



 文章探讨了标签系统的作用,如表达、组织、学习、发现和决策,并分析了用户为何及如何打标签。基于标签的推荐系统通过用户打标签的行为进行物品推荐,但面临数据稀疏性和热门标签偏好等问题。提出了TagBasedTFIDF算法、标签相似度扩展和标签清理等改进策略。同时,介绍了给用户推荐标签的方法,包括热门标签、物品标签和用户个性化标签等。对于新用户和非热门物品,建议使用内容数据和关键词拓展来生成推荐标签。
文章探讨了标签系统的作用,如表达、组织、学习、发现和决策,并分析了用户为何及如何打标签。基于标签的推荐系统通过用户打标签的行为进行物品推荐,但面临数据稀疏性和热门标签偏好等问题。提出了TagBasedTFIDF算法、标签相似度扩展和标签清理等改进策略。同时,介绍了给用户推荐标签的方法,包括热门标签、物品标签和用户个性化标签等。对于新用户和非热门物品,建议使用内容数据和关键词拓展来生成推荐标签。
标签是一种无层次化结构的、用来描述信息的关键词,它可以用来描述物品的语义。一种标签是让作者/专家给物品打标签;另一种是让用户给物品打标签,也就是UGC。
4.1 UGC标签系统的代表应用
标签系统的不同作用如下:
表达:标签系统帮助我表达对物品的看法
组织:打标签帮助我组织我喜欢的电影
学习:打标签帮助我增加对电影的了解
发现:标签系统使我更容易发现喜欢的电影
决策:标签系统帮助我判定是否看某一部电影
4.2 标签系统中的推荐问题
标签系统中的推荐问题主要有以下两个:基于标签的推荐(如何利用用户打标签的行为为其推荐物品)、标签推荐(如何给用户推荐适合物品的标签)。
我们首先需要解答下面的三个问题。
4.2.1 用户为什么进行标注
从社会维度划分,有些标注是给内容上传者使用,便于他们组织自己的信息;有些标注是给广大用户使用的,便于帮助其他用户找到信息。
从功能维度划分,有些标注用于更好地组织内容,方便用户将来的查找;有些标注用于传达某种信息。
4.2.2 用户如何打标签
标签流行度一样服从长尾分布
4.2.3 用户打什么样的标签
标签大体上可以分为以下几类:
表明物品是什么
表明物品的种类
表明谁拥有物品
表达用户的观点
用户相关的标签
用户的任务
4.3 基于标签的推荐系统
一个用户标签的数据集一般由三元组的集合表示,其中(u,i,b)表示用户u给物品i打上了标签b。
一个简单的算法是,
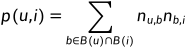
其中,B(u)使用户u打过的标签集合,B(i)是物品i被打过的标签集合,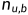 使用户u打过标签b的次数,
使用户u打过标签b的次数,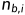 是物品i被打过标签b的次数。
是物品i被打过标签b的次数。
针对上述的算法,我们发现一些缺点并提出改进意见:
1)TF-IDF:该公式倾向于给热门标签对应的热门物品很大的权重,因此借鉴TF-IDF的思想我们提出TagBasedTFIDF,即:
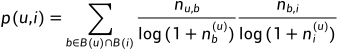
其中分母考虑了标签b/物品i分别被多少个不同的用户使用过/打过标签。
2)数据稀疏性:对于新用户或者新物品,BuBi的标签数量会很少。因此我们需要对标签集合做扩展,比如把相似度较高的标签合并到一起。这里我们就需要定义标签的相似度,基于邻域的定义方法如下
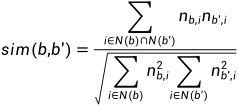
3)标签清理:一些标签并不能反映用户的兴趣,比如停止词、表示情绪的词等等,因此需要最标签清理。
当然我们也可以引入基于图的推荐算法,顶点包含用户顶点、物品顶点和标签顶点,如果我们有三元组(u,i,b),那么就在对应的三个点之间各加一条边。然后使用PersonalRank算法计算节点之间的相关性。
4.4 给用户推荐标签
常用方法基本都基于以下几种思路:
法0:给用户u推荐整个系统上最热门的标签(PopularTags)
法1:给用户u推荐物品i上最热门的标签(ItemPopularTags)
法2:给用户u推荐他自己经常使用的标签(UserPopularTags)
法3:物品和用户的融合(HybridPopularTags)
针对新用户和非热门物品,我们有两个解决思路。第一个思路,从内容数据中抽取关键词作为标签推荐;第二个思路,进行关键词拓展,利用为数不多的已有关键词,引入一些词义、领域相关的标签。

















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









