






 本文深入解析Hadoop MapReduce的工作原理,包括POM定义、Java业务逻辑实现、运行配置、自定义分区、数据传输优化、combiner机制、性能调优等关键环节,以及MapReduce全局计数器和多程序串联执行的高级应用。
本文深入解析Hadoop MapReduce的工作原理,包括POM定义、Java业务逻辑实现、运行配置、自定义分区、数据传输优化、combiner机制、性能调优等关键环节,以及MapReduce全局计数器和多程序串联执行的高级应用。
1.POM定义
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.hadoop.Mareduce</groupId>
<artifactId>MyWordCount</artifactId>
<version>1.0</version>
<!--必要的依赖-->
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.4</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--主函数入口-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>WordCountDriver</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<!--jdk定义-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
2.编写java实现业务逻辑
Map阶段代码:
创建类继承org.apache.hadoop.mapreduce.Mapper
public class MapperText extends Mapper<keyIn,valueIn,keyOut,valueOut> //><>内填写hadoop封装的数据类型
keyIn表示map阶段每一行的偏移量 LongWritable
valueIn表示map阶段读取的这一行内容 Text
keyOut表示map阶段输出的key字符串内容 Text
valueOut表示map阶段输出的统计次数记为1 LongWritable
hadoop自己封装了数据类型 所在包 org.apache.hadoop.io
int -> IntWritable
String -> Text
Long -> LongWritable
null -> NullWritable
父类Mapper有三个方法
setup();表示初始化方法,只执行一次
map();每读取一行数据调用一次
cleanup();只调用一次,程序结束的时候调用
所以子类需要重写map()这个方法
@Override
protected void map(LongWritable key,Text value,Countext countext){
String line= value.toString();
String[] words = line.split(" ")//按照空格切割一行数据得到单词数组
for(String word:words){
countext.writer(new Text(word),new LongWritable(1));//将每一个单词计数为1写入上下文
}
}
Reduce阶段代码:
创建类继承org.apache.hadoop.mapreduce.Reducer
public class ReduceText extends Reducer<keyIn,valueIn,keyOut,valueOut> //><>内填写hadoop封装的数据类型
keyIn表示map阶段输出的key表示为一个单词 Text 相当于map阶段的keyOut
valueIn表示map阶段读取的这一行内容,表示为这个单词出现的次数1 LongWritable 相当于map阶段的valueOut
keyOut表示聚合的key Text
valueOut表示reduce处理完对集合的key进行统计的值 LongWritable
与Map业务处理过程类似,需要重写reduce方法
reduce是先根据key进行排序,排完序之后根据key的组数调用reduce方法,一组调用一次
reduce阶段原始数据:<hello,1>,<world,1><hello,1>,<spark,1>
排序:<hello,1><hello,1>,<world,1>,<spark,1>
获取组数据<hello,1><hello,1>,分布式获取,一组调用一次reduce
组成迭代器:<hello,[1,1]>
@Override
protected void reduce(Text key,Iterator<LongWritable> values,Countext countext){//values表示迭代器
int count = 0;
for(LongWritable value:values){//迭代求和
count += value.get();
}
countext.writer(key ,new LongWritable(count));//写到上下文
}
3.运行主类
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
//指定配置
Configuration conf = new Configuration();//设定配置
Job job = Job.getInstance(conf);
//指定类
job.setJarByClass(WordCountDriver.class);//指定主类
job.setMapperClass(MapperText.class);//指定Mapper
job.setReducerClass(ReduceText.class);//指定Reduce
//指定数据类型
job.setMapOutputKeyClass(Text.class);//指定map阶段的输出key数据类型
job.setMapOutputValueClass(LongWritable.class);//指定map阶段的输出value数据类型
job.setOutputKeyClass(Text.class);//指定reduce阶段的输出key数据类型
job.setOutputValueClass(LongWritable.class);//指定reduce阶段的输出value数据类型
//指定位置
FileInputFormat.setInputPaths(job, "C:\\1.txt");//指定数据源
FileOutputFormat.setOutputPath(job, new Path("C:\\output"));//指定输出位置
//设置reduceTask
job.setNumReduceTasks(2);//表示两个reduceTask,最终输出两个文件,默认对key使用hashcode取余将数据分区
//提交
boolean status = job.waitForCompletion(true);//job.submit(); 前者是监控状态提交,后者是直接提交
//退出
System.exit(status ? 0 : 1);
}
}
4.集群启动程序
打包到linux运行
hadoop jar text.jar //text为打好的jar名称
5.本地调试启动
异常信息
Exception in thread "main" java.io.IOException: (null) entry in command string: null chmod 0700
1.本机没有安装windows的hadoop环境
2.安装环境后环境的bin目录下缺少winutils.exe文件与libwinutils.lib文件
6.自定义分区
默认分区类 org.apache.hadoop.mapreduce.lib.partition.HashPartitioner
创建一个分区类Partition继承org.apache.hadoop.mapreduce.Partitioner<Text, LongWritable>
重写分区方法(具体业务逻辑)
@Override
public int getPartition(Text text, LongWritable longWritable, int numPartitions) {//表示将a放在第二个分区
if(text.toString().equals("a")){
return 1;
}
return 0;
}
在启动job的时候加入自定义分区配置 job.setPartitionerClass(Partition.class);//传入自定义分区类
mapTask由逻辑切片个数决定task数 reduceTask由程序内部传入值设定,默认为1
分区的个数与reduceTask决定
逻辑切片原则,默认一个文件最小为一个块,当文件大小超过默认块大小的时候就会进行逻辑切片
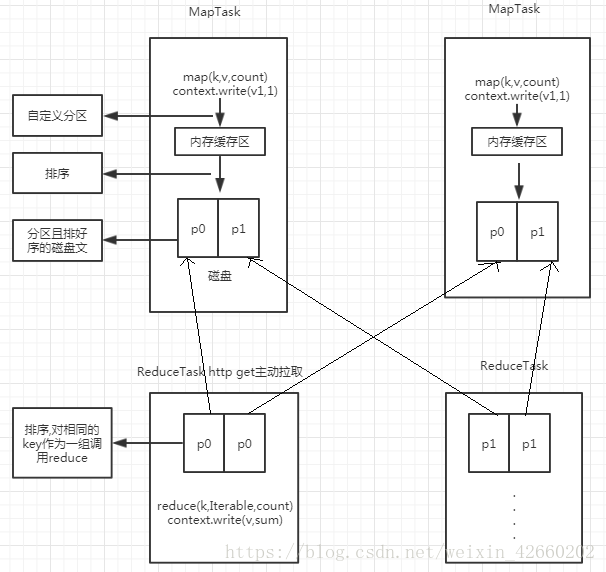
7.底层原理
在Map中上下文对象调用write方法将数据写入缓存区,写入缓存区之前会调用分区方法,给写入缓存区的数据带上一个分区标识
当缓存区的数据达到一定量的时候会按照分区排序好之后刷新到磁盘,最后将磁盘中的所有小文件合并
8.核心
数据传输单词统计使用的字符串与数字,有两个问题,第一个是每传一个数据都会new一个Text对象,占用大量资源,第二个是如果传递的数据是一个bean对象,有多个成员变量,这个使用单词统计的逻辑不能实现
解决第一个问题是将Text对象定义成成员变量,每一次都赋值这个对象的属性
解决第而个问题是将这个bean对象实现mr的序列化接口
bean(含有方法有参无参构造,get,set,toString)
这个对象需要实现mr程序自己自带的序列化接口
定义bean类
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Bean implements Writable{
private Integer up;
private Integer down;
/**
* 序列化
* @param dataOutput
* @throws IOException
*/
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(up);
dataOutput.writeInt(down);
}
/**
* 反序列化,注意反序列化的顺序,先序列化的参数需要先反序列化
* @param dataInput
* @throws IOException
*/
@Override
public void readFields(DataInput dataInput) throws IOException {
this.up = dataInput.readInt();
this.down = dataInput.readInt();
}
get set 构造 toString
.
.
.
}
定义Mapper类
public class MapperText extends Mapper<LongWritable, Text, Text, Bean> {
Text k = new Text();
private Bean value = new Bean();
@Override
protected void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
String[] split = values.toString().split(" ");
k.set(split[0]);
value.setAll(Integer.parseInt(split[1]), Integer.parseInt(split[2]));
context.write(k, value);
}
}
reduce类与Mapper的修改方法类似
主类需要修改变量的类型由LongWritable改Bean
最终输出如果是bean对象,会将toString方法的内容输出
9.按照bean中的某一个值排序
修改bean方法 继承WritableComparable接口,重写compareTo方法
public class Bean implements Writable, WritableComparable<Bean> {
private Integer up;
private Integer down;
/**
* 自定义排序 倒序,由大到小,即负数放在前面
*
* @param o
* @return
*/
@Override
public int compareTo(Bean o) {
return (down + up) - (o.up + o.down) > 0 ? -1 : 1;
}
compareTo方法中会传入下一个bean对象o,返回值位-1表示当前对象放在前面,下一个对象放在后面
10.combiner机制(只有key-value按照key统计求和才能使用,减少网络IO)
在mapTask阶段会产生许多key-value键值对<hello,1><hello,1><world,1>,如果<hello,1>特别多,那么会占用大量网络IO资源
所以在mapTask阶段就可以对这一些数据先做一次统计及<hello,3><world,1>,再把所有mapTask中同一个分区的数据拉取到同一个redis中二次聚合
1.在主类中添加job.setCombinerClass(ReducerText.class);
2.自定义类ReducerText继承Reducer,重写方法实现业务逻辑,与实际的Reducer处理逻辑一样,输入输出参数一样
11.调优
reduceTask性能调优,设置分区计算方法与重写分区数可以改善reduce阶段
task频繁创建与销毁可以设置JVM重用 mapred.job.reuse.jvm.num.tasks 默认1 可以修改大一些,能防止频繁创建与销毁
数据倾斜,使用hash打散
程序conf配置调优:
maperduce.map.memory.mb MapTask使用内存,默认1024 MB
maperduce.reduce.memory.mb ReduceTask使用内存,默认1024 MB
maperduce.map.cpu.mb MapTask使用cpu数,默认1
maperduce.reduce.cpu.mb ReduceTask使用cpu数,默认1
maperduce.map.java.opts MapTask使用JVM参数,例如-Xmx1024m -verbose:gc -Xloggc:/tmp/@taskid@.gc
maperduce.reduce.java.opts ReduceTask使用JVM参数




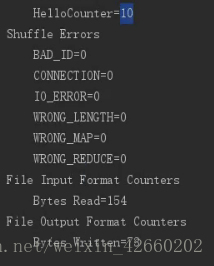
12.mr全局计数器(通常用于统计错误的数据量)
Counter counter = context.getCounter("GroupName", "CounterName");//全局变量,任何地方都可以获取
counter.increment(1);//表示加一,在程序结束的时候会打印这个计数内容
13.多个mr程序串联执行(用于复杂的逻辑,一个mr程序实现不了)
依赖框架JobControl,有缺陷,耦合度高,不容易排查错误,通常使用多个独立的job来调度处理
14.API
获取当前数据所在的文件名称
FileSplit inputSplit = (FileSplit) context.getInputSplit();//获取切片文件 String fileName = inputSplit.getPath().getName();//获取文件名称


















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











