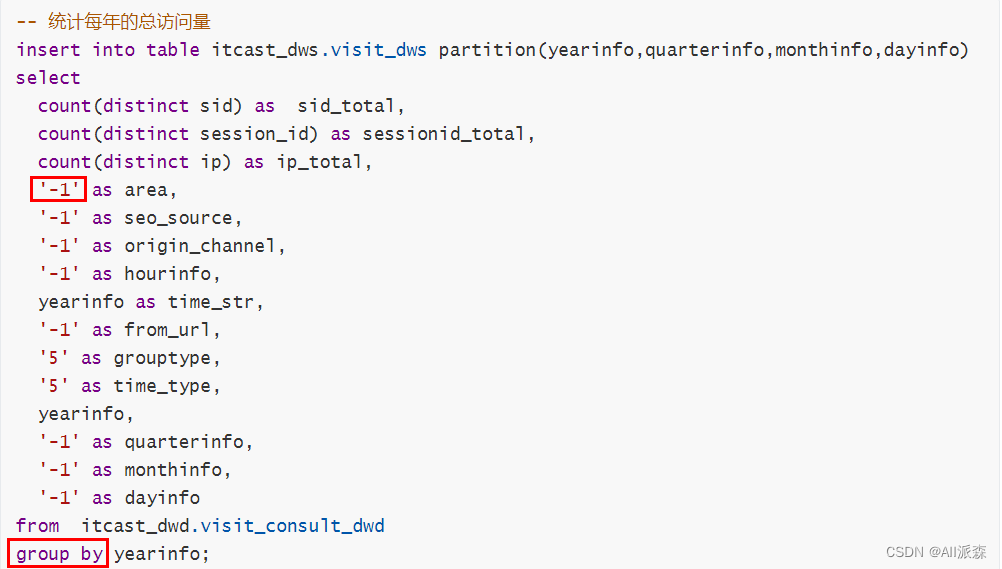
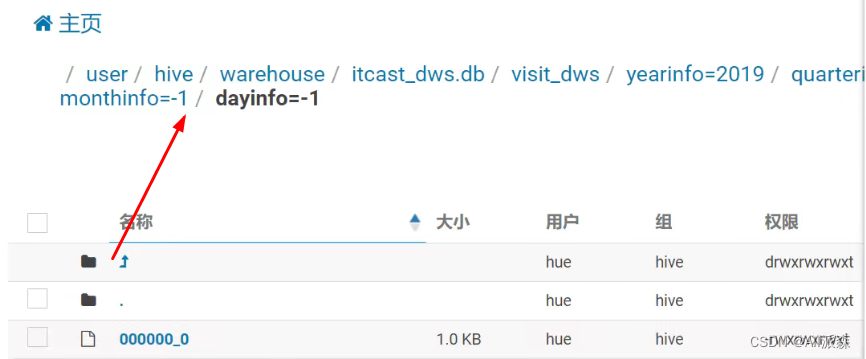
Group by 的select 中出现 ‘-1’
如何通过shell脚本获取上一天的日期呢?
难度1: 如何通过shell脚本获取上一天的日期呢?
date -d '-2 day' : 获取前二天的日期
date -d '-1 year': 获取上一年日期
date -d '-1 week': 获取上一周的日期
date -d '-1 hour': 获取上一个小时日期
注意上述命令获取后的日期格式为: 2021年 09月 26日 星期日 08:48:12 CST
但是sqoop基本需要的是 2021-09-25 如何解决呢?
date -d '-1 day' +'%Y-%m-%d %H:%M:%S'
输出为: 2021-09-25 09:51:42
shell脚本之sqoop运行方式
串行:with
并行:&
namenode的元数据是存储在硬盘还是内存
在Hadoop的HDFS中,NameNode管理着文件系统的元数据信息。这些元数据以两种形式存在:一部分以内存对象的形式存储在内存中,包括文件和目录的层次结构、文件属性和块的位置信息等,这样做是为了快速访问和处理文件系统操作;另一部分则是元数据的序列化文件,存储在磁盘上,这是为了确保在NameNode宕机后,数据依然不会丢失。此外,NameNode还会将元数据写入到一个或多个持久化存储设备中,通常是一个或多个编辑日志文件(Edit Logs)和一个FsImage文件。编辑日志文件记录了文件系统的操作日志,而FsImage文件则是元数据的快照。当NameNode重启时,它会读取编辑日志文件来恢复文件系统的状态,并加载FsImage文件来还原元数据。这种机制保证了Hadoop HDFS的高可用性和数据的安全性。

















 1868
1868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









