




 本文介绍了如何使用Python分析和爬取使用Ajax加载的果壳网科学人文章。通过Chrome开发者工具观察Ajax请求,识别请求链接和参数,特别是offset参数用于分页。解析响应的JSON数据获取文章链接,然后用BeautifulSoup提取文章的标题、作者和正文。最后,将数据保存为txt文件或存入MongoDB数据库,利用进程池提高爬取速度。
本文介绍了如何使用Python分析和爬取使用Ajax加载的果壳网科学人文章。通过Chrome开发者工具观察Ajax请求,识别请求链接和参数,特别是offset参数用于分页。解析响应的JSON数据获取文章链接,然后用BeautifulSoup提取文章的标题、作者和正文。最后,将数据保存为txt文件或存入MongoDB数据库,利用进程池提高爬取速度。
有时在使用requests抓取页面会遇到得到的结果与在浏览器 中看到的结果不一样,在浏览器检查元素中可以看到的正常的显示的网页数据,但是requests请求得到的结果却没有。这是因为requests请求得到的时原始的html文档,而浏览器中的界面确实经过JavaScript处理数据生成的结果,这些数据来源可能不同,有的时Ajax加载的,可能包含在html文档中,也有可能经过JavaScript渲染得到的。
对于Ajax(全称:Asynchronous JavaScript and XML),即异步的JavaScript和XML,是一种利用JavaScript技术在保证页面不刷新的情况下与服务器交换数据并更新部分网页的技术。
对于没有使用Ajax技术的网页来说,要想更新内容,就必须刷新整个页面,但使用Ajax就可以在后台完成与服务器的数据交互,获取到数据之后,再利用JavaScript改变网页即可。
这里以果壳网科学人为例,url为:“https://www.guokr.com/scientific/”,在文章下拉中我们并没有发现有翻页的操作,但会出现一个加载动画,然后下方又出现了新的内容,这个过程就是Ajax加载的过程,而网页的连接并没有改变。
 Ajax加载动画
Ajax加载动画
Ajax的分析:
Ajax具体又是如何实现这一过程的呢。从发送Ajax请求到网页更新过程中其实可以简单分为一下3个部分:
1)发送请求;
2)解析内容;
3)渲染网页
这个过程基本都需要以来JavaScript来实现,因为不是专业的,这里就不班门弄斧了,下面具体来说一下分析方法;
以chrome浏览器来介绍,打开链接:“https://www.guokr.com/scientific/”,打开开发者工具,并切换到network选项卡,如下图所示:
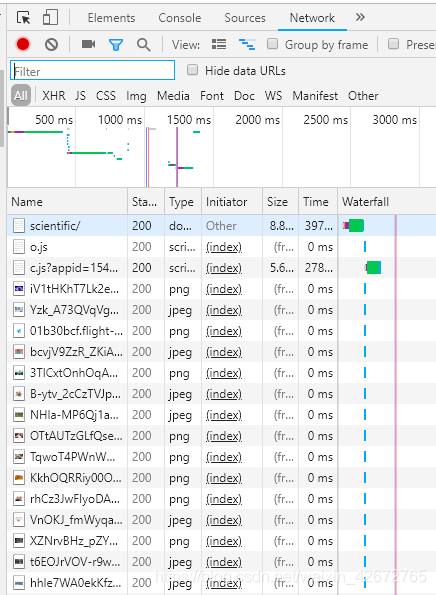 network面板结果
network面板结果
这里可以看到非常多的条目,但Ajax的请求是一种特殊的类型,叫做xhr,在选项栏直接选区XHR,则剩下显示的就都是Ajax请求了,并且随着下滑在下方会不断的出现新的Ajax请求,下面就可以通过分析这个请求去实现数据的爬取了。(在请求头信息中发现X-Requested-With: XMLHttpRequest字段即为Ajax请求)
选定其中一个请求,进入详情界面,如下图:
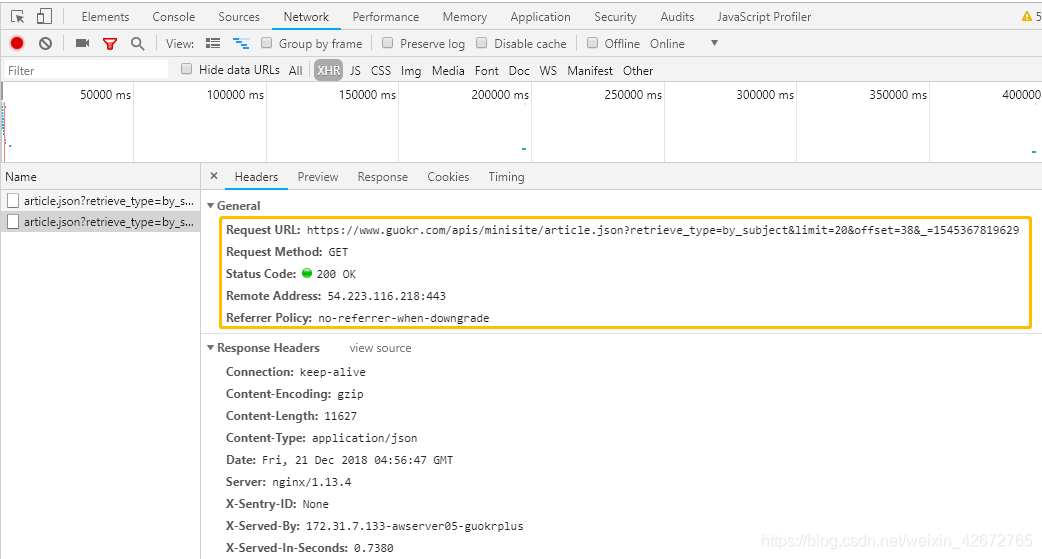 可以发现这是一个GET类型的请求,请求的链接为:’https://www.guokr.com/apis/minisite/article.json?retrieve_type=by_subject&limit=20&offset=38&_=1545367819629‘,请求的参数有3个:retrieve_type,limit和offset,通过查看其他请求发现retrieve_type,limit始终如一,改变的只有offset值,即控制分页的参数,且规律很简单,第一页为18,此后每一页增加20.
可以发现这是一个GET类型的请求,请求的链接为:’https://www.guokr.com/apis/minisite/article.json?retrieve_type=by_subject&limit=20&offset=38&_=1545367819629‘,请求的参数有3个:retrieve_type,limit和offset,通过查看其他请求发现retrieve_type,limit始终如一,改变的只有offset值,即控制分页的参数,且规律很简单,第一页为18,此后每一页增加20.
接下来观察这个请求的响应内容,即preview界面,如下图:
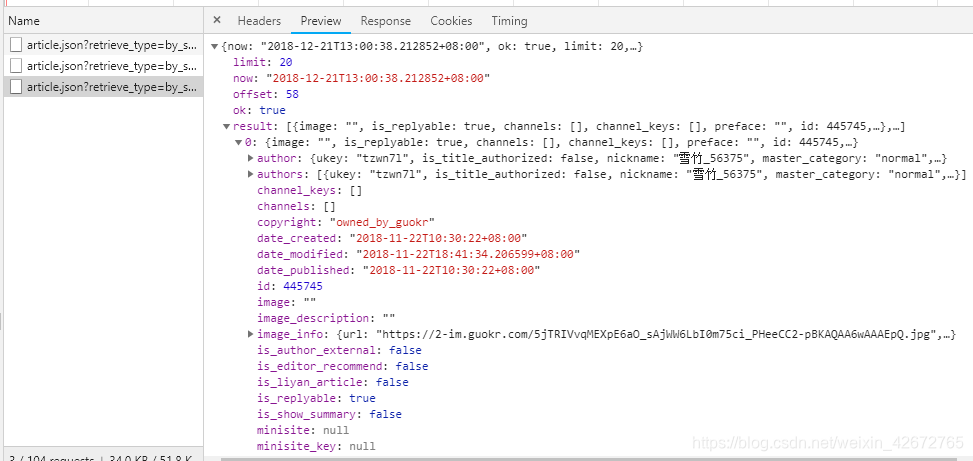 响应内容
响应内容
可以发现这个响应内容是JSON格式的,浏览器帮我们做了解析,可以看到信息就是在result里面,这里我们只需要得到文章的链接即可,即url字段,然后在每一个详情页面对文章内容解析。
接下来是具体代码的实现:
首先定义一个方法来获取每次请求的结果,在请求时,将offset作为参数传入来构造url,代码如下:
import requests
from urllib.parse import urlencode
def get_index(offset):
base_url = 'http://www.guokr.com/apis/minisite/article.json?'
data = {
'retrieve_type': "by_subject",
'limit': "20",
'offset': offset
}
url = base_url + urlencode(data)
#print(url)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









