






 本文详细介绍了Flume日志采集系统的架构、组件、安装配置及常见问题解决,包括Source、Sink、Channel的工作原理,如何搭建Flume环境,配置各种场景,并提供了自定义开发指南。
本文详细介绍了Flume日志采集系统的架构、组件、安装配置及常见问题解决,包括Source、Sink、Channel的工作原理,如何搭建Flume环境,配置各种场景,并提供了自定义开发指南。
目录
2. 采集端口数据将部分数据发送到控制台,另一部分发送到其他端口
七. Flume监控工具Ganglia (web gmetad gmod)
1.修改类org.apache.flume.serialization.LineDeserializer
一. Flume简单介绍
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单,由java源码编写,可通过java自定义扩展
Flume 官网地址 各个版本点击下载 下面安装用的是版本1.9.0
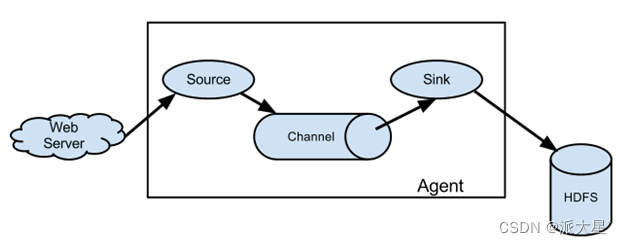
Flume由三部分组成,Source、Channel、Sink
1. Agent
Agent是一个由Flume启动的JVM进程,它以事件的形式将数据从源头送至目的地。Agent主要有3个部分组成,Source、Channel、Sink
2. Source
负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据
3. Sink
不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent
4. Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作
5. Event
传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组
二. 环境安装
解压后修改配置文件
1. 创建日志目录
mkdir <flume_home>/logs2. 修改日志配置文件
vim <flume_hme>/conf/log4j.properties3.修改运行堆内存
mv <flume_hme>/conf/flume-env.sh.template <flume_hme>/conf/flume-env.sh
vim<flume_hme>/conf/flume-env.sh增加缓存Channel 的堆内存
export JAVA_OPTS="-Xms4000m -Xmx4000m -Dcom.sun.management.jmxremote"4. 确定日志打印的位置
#flume.root.logger=DEBUG,console console表示输出到控制台
flume.root.logger=INFO,LOGFILE
flume.log.dir=/home/tools/flume/flume-1.9.0/logs
flume.log.file=flume.log5. 修改flume使用内存 内存调大
vim <flume_home>/bin/flume-ngJAVA_OPTS="-Xms4096m -Xmx4096m -Dcom.sun.management.jmxremote"安装完成
三. 校验flume
使用Flume监听一个端口,收集该端口数据,并打印到控制台
1. 安装netcat工具和net-tools工具
yum install -y nc
yum install net-tools -y2. 判断44444端口是否被占用,选择一个没有被占用的端口用于数据接收
netstat -nlp | grep 444443. 在配置conf目录下创建数据采集的配置文件nc_to_log.conf文件
vim conf/nc_to_log.conf4. 修改配置内容
# 组件定义
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# sources配置
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# sink配置
a1.sinks.k1.type = logger
# channels配置
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 连接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c15. 启动Flume
bin/flume-ng agent -c conf/ -n a1 -f conf/nc_to_log.conf -Dflume.root.logger=console启动命令中 a1是采集数据配置文件中定义的agent的名称
启动参数解释
| --conf/-c | 配置文件存储在conf/目录 系统会去这个目录下 读取系统配置 例如:日志配置 脚本等 |
| --name/-n | 表示给agent起名为a1 |
| --conf-file/-f | flume本次启动读取的agent配置文件 是在conf文件夹下的nc-flume-log.conf文件 |
| -Dflume.root.logger=info,console | -D表示flume运行时动态修改参数覆盖属性值打印控制台 |
6.发送数据验证
nc localhost 44444
四 .各种常用的场景配置
官方文档 点击官 1.9.0
1.组件
# 组件定义 agent为a1 sources为r1,sinks为k1,hannels为c1,可以配置多个例如 sources = r1 r2,使用逗号隔开
a1.sources = r1
a1.channels = c1
a1.sinks = k12. source配置
2.1. 文件source
# 必选 指定类型为文件实时采集
a1.sources.r1.type = TAILDIR
# 必选 指定采集的多个组,每个组个可以对应一个路径
a1.sources.r1.filegroups = f1 f2
# 必选 指定组采集的文件路径,必须精确到文件,可以写匹配表达式匹配多个文件
a1.sources.r1.filegroups.f1 = /home/myuser/data/2022/2022.*.log
a1.sources.r1.filegroups.f2 = /home/myuser/data/2023/2023.*.log
# 可选 断点续传配置
a1.sources.r1.positionFile = /home/myuser/data/tmp/taildir.json2.2 目录source
# 必选 指定类型为目录离线采集,采集整个目录
a1.sources.r1.type = spoolDir
# 必选 指定组采集的目录
a1.sources.r1.spoolDir= /home/myuser/data/2022/2022.*.log
# 可选 采集完成之后文件的文件后缀
a1.sources.r1.fileSuffix = .COMPLETED
# 可选 何时删除采集完成的文件never/immediate 永不/立即
a1.sources.r1.deletePolicy = never
# 可选 采集目录需要传输的文件名称正则表达式
a1.sources.r1.includePattern =
# 可选 采集目录需要跳过的文件名称正则表达式
a1.sources.r1.ignorePattern =
# 可选 轮训新文件的时间间隔
a1.sources.r1.pollDelay = 500
# 可选 是否采集子目录下的文件
a1.sources.r1.recursiveDirectorySearch = false
# 可选 批量传输的条数
a1.sources.r1.batchSize = 100
# 可选 传输字符集
a1.sources.r1.inputCharset = UTF-82.3 kafka source
# 必选 类型为kafka类型
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
# 必选 集群列表
a1.sources.r1.kafka.bootstrap.servers = localhost:9092
# 可选 组id
a1.sources.r1.kafka.consumer.group.id = group_id
# 必选 消费的topiclie列表 逗号分割
a1.sources.r1.kafka.topics = topicName1,topicName2
# 可选 使用正则表达式消费topics列表,与上一个配置2选1
a1.sources.r1.kafka.topics.regex =
# 可选 一批数据量大小
a1.sources.r1.batchSize = 3000
# 可选 一批数据延迟时间
a1.sources.r1.batchDurationMillis = 3000
# 可选 原始数据是否是event的形式,不是就自己封装header,是就复用原始数据的header
a1.sources.r1.useFlumeEventFormat = false2.4 Avro source
# 必选 类型向avro网络端口接收
a1.sources.r1.type = avro
# 必选 发送主机
a1.sources.r1.bind = localhost
# 必选 发送端口
a1.sources.r1.port = 4444
# 可选 数据发送线程数
a1.sources.r1.threads = 42.5 自定义Source
# 必选 实现AbstractSource接口
a1.sources.r1.type = com.filtrer.flume.MySource
# 配置的param参数,可以在自定义实现类中获取
a1.sources.r1.param = message3. channel配置
3.1. 内存 Memory Channel
#必选 channels配置类型为内存
a1.channels.c1.type = memory
#可选 缓存中存储的最大数据量
a1.channels.c1.capacity = 1000
#可选 通道在每个事务中从源获取或提供给接收器的最大事件数
a1.channels.c1.transactionCapacity = 1003.2. 文件 File Channel
# 必选 channels配置类型为文件
a1.channels.c1.type = file
# 可选 缓存位置
a1.channels.c1.checkpointDir = /home/myuser/data/channel/checkpoint
# 可选 是否备份检查点,如果不备份,不用配置备份目录
a1.channels.c1.useDualCheckpoints = true
# 可选 检查点备份的目录
a1.channels.c1.backupCheckpointDir = /home/myuser/data/channel/backup
# 可选 存储日志文件的目录列表
a1.channels.c1.dataDirs = /home/myuser/data/channel/data
# 可选 传输最大支持的事物大小
a1.channels.c1.transactionCapacity = 10000
# 可选 检查点时间间隔 毫秒
a1.channels.c1.checkpointInterval = 30000
# 可选 单个日志文件最大容量
a1.channels.c1.maxFileSize = 21464350713.3. kafka Channel
# 必选 channels配置类型为kafka 接收Source的数据发送到kafka,省去了sink
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
# 必选 kafka集群节点hostname1:port1,hostname2:port2
a1.channels.c1.kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092
# 可选 使用的topic
a1.channels.c1.kafka.topic = topicName
# 可选 true是否以event的形式写入kafka
a1.channels.c1.parseAsFlumeEvent = false4. sink配置
4.1. HDFS sink
# 必选 类型为HDFS
a1.sinks.k1.type = hdfs
# 必选 HDFS存储路径目录,hdfs的HA模式 可以使用hdfs-site.xml文件的dfs.nameservices的名称替换ip:端口需要hdfs的配置目录文件
a1.sinks.k1.hdfs.path = hdfs://node2:8020/flume/%Y%m%d/%H_%M
#a1.sinks.k1.hdfs.path = hdfs://mycluster/flume/%Y%m%d/%H_%M
# 可选 存储文件前缀后缀配置
a1.sinks.k1.hdfs.filePrefix =
a1.sinks.k1.hdfs.fileSuffix = .log
# 可选 临时文件前缀后缀配置
a1.sinks.k1.hdfs.inUsePrefix =
a1.sinks.k1.hdfs.inUseSuffix = .tmp
# 可选 压缩格式 gzip, bzip2, lzo, lzop, snappy
a1.sinks.k1.hdfs.codeC =
# 文件类型 分为二进制文件SequenceFile 文本文件DataStream(不能压缩) CompressedStream(可以压缩)
a1.sinks.k1.hdfs.fileType = DataStream
# 可选 是否将时间记录为sink写入hdfs的时刻
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 可选 临时文件等待多少秒后滚动文件 (滚动含义:将临时文件转化为存储文件,并重新创建临时文件)
a1.sinks.k1.hdfs.rollInterval = 30
# 可选 临时文件大小达到多少字节后滚动,推荐配置一个hdfs块大小
a1.sinks.k1.hdfs.rollSize = 67108864
# 可选 临时文件数据量达到多少条后滚动,0表示与数据量无关
a1.sinks.k1.hdfs.rollCount = 10flume1.9.0连接hadop3.1.3会报错 报错信息为
ERROR - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:459)] process failed
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
这是因为flume内依赖的guava.jar和hadoop内的版本不一致造成的。
查看hadoop安装目录下share/hadoop/common/lib内guava.jar版本与flume安装目录下lib内guava.jar的版本,如果两者不一致,删除版本低的,并拷贝高版本过去。
4.2. 网路端口Avro sink
# 必选 类型为向avro网络端口传输数据
a1.sinks.k1.type = avro
# 必选 传输主机
a1.sinks.k1.hostname = localhost
# 必选 传输端口
a1.sinks.k1.port = 4444
# 可选 批处理数据量
a1.sinks.k1.batch-size = 100
# 可选 第一次连接超时时间(毫秒)
a1.sinks.k1.connect-timeout = 20000
# 可选 传输数据超时时间(毫秒)
a1.sinks.k1.request-timeout = 200004.3. 文件File Roll sink
# 必选 类型为写入本地目录(会生成空文件 不适用)
a1.sinks.k1.type = file_roll
# 必选 写入目录配置
a1.sinks.k1.sink.directory = /home/myuser/data
# 可选 滚动时间间隔
a1.sinks.k1.sink.rollInterval = 30
# 可选 批处理数据量大小
a1.sinks.k1.sink.batchSize = 1004.4. 控制台 sink
# 必选 直接打印到控制台
a1.sinks.k1.type = logger4.5. kafka sink
# 必选 类型kafka
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
# 必选 kafka集群节点hostname1:port1,hostname2:port2
a1.sinks.k1.sink.kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092
# 可选 采集的topic
a1.sinks.k1.sink.kafka.topic = default-flume-topic
# 可选 在一个批处理中处理多少条消息
a1.sinks.k1.sink.flumeBatchSize = 100
# 可选 0/1/-1 忽略响应/主节点写入成功/所有节点写入成功
a1.sinks.k1.sink.kafka.producer.acks = 1
# 可选 原始数据是否是event的形式,不是就自己封装header,是就复用header
a1.sources.r1.useFlumeEventFormat = false4.6. 自定义Sink
# 必选 实现AbstractSink接口,通过getChannel方法获取数据
a1.sinks.k1.type = com.filtrer.flume.MySink
# 配置的param参数,可以在自定义实现类中获取
a1.sinks.k1.param = message5. 组装
5.1. 最简 一对一组装
#sources r1
#channel c1
#sinks k1
# 连接组件 r1-> c1 k1 <- c1 即 r1-> c1 -> k1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c15.2. 一对多组装
# sources r1
# channel c1 c2
# sinks k1 k2
# 数据存两份分别到c1和c2
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c25.3. 路由
通过代码自定义拦截规则路由分发
pom坐标
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>拦截器代码打包上传<flume_home>/lib目录下
package com.filtrer.flume;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.List;
import java.util.Map;
public class MyInterceptor implements Interceptor {
public static class MyBuilder implements Interceptor.Builder{
@Override
public Interceptor build() {return new MyInterceptor();}
@Override
public void configure(Context context) {}
}
@Override
public void initialize() {}
@Override
public Event intercept(Event event) {//配合选择器往header中添加key key的名字叫my_key value有type_number/default default表示默认
byte[] body = event.getBody();//获取数据
Map<String, String> headers = event.getHeaders();//获取header,todo 这里可以用数据时间戳覆盖header中的时间戳解决数据漂移问题
if(body[0] >= '0' && body[0] <= '9'){headers.put("my_key","type_number");}
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
for (Event event : list) {intercept(event);}return list;
}
@Override
public void close() {}
}
# sources r1
# channels c1 c2
# sinks k1 k2
# 连接组件
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
# 可选 对需要发送的channels使用什么分发策略(默认 复制replication)/(路由multiplexing) 配置了路由需要指定路由规则以及规则以及拦截器
a1.sources.r1.selector.type = multiplexing
# 路由规则 my_key 代码中声明了
a1.sources.r1.selector.header = my_key
# 路由1 type_number 代码编写命中规则
a1.sources.r1.selector.mapping.type_number = c1
# 路由2 default 默认未命中的走向
a1.sources.r1.selector.default = c2
# 拦截器名称
a1.sources.r1.interceptors = my_interceptors
# 拦截器对应的class类 将类名中的"."修改为"$" 拦截器只能在source阶段实现
a1.sources.r1.interceptors.my_interceptors.type = com.filtrer.flume.MyInterceptor$MyBuilderFlume支持的数据传输形式
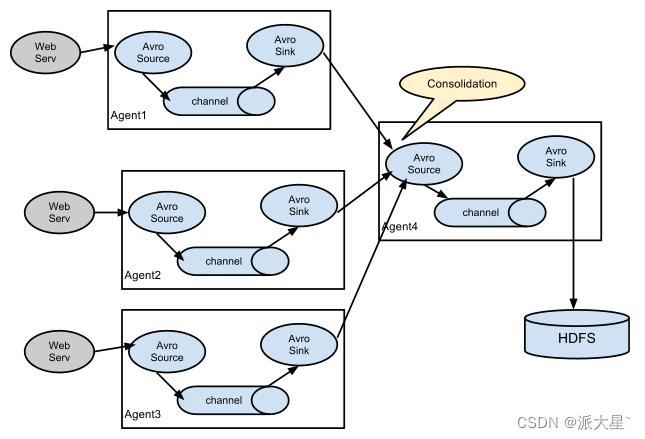
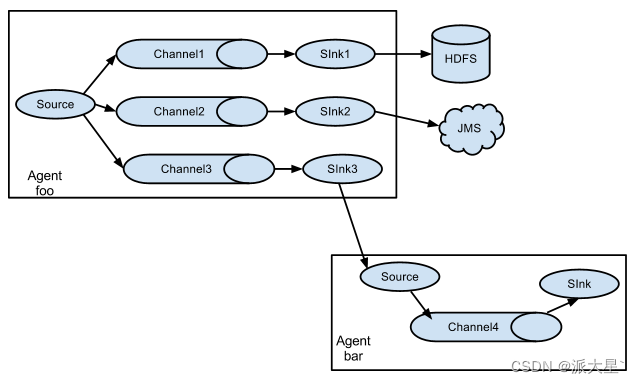
五. 自定义开发
导入pom坐标
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>1.source开发
package com.filtrer.flume;
import org.apache.flume.Context;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.source.AbstractSource;
import java.util.HashMap;
import java.util.UUID;
public class MySource extends AbstractSource implements Configurable, PollableSource {
//定义配置文件将来要读取的字段
private String param;
//初始化配置信息
@Override
public void configure(Context context) {param = context.getString("param", "msg");}
@Override
public Status process() throws EventDeliveryException {
try {
HashMap<String, String> header = new HashMap<>();//创建事件头信息
SimpleEvent event = new SimpleEvent();//创建事件
//循环封装事件
for (int i = 0; i < 100; i++) {
event.setHeaders(header);//给事件设置头信息
event.setBody((param + UUID.randomUUID()).getBytes());//给事件设置内容
getChannelProcessor().processEvent(event);//将事件写入 channel,循环量推荐与transactionCapacity保持一直,默认100
}
} catch (Exception e) {
e.printStackTrace();
return Status.BACKOFF;
}
return Status.READY;
}
@Override
public long getBackOffSleepIncrement() {return 0;}
@Override
public long getMaxBackOffSleepInterval() {return 0;}
}2.sink开发
package com.filtrer.flume;
import org.apache.flume.*;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink;
public class MySink extends AbstractSink implements Configurable {
private String param;
@Override
public void configure(Context context) {
param= context.getString("param", "msg");//获取配置内容并设置默认值
}
@Override
public Status process() throws EventDeliveryException {
Channel channel = getChannel();//获取Channel并开启事务
Transaction transaction = channel.getTransaction();
transaction.begin();
try {
Event event;//抓取数据
while (true) {
event = channel.take();
if (event != null) {break;}
}
//处理数据
System.out.println(String.format("%s %s",param,new String(event.getBody())));
transaction.commit();//提交事务
return Status.READY;
} catch (Exception e) {//异常回滚事物
transaction.rollback();
return Status.BACKOFF;
} finally {
transaction.close();
}
}
}六. 完整示例
1. 采集端口数据到控制台
# 组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
# # 必选 发送主机
a1.sources.r1.bind = node1
# # 必选 发送端口
a1.sources.r1.port = 55555
# # 可选 数据发送线程数
# sink配置
a1.sinks.k1.type = logger
# channels配置
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 连接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2. 采集端口数据将部分数据发送到控制台,另一部分发送到其他端口
# 组件定义
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
# sources配置
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.channels.c1.type = memory
a1.channels.c2.type = memory
a1.sinks.k1.type = logger
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = node1
a1.sinks.k2.port = 55555
# 连接组件
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
# 拦截器
a1.sources.r1.selector.type = multiplexing
# 路由规则 my_key 代码中声明了
a1.sources.r1.selector.header = my_key
# 路由1 type_number 代码编写命中规则
a1.sources.r1.selector.mapping.type_number = c1
# 路由2 default 默认未命中的走向
a1.sources.r1.selector.default = c2
# 拦截器名称
a1.sources.r1.interceptors = my_interceptors
# 拦截器对应的class类 将类名中的"."修改为"$"
a1.sources.r1.interceptors.my_interceptors.type = com.filtrer.flume.MyInterceptor$MyBuilder
七. Flume监控工具Ganglia (web gmetad gmod)
在所有部署flume节点的机器上安装gmod用于采集监控数据,在单独的整体监控节点上安装web gmetad用于整合信息并web可视化
部署方式
| 节点名称 | 部署内容 | host |
| Flume节点1 | gmod flume | node1 |
| Flume节点2 | gmod flume | node2 |
| ...... | gmod flume | node* |
| Flume节点9 | gmod flume | node9 |
| Flume监控节点 | gmod gmetad web | node10 |
1. 部署Flume节点
先在所有要部署的节点上安装epel-release依赖
yum -y install epel-release所有节点安装gmond 并修改配置文件gmond.conf
yum -y install ganglia-gmondvim /etc/ganglia/gmond.conf 修改所有节点的配置内容如下
cluster {
name = "web展示节点的host"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel {
#bind_hostname = yes # Highly recommended, soon to be default.
# This option tells gmond to use a source address
# that resolves to the machine's hostname. Without
# this, the metrics may appear to come from any
# interface and the DNS names associated with
# those IPs will be used to create the RRDs.
# mcast_join = 239.2.11.71
# 数据发送给web展示节点
host = node10
port = 8649
ttl = 1
}
udp_recv_channel {
# mcast_join = 239.2.11.71
port = 8649
# 接收来自任意连接的数据
bind = 0.0.0.0
retry_bind = true
# Size of the UDP buffer. If you are handling lots of metrics you really
# should bump it up to e.g. 10MB or even higher.
# buffer = 10485760
}
2. 部署监控节点
安装
yum -y install ganglia-gmetad
yum -y install ganglia-web
2.1. 修改配置文件ganglia.conf
vim /etc/httpd/conf.d/ganglia.confAlias /ganglia /usr/share/ganglia
<Location /ganglia>
Require all granted
</Location>
2.2. 修改配置文件gmetad
vim /etc/ganglia/gmetad.conf# 修改为当前节点
data_source "node10" node102.3. 修改配置文件config
vim /etc/selinux/configSELINUX=disabled
SELINUXTYPE=targeted2.4. 重启selinux 本次生效关闭必须重启
setenforce 02.5. 赋值ganglia使用权限
chmod -R 777 /var/lib/ganglia3. 启动监控
3.1. 在所有节点上启动gmond
systemctl start gmond3.2. 在web监控节点上启动httpd和gmetad
systemctl start httpd
systemctl start gmetad访问 http://node3/gangliahttp://node3/ganglia
4.发送数据监控结果
监控需要flume启动任务的时候指定监控节点,将flume的信息发送到监控节点上
指定使用什么工具监控 | -Dflume.monitoring.type=ganglia |
| 监控数据发往哪一台节点 | -Dflume.monitoring.hosts=node10:8649 |
bin/flume-ng agent -c conf/ -n a1 -f conf/nc-flume-log.conf -Dflume.monitoring.type=ganglia -Dflume.monitoring.hosts=node10:8649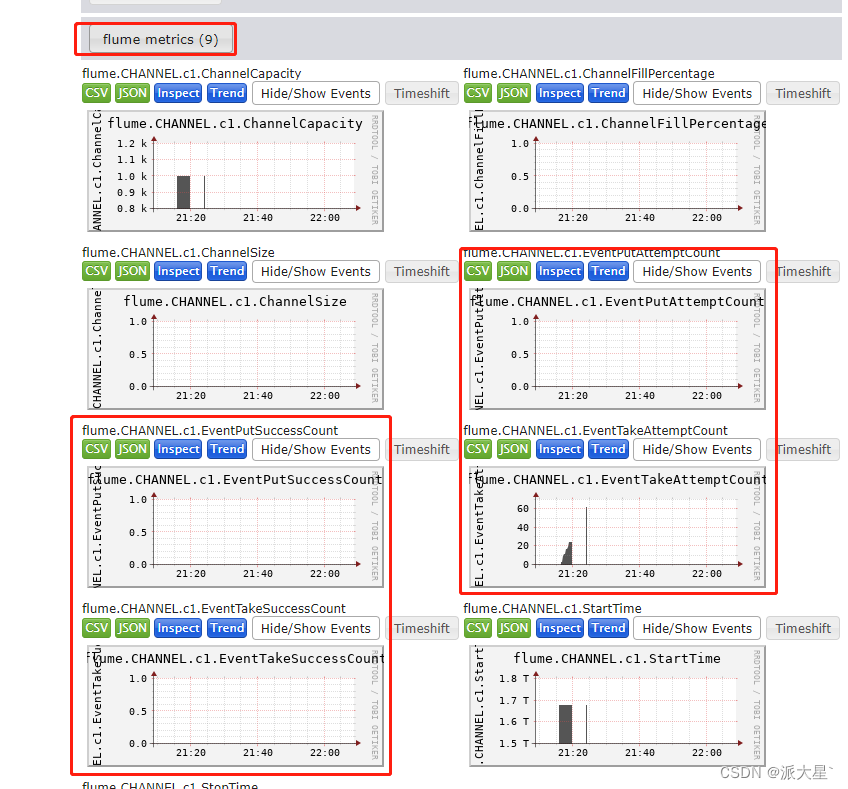
八. 数据传输截断bug
数据传输过程中,一条数据的大小超过默认大下2048字节,这一条数据会被拆成两条数据,导致数据格式异常
处理方法,修改类LineDeserializer
位置 org.apache.flume.serialization.LineDeserializer
1.修改类org.apache.flume.serialization.LineDeserializer
复制LineDeserializer之前的代码,并修改MAXLINE_DFLT参数,数值调大,保证数据不断的长度
2.覆盖flume-ng-core
编译打包后,用这个新包替换linux服务器中 目录<flume_home>/lib下的flume-ng-core包
九. 数据漂移bug
Flume将数据存储在HDFS的时候指定目录给的已日期为单位,如果数据产生时间为23:59:59秒,当数据到达Flume的时间已经是第二天,这是Flume会用第二天的时间作为目录,让第一天的数据进入第二天的目录造成数据漂移,Flume是使用event里面的header中的timestamp时间戳作为目录的依据,所以需要使用拦截器,将header中的时间戳改为数据的时间戳



















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











