



 文章介绍了协同过滤的基本原理,包括用户和物品两种协同过滤算法,以及如何通过用户行为数据进行分析。此外,还讨论了隐语义模型如LFM以及基于图的推荐算法在处理用户-物品交互数据时的角色。文章强调了冷启动问题和实时性在不同模型中的影响,并指出热门物品对推荐结果的潜在影响。
文章介绍了协同过滤的基本原理,包括用户和物品两种协同过滤算法,以及如何通过用户行为数据进行分析。此外,还讨论了隐语义模型如LFM以及基于图的推荐算法在处理用户-物品交互数据时的角色。文章强调了冷启动问题和实时性在不同模型中的影响,并指出热门物品对推荐结果的潜在影响。
协同过滤就是指用户可以齐心协力,通过不断地和网站互动,使自己的推荐列表能够不断过滤掉自己不感兴趣的物品,从而越来越满足自己的需求。
2.1 用户行为数据简介
原始日志、很多互联网业务会把多种原始日志安全用户行为汇总成会话日志。比如,一个并行程序会周期性地归并展示日志恶化点击日志,得到的会话日志中每条消息是一个用户提交的查询、结果以及点击。
按照反馈的明确性,用户行为分为显性和隐性。显性反馈行为的例子是评分和喜欢/不喜欢等。隐形反馈行为的例子是用户浏览行为。按照反馈的方向,用户行为分为正反馈和负反馈。按照是否记录事件时间信息,又分为有上下文和无上下文的行为。
2.2 用户行为分析
2.2.1 用户活跃度和物品流行度的分布
用户活跃度和物品流行度都服从长尾分,即“多数占据少数”。
2.2.2 用户活跃度和物品流行度的关系
用户越活跃,越倾向于浏览冷门的物品。仅仅基于用户行为数据设计的推荐算法一般称作协同过滤算法,比如基于邻域的方法、隐语义模型、基于图的随机游走算法等。
2.3 实验设计与算法评测
2.4 基于邻域的算法
2.4.1 基于用户的协同过滤算法
核心思想是,先找到和一个用户有相似兴趣的其他用户,然后把那些用户喜欢的且该用户没有听说过的物品推荐出去。
以余弦相似度为例,给定用户u和用户v,令N(u)表示u有过正反馈的物品集合,令N(v)表示v有过正反馈的物品集合。那么两个用户的相似度为
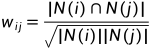
实际上,计算时无需遍历所有的(u,v)配对,为节省运算时间。只需要建立稀疏矩阵C,然后通过物品到用户的倒查表,通过+1操作来加速计算。
得到兴趣相似度后,就可以计算用户u对物品j的感兴趣程度了:
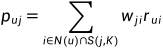
其中N(u)是用户喜欢的物品的集合,S(i,K)是和物品i最相似的K个物品的集合。一般情况下,随着K的提升,推荐系统的准召会先提升后降低,流行度会持续上升,覆盖率会持续下降。
当然用户相似度也有一些优化方法,比如User-IIF算法,惩罚了热门物品对相似度的影响。
2.4.2 基于物品的协同过滤算法
核心思想是,给用户推荐那些和他们之前喜欢的物品相似的物品。具体过程与UserCF类似。
2.4.3 UserCF和ItemCF的综合比较
UserCF | ItemCF | |
性能 | 适用于用户较少的场合 | 适用于物品数明显小于用户数的场合 |
适用领域 | 时效性强,用户个性化兴趣不明显 | 长尾物品丰富,用户个性化需求强烈 |
实时性 | 用户有新行为,不一定造成推荐结果的立即变化 | 用户有新行为,一定会导致推荐结果的实时变化 |
冷启动 | 新用户不行,新物品可以 | 新物品不行,新用户可以 |
可解释性 | 很难提供令用户信服的推荐解释 | 利用用户的历史行为给用户做推荐解释,可以令用户比较信服 |
注:CF方法要注意消除热门物品对推荐结果的影响,必要的时候可以牺牲准召来提升覆盖度。
2.5 隐语义模型
核心思想是,基于用户行为统计对物品进行自动分类,例如pLSA、LDA、LFM等。
隐语义模型是可以通过数据来学习的。针对隐性反馈行为,我们需要人为刻画负样本,构造负样本需要考虑以下两点:第一,正负样本比例尽可能均衡;第二,尽可能选用热门但用户无反馈的商品作为负样本。
以LFM为例,通过如下公式计算用户u对物品i的兴趣:
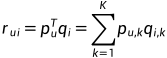
这里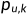 度量用户u的兴趣和第k个隐类的关系,而
度量用户u的兴趣和第k个隐类的关系,而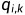 度量第k个隐类和物品i之间的关系。训练的过程是最小化损失函数的过程,即MSE加正则项。
度量第k个隐类和物品i之间的关系。训练的过程是最小化损失函数的过程,即MSE加正则项。
但是,LFM模型很那实现实时的推荐,因为它每次训练时都需要扫描所有的用户行为记录,这样才能计算出用户隐类向量和物品隐类向量。新闻推荐领域冷启动问题非常明显,每天都会有大量新的新闻。这些新闻的生命周期很短,因此推荐算法对于实时性的要求较高,LFM明显与实际产品需要矛盾。
2.6 基于图的模型
2.6.1 用户行为数据的二分图表示
令G(V,E)表示用户物品二分图,其中V由用户顶点集合和物品顶点集合组成。如果用户u对物品i产生过行为,那么两个点之间则连一条线。遮掩构成一个用户-物品二分图模型。
2.6.2 基于图的推荐算法
关键在于度量图中任意两个顶点之间的相关性,主要取决于以下3个因素:
1)两个顶点之间的路径数
2)两个顶点之间的路径长度
3)两个顶点之间的路径经过的顶点。
相关性搞得顶点一般具有如下特征:
1)两个顶点之间有很多路径相连
2)连接两个顶点之间的路径长度都比较短
3)连接两个顶点之间的路径不会经过初度比较大的顶点


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









