




简介:Node.js是一个让开发者能够在服务器端使用JavaScript编程的运行环境。在处理文本数据时,iconv-lite作为一个纯JavaScript实现的字符编码转换库,无需C++扩展即可在多种平台上无缝工作。它支持多种常见字符编码,如UTF-8、GBK、BIG5、ISO-8859-1等,并提供直观的使用方法和流处理支持,简化编码转换过程,提升代码的可读性和可维护性。本指南将帮助开发者理解并熟练运用iconv-lite,提高Node.js应用程序的质量。 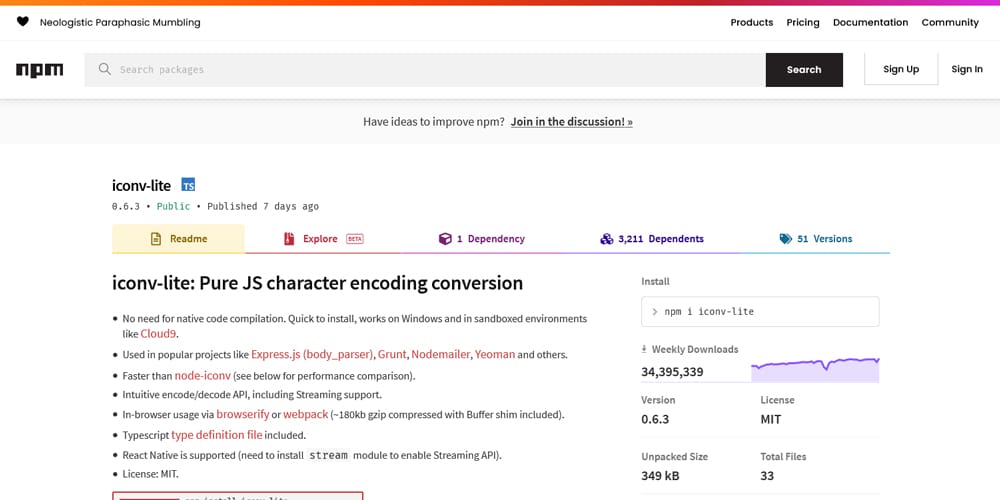
1. Node.js环境下的JavaScript服务器端编程
Node.js 的出现颠覆了传统的服务器端编程方式,它允许开发者使用 JavaScript 在服务器上执行代码,从而能够轻松构建高性能的网络应用。Node.js 的核心是一个事件驱动的非阻塞 I/O 模型,这意味着它能快速响应并发请求,非常适合处理大量短连接,如实时通信应用。
Node.js 的基础架构包括一组核心模块,它们提供构建网络应用所需的基础设施。比如, http 模块可以用来搭建HTTP服务器。通过 require() 函数,开发者可以轻松地引入这些核心模块,并扩展它们的功能。
异步 I/O 是 Node.js 的另一大特性,这主要归功于其背后的事件循环机制。这一机制确保了即使在高负载下,应用也能继续处理请求,而不是被单个耗时操作阻塞。下面是一个简单的 HTTP 服务器搭建示例:
const http = require('http');
const hostname = '***.*.*.*';
const port = 3000;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello World\n');
});
server.listen(port, hostname, () => {
console.log(`Server running at ***${hostname}:${port}/`);
});
在这个例子中,我们创建了一个服务器,它监听本地端口 3000 。任何对这个服务器的 HTTP 请求都会收到一个简单的 "Hello World" 响应。这个例子展示了 Node.js 异步编程模型的一个基础用例,但它仅仅触及了 Node.js 能力的冰山一角。随着章节的深入,我们将探讨更多的高级功能和最佳实践。
2. iconv-lite库的介绍与平台兼容性
iconv-lite库功能特性详解
iconv-lite是一个流行的字符编码转换库,它主要解决了Node.js环境下的字符编码转换问题。与操作系统相关的字符编码转换库不同,iconv-lite使用纯JavaScript实现,确保了其跨平台的特性。这意味着开发者可以无需担心底层平台的差异,因为iconv-lite能在任何支持Node.js的系统上无缝运行。
该库支持的编码转换涵盖了从最常见的UTF-8、GBK,到繁体中文的Big5,再到适用于多种欧洲语言的ISO-8859-1等多种字符编码。它也支持一些较不常见的字符编码转换,如Windows-1251、KOI8-R、IBM866等。
使用iconv-lite进行编码转换的主要优势之一是它能够在内存中高效地完成转换任务,无需额外的转换过程。这对于处理大量文本数据时尤其重要,因为它可以显著减少内存的使用和提升转换速度。
// 示例代码:使用iconv-lite进行编码转换
const iconv = require('iconv-lite');
// 将字符串从UTF-8转换为GBK编码
let utf8Str = '这是一段UTF-8编码的中文字符串';
let gbkBuffer = iconv.encode(utf8Str, 'gbk');
// 将GBK编码的Buffer转换回UTF-8编码的字符串
let utf8StringAgain = iconv.decode(gbkBuffer, 'gbk');
在上述代码中,我们首先使用 iconv.encode 函数将UTF-8编码的字符串转换为GBK编码的Buffer对象,然后再次使用 iconv.decode 函数将GBK编码的Buffer对象还原为UTF-8编码的字符串。这种编码转换过程不仅简洁,而且效率高,不会因为字符编码转换而产生额外的性能损耗。
iconv-lite与平台兼容性
iconv-lite的另一个显著特点是其出色的平台兼容性。由于其代码是完全用JavaScript编写的,无需进行任何本地编译。这就意味着它可以轻易地在不同的操作系统上运行,包括但不限于Windows、Linux和macOS。对多平台兼容性的支持,是它区别于其他依赖本地编译的编码转换库的关键优势。
即便如此,iconv-lite在某些特定的操作系统或Node.js版本上仍然可能遇到兼容性问题。因此,在跨平台开发实践中,我们推荐进行详尽的测试以确保在所有目标平台上都能稳定运行。在实际开发过程中,可能需要根据平台的不同,适当调整代码以解决潜在的兼容性问题。例如,在Windows系统上可能需要额外的配置来处理不同类型的换行符。
// 示例代码:在Windows系统上处理换行符
let rawText = '第一行文本\r\n第二行文本';
let utf8Str = iconv.decode(Buffer.from(rawText, 'binary'), 'utf8')
.replace(/\r/g, ''); // 移除\r,模拟Windows平台的换行符处理
在上述示例中,我们展示了如何在Windows平台上处理文本输入中的CR字符(\r),以确保文本的一致性。尽管iconv-lite默认能够处理跨平台的换行符,但在某些情况下,手动处理仍可能是必要的。
iconv-lite的安装与使用
通过npm安装iconv-lite
npm是Node.js的官方包管理工具,它极大地简化了在Node.js项目中安装和管理第三方库的过程。安装iconv-lite库的过程非常直接,只需要在项目目录下运行npm的安装命令即可:
npm install iconv-lite
这条命令会将iconv-lite库添加到项目的 node_modules 目录,并且会自动更新项目中的 package.json 文件,将iconv-lite作为一个依赖项记录下来。安装完成后,开发者就可以在项目中的任何JavaScript文件中引入并使用iconv-lite了。
解决npm安装时遇到的问题
虽然npm安装过程通常非常顺畅,但有时也会遇到一些问题。常见的问题包括网络连接错误、权限问题、版本冲突等。当遇到这些问题时,需要根据错误信息采取相应的解决措施。
例如,如果遇到网络连接错误,可以尝试切换npm镜像源或者检查网络配置;权限问题可以通过更改npm的全局安装目录的权限或者使用sudo命令解决;版本冲突则需要在 package.json 文件中手动指定依赖库的版本号,或者使用版本管理工具,如nvm,来管理不同项目间的Node.js和npm版本。
测试iconv-lite在不同环境的兼容性
为了确保iconv-lite在不同的运行环境中都能稳定工作,进行跨平台的测试是必不可少的一步。开发者需要创建一个测试用例集,覆盖所有支持的编码格式,以及主要操作系统平台。测试时可以利用持续集成(CI)服务,如Travis CI、GitHub Actions等,来自动化测试过程并记录测试结果。
测试不仅仅是确认iconv-lite能否在特定环境下运行,还要确保转换的准确性和性能表现。在不同平台上,可以比较转换操作所消耗的时间,检查是否在任何平台上都保持了高效的性能。此外,开发者也应当注意到内存使用情况,尤其是在处理大型文件时,以避免因为内存溢出导致程序崩溃。
总结
iconv-lite作为一个完全用JavaScript实现的字符编码转换库,在Node.js项目中有着广泛的应用。它简单易用,功能强大,且拥有出色的跨平台兼容性。通过简单的npm安装和配置,开发者就能在项目中方便地使用iconv-lite进行字符编码转换,解决开发中遇到的编码问题。尽管如此,为了确保在不同环境下的稳定运行,必要的平台兼容性测试和问题解决策略是必不可少的。
3. 多种字符编码格式支持
字符编码是数据处理的基础,不同字符编码之间转换是国际间信息交换的关键技术之一。在Web开发中,尤其是涉及到国际化和本地化的项目,正确的处理和转换各种字符编码格式尤为重要。本章将深入探讨iconv-lite库支持的多种字符编码格式,它们的特点、应用场景以及如何在Node.js环境下使用iconv-lite进行编码转换。
3.1 字符编码格式概述
字符编码(Character Encoding)是将字符集中的字符编排、数字化的过程。它决定了一组字符如何被映射成字节序列。字符编码格式的选择会直接影响数据的存储、传输和显示效果。以下是iconv-lite支持的几种重要字符编码格式及其简要说明:
- UTF-8 : 是Unicode的一种实现方式,兼容ASCII,并且支持世界上绝大多数的文字系统。UTF-8是互联网上使用最广泛的字符编码。
- GBK : 主要用于简体中文Windows操作系统,是中国国家标准的扩展编码,可以看做是GB2312的扩展,支持更多的字符。
- BIG5 : 主要用于繁体中文区,是繁体中文的主要编码方式。
- ISO-8859-1 : 又称Latin-1,它涵盖了西欧语言中使用的拉丁字母,是ISO 8859系列的第一部分,用于多种欧洲语言。
3.2 编码转换的应用场景
不同的应用场景需要选择适合的字符编码,从而确保数据的正确显示和处理。以下是编码转换可能的使用场景:
- 多语言环境的Web应用 : 在这种场景中,服务器需要处理来自不同国家/地区的用户输入,并将内容呈现给不同的用户。正确的字符编码转换能确保不同语言的数据在前端正确显示。
- 数据导入导出 : 当我们需要从外部数据源导入数据或向外部系统导出数据时,数据的编码可能需要转换以匹配目标系统的编码。
- 国际化和本地化 : 应用程序可能需要支持多语言。在处理国际化和本地化时,编码转换是确保文本正确显示的关键步骤。
3.3 使用iconv-lite进行编码转换
iconv-lite库为Node.js提供了方便的编码转换功能。以下是一个使用iconv-lite库将字符串从UTF-8转换为GBK的例子,并将转换结果输出到控制台。
const iconv = require('iconv-lite');
// 假设我们有一个UTF-8编码的字符串
let utf8String = '你好,世界!';
// 使用iconv-lite将字符串从UTF-8编码转换为GBK编码
let gbkBuffer = iconv.encode(utf8String, 'GBK');
console.log('转换后的GBK编码Buffer对象:', gbkBuffer);
3.3.1 代码逻辑逐行解读
-
const iconv = require('iconv-lite');这行代码引入了iconv-lite库。 -
let utf8String = '你好,世界!';定义了一个包含中文字符的UTF-8编码字符串。 -
let gbkBuffer = iconv.encode(utf8String, 'GBK');调用iconv-lite的encode方法将UTF-8编码的字符串转换为GBK编码,并返回一个Buffer对象。这里的Buffer对象包含GBK编码的字节序列。 -
console.log('转换后的GBK编码Buffer对象:', gbkBuffer);将转换后的Buffer对象输出到控制台。
3.3.2 参数说明
-
utf8String: UTF-8编码的原始字符串。 -
'GBK': 目标编码格式。
3.4 支持编码的编码表
iconv-lite通过内置的编码表支持多种编码格式的转换。编码表是一张映射表,它记录了字符与字节序列之间的对应关系。iconv-lite在内部使用这些映射表来执行编码转换操作。下面是一个编码表的简单示例:
| 字符 | UTF-8编码 | GBK编码 | |------|-----------|---------| | 你 | E4 BD A0 | C4 E3 | | 好 | E5 A5 BD | BA BA | | , | E2 80 8B | 2C | | 世 | E4 B8 96 | CA A5 | | 界 | E7 95 8C | BD F5 | | ! | E2 84 97 | 21 |
在进行编码转换时,iconv-lite会查找这个表,找到对应编码,然后构建转换后的Buffer。
3.5 完整的编码转换流程
3.5.1 从文件读取并转换
在实际应用中,我们经常会遇到需要从文件中读取文本内容并进行编码转换的情况。以下是一个完整的流程,从读取文件内容到编码转换,再到输出结果的Node.js代码示例:
const iconv = require('iconv-lite');
const fs = require('fs');
// 从UTF-8编码的文件中读取文本
const utf8Content = fs.readFileSync('example_utf8.txt', 'utf8');
// 将UTF-8编码的内容转换为GBK编码的Buffer对象
const gbkContentBuffer = iconv.encode(utf8Content, 'GBK');
// 将GBK编码的Buffer对象转换回字符串,以便显示
const gbkContentString = iconv.decode(gbkContentBuffer, 'GBK');
// 输出转换后的GBK编码内容
console.log('GBK编码的内容:', gbkContentString);
3.5.2 代码逻辑逐行解读
-
const fs = require('fs');引入Node.js的内置文件系统模块,以便进行文件读写操作。 -
const utf8Content = fs.readFileSync('example_utf8.txt', 'utf8');同步读取名为example_utf8.txt的文件内容,文件内容被假定为UTF-8编码。 -
const gbkContentBuffer = iconv.encode(utf8Content, 'GBK');使用iconv-lite的encode方法将UTF-8编码的字符串转换为GBK编码的Buffer对象。 -
const gbkContentString = iconv.decode(gbkContentBuffer, 'GBK');使用iconv-lite的decode方法将GBK编码的Buffer对象解码回字符串。 -
console.log('GBK编码的内容:', gbkContentString);将转换后的GBK编码内容输出到控制台。
3.6 总结
本章详细介绍了iconv-lite支持的多种字符编码格式,并通过代码示例展示了如何在Node.js环境中进行编码转换。字符编码是网络应用和数据处理中的基础组成部分,正确地使用编码转换功能对于保证数据的准确性和完整性至关重要。通过本章的内容,您应该已经掌握了在Node.js项目中使用iconv-lite库进行基本编码转换的方法,并能够理解这些操作在实际开发中的应用。
4. 如何使用npm安装iconv-lite
Node.js的生态系统中,npm(Node Package Manager)是其中的重要组成部分,它帮助开发者轻松地管理和使用第三方模块。iconv-lite作为一个广受欢迎的字符编码转换库,其安装过程非常简单。本章将引导您了解如何通过npm安装iconv-lite,并解决在安装过程中可能遇到的常见问题。
安装前的准备
在开始安装iconv-lite之前,确保您已经安装了Node.js环境和npm。可以通过以下命令检查Node.js和npm的版本,以确认它们是否安装成功。
node -v
npm -v
如果您的环境中尚未安装Node.js或npm,访问[Node.js官网](***下载安装包进行安装。
使用npm安装iconv-lite
基本安装命令
在Node.js项目目录下打开终端,运行以下命令来安装iconv-lite:
npm install iconv-lite
安装成功后,您将在项目的 node_modules 文件夹中看到iconv-lite,同时在 package.json 文件中会添加iconv-lite为项目依赖。
全局安装
如果您希望在全局环境中安装iconv-lite,以便在任何项目中使用,可以添加 -g 参数:
npm install -g iconv-lite
安装完成后,您可以在命令行中直接使用iconv-lite命令了。
安装过程中的问题及其解决方法
版本冲突问题
有时候,项目中可能会因为依赖的iconv-lite版本不一致而导致冲突。为避免此问题,可以在 package.json 中指定iconv-lite的版本号:
"dependencies": {
"iconv-lite": "^0.4.23"
}
权限问题
在某些操作系统中,可能会遇到权限不足的问题。建议不要使用root用户直接安装npm包。如果是使用Linux或MacOS,可以通过修改npm配置文件或使用 sudo 来解决权限问题:
sudo npm install iconv-lite
网络问题
在某些地区,由于网络限制等原因,可能会遇到无法从npm源下载包的问题。此时,可以考虑使用国内的镜像源,例如淘宝的npm镜像:
npm config set registry ***
之后再尝试安装iconv-lite。
其他问题
如果在安装过程中遇到其他问题,可以查看npm的错误日志。大部分错误日志都会提供一些线索。同时,您也可以访问iconv-lite的[GitHub页面](***来获取帮助或查找解决方案。
验证安装是否成功
安装完成后,可以通过编写一个简单的Node.js脚本来验证iconv-lite是否安装成功:
const iconv = require('iconv-lite');
// 确保iconv-lite已经成功加载
console.log(iconv.decode(Buffer.from([0x48, 0x65, 0x6C, 0x6C, 0x6F]), 'utf-8'));
执行上述脚本,如果输出为"Hello",则表明iconv-lite已成功安装并可以正常使用。
总结
npm是Node.js应用的包管理工具,使用npm安装iconv-lite是维护和开发Node.js项目时不可或缺的一个步骤。本章通过介绍安装前的准备工作、基本安装命令、全局安装以及安装过程中可能遇到的问题及解决方法,让开发者能够顺利地在自己的项目中集成iconv-lite。接下来的章节将介绍如何使用iconv-lite进行编码转换,包括Buffer对象和字符串之间的转换操作。
5. Buffer对象到字符串的编码转换与反向操作示例
Node.js 中的 Buffer 对象是处理二进制数据的桥梁。当我们处理涉及字符编码转换的场景时,经常需要在 Buffer 和字符串之间进行转换。iconv-lite 库为此提供了一种简便的方法来处理这种转换。本章将探讨如何使用 iconv-lite 实现 Buffer 对象和字符串之间的编码转换,包括从 Buffer 到字符串的转换以及从字符串到 Buffer 的反向操作,并将通过具体的示例来展示这一过程。
Buffer 对象与字符串之间的转换
从 Buffer 到字符串的转换
当从网络或其他源接收到了二进制数据时,通常这些数据被存储在 Buffer 对象中。为了进一步处理或展示这些数据,我们需要将它们转换成字符串。以下是使用 iconv-lite 进行这种转换的代码示例:
const iconv = require('iconv-lite');
// 假设 buf 是已经接收的 Buffer 对象
let buf = Buffer.from([0x48, 0x65, 0x6C, 0x6C, 0x6F]);
// 使用 iconv-lite 的 decode 函数进行转换
let str = iconv.decode(buf, 'utf-8');
console.log(str); // 输出:Hello
在这个示例中,我们首先引入了 iconv-lite 库。然后创建了一个包含 "Hello" 字符串 ASCII 值的 Buffer 对象。通过调用 iconv.decode 方法并传入 Buffer 对象和目标编码 'utf-8',我们得到了一个包含对应字符的字符串。
参数说明与逻辑分析
在上述代码中, iconv.decode 方法接受两个参数:第一个参数是 Buffer 对象,第二个参数是目标字符编码。该方法返回一个字符串,表示由 Buffer 对象中的二进制数据转换而来的文本。
从字符串到 Buffer 的转换
与 Buffer 到字符串的转换相反,当我们需要将字符串转换为二进制数据以用于网络传输或文件存储时,我们也需要进行编码转换。以下是实现这种转换的代码示例:
const iconv = require('iconv-lite');
// 假设 str 是需要转换的字符串
let str = 'Hello';
// 使用 iconv-lite 的 encode 函数进行转换
let buf = iconv.encode(str, 'utf-8');
console.log(buf); // 输出 Buffer 对象包含的二进制数据
在这个示例中,我们首先引入了 iconv-lite 库。然后创建了一个表示 "Hello" 的字符串。通过调用 iconv.encode 方法并传入字符串和目标编码 'utf-8',我们得到了一个包含相应 ASCII 值的 Buffer 对象。
参数说明与逻辑分析
iconv.encode 方法同样接受两个参数:第一个参数是需要转换的字符串,第二个参数是目标字符编码。该方法返回一个 Buffer 对象,表示由字符串转换而来的二进制数据。
编码转换过程中的常见问题与解决策略
字符串编码与解码的一致性
在使用 iconv-lite 进行编码转换时,确保源编码和目标编码匹配是关键。如果指定的编码不正确,转换过程中可能会产生乱码或错误。例如:
const iconv = require('iconv-lite');
// 正确的转换
let str = iconv.decode(Buffer.from([0x48, 0x65, 0x6C, 0x6C, 0x6F]), 'utf-8');
console.log(str); // 输出:Hello
// 错误的转换,产生乱码
let str2 = iconv.decode(Buffer.from([0x48, 0x65, 0x6C, 0x6C, 0x6F]), 'gbk');
console.log(str2); // 输出:乱码
在此例中,使用 'utf-8' 作为目标编码可以正确解码 Buffer 对象。如果使用 'gbk',则会得到乱码,因为 'gbk' 编码与源数据中的字节序列不匹配。
编码转换错误的处理
在某些情况下,源数据可能包含一些无法转换为目标编码的字节序列。在这种情况下,iconv-lite 会抛出异常。为了更稳健的处理编码转换,我们应该捕获这些异常,示例如下:
const iconv = require('iconv-lite');
try {
let str = iconv.decode(Buffer.from([0x48, 0x65, 0x6C, 0x6C, 0xFF]), 'utf-8');
} catch (e) {
console.error('转换错误:', e);
// 可以在这里实施错误处理逻辑
}
在这个示例中,我们尝试将一个含有非 'utf-8' 字节序列的 Buffer 对象转换为字符串。由于 '0xFF' 是无效的 'utf-8' 字节,转换过程中会抛出异常。我们通过 try-catch 语句捕获异常并进行处理。
本章小结
在 Node.js 环境下处理二进制数据时,编码转换是一个常见的需求。iconv-lite 库为我们提供了简单而强大的 API 来实现 Buffer 和字符串之间的编码转换。通过实际代码示例,我们演示了从 Buffer 到字符串以及从字符串到 Buffer 的转换过程。通过理解编码转换中的常见问题并采取适当的解决策略,我们可以确保数据在不同编码之间转换的准确性和稳健性。本章的内容为开发者在进行涉及字符编码转换的数据处理时提供了可靠的参考。
6. iconv-lite流处理功能及其在大文件处理中的应用
在处理大文件时,传统的内存处理方式可能会导致内存溢出,特别是对于那些内存受限的系统来说,这是一个严峻的挑战。幸运的是,Node.js与iconv-lite库提供的流处理功能,能够以流的形式逐步处理文件,从而显著减少内存的使用。这使得开发者能够轻松处理大文件,无需担心内存溢出的问题。
6.1 iconv-lite流处理机制
iconv-lite的流处理机制允许开发者对大文件进行逐步的、逐段的处理,避免了将整个文件一次性加载到内存中。这可以通过Node.js的 stream 模块实现,iconv-lite与之完美结合,支持 Readable 和 Writable 流的转换。
示例代码:如何使用iconv-lite进行流式转换
const iconv = require('iconv-lite');
const fs = require('fs');
const stream = require('stream');
// 创建一个可读流
const readStream = fs.createReadStream('input.txt', 'utf8');
// 创建一个iconv-lite的编码转换流
const encodeStream = new stream.Transform({
transform: function(chunk, encoding, callback) {
// 将读取的数据段(chunk)进行编码转换
this.push(iconv.encode(chunk, 'GBK'));
callback();
}
});
// 创建一个可写流
const writeStream = fs.createWriteStream('output.txt', 'GBK');
// 将流连接起来
readStream.pipe(encodeStream).pipe(writeStream);
在上面的示例中,我们首先创建了一个可读流,用于读取源文件 input.txt 。接着,创建了一个iconv-lite的 Transform 流,它会处理所有进入的数据块( chunk ),并使用 iconv.encode 方法将它们转换为GBK编码。最后,我们创建了一个可写流来写入转换后的数据到 output.txt 文件。
6.2 在大文件处理中的应用
流处理在大文件处理中的应用至关重要。例如,当需要转换的文件大小超过服务器内存时,一次性加载整个文件会非常危险。流处理允许我们边读边写,这样可以将内存使用保持在低水平。
实际案例:处理大日志文件
假设我们需要将一个存储了大量用户操作日志的文件从UTF-8编码转换为GBK编码。日志文件非常大,可能达到数GB。传统的处理方法会占用大量内存,甚至导致程序崩溃。这时,我们可以使用流处理来避免这种情况:
// 创建一个可读流
const readStream = fs.createReadStream('large_log_utf8.txt', { encoding: 'utf8' });
// 创建一个iconv-lite的编码转换流
const encodeStream = new stream.Transform({
transform: function(chunk, encoding, callback) {
this.push(iconv.encode(chunk, 'GBK'));
callback();
}
});
// 创建一个可写流
const writeStream = fs.createWriteStream('large_log_gbk.txt', { encoding: 'GBK' });
// 将流连接起来处理大文件
readStream.pipe(encodeStream).pipe(writeStream);
通过上述代码,我们可以有效管理内存使用,同时完成对大文件的编码转换任务。
6.3 性能优化建议
在使用iconv-lite进行流处理时,还可以考虑一些性能优化措施:
- 使用流的管道操作符(
pipe)来简化代码,提高可读性。 - 调整Node.js的事件循环和流的内部缓冲区大小,以适应不同大小的文件处理。
- 利用
--max-old-space-size参数来调整Node.js的内存限制,以处理非常大的文件。
通过这些方法,开发者可以确保程序既高效又稳定地处理大文件。
小结
本章详细解读了iconv-lite流处理功能及其在大文件处理中的应用。通过流式转换,我们可以显著减少内存消耗,有效处理大文件,这对于提高程序的性能和效率至关重要。希望本章的内容能够帮助开发者在处理大型数据集时更加游刃有余。
简介:Node.js是一个让开发者能够在服务器端使用JavaScript编程的运行环境。在处理文本数据时,iconv-lite作为一个纯JavaScript实现的字符编码转换库,无需C++扩展即可在多种平台上无缝工作。它支持多种常见字符编码,如UTF-8、GBK、BIG5、ISO-8859-1等,并提供直观的使用方法和流处理支持,简化编码转换过程,提升代码的可读性和可维护性。本指南将帮助开发者理解并熟练运用iconv-lite,提高Node.js应用程序的质量。


















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









