




简介:Apache Lucene是一款开源全文检索库,本文章详细介绍了Lucene 3.5.0版本的两个核心组件——“lucene-core-3.5.0.jar”和”lukeall-3.5.0.jar”。”lucene-core-3.5.0.jar”提供了索引创建、查询解析等基础功能,”lukeall-3.5.0.jar”则是一个强大的索引浏览器和分析工具。这两者通常一起使用,以确保高效创建和管理索引,以及进行有效的索引检查和调试。掌握这两者的使用对于构建全文搜索引擎和优化搜索性能至关重要。
1. Lucene 3.5.0版本概述
Lucene是一个由Apache软件基金会支持的开源搜索引擎库,广泛应用于全文搜索领域。3.5.0版本是Lucene项目的一个重要里程碑,它不仅包含了对已有功能的增强和改进,还引入了新的特性以满足日益增长的搜索需求。该版本对索引效率和搜索性能进行了优化,增强了对不同语言文本处理的能力,并提供了更多的API扩展点以支持自定义需求。本章将概述Lucene 3.5.0版本的核心特性,为后续章节更深入的技术探讨和应用场景分析奠定基础。
2. lucene-core-3.5.0.jar功能介绍
2.1 Lucene核心库基础
2.1.1 文档索引的基本流程
Lucene是一款开源的全文检索引擎库,为文本数据提供了索引和搜索的功能。在lucene-core-3.5.0.jar中,文档索引的基本流程可以分解为以下几个关键步骤:
- 创建索引器(IndexWriter): 首先需要创建一个索引器对象,它是管理索引创建过程的核心。这个对象负责将文档添加到索引中。
- 创建文档(Document)对象: 对于要索引的每篇文档,需要创建一个Document对象,并为它添加Field(字段)对象。Field对象是实际存储文本信息的地方,通过不同的类型来定义文本数据的处理方式。
- 添加文档到索引: 将Document对象添加到索引器中,Lucene会处理文档,并将其转换成索引格式存储起来。
- 优化和关闭索引器: 在添加了所有需要索引的文档之后,应该对索引进行优化并关闭索引器。这一步骤是为了提高搜索效率和索引安全性。
// 示例代码块展示创建索引的基本流程
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(new File("/path/to/index")), new IndexWriterConfig(Version.LUCENE_35, new WhitespaceAnalyzer(Version.LUCENE_35)));
Document doc = new Document();
doc.add(new Field("id", "1", Field.Store.YES, Field.Index.NOT_ANALYZED));
doc.add(new Field("content", "example text to be indexed", Field.Store.YES, Field.Index.ANALYZED));
indexWriter.addDocument(doc);
indexWriter.optimize();
indexWriter.close();
上述代码块展示了如何使用Java代码创建一个索引器,为一个文档创建索引,并添加到索引库中。其中 IndexWriter 是核心类,负责管理索引的创建。 Document 对象代表了要索引的文档,而 Field 对象则代表了文档中的一个字段。
2.1.2 搜索引擎的基本原理
搜索引擎的基本原理涉及索引创建和搜索执行两个方面。索引创建是搜索引擎工作的第一步,涉及处理原始数据并构建搜索所需的数据结构。搜索执行是利用创建好的索引来快速找到用户查询的相关信息。
在Lucene中,搜索引擎的基本原理可以分为以下几个核心步骤:
- 建立倒排索引: Lucene通过分析文本内容,将其中的词汇创建倒排索引。倒排索引记录了每个词语出现的所有文档,以及它们在文档中的位置等信息。
- 查询处理: 用户输入的查询首先被解析和标准化,转换为搜索引擎可以理解的格式。然后查询被展开,找到所有与查询词语相关的倒排索引项。
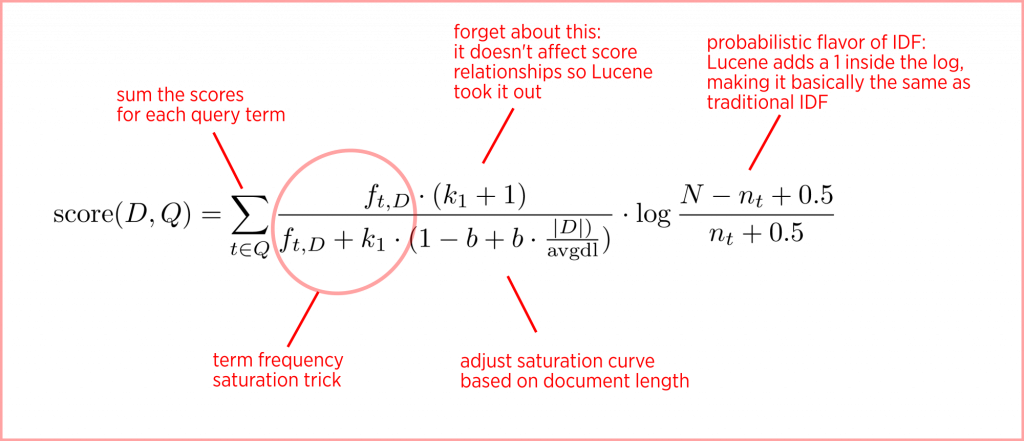
- 相关性计算: 根据索引项和搜索算法计算文档的相关性评分。这通常基于词频、文档频率、字段类型等参数。
- 结果排序和返回: 搜索引擎根据计算出的相关性评分对结果进行排序,然后返回给用户。
// 示例代码块展示使用Lucene进行搜索的过程
IndexSearcher searcher = new IndexSearcher(Directory.open(new File("/path/to/index")));
QueryParser parser = new QueryParser(Version.LUCENE_35, "content", new WhitespaceAnalyzer(Version.LUCENE_35));
Query query = parser.parse("example text");
TopDocs hits = searcher.search(query, null, 10);
for (ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
System.out.println("Found: " + doc.get("id"));
}
searcher.close();
以上代码展示了如何使用Lucene执行一个简单的文本搜索。 IndexSearcher 是用于查询索引的核心类,而 QueryParser 用于将用户的文本查询解析为Lucene可以处理的查询对象。之后,使用 search 方法执行查询并获取结果。
2.2 分析器与语言处理
2.2.1 分析器的工作原理
分析器是处理文本并将其转换为可索引形式的组件。它的工作流程包括分词(tokenization),小写转换,停用词过滤和词干提取等。
- 分词: 将文本分割为一系列的词项(token),这些词项可以被索引。
- 小写转换: 为了使索引不受大小写影响,分析器会将所有词项转换为小写。
- 停用词过滤: 常见但是对搜索结果的区分度影响不大的词(如“的”,“是”等)被过滤掉。
- 词干提取: 把单词还原为其词根形式。
// 示例代码块展示使用Lucene的StandardAnalyzer
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_35);
TokenStream stream = analyzer.tokenStream("contents", new StringReader("This is an example text."));
CharTermAttribute term = stream.getAttribute(CharTermAttribute.class);
stream.reset();
while (stream.incrementToken()) {
System.out.println(term.toString());
}
stream.close();
在上述代码块中, StandardAnalyzer 是一个常用的分析器,它可以处理英文文本。通过 tokenStream 方法获取 TokenStream 实例,然后通过循环读取每一个token,这里使用了 CharTermAttribute 来获取当前的词项。
2.2.2 支持的语言分析器及特性
Lucene提供了多语言的分析器,以便适应不同语言的特性。这些分析器包括英语、法语、德语等,每一个分析器都考虑了对应语言的特殊规则和停用词等。
例如, FrenchAnalyzer 适合处理法语文本数据。它支持法语特有的词干提取和小写转换等处理方式。而 RussianAnalyzer 则适用于俄语文本,提供了相应的语言特性处理。
Lucene 3.5.0还支持自定义分析器,可以按照特定需求组合不同的分析组件(如分词器、过滤器等),从而为特殊应用场景提供定制化的解决方案。
// 示例代码块展示创建自定义分析器
Analyzer customAnalyzer = new Analyzer() {
@Override
protected TokenStreamComponents createComponents(String fieldName) {
Tokenizer source = new StandardTokenizer(Version.LUCENE_35);
TokenFilter filter = new StopFilter(Version.LUCENE_35, source, StopAnalyzer.ENGLISH_STOP_WORDS_SET);
return new TokenStreamComponents(source, filter);
}
};
上述代码通过继承 Analyzer 类,创建了一个简单的自定义分析器,它使用了 StandardTokenizer 和 StopFilter 。通过这种方式,可以灵活地添加更多的过滤器或自定义组件,构建出完全符合需求的分析器。
2.3 索引和搜索的高级特性
2.3.1 索引的读写机制
Lucene索引采用的是基于磁盘的存储机制,索引结构的每个部分都被设计为可以单独读写。它使用了一套复杂的文件系统来优化存储和检索速度。
- 段(segmentation): Lucene索引被分割成多个段,每个段包含一组文档。段是独立搜索的,可以实现高效的增量更新和查询。
- 合并(merging): 在一定条件下,Lucene会将多个小段合并为一个大段,减少段的数量,从而提升查询效率。
- 写入策略: Lucene支持即时写入(flush)和后台合并写入(optimize),以平衡索引更新速度和搜索性能。
// 示例代码块展示Lucene索引的写入机制
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_35, new WhitespaceAnalyzer(Version.LUCENE_35));
config.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
try (IndexWriter writer = new IndexWriter(FSDirectory.open(new File("/path/to/index")), config)) {
writer.addDocument(doc);
// 可选: 使用optimize方法来合并段,优化索引性能
writer.forceMerge(1);
}
在这段示例代码中, IndexWriter 控制了索引的写入操作。通过配置 IndexWriterConfig ,可以设置索引的打开模式,决定是创建一个新索引还是向现有索引添加内容。还可以在必要时调用 forceMerge 方法来合并段,优化索引性能。
2.3.2 搜索优化技术
为了提高搜索性能,Lucene提供了多种搜索优化技术,包括但不限于相关性评分、缓存机制、查询展开等。
- 相关性评分: Lucene使用向量空间模型(VSM)来计算查询和文档之间的相似度,影响排名。
- 缓存机制: Lucene提供了多种缓存机制,例如过滤器缓存和查询结果缓存,用于加速搜索。
- 查询展开: Lucene支持查询展开技术,如短语搜索和通配符搜索,提高用户查询的灵活性。
// 示例代码块展示Lucene搜索的优化技术
IndexSearcher searcher = new IndexSearcher(Directory.open(new File("/path/to/index")));
BooleanClause.Occur[] flags = {BooleanClause.Occur.SHOULD, BooleanClause.Occur.MUST};
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(new TermQuery(new Term("field1", "value1")), flags[0]);
builder.add(new TermQuery(new Term("field2", "value2")), flags[1]);
TopDocs hits = searcher.search(builder.build(), 10);
for (ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
System.out.println("Found: " + doc.get("id"));
}
searcher.close();
在这段代码中,使用了 BooleanQuery 来构建一个包含多个条件的复杂查询,并且可以为每个条件指定在布尔查询中的作用(必须、应该或禁止)。这为复杂的查询需求提供了灵活性,并且通过精确控制这些条件,可以优化搜索结果的相关性和排名。
此外,Lucene还提供了对查询结果的缓存机制,可以通过配置 IndexSearcher 对象来实现。例如,查询缓存可以用来存储之前执行过的查询结果,如果相同的查询再次执行,可以直接从缓存中获取结果,极大地提升了搜索性能。
以上内容仅涵盖部分lucene-core-3.5.0.jar核心功能的高级特性。在实际应用中,您还可以探索诸如查询性能分析器、自定义评分算法、查询缓存策略等优化技术,以获得更好的搜索体验和性能。
3. lukeall-3.5.0.jar功能介绍
3.1 LukeAll工具概述
3.1.1 LukeAll工具的主要功能
LukeAll工具是由Lucene的开发团队提供的一款强大的索引浏览器,它能够让开发者深入地查看和分析Lucene索引的内容。该工具不仅仅提供了直观的图形用户界面,还可以直接对索引文件进行操作,包括查看、修改和优化等。
使用LukeAll,开发者可以浏览索引结构,查看索引文件的详细信息如文档数、字段信息等。它还支持搜索索引内容,可以使用不同的查询语言,如Lucene的查询语法。该工具也能够查看文档中各个字段的详细索引情况,例如倒排列表、项频率、词向量等。
此外,LukeAll还具备检查索引完整性的功能,能够发现潜在的错误并帮助修复这些问题。它提供了调试功能,开发者可以用它来诊断和解决问题,同时对索引性能进行分析和优化。
3.1.2 与其他工具的对比分析
与LukeAll相似的工具,比如Lucene自带的Index Toolbox,虽然在功能上较为基础,但足以完成一些简单的索引操作,如查看文档数、删除文档等。
然而,LukeAll在许多方面都超越了这些基础工具。首先,它的图形用户界面比命令行工具更加直观易用,便于用户理解索引的复杂结构。其次,LukeAll支持多种查询语言,并且提供了多种索引分析和优化工具,使其成为功能最为强大的Lucene索引浏览器之一。
对比其他第三方的索引管理工具,如Elasticsearch的Head插件,LukeAll更加专注于Lucene底层索引的查看与维护,而不依赖于特定的搜索引擎。这对于想要深入研究Lucene底层机制的开发者来说,是非常有价值的一个工具。
3.2 索引浏览器的使用方法
3.2.1 索引内容的查看技巧
要使用LukeAll查看索引内容,首先需要启动LukeAll应用程序,并加载目标Lucene索引文件。在打开的主界面中,索引的总体信息会立即显示出来,包括索引的文档数量、字段统计、最大文档ID等。
深入到各个字段查看时,可以展开字段列表,然后对特定字段展开子项。LukeAll会显示包括词条、频率、词向量等在内的详细信息。例如,想要查看一个名为”title”的字段时,可以展开”title”条目,然后选择“Terms”来查看所有词条,或者选择“Documents”来查看哪些文档包含该字段。
在查看词条时,可以使用通配符或者正则表达式来过滤感兴趣的词条。此外,对于想要查看的特定文档,可以通过文档ID或者特定字段的值来搜索。LukeAll支持多种字段搜索,如等值搜索、范围搜索等。
3.2.2 索引结构的分析和优化
LukeAll不仅能够帮助开发者查看索引内容,还提供了分析索引结构的功能。通过查看索引中的“Field Info”和“Document Structure”,开发者可以获得字段数据类型、字段统计信息、文档结构等信息。
当进行索引优化时,可以利用LukeAll分析索引的健康状态,查看是否有碎片化现象,如过多的小段落(segment)生成。LukeAll提供了合并段落的功能,可以有效地减少段落数量,优化索引结构。
开发者还可以使用LukeAll查看和分析索引中每个字段的词频统计,这对于决定是否使用term boosts(词条提升)等高级特性来优化搜索结果是非常有帮助的。LukeAll工具中的这些高级分析功能为索引优化和性能调优提供了强大的支持。
3.3 索引调试与维护
3.3.1 索引完整性的检查
在使用LukeAll进行索引完整性的检查时,可以通过“Tools”菜单访问索引检查工具。这个工具能够检测索引中可能存在的问题,如丢失的段落、损坏的词条等。检查过程中,LukeAll会报告发现的所有问题,并提供修复建议。
检查索引时,LukeAll会遍历索引中的所有段落,对每个段落进行扫描,并对比索引的主目录信息。如果发现不一致的数据,LukeAll会报告出来。例如,如果一个词条在某个段落的倒排列表中出现,但在主目录中没有记录,那么这个词条就可能丢失。
开发者可以手动修复这些问题,也可以让LukeAll自动尝试修复。值得注意的是,索引的修复操作可能会改变索引的内容,因此在执行修复之前,建议备份原始索引。
3.3.2 索引修复与优化实例
使用LukeAll进行索引修复之前,最好先对索引进行备份,以防在修复过程中出现不可预见的错误导致数据丢失。在LukeAll中备份索引很简单,只需选择要备份的索引,并使用“File”菜单中的“Save As”选项即可。
当确定要对索引进行修复时,可以使用LukeAll提供的“Fix”功能。在修复过程中,LukeAll会将丢失的段落合并到主目录中,修复损坏的词条,并清理无效的段落。在修复完成后,LukeAll会显示修复报告,展示修复了哪些问题。
索引优化是一个持续的过程。修复完成后,可以使用LukeAll中的合并功能来优化索引。通过选择需要合并的段落并执行合并,可以减少段落数量,提高索引的搜索效率。
下面的表格列出了在进行索引修复和优化时需要关注的一些关键步骤:
| 步骤 | 描述 |
|---|---|
| 1 | 备份索引以防止数据丢失。 |
| 2 | 使用LukeAll打开有问题的索引文件。 |
| 3 | 进行索引完整性检查并记录报告。 |
| 4 | 根据报告决定是否需要手动修复或让LukeAll自动修复。 |
| 5 | 修复完成后,再次检查索引确认问题已解决。 |
| 6 | 使用LukeAll的段落合并功能优化索引。 |
| 7 | 最后,再次进行完整性和性能测试,确保索引正常工作。 |
通过上述步骤,开发者可以有效地利用LukeAll工具来维护和优化Lucene索引,确保索引的健康和性能。
4. 索引创建与管理实践
索引的创建和管理是任何搜索引擎应用的核心部分。本章节将深入探讨使用 Lucene 核心库创建索引的步骤,同时分享索引策略和管理技巧,以及索引的备份与恢复的最佳实践。
4.1 实践:使用lucene-core创建索引
4.1.1 文档的添加和更新
在 Lucene 中,一个文档(Document)通常对应一个要索引的单元,比如一条记录或一个页面。添加或更新文档主要涉及以下几个步骤:
- 创建一个
Document对象。 - 向
Document中添加Field对象,指定字段名(name)、值(value)以及字段类型(Store、Index、TermVector等选项)。 - 创建一个
IndexWriter对象,用于管理索引的写操作。 - 使用
IndexWriter的addDocument方法添加Document到索引中。 - 对于更新操作,可使用
IndexWriter的updateDocument或deleteDocuments与addDocument组合实现。
下面是添加文档的简单示例代码:
// 创建一个Document对象
Document doc = new Document();
// 向Document中添加Field对象
doc.add(new TextField("title", "Lucene in Action", Field.Store.YES));
doc.add(new StringField("isbn", "193398817", Field.Store.YES));
// ...添加其他字段
// 创建IndexWriter配置
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35));
iwc.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND); // 设置为创建或追加模式
// 创建IndexWriter对象
try (IndexWriter writer = new IndexWriter(FSDirectory.open(new File("/path/to/index")), iwc)) {
writer.addDocument(doc); // 添加文档到索引
}
4.1.2 批量索引的实现和注意事项
批量索引能有效提升索引创建的效率,减少对文件系统的写操作次数,适用于索引大量数据的场景。使用Lucene的 IndexWriter 可以方便地实现批量索引。具体方法是在同一个 IndexWriter 对象上连续调用 addDocument 方法。
注意事项包括:
- 确保索引操作不会超出JVM内存限制。
- 合理使用事务控制,例如
commit()方法,以避免数据丢失。 - 考虑在后台线程中执行索引操作,避免影响前端服务的响应时间。
- 定期使用
optimize()方法整理索引,减少索引碎片化。
4.2 索引策略与管理技巧
4.2.1 索引版本控制的策略
随着应用的发展,索引的结构和内容可能会发生变化。版本控制对于管理索引的变更至关重要,它有助于维护数据的一致性并支持向后兼容。Lucene本身不提供内置的版本控制机制,但可以通过外部策略实现。
一种常见的策略是使用不同的索引目录来区分版本。例如,可以在索引目录的命名中加入时间戳或版本号。当索引结构发生变化时,创建一个新的目录来存放新版本的索引。在服务部署时,可以通过配置文件来指定使用的索引目录,从而实现版本切换。
4.2.2 索引存储的最佳实践
索引的存储关乎性能和成本。以下是一些最佳实践:
- 使用SSD而不是传统的HDD来存储索引,以减少查询延迟。
- 确保索引目录具有足够的I/O性能,以支持高并发读写请求。
- 定期进行索引备份,以防止数据丢失。
- 对于非常大的索引,可以考虑分片存储,以便于维护和分布式查询。
4.3 索引的备份与恢复
4.3.1 索引备份的流程和工具
备份索引是为了在数据丢失或损坏的情况下能够迅速恢复。Lucene的备份相对简单,主要涉及复制索引目录到另一个安全的位置。
可以使用Java NIO包中的 Files.copy 方法进行备份:
Path source = Paths.get("/path/to/index");
Path target = Paths.get("/path/to/index-backup");
try {
Files.walkFileTree(source, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
Files.copy(file, target.resolve(source.relativize(file)));
return FileVisitResult.CONTINUE;
}
});
} catch (IOException e) {
e.printStackTrace();
}
除了手动备份外,也可以使用脚本自动化备份过程,例如通过定时任务来执行备份操作。
4.3.2 索引恢复的场景和策略
索引恢复是指在索引数据丢失、损坏或索引目录错误的情况下,将备份的索引复制回原索引目录。以下是恢复策略的步骤:
- 确定备份的位置和时间点。
- 清除原索引目录或将其移动到一个临时位置。
- 将备份的索引复制回原索引目录。
- 重启应用以使更改生效。
在执行索引恢复操作时,务必小心谨慎,确保备份数据的完整性和一致性。另外,考虑到恢复操作可能会影响服务的可用性,建议在低峰时段进行恢复操作。
通过上述实践操作,可以帮助读者更好地理解和掌握在使用 Lucene 进行索引创建与管理中的各种有效策略和技巧。
5. 索引检查与调试实践
在本章中,我们将深入探讨索引的检查与调试实践。这是确保Lucene索引质量的重要环节,同时也为性能优化提供了基础。
5.1 索引的健康检查
5.1.1 常见的索引问题
在使用Lucene进行索引时,可能会遇到各种问题,如文档数据丢失、索引损坏、搜索性能下降等。这些常见问题往往与索引文件的完整性、存储介质的稳定性以及操作的正确性有关。
5.1.2 索引健康状态的诊断方法
诊断索引的健康状态可以通过多种方式,例如使用Lucene自带的验证工具 IndexValidator ,或者编写脚本来检查索引文件的完整性和结构。
// 示例代码:使用Lucene自带的IndexValidator进行索引验证
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexValidator;
try {
IndexReader reader = IndexReader.open(indexDirectory);
IndexValidator validator = new IndexValidator();
if (validator.validate(reader)) {
System.out.println("索引验证通过");
} else {
System.out.println("发现索引问题,请进行修复");
}
reader.close();
} catch (Exception e) {
System.err.println("索引验证失败,原因:" + e.getMessage());
}
5.2 问题调试与性能优化
5.2.1 调试工具和方法的选择
进行索引调试和性能优化时,可以使用不同的工具和方法。Lucene的 Luke 工具是一个流行的选项,它可以帮助开发者可视化索引结构,并进行实时搜索测试。
5.2.2 性能瓶颈的识别与优化
性能瓶颈的识别通常需要通过监控索引操作的耗时、I/O读写次数等指标。一旦识别瓶颈,可以通过索引合并、提高硬件性能或调整索引参数来优化性能。
5.3 搜索结果的验证与分析
5.3.1 搜索结果的准确度评估
为了验证搜索结果的准确度,可以定义一些测试用例,并使用这些用例来检查搜索结果的相关性。这通常涉及到人工检查,但也有一些自动化工具能够提供帮助。
5.3.2 搜索行为的分析与改进
通过分析用户的搜索行为,可以发现搜索模式和常见的查询问题,进而改进搜索算法和调整查询解析器的配置,从而提高用户体验。
// 示例代码:利用Lucene进行搜索并分析结果的相关性
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
// 构建索引搜索器
try {
Directory directory = FSDirectory.open(indexDirectory);
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(directory));
StandardAnalyzer analyzer = new StandardAnalyzer();
QueryParser parser = new QueryParser("contents", analyzer);
// 执行搜索
Query query = parser.parse("搜索关键词");
TopDocs topDocs = searcher.search(query, 10);
// 分析结果
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
System.out.println("文档ID: " + doc.getField("id").stringValue());
System.out.println("文档路径: " + doc.getField("path").stringValue());
System.out.println("文档内容: " + doc.getField("contents").stringValue());
System.out.println("相关性得分: " + scoreDoc.score);
System.out.println("---------");
}
} catch (Exception e) {
System.err.println("搜索错误: " + e.getMessage());
}
上述示例代码展示了如何使用Lucene的 IndexSearcher 类来执行搜索,并分析每个返回结果的相关性得分。
通过上述章节的内容,我们可以看到索引检查与调试实践不仅仅是解决错误或问题的过程,它还包括对索引性能的优化和搜索质量的持续改进。一个健康和优化良好的索引系统对于提供高效的搜索引擎至关重要。随着技术的不断进步,索引检查与调试也在不断发展,引入了更多的自动化工具和方法。对于IT专业人士而言,深入理解和掌握这些技能,能够帮助他们更好地维护和提升系统的搜索性能。
简介:Apache Lucene是一款开源全文检索库,本文章详细介绍了Lucene 3.5.0版本的两个核心组件——“lucene-core-3.5.0.jar”和”lukeall-3.5.0.jar”。”lucene-core-3.5.0.jar”提供了索引创建、查询解析等基础功能,”lukeall-3.5.0.jar”则是一个强大的索引浏览器和分析工具。这两者通常一起使用,以确保高效创建和管理索引,以及进行有效的索引检查和调试。掌握这两者的使用对于构建全文搜索引擎和优化搜索性能至关重要。

















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









