



随着o1的问世以及在test-time compute趋势下,在提高大型语言模型(LLM)的多步骤推理能力方面,其中通过离线强化学习(offline-RL)方法作为其中一种技术方法甚至形成范式正变得至关重要,这有助于模型快速适应并通过构建全局探索与利用机制匹配复杂任务。
尽管直接偏好优化(DPO)在使LLM与人类偏好一致方面显示出潜力,但它在“多步骤”推理任务的泛化分布以及稀疏奖励反馈上存在着天然的局限性,因为:
(1) DPO依赖于配对偏好数据,而这种数据在多步骤推理任务中并不容易获得;
(2) 它在奖励反馈所主导的策略或价值网络或显或隐式函数过程中对所有过程性步骤或即标记一视同仁,导致在多步骤推理任务中信用分配效果不佳,这些任务通常伴随着稀疏的奖励。
针对于此,清华大学,UC San Diego,Salesforce Research及Northwestern University等研究者近期提出Offline Reinforcement Learning for LLM Multi-Step Reasoning,OREO一种用于促进LLM多步骤推理的离线RL方法,借鉴先前关于最大熵强化学习的研究成果,通过优化软Bellman方程来联合学习策略模型和价值函数,证明了这种方法减少了收集成对数据的需求,并实现了更好的奖励信号分配。
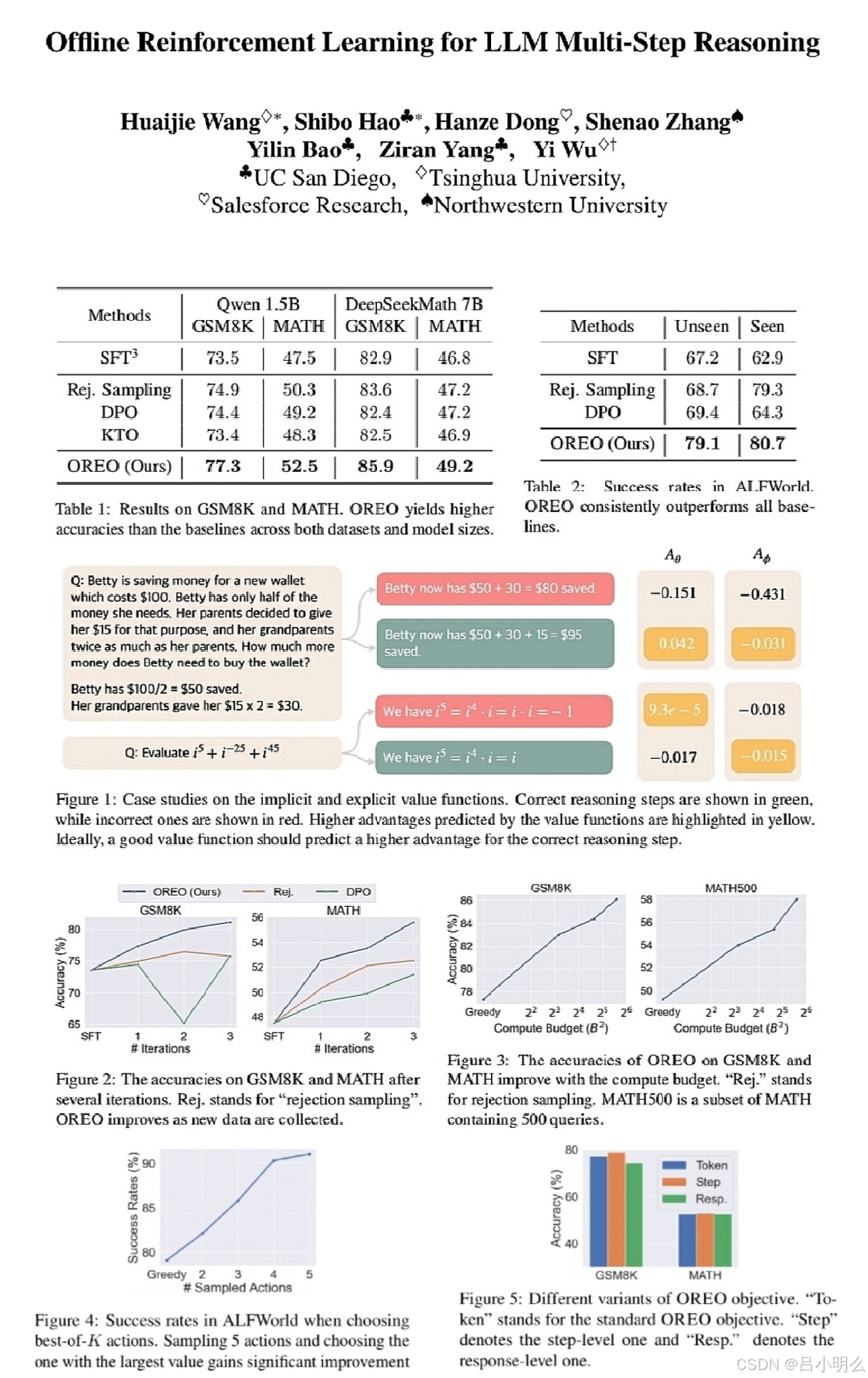
实验证明,OREO在数学推理任务(GSM8K、MATH)和具身智能代理控制(ALFWorld)等多步骤推理基准测试中超越了现有的离线学习方法。当有额外资源时,该方法可以扩展到多迭代框架。此外,学习到的价值函数可以用来指导树搜索,从而进一步提高性能。
我想:OREO通过这种借鉴软soft Q-Learning的思想,其通过优化为soft bellman方程以最大化目标通过引入熵项来鼓励探索并提高学习策略的鲁棒性,从而在步骤级过程中凸现显式价值函数的作用以及和LLM策略合并,并针对稀疏的过程奖励实现推理步骤之间的精细奖励分配这种优化方向为未来深入RL领域持续优化打开了理论探索的又一扇门,也意味着在未来RL领域中其策略与价值网络之间的平衡与统一将有很多可深挖探索的潜在空间与可能。

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









