



Instruction-Following是语言模型的一项基本能力,它要求模型能够识别指令中最微妙的要求,并将其准确地反映在输出中。
这种能力往往可以通过偏好学习进行优化。然而现有的方法在创建偏好对时通常会直接从模型中采样多个独立的响应,其可能会引入与准确遵循指令无关的内容变化(例如,关于同一语义的不同表达),从而干扰教导模型识别关键差异以改进指令遵循的目标。
鉴于此,清华&智谱研究者们提出了SPAR,构建并整合树搜索自精炼的自博弈框架,从而产生更有效且针对性的偏好对,而免受其它语义干扰。通过自我博弈,LLM采用树搜索策略来完善其之前对指令的响应,同时尽量减少不必要的变化。
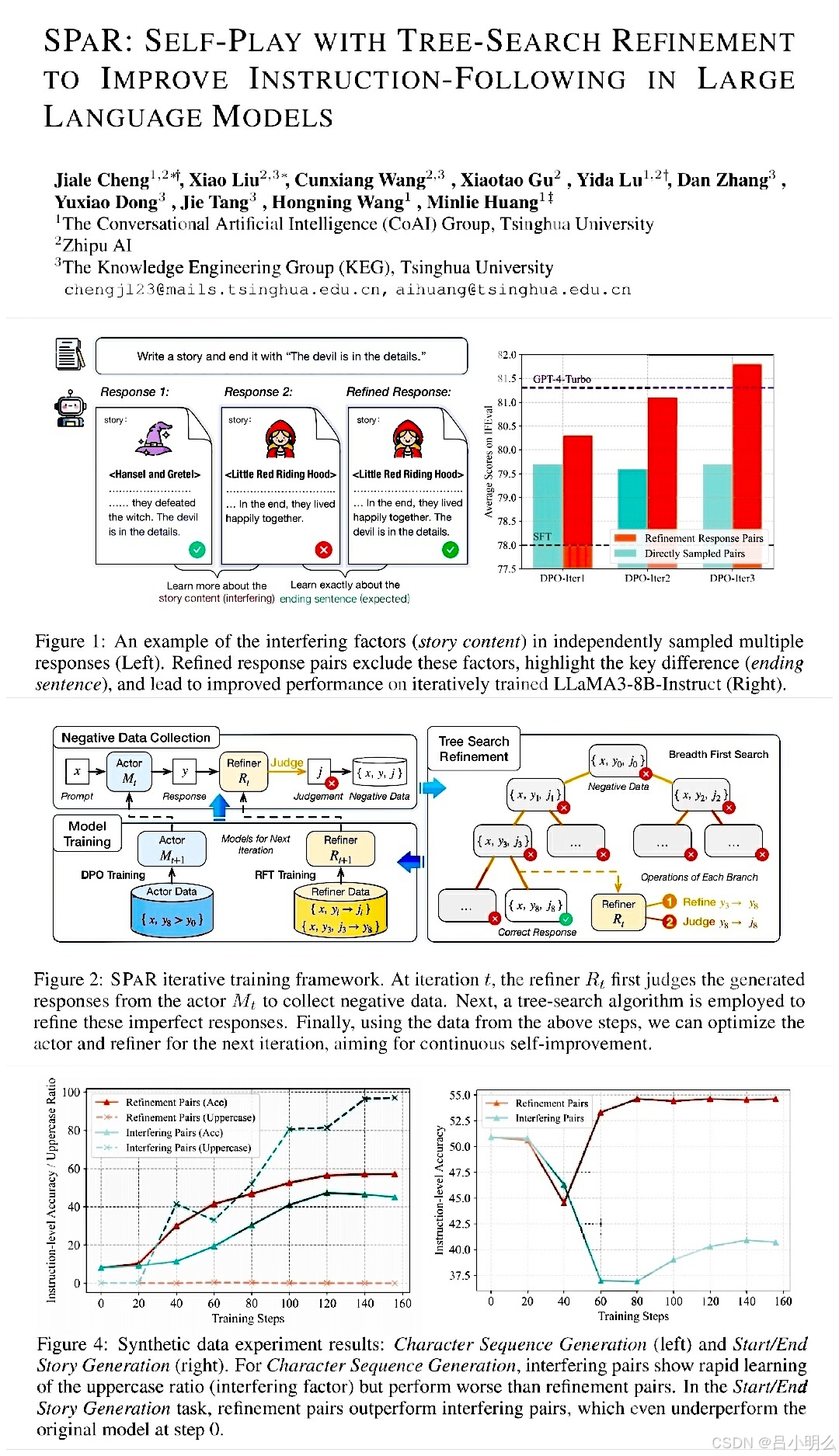
我们知道,在诸多定向复杂推理任务中模型在对上下文的指令遵循过程中的细微差别可能决定其任务执行的最终成败,这也是持续强化偏好作为一种解决途径的学习策略。
传统方法中,通过从目标模型中采样多个独立响应,不可避免的无意中引入了与指令成功遵循更多无关的变化与噪声,其中原因结合不同的任务场景可能涉及多方面:包括在指令在任务领域设置时相对语义熵偏大、上下文情景限定不充分、领域任务可执行空间所处的环境与形式化严格限定等。
如论文中所举的例子:给定指令:“写一个故事并以‘细节决定成败’结尾”,从一个LLM中采样多个独立响应可能会导致像《小红帽》和《汉赛尔与格莱特》这样不同的故事。这种叙事内容的变化会干扰模型学习如何实现关键要求(指定的结尾句子)并最终误导偏好对中的比较。因此,从偏好对中有效学习需要排除这些无关因素,并关注推动成功遵循指令的关键差异。
因此,SPAR框架通过结构化树搜索让LLMs实现自博弈,迭代指导它从细微差别中学习指令遵循。在每一轮自博弈中,一个LLM扮演两个不同的角色:执行者和优化者,它们都从同一个模型初始化。执行者执行复杂指令,而优化者评判并优化执行者的响应。
在迭代过程中,首先收集执行者未能准确遵循指令的响应,从这些失败的响应开始,应用树搜索算法进行精炼,以确保了相对于前一轮采样的精进改进。执行者对指令生成响应,优化者识别不准确的响应(负响应),并通过DPO与RFT方法持续提升执行者与优化者,为下一次迭代做准备。
在我们未来基于llm构建上层原生应用时,不论是相对复杂的Multi-Agent、Work Flow、Copilot多重形式还是OpenAI这种o系长链推理又或是与lean4这种形式化抽象工具的结合,出于对llm原生泛化涌现能力所带来的多样化甚至是某种幻觉的特性本身,也许探索出一种完备且通用的指令遵循增强框架是必要且关键的。
我想这种方法与不久前谷歌DeepMind所提出苏格拉底式自递归增强学习思想有着异曲同工之妙,其更大的意义是通过限定在某一领域树搜索下的持续递归增强,以建立对领域精细泛化分布的框架体系。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









