



 MapReduce理论中,Map的数量增加能提升计算速度,但过多会导致资源浪费。它适合处理Map间关联度不大的数据,而不适合有强关联的数据。Map的逻辑切数据默认128M,MapReduce的Hdfs切块大小不可调。文章还探讨了MapReduce的底层工作原理。
MapReduce理论中,Map的数量增加能提升计算速度,但过多会导致资源浪费。它适合处理Map间关联度不大的数据,而不适合有强关联的数据。Map的逻辑切数据默认128M,MapReduce的Hdfs切块大小不可调。文章还探讨了MapReduce的底层工作原理。
一、MapReduce基础知识
理论上,Map数量越多,程序计算速度也会越快。但是到达一定量级时,就不能在增加了,否则会造成资源的浪费。(因为每次启动Map也需要消耗大量的计算机资源)。
适合MR的应用场景: MR适合进行计算一些各Map之间==关联度不大或者没有关联度的数据==。
不适合MR的应用场景:各Map之间==存在关联==的情况,==不适合使用MR==

MapReduce需要关注successful下面的输出日志: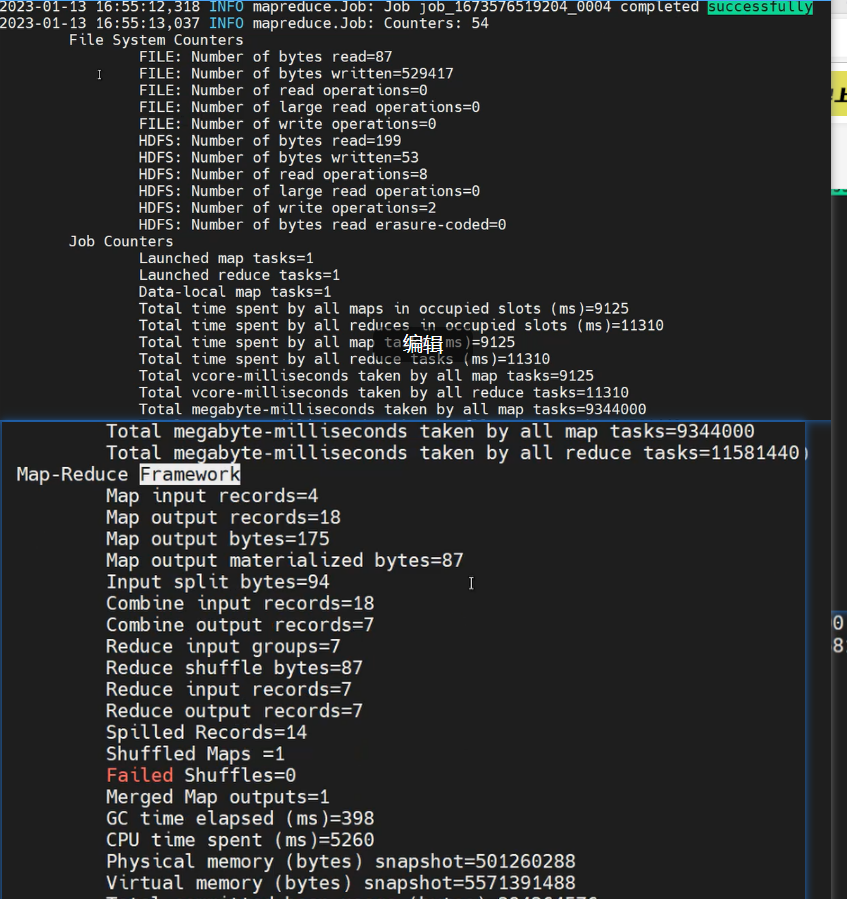
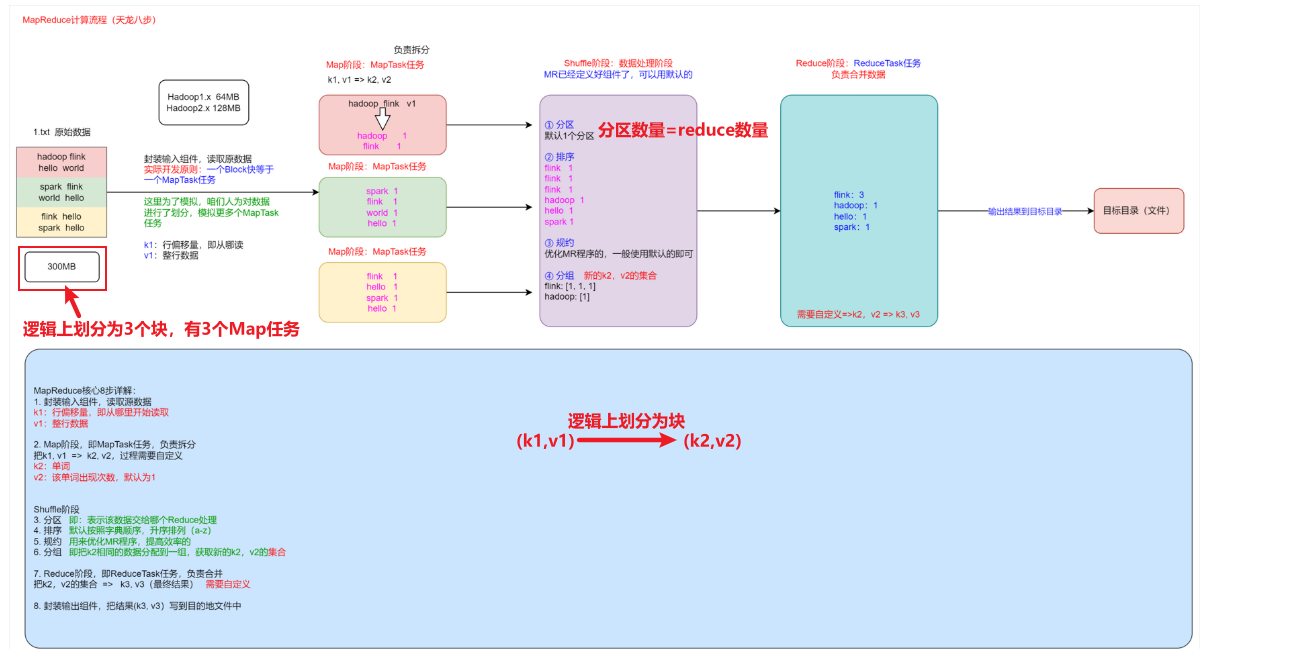
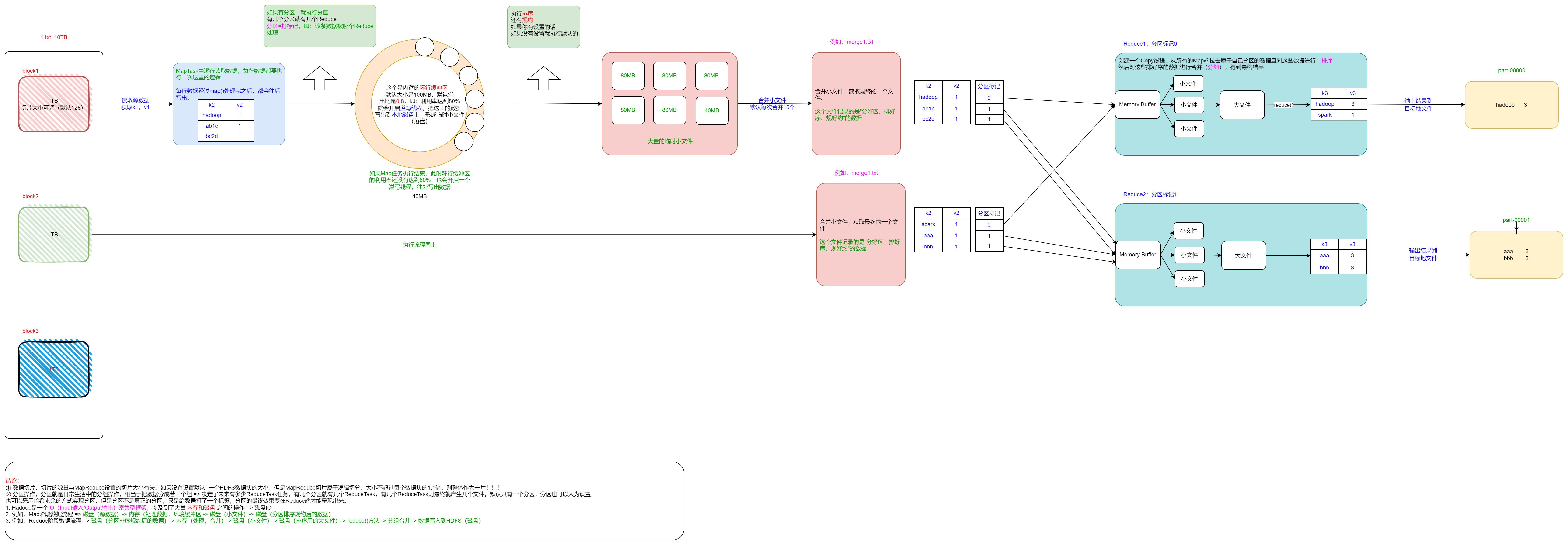
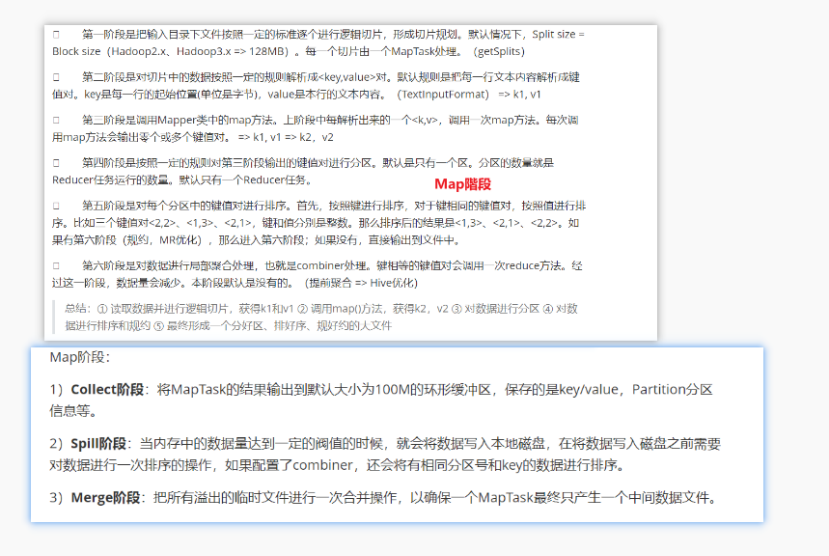
二、MapReduce计算流程(天龙八步)
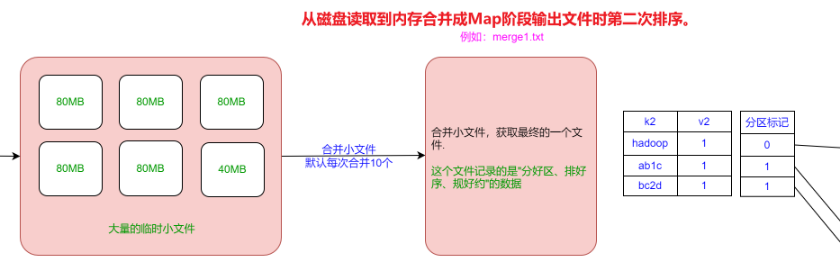
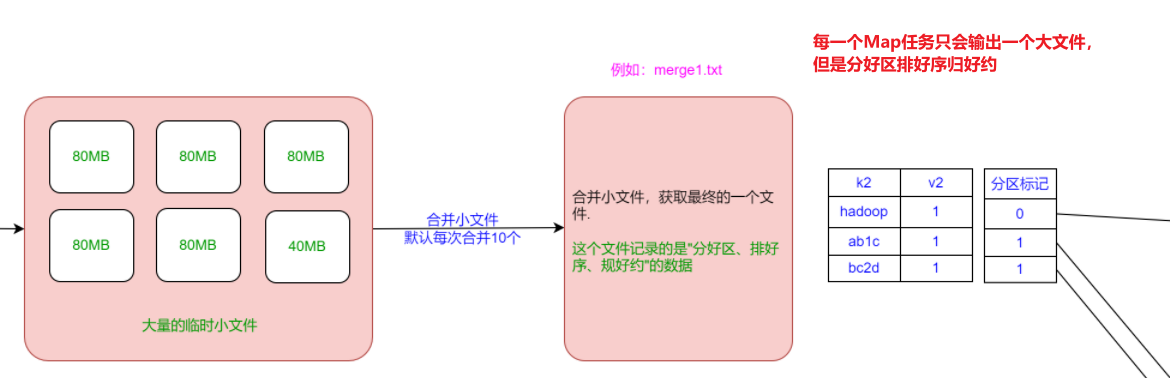
Map逻辑切数据默认128M,可以调;Hdfs12不可调。
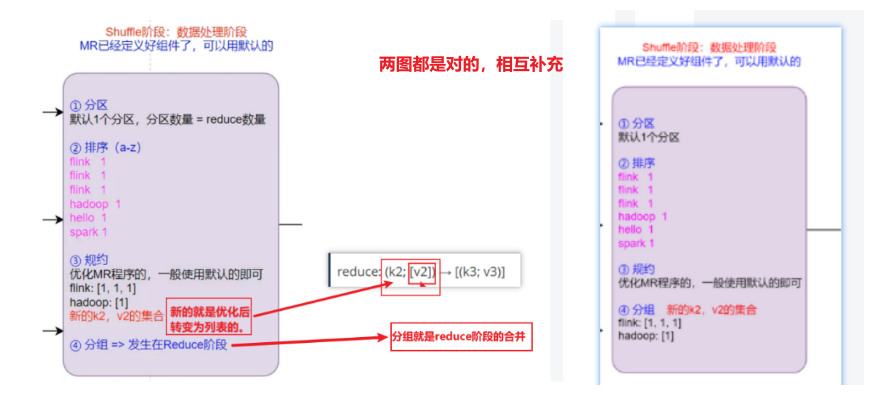
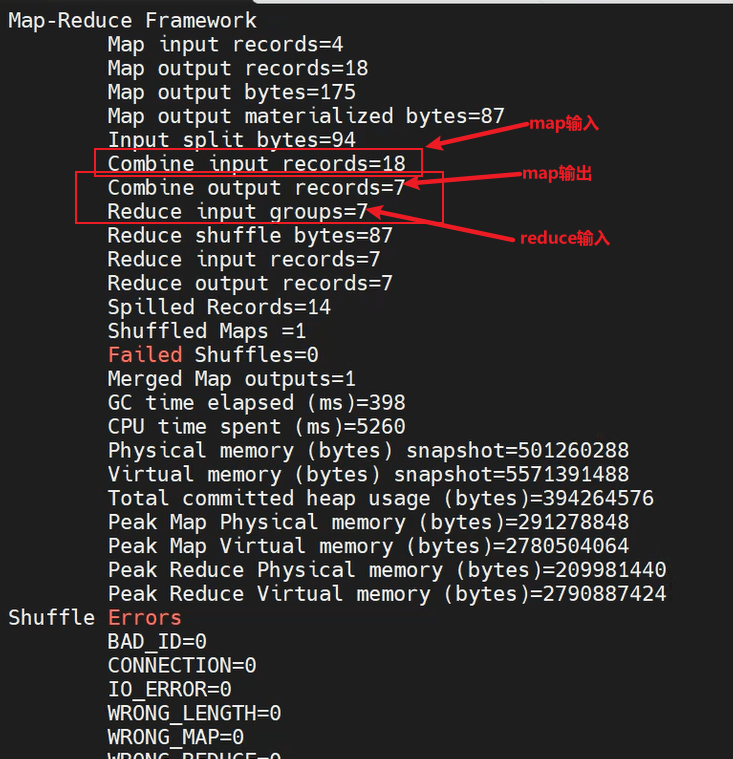

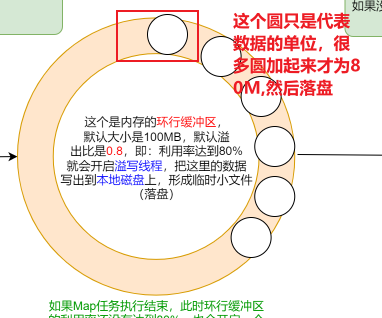
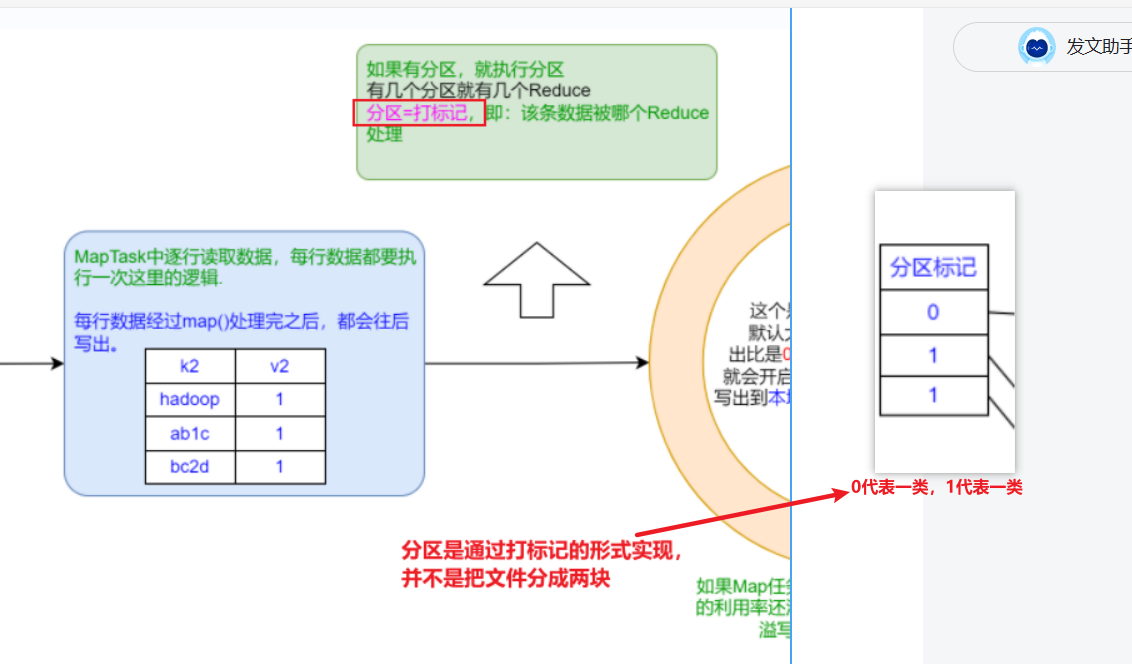
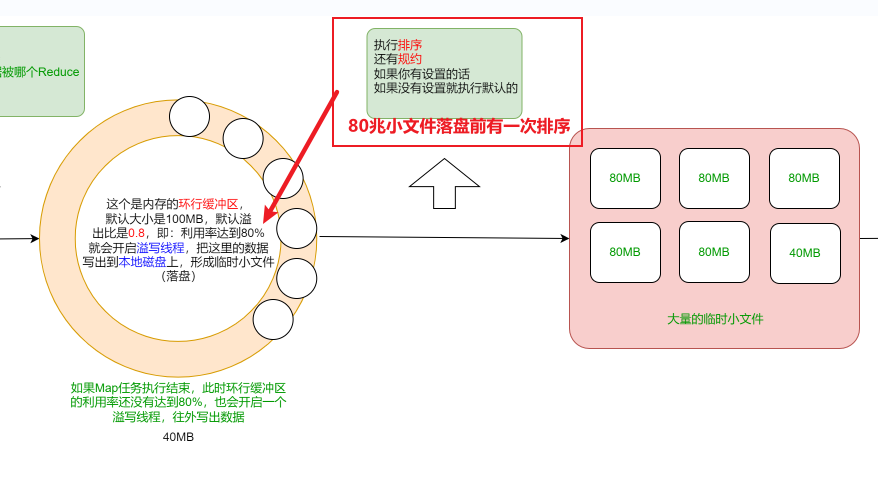
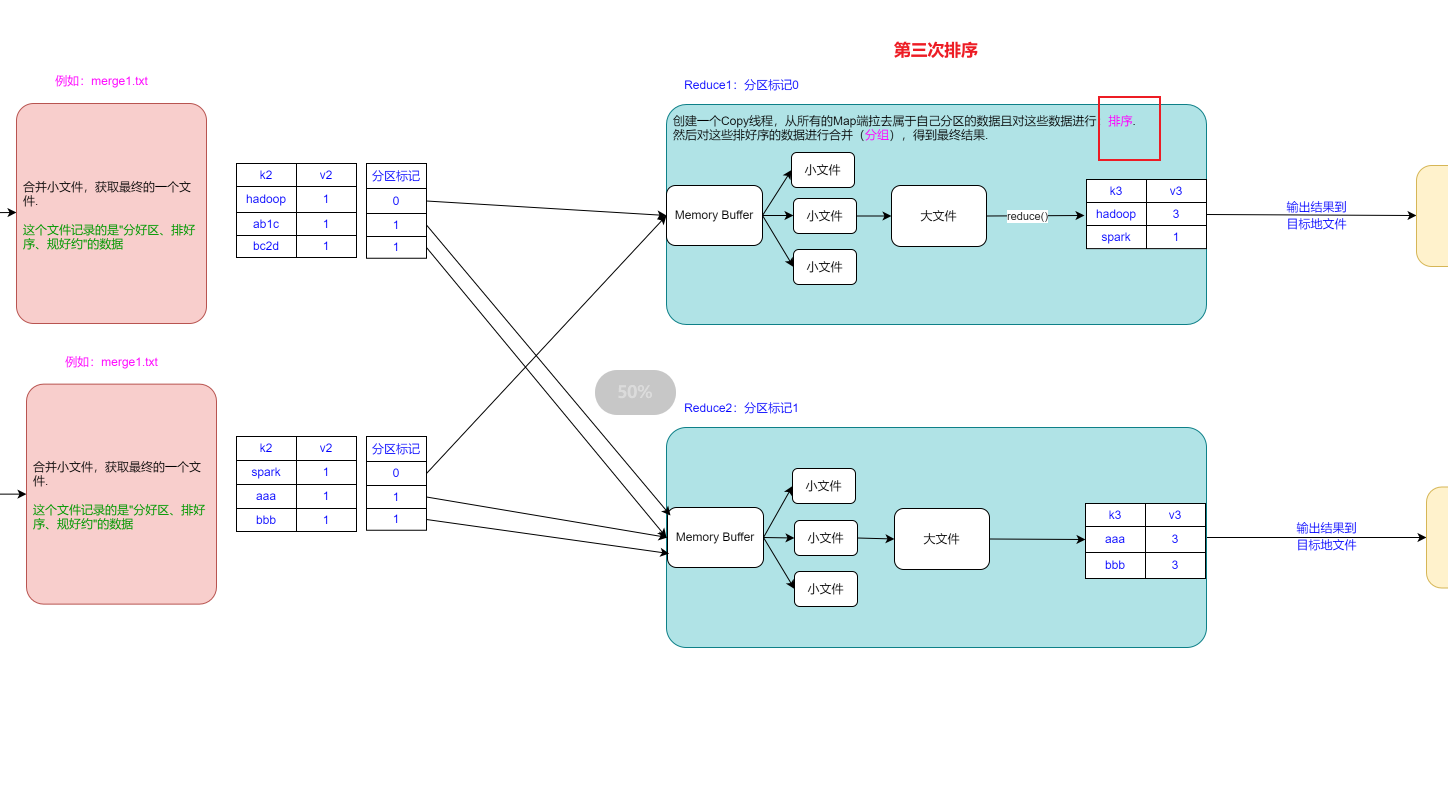
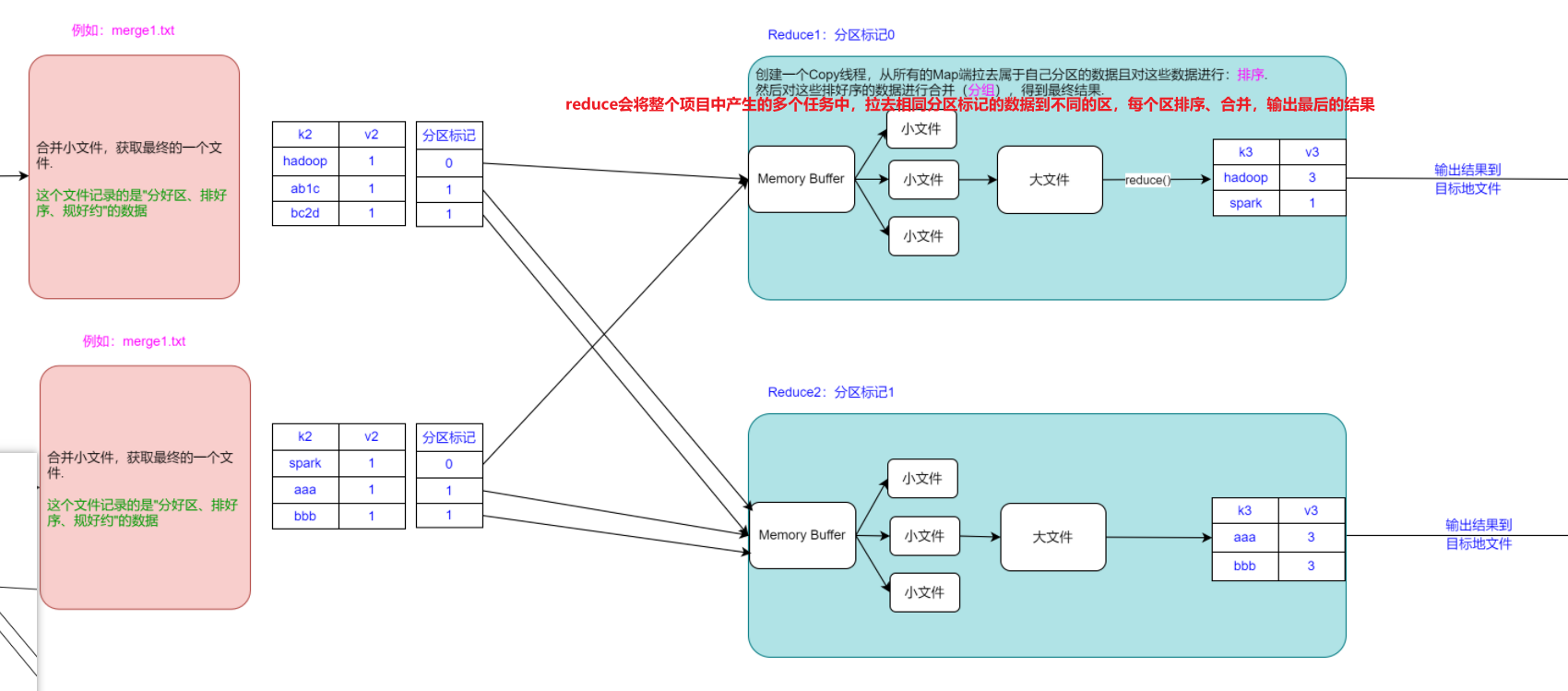
三、MapReduce底层原理




















 2200
2200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









