




简介:ZooKeeper 3.4.9是Apache Hadoop生态中的关键分布式协调组件,提供命名服务、配置管理、集群同步和分布式事件通知等核心功能。其树形数据模型、主从复制架构与Watcher监听机制,确保了高可用性与强一致性。本解析涵盖ZooKeeper在分布式系统中的核心应用场景与技术实现,结合API设计、性能优化与安全机制,帮助开发者深入掌握该版本在真实环境下的部署与运维,提升分布式系统稳定性与可维护性。
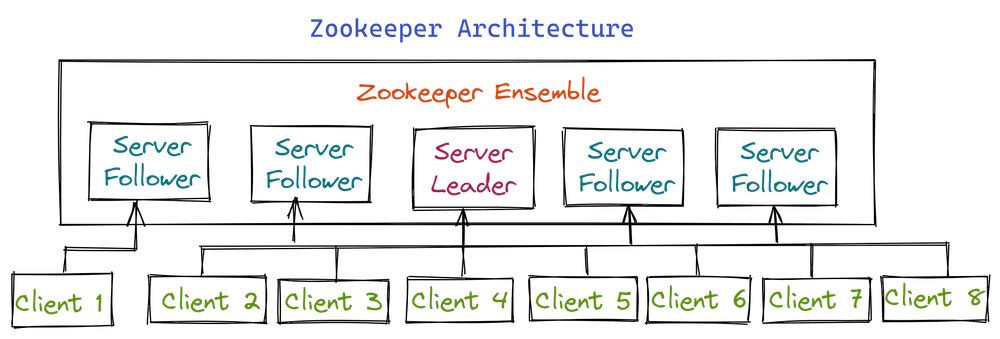
1. ZooKeeper基本概念与核心作用
1.1 分布式协调服务的核心定位
ZooKeeper 是分布式系统中的“中枢神经系统”,专为解决集群环境下的协调问题而设计。它通过提供高可用、强一致性的数据存储与通知机制,支撑配置管理、命名服务、分布式锁和 Leader 选举等关键场景。
其核心基于 ZAB 协议(ZooKeeper Atomic Broadcast)实现数据复制,确保所有节点视图全局一致。客户端通过 TCP 长连接与服务器通信,利用层次化的 Znode 树模型组织数据,并借助 Watcher 机制实现实时感知。
/ ← 根节点
├── config ← 配置管理路径
├── locks ← 分布式锁路径
└── brokers ← Kafka 节点注册位置
正是这种简洁而强大的抽象,使 ZooKeeper 成为 Hadoop、Kafka、Dubbo 等主流框架依赖的协同基石。
2. Znode树形数据模型与操作API
ZooKeeper 的核心设计理念之一是提供一个分布式的、层次化的内存数据库,用于实现高效协调服务。这个内存数据库以 Znode(ZooKeeper Node)为基本单位组织成一棵类似文件系统的树形结构,每个节点都可以存储少量数据并拥有子节点。这种类文件系统的设计不仅直观易用,而且天然支持路径寻址和层级划分,使得它能够灵活应对各种分布式协作场景的需求。Znode 模型不仅是 ZooKeeper 存储的基础,更是其一致性保障、事件通知机制以及高级功能如分布式锁、Leader 选举等实现的基石。
在实际应用中,开发者通过客户端 API 对这棵树进行增删改查操作,并结合 Watcher 监听机制感知状态变化。理解 Znode 的数据结构、类型特性、版本控制策略以及访问语义,是构建高可用、强一致的分布式系统的关键前提。本章将深入剖析 Znode 的内部构成,解析不同类型的节点行为差异,阐明线性一致性读写背后的原理,并通过编程实践展示如何正确使用 ZooKeeper 提供的核心 API 完成典型任务。
2.1 Znode的数据结构与类型划分
Znode 是 ZooKeeper 中最小的数据单元,每一个 Znode 都对应一个唯一的路径(如 /app/config/db_url ),并可以附带最多 1MB 的数据内容。尽管单个节点容量有限,但整个 Znode 树可容纳数百万个节点,适合存储配置信息、状态标识或轻量级元数据。更重要的是,Znode 不仅是一个静态存储容器,还具备丰富的元信息字段和动态行为特征,这些特性使其超越了传统键值对模型的能力边界。
2.1.1 持久节点与临时节点的本质区别
ZooKeeper 支持两种主要类型的 Znode: 持久节点(Persistent Node) 和 临时节点(Ephemeral Node) 。它们的根本区别在于生命周期管理方式。
- 持久节点 :一旦创建,除非被显式删除(通过
delete操作),否则会一直存在于集群中,即使创建它的客户端断开连接也不会消失。 - 临时节点 :其生命周期绑定于创建该节点的客户端会话(Session)。当客户端与 ZooKeeper 服务器失去连接超过会话超时时间(由
sessionTimeout参数设定),ZooKeeper 会自动清除所有属于该会话的临时节点。
这一机制特别适用于服务发现、存活检测等需要“自动清理”的场景。例如,在微服务架构中,服务实例启动时可在 /services/app_name/ 下创建一个临时节点表示自己在线;一旦进程崩溃或网络中断导致会话失效,ZooKeeper 自动移除该节点,其他服务即可感知到该实例已下线。
下面是一个 Java 示例代码,演示如何创建持久节点和临时节点:
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
public class ZnodeTypeExample {
private static final String CONNECT_STRING = "localhost:2181";
private static final int SESSION_TIMEOUT = 5000;
public static void main(String[] args) throws Exception {
ZooKeeper zk = new ZooKeeper(CONNECT_STRING, SESSION_TIMEOUT, event -> {});
// 创建持久节点
zk.create("/persistent_node", "data-persistent".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 创建临时节点
zk.create("/ephemeral_node", "data-temporary".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println("Nodes created.");
// 主线程等待,保持会话活跃
Thread.sleep(60000); // 60秒后程序退出
zk.close();
}
}
代码逻辑逐行解读:
| 行号 | 说明 |
|---|---|
| 7 | 初始化 ZooKeeper 客户端,连接本地 ZK 服务,设置超时时间为 5 秒,第三个参数为默认监听器(此处为空实现)。 |
| 10–12 | 调用 create() 方法创建一个持久节点 /persistent_node ,权限设为开放(生产环境不应使用),模式为 PERSISTENT 。 |
| 15–17 | 创建一个临时节点 /ephemeral_node ,使用 EPHEMERAL 模式,数据内容为字节数组。 |
| 20 | 输出提示信息。 |
| 23 | 延迟 60 秒,模拟客户端运行期间保持会话有效。 |
| 25 | 关闭连接,触发会话终止,从而导致 /ephemeral_node 被自动删除。 |
⚠️ 注意:若在此期间断开网络或强制关闭 JVM,则临时节点立即被清除,而持久节点仍保留。
参数说明:
-
CreateMode.PERSISTENT:表示节点永久存在。 -
CreateMode.EPHEMERAL:表示节点依附于当前会话。 -
ZooDefs.Ids.OPEN_ACL_UNSAFE:代表完全开放的访问权限,任何客户端均可读写——仅用于测试。 -
sessionTimeout:必须合理设置,太短会导致频繁重连,太长则无法及时感知故障。
下表对比两类节点的关键属性:
| 特性 | 持久节点 | 临时节点 |
|---|---|---|
| 生命周期 | 手动删除为止 | 会话结束即销毁 |
| 是否可有子节点 | 是 | 是(但子节点不能是临时节点) |
| 典型用途 | 配置项、命名空间 | 服务注册、Leader 标识 |
| 客户端离线影响 | 无影响 | 节点自动删除 |
| 可否重复创建 | 否(路径唯一) | 否(同一会话内不可重复) |
此外,ZooKeeper 明确规定: 临时节点不能拥有子节点 。这是为了防止出现“孤儿临时子树”问题——即父节点因会话失效被删除,但其子节点却无法被正确清理。
2.1.2 有序节点的生成机制与应用场景
除了持久与临时的区别外,ZooKeeper 还支持“有序(Sequential)”特性。当创建节点时指定 SEQUENTIAL 标志,ZooKeeper 会在用户提供的路径后自动附加一个单调递增的 10 位数字序号,格式为 %010d 。例如:
zk.create("/tasks/task-", "data".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);
// 可能返回路径:/tasks/task-0000000001
此序号由 ZooKeeper 集群全局维护,保证在同一父节点下的顺序唯一性和递增性,基于 ZAB 协议确保跨副本的一致性。
应用场景分析:
- 分布式队列 :多个客户端向
/queue/tasks-写入任务节点,由于带有顺序号,可以通过获取最小序号节点来实现 FIFO 队列。 - 选举排序 :在 Leader 选举中,各参与者创建临时顺序节点,然后检查是否有比自己序号更小的节点存在,若无则成为 Leader。
- 唯一事务 ID 生成器 :利用路径+序号组合生成全局唯一的 ID,避免中心化 UUID 或数据库自增主键瓶颈。
以下流程图展示了使用有序节点实现公平锁的基本流程:
sequenceDiagram
participant ClientA
participant ClientB
participant ZooKeeper
ClientA->>ZooKeeper: create("/lock/req-", EPHEMERAL_SEQUENTIAL)
ZooKeeper-->>ClientA: 返回 /lock/req-0000000001
ClientB->>ZooKeeper: create("/lock/req-", EPHEMERAL_SEQUENTIAL)
ZooKeeper-->>ClientB: 返回 /lock/req-0000000002
ClientA->>ZooKeeper: getChildren("/lock")
ZooKeeper-->>ClientA: [req-0000000001, req-0000000002]
alt 最小序号 == 自己
ClientA->>ClientA: 获取锁成功
end
ClientB->>ZooKeeper: getChildren("/lock")
ZooKeeper-->>ClientB: [req-0000000001, req-0000000002]
note over ClientB: 发现 req-0000000001 < 自己
ClientB->>ZooKeeper: watch /lock/req-0000000001 (delete)
从图中可见,客户端通过比较自身节点序号与同级节点中的最小值决定是否获得资源访问权。当持有最小序号的节点被删除后,Watcher 会被触发,唤醒下一个等待者。
实现注意事项:
- 序号是 每父节点局部递增 ,而非全局唯一递增。即
/a/x-和/b/y-的序号分别计数。 - 创建带有
SEQUENTIAL的节点时,原路径末尾建议加上'-'分隔符,便于后续解析。 - 序号最大为
2^31 - 1,约 21 亿次后回绕(实际极少达到)。
2.1.3 Znode的版本控制与CAS操作支持
ZooKeeper 为每个 Znode 维护多个版本号,用于实现乐观并发控制(Optimistic Concurrency Control, OCC),防止并发更新冲突。主要版本字段包括:
| 版本类型 | 字段名 | 含义 |
|---|---|---|
| dataVersion | stat.cversion | 数据修改次数(每次 setData +1) |
| cversion | stat.cversion | 子节点变更次数(每次 addChild/deleteChild +1) |
| aclVersion | stat.aversion | ACL 权限修改次数 |
| zxid | stat.mzxid , stat.pzxid | 事务ID,全局唯一,用于排序 |
其中最关键的是 dataVersion ,它可用于实现类似于 CAS(Compare-and-Swap)的操作。例如,在调用 setData(path, data, expectedVersion) 时,如果传入的 expectedVersion 不等于当前节点的实际 dataVersion ,则操作失败并抛出 BadVersionException 。
这种机制非常适合处理并发写竞争。比如两个客户端同时读取某个配置节点,随后都尝试更新,只有第一个提交的成功,第二个因版本不匹配而失败,需重新读取再试。
示例代码如下:
Stat stat = new Stat();
byte[] currentData = zk.getData("/config/threshold", false, stat);
int currentVer = stat.getVersion(); // 获取当前版本
// 尝试更新,期望版本为 currentVer
try {
zk.setData("/config/threshold", "new_value".getBytes(), currentVer);
System.out.println("Update succeeded.");
} catch (KeeperException.BadVersionException e) {
System.out.println("Concurrent update detected. Retry needed.");
}
逻辑分析:
- 第 2 行通过
getData()获取节点数据及Stat元信息,包含当前dataVersion。 - 第 4 行调用
setData()并传入预期版本号。 - 若在此期间另一客户端已修改该节点,
dataVersion已增加,则本次更新失败,程序可据此触发重试逻辑。
这种方式避免了加锁带来的性能损耗,体现了 ZooKeeper “轻量级协调”的设计哲学。
| 使用模式 | 描述 | 适用场景 |
|---|---|---|
| 无版本检查 | setData(path, data, -1) | 忽略版本,强制覆盖 |
| CAS 更新 | setData(path, data, expectedVer) | 配置更新、状态切换 |
| 多步事务 | 配合 multi() 批量执行原子操作 | 跨节点一致性变更 |
综上所述,Znode 的类型划分不仅仅是简单的分类,而是支撑复杂分布式协议实现的核心抽象。通过灵活组合持久/临时、有序/无序、版本控制等特性,开发者可以在不引入外部依赖的情况下构建出健壮的协调逻辑。
3. Watcher事件监听机制详解
在分布式系统中,实时感知状态变化是实现高可用服务协调的关键能力。ZooKeeper 提供的 Watcher 机制正是为此而设计的核心功能之一。它允许客户端对特定 Znode 节点的状态变更进行异步监听,从而在数据更新、子节点增减或节点删除时获得即时通知。这种轻量级、低延迟的事件驱动模型广泛应用于配置热更新、服务发现和发布/订阅系统等场景。然而,由于其“一次性触发”特性和与会话生命周期紧密耦合的设计,若使用不当极易导致事件丢失或响应延迟。因此,深入理解 Watcher 的工作原理、可靠性边界及性能影响因素,对于构建稳定高效的分布式协同系统至关重要。
3.1 Watcher的工作机制与触发条件
Watcher 是 ZooKeeper 客户端与服务器之间建立的一种单次注册、异步通知的监听机制。当某个被监控的 Znode 发生指定类型的变更时,ZooKeeper 服务器会向对应客户端发送一个事件通知。该机制并非持续监听,而是遵循“注册 → 触发 → 失效”的生命周期模式,必须由客户端在收到通知后重新注册才能继续监听后续变化。
3.1.1 一次性通知特性与重注册逻辑
ZooKeeper 的 Watcher 最显著的特征是 一次性(one-time trigger) :一旦某个 Watcher 被触发,无论是否成功处理,它都会自动从服务器端注销。这意味着如果希望持续监听某一路径的变化,客户端必须在接收到事件之后主动再次调用 exists() 、 getData() 或 getChildren() 等支持 Watch 参数的方法来重新注册监听。
这一设计背后有明确的工程考量:避免服务器长期维护大量无效监听器所带来的内存开销和复杂性。但这也带来了编程上的挑战——开发者必须显式管理重注册流程,否则将错过后续的所有变更。
以下是一个 Java 客户端中典型的 Watcher 重注册示例:
public class PersistentWatcher implements Watcher {
private final ZooKeeper zk;
private final String path;
public PersistentWatcher(ZooKeeper zk, String path) throws KeeperException, InterruptedException {
this.zk = zk;
this.path = path;
// 首次注册监听
registerWatch();
}
private void registerWatch() throws KeeperException, InterruptedException {
zk.exists(path, this); // 注册对节点存在性的监听
}
@Override
public void process(WatchedEvent event) {
System.out.println("Received event: " + event);
if (event.getType() == Event.EventType.NodeDataChanged) {
System.out.println("Node data changed: " + path);
// 执行业务逻辑,如刷新本地缓存
handleConfigUpdate();
try {
// 重新注册监听,确保下次变更仍能捕获
registerWatch();
} catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
}
private void handleConfigUpdate() {
// 拉取最新配置数据
try {
byte[] data = zk.getData(path, false, null);
System.out.println("New config: " + new String(data));
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码逻辑逐行解读:
- 第6~10行 :构造函数初始化 ZooKeeper 实例和监听路径,并立即调用
registerWatch()进行首次注册。 - 第13~15行 :
registerWatch()方法通过zk.exists(path, this)向服务器注册当前对象作为 Watcher。注意这里使用的是exists接口而非getData,仅关注节点是否存在及其数据变化。 - 第20~24行 :
process()是 Watcher 接口的核心回调方法。每当事件到达时,ZooKeeper 客户端线程会调用此方法。 - 第27行 :判断事件类型为
NodeDataChanged,表示目标节点的数据已修改。 - 第32~38行 :执行具体业务操作(如更新本地配置),然后调用
registerWatch()重新注册,形成闭环。
⚠️ 注意事项:若在
registerWatch()中抛出异常(如网络中断),则本次重注册失败,可能导致事件漏报。因此生产环境中通常需结合重试机制与错误日志记录。
此外,ZooKeeper 并不保证事件送达顺序与操作顺序完全一致,但在同一个客户端连接上,事件按 zxid(事务ID)严格有序。这为实现最终一致性提供了基础保障。
3.1.2 数据变更、子节点变更与节点删除的监听粒度
ZooKeeper 支持三种主要的 Watch 类型,分别对应不同的节点状态变化:
| 监听类型 | 触发条件 | 使用方法 |
|---|---|---|
NodeCreated | 目标路径原不存在,现被创建 | exists(path, watcher) |
NodeDeleted | 目标节点被删除 | exists(path, watcher) 或 getData(path, watcher) |
NodeDataChanged | 节点数据内容发生变化 | getData(path, watcher) |
NodeChildrenChanged | 子节点列表发生增删 | getChildren(path, watcher) |
这些事件类型决定了客户端可以精细化地控制监听范围。例如,在服务发现场景中,通常只需监听 /services/service-name 下的子节点变化(即实例上下线),而不关心每个实例的具体数据内容。
下面展示如何利用 getChildren 实现对子节点变动的监听:
public class ChildrenChangeWatcher implements Watcher {
private final ZooKeeper zk;
private final String parentPath;
public ChildrenChangeWatcher(ZooKeeper zk, String parentPath) throws Exception {
this.zk = zk;
this.parentPath = parentPath;
watchChildren();
}
private void watchChildren() throws KeeperException, InterruptedException {
List<String> children = zk.getChildren(parentPath, this);
System.out.println("Current children: " + children);
}
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeChildrenChanged) {
System.out.println("Children changed under: " + event.getPath());
try {
// 获取最新子节点列表
watchChildren(); // 重新注册并获取数据
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
参数说明与逻辑分析:
-
getChildren(path, watcher):同时返回当前子节点列表并设置 Watch。只有当子节点数量或名称改变时才会触发事件(数据变更不会触发)。 - 事件回调中再次调用
watchChildren()不仅完成重注册,也同步拉取最新状态,适合用于动态服务列表更新。 - 若父节点本身被删除,则也会触发一次
NodeChildrenChanged事件,随后所有 Watcher 自动失效。
3.1.3 客户端事件队列与串行处理模型
ZooKeeper 客户端内部采用 单线程串行化处理事件 的模型。所有来自服务器的 Watch 事件都被放入一个 FIFO 队列中,由专门的 EventThread 线程依次调用用户定义的 process() 方法。
graph TD
A[ZooKeeper Server] -->|发送事件| B(客户端网络层)
B --> C{事件分发器}
C --> D[EventQueue]
D --> E[EventThread]
E --> F[调用用户Watcher.process()]
F --> G[用户自定义逻辑]
G --> H[可能触发ZK API调用]
H --> I[ZooKeeper客户端]
该流程图展示了事件从服务器到应用逻辑的完整路径。关键点在于:
- 所有 Watcher 回调都在同一个线程中执行, 不允许阻塞操作 (如远程调用、数据库查询)。否则会影响其他事件的及时处理。
- 如果某次 process() 执行耗时过长,会导致后续事件堆积,甚至引发会话超时(session timeout)。
- 建议在 process() 中仅做轻量级操作(如标记状态、唤醒工作线程),将实际处理逻辑提交至独立线程池。
例如:
private final ExecutorService workerPool = Executors.newFixedThreadPool(4);
@Override
public void process(WatchedEvent event) {
workerPool.submit(() -> {
try {
handleEvent(event); // 在独立线程中处理耗时任务
} catch (Exception e) {
log.error("Failed to handle event", e);
}
});
}
这样既保证了事件接收的及时性,又避免了主线程阻塞风险。
3.2 Watcher的可靠性保障与常见陷阱
尽管 Watcher 提供了强大的实时感知能力,但由于其依赖于 TCP 长连接和会话状态,在网络波动或节点故障时容易出现不可靠行为。理解其可靠性边界并采取相应防护措施,是保障系统健壮性的关键。
3.2.1 连接中断后的事件丢失问题
当客户端与 ZooKeeper 集群之间的网络连接断开时,正在传输中的 Watch 事件可能无法送达。更重要的是, 在连接恢复前发生的任何节点变更都不会被补发 。这是因为 ZooKeeper 不维护离线期间的历史事件日志。
假设一个客户端正在监听 /config/db-url ,在其断网期间管理员修改了数据库地址。待连接恢复后,客户端不会收到此次变更的通知,除非手动轮询检查或依赖其他机制检测版本号(zxid)差异。
解决方案包括:
- 结合定期轮询机制验证关键节点的 stat 信息(如 mtime、version);
- 利用 multi 操作原子读取数据与元信息;
- 在应用启动或会话重建后强制全量同步状态。
3.2.2 会话超时对Watcher注册状态的影响
ZooKeeper 的 Watcher 与客户端会话(Session)绑定。当会话因超时而失效时,所有已注册的 Watcher 都会被服务器自动清除。即使后续建立新会话,也不会继承之前的监听关系。
下表总结了不同连接状态下 Watcher 的行为:
| 状态 | 是否保持连接 | Session 是否有效 | Watcher 是否保留 |
|---|---|---|---|
| 正常运行 | ✅ | ✅ | ✅ |
| 短暂断网(< sessionTimeout) | ❌ | ✅(reconnecting) | ❌(需重连后重注册) |
| 会话超时(> sessionTimeout) | ❌ | ❌(session expired) | ❌(全部丢失) |
因此,在客户端实现中应监听 Event.EventType.None 类型的事件,判断是否为会话级别事件:
public void process(WatchedEvent event) {
if (event.getState() == Event.KeeperState.Expired) {
System.err.println("Session expired! Need to recreate ZooKeeper instance.");
// 必须新建ZK连接并重新注册所有Watcher
reconnectAndRestoreWatches();
} else if (event.getType() != Event.EventType.None) {
// 处理普通节点事件
handleNodeEvent(event);
}
}
3.2.3 如何避免事件漏报与重复响应
由于 Watcher 的一次性机制和网络不确定性,可能出现两种典型问题:
1. 事件漏报 :未及时重注册导致中间变更未被捕获;
2. 重复响应 :同一次变更可能因重试或多路径传播被多次通知。
应对策略如下:
防止漏报:
- 所有
getData/getChildren调用都应附带 Watcher,并在回调中立即重注册; - 对关键配置项增加版本校验(如比较
Stat.mzxid); - 使用 ZAB 协议提供的全局顺序号
zxid来判断是否有跳跃。
避免重复:
- 引入去重缓存(如用
ConcurrentHashMap<String, Long>记录最后处理的 zxid); - 设计幂等处理逻辑(如配置更新前比对新旧值);
- 在分布式环境下使用共享锁或协调机制控制并发处理。
例如:
private final Map<String, Long> lastProcessedZxid = new ConcurrentHashMap<>();
void handleDataChange(String path, Stat stat) {
long currentZxid = stat.getMzxid();
Long lastZxid = lastProcessedZxid.get(path);
if (lastZxid != null && currentZxid <= lastZxid) {
log.warn("Duplicate or outdated event for {}, zxid={}", path, currentZxid);
return;
}
// 更新并处理
lastProcessedZxid.put(path, currentZxid);
applyConfiguration(path);
}
3.3 基于Watcher的实时感知系统构建
Watcher 机制是构建各类实时感知系统的基石。本节以配置中心和服务发现为例,演示如何基于 Watcher 实现高效、可靠的动态感知架构。
3.3.1 配置中心动态推送的设计实现
现代微服务架构普遍采用集中式配置中心,要求配置变更能实时推送到所有实例。ZooKeeper 可作为底层存储与通知通道。
典型结构如下:
+------------------+ +--------------------+
| Config Admin | ----> | /configs/app/db_url |
+------------------+ +--------------------+
↑
| Watcher
↓
+-----------------------+
| Application Instance |
| - Local Cache |
| - Auto-refresh on W |
+-----------------------+
实现要点:
- 所有应用实例在启动时读取 /configs/{app} 路径下的配置,并注册 Watch;
- 当管理员通过运维工具修改配置时,ZooKeeper 自动通知所有监听者;
- 应用收到通知后重新拉取数据并刷新本地缓存(如 Spring 的 @RefreshScope );
Java 示例片段:
byte[] data = zk.getData("/configs/myapp", new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType() == NodeDataChanged) {
reloadConfig(); // 异步加载
}
}
}, null);
优点:低延迟、高一致性;缺点:海量实例同时响应可能导致“惊群效应”。
优化方案:
- 分片通知:引入中间代理层(如 Config Agent)减少直连 ZooKeeper 的客户端数;
- 延迟合并:对短时间内多次变更只处理最后一次;
- 加入随机退避机制避免集体重刷。
3.3.2 服务发现中节点上下线监测方案
在 RPC 或微服务体系中,服务提供方将自身注册为临时节点(Ephemeral Node),消费者通过监听 /services/service-a 的子节点变化实现自动发现。
flowchart LR
A[Provider] -- create Ephemeral --> B[/services/service-a/192.168.1.1:8080]
C[Consumer] -- getChildren + Watch --> B
B -- NodeChildrenChanged --> C
C --> D[Update routing table]
流程说明:
1. 提供者启动时创建临时节点;
2. 消费者获取当前列表并注册 NodeChildrenChanged Watch;
3. 提供者宕机后节点自动消失,消费者收到通知并剔除无效地址;
4. 新实例加入时触发新增事件,消费者自动纳入负载均衡。
该模式天然支持故障自动剔除,无需心跳探测协议。
3.3.3 实现轻量级发布/订阅系统的完整流程
可基于 ZooKeeper 构建简单的 Pub/Sub 系统:
- 主题映射为 Znode 路径(如
/topics/news); - 消息以有序临时节点形式发布(
create(..., SEQUENCE | EPHEMERAL)); - 订阅者监听
NodeChildrenChanged并消费新增节点; - 消费完成后删除消息节点(或 TTL 自动清理);
优势:强一致性、顺序可靠;局限:不适合高频消息场景(受限于 ZK 写性能)。
3.4 Watcher性能调优与资源管理
大规模系统中,过多 Watcher 会对 ZooKeeper 集群造成显著压力。
3.4.1 大规模Watcher注册对ZooKeeper的压力影响
每个 Watcher 在服务器端占用一定内存(约 100~200 字节),且事件广播涉及跨节点通信(通过 ZAB 协议)。当客户端数量超过数千、监听路径达百万级时,可能出现:
- 内存占用过高;
- 事件分发延迟增加;
- Leader 负载过重。
建议:
- 控制单个集群的 Watcher 总数在合理范围内(< 1M);
- 避免对高频写路径设置过多监听;
- 使用聚合节点减少监听点(如 /status/all 统一通知);
3.4.2 减少无效Watcher提升系统吞吐能力
无效 Watcher 指注册后从未被触发或早已失效的监听器。可通过以下方式优化:
- 实施 Watcher 生命周期监控(JMX 暴露统计指标);
- 定期清理长时间无变更路径的监听;
- 采用“懒注册”策略:仅在需要时才开启监听;
最终目标是在实时性与系统负载间取得平衡,确保核心业务不受干扰。
4. 分布式锁与集群同步实现
在分布式系统中,多个节点往往需要对共享资源进行并发访问。由于缺乏全局内存视图和统一时钟,传统的单机锁机制无法直接适用于跨进程、跨网络的场景。ZooKeeper 凭借其强一致性模型、顺序性保证以及临时节点与 Watcher 机制,成为构建分布式锁和集群协调功能的理想选择。本章将深入剖析基于 ZooKeeper 实现分布式锁的核心原理,涵盖从基本竞争机制到复杂读写锁设计,并进一步扩展至 Leader 选举与分布式栅栏等高级同步原语。
4.1 分布式锁的基本原理与实现模式
分布式锁的本质是确保在同一时刻只有一个客户端能够获得特定资源的操作权限。ZooKeeper 提供了天然支持这一需求的数据结构和事件通知机制——通过 Znode 的创建顺序性和 Watcher 的监听能力,可以构造出高效且可靠的互斥控制逻辑。
4.1.1 基于临时顺序节点的竞争机制
ZooKeeper 中最典型的分布式锁实现方式是使用“临时顺序节点”(Ephemeral Sequential Node)。每个请求加锁的客户端在其父节点下创建一个带有 EPHEMERAL | SEQUENCE 标志的子节点,例如 /lock_root/lock-000000001 。这些节点由 ZooKeeper 按照全局递增的 zxid(事务 ID)自动分配序号,从而形成严格有序的命名空间。
该机制的关键优势在于:
- 故障自清理 :因使用临时节点,若客户端崩溃或会话中断,对应节点会被 ZooKeeper 自动删除,避免死锁。
- 顺序可比性 :所有节点按创建时间严格排序,便于判断是否轮到当前客户端获取锁。
- 轻量级监听 :仅需监听前驱节点的删除事件即可感知锁状态变化,减少服务器压力。
// Java 示例:创建临时顺序节点
String lockPath = "/distributed_locks";
String subNode = "lock-";
ZooKeeper zk = new ZooKeeper("localhost:2181", 5000, null);
// 创建临时顺序节点
String createdPath = zk.create(
lockPath + "/" + subNode,
new byte[0],
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL
);
代码解释与参数说明 :
lockPath + "/" + subNode:指定锁的根路径及前缀名;new byte[0]:节点数据为空,仅用于标识存在;ZooDefs.Ids.OPEN_ACL_UNSAFE:表示无权限控制,生产环境应配置 ACL;CreateMode.EPHEMERAL_SEQUENTIAL:关键标志位,确保节点为临时且带序号;- 返回值
createdPath包含完整路径与实际生成的序号,如/distributed_locks/lock-000000003。
此方法利用 ZooKeeper 的原子性操作,确保即使多个客户端同时尝试创建节点也不会发生冲突,且每个节点都有唯一确定的顺序位置。
4.1.2 锁获取流程与前驱节点监听判断
一旦客户端成功创建自己的顺序节点,下一步就是判断是否可以获得锁。通常采用“最小序号即持有锁”的策略:如果当前节点的序号在整个子节点列表中是最小的,则认为获取锁成功;否则,监听其直接前驱节点的删除事件。
以下是典型的锁获取逻辑流程图:
graph TD
A[客户端请求获取锁] --> B{创建EPHEMERAL_SEQUENTIAL节点}
B --> C[获取父节点下的所有子节点并排序]
C --> D{当前节点是否为最小?}
D -- 是 --> E[获取锁成功]
D -- 否 --> F[监听前驱节点的删除事件]
F --> G[等待事件触发]
G --> H{前驱节点被删除?}
H -- 是 --> C
H -- 否 --> I[处理异常或超时]
上述流程体现了典型的“循环重试+事件驱动”模型。客户端不会持续轮询,而是依赖 ZooKeeper 的事件推送机制来降低网络开销和响应延迟。
为了提升性能,建议每次监听只关注前一个节点,而非整个子节点集。这可以通过解析 createdPath 中的序号部分并查找前驱节点完成:
List<String> children = zk.getChildren(lockPath, false);
Collections.sort(children); // 按字典序排序(数字不足位补零)
String myNodeName = createdPath.substring(createdPath.lastIndexOf('/') + 1);
int myIndex = children.indexOf(myNodeName);
if (myIndex == 0) {
// 当前节点序号最小,获得锁
} else {
String predecessor = children.get(myIndex - 1);
final CountDownLatch latch = new CountDownLatch(1);
// 注册 Watcher 监听前驱节点删除
zk.getData(lockPath + "/" + predecessor, event -> {
if (event.getType() == Watcher.Event.EventType.NodeDeleted) {
latch.countDown();
}
}, null);
// 阻塞直到前驱节点被删除
boolean acquired = latch.await(30, TimeUnit.SECONDS);
}
逐行逻辑分析 :
getChildren()获取当前锁目录下的所有子节点;Collections.sort()利用字符串自然排序匹配 ZooKeeper 的命名规则(如lock-000000001<lock-000000002);indexOf()定位当前节点的位置;- 若索引为 0,说明无更小序号节点,可立即获得锁;
- 否则,取出前一个节点名称,注册
getData()调用附带 Watcher;- 使用
CountDownLatch实现阻塞等待,直到前驱节点被删除后唤醒;- 设置超时时间为 30 秒,防止无限等待导致资源占用。
该方案兼顾效率与可靠性,适用于高并发环境下对关键资源的串行化访问控制。
4.1.3 可重入锁与公平性保障设计
标准的临时顺序节点锁虽然实现了互斥,但不支持可重入特性。若同一客户端多次请求锁,会产生多个不同序号的节点,导致自身也被阻塞。为此,可在客户端维护线程本地存储(ThreadLocal),记录已持有的锁信息,并结合会话 ID(Session ID)进行身份识别。
改进思路如下:
| 特性 | 描述 |
|---|---|
| 可重入 | 同一会话内重复获取同一锁时直接计数增加 |
| 公平性 | 所有请求按创建顺序排队,先到先得 |
| 锁释放 | 计数归零时才真正删除节点 |
具体实现中,可在节点数据中嵌入 sessionId 和 threadId:
byte[] data = (sessionId + ":" + Thread.currentThread().getId()).getBytes(StandardCharsets.UTF_8);
zk.create(lockPath + "/reentrant-", data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
当尝试获取锁时,遍历前面的所有节点,检查是否有相同 sessionId 的节点存在。若有,则视为同一线程重入,直接递增计数而不重新注册监听。
此外,为增强公平性,还可引入“锁申请队列”概念:所有请求必须进入队列等待调度,杜绝抢占行为。这种设计特别适合金融交易、任务分发等要求严格顺序处理的场景。
4.2 共享锁与排他锁的编码实践
除了独占式的排他锁(Exclusive Lock),在某些业务场景中还需要支持多读单写的共享锁(Shared Lock),以提高并发吞吐量。ZooKeeper 可通过区分读写节点类型并制定优先级规则来实现 ReadWriteLock 模式。
4.2.1 写锁抢占与读锁并发控制
共享锁的核心挑战是如何保证写操作的排他性,同时允许多个读操作并发执行。常见策略是将锁分为两类节点:
-
/shared_lock/read-开头的临时顺序节点表示读锁; -
/shared_lock/write-开头的表示写锁。
其竞争规则定义如下:
- 如果当前节点是写锁,只有当它前面没有任何其他节点时才能获取锁;
- 如果当前节点是读锁,则只要前面没有写锁节点即可并发获取。
这意味着读锁之间可以共存,但任何写锁都必须等待前面所有读锁和写锁释放。
以下表格总结了不同节点类型的竞争关系:
| 当前请求 | 前面存在的节点类型 | 是否可获取锁 |
|---|---|---|
| 读 | 读 | ✅ 是 |
| 读 | 写 | ❌ 否 |
| 写 | 读或写 | ❌ 否 |
| 写 | 无 | ✅ 是 |
这种机制有效防止了写饥饿问题,同时最大化读并发能力。
4.2.2 利用ZooKeeper实现ReadWriteLock模式
下面是一个简化的 Java 实现片段,展示如何根据节点类型决定是否获取共享锁:
public class SharedReentrantReadWriteLock {
private final ZooKeeper zk;
private final String rootPath = "/shared_lock";
private final String readPrefix = "read-";
private final String writePrefix = "write-";
public boolean tryAcquireReadLock() throws Exception {
String path = zk.create(rootPath + "/" + readPrefix, ... EPHEMERAL_SEQUENTIAL);
return waitForTurn(path, true);
}
public boolean tryAcquireWriteLock() throws Exception {
String path = zk.create(rootPath + "/" + writePrefix, ... EPHEMERAL_SEQUENTIAL);
return waitForTurn(path, false);
}
private boolean waitForTurn(String fullPath, boolean isReadLock) throws Exception {
while (true) {
List<String> children = zk.getChildren(rootPath, false);
Collections.sort(children);
String nodeName = fullPath.substring(fullPath.lastIndexOf('/') + 1);
int currentIndex = children.indexOf(nodeName);
boolean hasPrecedingWriter = false;
for (int i = 0; i < currentIndex; i++) {
String name = children.get(i);
if (name.startsWith(writePrefix)) {
hasPrecedingWriter = true;
break;
}
}
if ((isReadLock && !hasPrecedingWriter) || (!isReadLock && currentIndex == 0)) {
return true; // 成功获取锁
}
// 监听最近的一个写节点或前驱节点
String watchPath = findClosestPrecedingWriteNode(children, currentIndex);
registerOneTimeWatcher(watchPath, () -> {});
waitForEvent(); // 等待唤醒
}
}
}
参数说明与逻辑分析 :
tryAcquireReadLock()与tryAcquireWriteLock()分别发起读/写锁请求;waitForTurn()是核心判断逻辑,不断检查前驱节点类型;hasPrecedingWriter标记是否存在前面的写锁节点;- 读锁只需确认前面无写锁即可通过;
- 写锁必须位于首位才能获取;
registerOneTimeWatcher()注册一次性的 Watcher,减少无效监听;- 循环重试直至满足条件或超时。
此实现支持基本的读写分离语义,可用于缓存更新、配置加载等场景。
4.2.3 死锁预防与超时释放机制集成
尽管 ZooKeeper 本身通过临时节点规避了永久死锁,但在应用层仍可能出现逻辑死锁或长时间阻塞。因此需引入超时机制:
boolean acquired = waitForTurnWithTimeout(path, 30, TimeUnit.SECONDS);
if (!acquired) {
throw new TimeoutException("Failed to acquire lock within timeout");
}
同时,在锁管理器中维护每个锁的持有时间戳,并定期扫描过期锁进行强制释放(需谨慎处理,防止误删)。
另一种优化手段是引入租约(Lease)机制:客户端定期发送心跳续期,若未能及时续期则自动释放锁。这种方式更适合长周期任务的协调。
4.3 Leader选举机制原理与实践
在分布式系统中,常常需要选出一个主节点负责协调工作,如 Kafka 的 Controller、HDFS 的 NameNode 等。ZooKeeper 提供了一种简单而高效的 Leader 选举实现方式。
4.3.1 利用最小序号节点决定Leader归属
Leader 选举可复用分布式锁的思想:所有候选节点在同一目录下创建临时顺序节点,序号最小者当选为主节点。
String leaderPath = "/election";
String candidatePath = zk.create(leaderPath + "/candidate-", data, ..., EPHEMERAL_SEQUENTIAL);
List<String> candidates = zk.getChildren(leaderPath, false);
Collections.sort(candidates);
if (candidatePath.endsWith(candidates.get(0))) {
becomeLeader();
} else {
watchPreviousCandidate(candidates, candidatePath);
}
当选主失败时,监听前一个节点的删除事件。一旦前驱退出,重新检查排名并决定是否晋升。
4.3.2 崩溃恢复过程中的重新选举行为
当 Leader 节点宕机,其对应的临时节点被 ZooKeeper 自动清除,触发其余节点的 Watcher 事件。下一个序号最小的节点检测到自己已成为首节点后,自动升级为主控角色。
该机制具备快速故障转移能力,平均切换时间取决于会话超时设置(通常为几秒级别)。
4.3.3 主节点故障转移的延迟优化策略
为降低切换延迟,可采取以下措施:
- 缩短
sessionTimeout至合理范围(如 6s~10s); - 使用 NIO 客户端保持连接活跃;
- 在客户端预加载必要状态,缩短恢复时间;
- 引入“影子 Leader”预热机制,提前准备备用节点。
4.4 集群任务协调与屏障同步
4.4.1 分布式栅栏(Barrier)的构造方法
分布式栅栏用于让一组节点等待彼此到达某个同步点后再继续执行。可通过创建一个计数节点 /barrier/count 并监控其值是否达到预期数量来实现。
4.4.2 双屏障控制批量作业启动与完成
双屏障不仅等待全部成员加入,还等待全部成员完成任务后再解除。典型应用于 MapReduce 类批处理系统。
+------------------+ +------------------+
| Node A |<----->| Coordination |
| waits at barrier | | Service (ZK) |
+------------------+ +------------------+
↑
Tracks participant count
通过 Watcher 监听 /barrier/reached 和 /barrier/released 节点状态,实现精准同步控制。
5. 集中式配置管理与动态更新机制
在现代分布式系统架构中,服务实例数量庞大、部署环境复杂多变,传统的本地静态配置方式已无法满足快速迭代和灵活运维的需求。集中式配置管理作为一种核心基础设施能力,能够实现配置的统一存储、版本控制、权限隔离以及动态推送,极大提升了系统的可维护性与弹性响应能力。ZooKeeper 凭借其强一致性保证、高效的 Watcher 事件通知机制以及树形 Znode 数据模型,成为构建高可用配置中心的理想选择。
本章将深入探讨如何基于 ZooKeeper 构建一个具备实时感知、安全可控、支持灰度发布的集中式配置管理系统。从设计原则出发,逐步展开技术实现路径,并结合生产部署中的高可用考量,提供完整的实践方案。通过本章内容,读者不仅能掌握 ZooKeeper 在配置管理场景下的最佳实践模式,还能理解其背后的设计权衡与性能优化策略。
5.1 配置中心的设计原则与架构选型
构建一个健壮的配置中心不仅仅是技术选型的问题,更是一套系统工程的设计过程。它需要兼顾一致性、可用性、安全性、可观测性和扩展性五大核心维度。ZooKeeper 作为 CP 系统(Consistency & Partition Tolerance),天然适合用于对数据一致性要求极高的配置管理场景。相比其他 AP 型配置中心(如 Consul 或 Eureka),ZooKeeper 能确保所有客户端看到的是全局一致的配置视图,避免因网络分区导致配置错乱的风险。
5.1.1 统一存储带来的运维优势
将配置信息集中存储于 ZooKeeper 的 Znode 层级结构中,可以带来诸多运维层面的优势。首先,配置变更不再依赖于逐台机器的手动修改或脚本推送,而是通过一次写操作即可广播至整个集群;其次,所有服务实例共享同一份“真理源”(Source of Truth),消除了配置漂移问题;再次,配合 ACL 权限控制机制,可实现细粒度的访问控制,防止非法读写。
例如,在微服务架构中,每个服务可通过命名空间划分独立的配置路径:
/configs
├── /service-user
│ ├── /dev
│ │ └── config → {"db.url": "jdbc:mysql://...", "pool.size": 20}
│ ├── /prod
│ │ └── config → {"db.url": "jdbc:mysql://prod...", "pool.size": 50}
├── /service-order
└── /prod
└── config → {"timeout.ms": 3000, "retry.count": 3}
该层级结构清晰表达了环境(dev/prod)、服务名称和服务配置的关系,便于自动化工具进行扫描与审计。
更重要的是,这种统一存储模型为实现 配置版本化 和 回滚机制 提供了基础。虽然 ZooKeeper 自身不直接支持版本快照功能,但可以通过外部元数据记录每次 setData 操作的时间戳与 zxid(ZooKeeper Transaction ID),并借助外部数据库或日志系统保存历史版本,从而实现类似 Git 的配置管理流程。
下表对比了传统文件配置与基于 ZooKeeper 的集中式配置的关键特性差异:
| 特性 | 文件配置(本地) | ZooKeeper 集中式配置 |
|---|---|---|
| 配置一致性 | 弱,易出现漂移 | 强,全局线性一致 |
| 变更传播延迟 | 分钟级(需下发) | 秒级(Watcher 实时通知) |
| 安全性 | 依赖 OS 权限 | 支持 ACL + SASL 认证 |
| 动态热加载 | 复杂,需轮询 | 原生支持事件驱动 |
| 故障恢复 | 无自动恢复机制 | 临时节点自动清理 |
| 扩展性 | 单机局限 | 支持大规模集群接入 |
此外,ZooKeeper 的会话机制(Session)也增强了配置系统的健壮性。当客户端异常断开连接时,若使用临时节点存放运行时配置状态(如“是否启用调试模式”),则可在会话超时后由系统自动清除无效状态,避免“僵尸配置”。
5.1.2 版本管理与灰度发布的可行性
尽管 ZooKeeper 不内置版本控制系统,但通过合理设计 Znode 结构与元数据附加字段,完全可以实现轻量级的版本追踪与灰度发布能力。
一种常见的做法是为每个配置节点添加额外的属性节点,用于记录版本号、更新时间、操作人等信息:
/configs/service-user/prod
├── config → JSON 格式的配置内容
├── version → "v1.2.3"
├── updated_at → "2025-04-05T10:23:00Z"
├── operator → "admin@company.com"
└── status → "active"
当执行配置更新时,先校验当前版本状态,再原子性地更新 config 和 version 节点(可通过 multi-op 事务操作保证一致性)。客户端在接收到 Watcher 通知后,可比较本地缓存版本与远端版本,决定是否重新加载。
对于灰度发布场景,可通过引入标签路由机制实现分组推送。例如,利用 ZooKeeper 中的“配置分组节点”来区分不同流量群体:
/configs/service-user/
├── /group-all → 全量生效
├── /group-canary → 仅灰度机器监听此路径
├── /group-beta → 内部测试用户组
各客户端根据自身标识(如 IP 段、主机标签)订阅对应的配置路径。这种方式无需改动 ZooKeeper 核心逻辑,仅通过路径规划即可实现灵活的发布策略。
下面是一个基于 Mermaid 的配置中心整体架构流程图,展示了客户端如何通过 Watcher 实现动态感知:
graph TD
A[ZooKeeper Cluster] -->|存储配置数据| B((Znode Tree))
B --> C[/configs/service-x/prod/config]
C --> D[Watcher 注册]
D --> E[Client Instance 1]
D --> F[Client Instance 2]
D --> G[Client Instance N]
H[Config Management UI/API] -->|更新配置| C
C -->|触发事件| D
D -->|异步通知| E
D -->|异步通知| F
D -->|异步通知| G
E --> I[本地缓存更新]
F --> J[重新初始化组件]
G --> K[应用新配置]
上述流程体现了事件驱动的配置更新闭环:配置变更 → ZooKeeper 持久化 → 事件广播 → 客户端响应 → 本地生效。整个过程延迟通常在毫秒级别,显著优于定时拉取模式。
为进一步提升可靠性,建议在客户端实现双层缓存机制:
- 内存缓存 :保存最新配置对象,供应用程序快速访问;
- 本地磁盘缓存 :持久化最近一次成功获取的配置,用于启动时 fallback 或网络中断期间降级使用。
这不仅提高了容错能力,也为后续章节讨论的“动态更新”打下了坚实基础。
5.2 动态配置推送的技术实现路径
动态配置推送是集中式配置中心的核心能力之一,意味着配置变更无需重启服务即可生效。ZooKeeper 提供了强大的事件驱动机制,使得这一目标得以高效实现。本节将详细阐述基于 Watcher 的热加载机制、客户端缓存策略以及配置审计日志的落地方案。
5.2.1 监听特定Znode实现配置热加载
ZooKeeper 的 Watcher 机制允许客户端注册对某个 Znode 的监听,一旦该节点的数据发生变化( setData )、子节点增减或节点被删除,便会触发一次性的事件通知。正是这一特性,构成了动态配置推送的基础。
以下是一个典型的 Java 客户端代码示例,展示如何监听 /configs/app-service/prod/config 节点并实现热加载:
public class ConfigWatcher {
private final String CONFIG_PATH = "/configs/app-service/prod/config";
private ZooKeeper zk;
private volatile AppConfiguration currentConfig;
public void start() throws IOException, KeeperException, InterruptedException {
zk = new ZooKeeper("zk1:2181,zk2:2181,zk3:2181", 5000, this::process);
// 首次同步读取配置
byte[] data = zk.getData(CONFIG_PATH, this::watcherCallback, null);
this.currentConfig = parseConfig(data);
System.out.println("Initial config loaded: " + currentConfig);
}
private void watcherCallback(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDataChanged &&
event.getPath().equals(CONFIG_PATH)) {
try {
// 重新获取最新配置
byte[] newData = zk.getData(CONFIG_PATH, this::watcherCallback, null);
AppConfiguration newConfig = parseConfig(newData);
// 比较并应用变更
if (!newConfig.equals(currentConfig)) {
System.out.println("Detected config change, reloading...");
applyNewConfiguration(newConfig);
this.currentConfig = newConfig;
}
} catch (Exception e) {
System.err.println("Failed to reload config: " + e.getMessage());
// 重新注册监听以防丢失事件
registerAgain();
}
}
}
private void registerAgain() {
try {
zk.getData(CONFIG_PATH, this::watcherCallback, null);
} catch (Exception e) {
// 递归重试或告警
}
}
private AppConfiguration parseConfig(byte[] data) {
return JsonUtils.fromJson(new String(data), AppConfiguration.class);
}
private void applyNewConfiguration(AppConfiguration config) {
// 触发业务组件重载,如 DataSource、CacheManager 等
ComponentRegistry.reload(config);
}
}
代码逻辑逐行分析:
-
zk = new ZooKeeper(...):建立与 ZooKeeper 集群的连接,第三个参数为全局事件处理器。 -
zk.getData(path, watcher, stat):这是关键操作——在读取数据的同时注册 Watcher。注意 Watcher 是“一次性”的,因此每次处理完事件后必须重新注册。 -
watcherCallback方法中判断事件类型是否为NodeDataChanged,且路径匹配目标配置节点。 - 成功获取新数据后反序列化为配置对象,并与当前配置比较,若有变化则调用
applyNewConfiguration进行热更新。 -
registerAgain()确保即使发生异常也能恢复监听,防止事件遗漏。
⚠️ 重要提示 :由于 Watcher 是一次性触发的,开发者必须在每次事件处理完成后显式调用
getData()、exists()或getChildren()并传入新的回调函数,否则将无法继续接收后续变更通知。
为了提高稳定性,推荐封装一个带自动重连与 Watcher 重注册机制的通用 ConfigLoader 类,避免重复编码错误。
5.2.2 客户端缓存与本地 fallback 策略
在实际生产环境中,网络抖动、ZooKeeper 集群短暂不可用等情况难以避免。若此时客户端无法获取配置,可能导致服务启动失败或运行异常。为此,必须设计完善的缓存与降级策略。
典型的客户端配置加载流程如下表所示:
| 步骤 | 操作 | 备注 |
|---|---|---|
| 1 | 尝试从 ZooKeeper 加载最新配置 | 主路径 |
| 2 | 若成功,更新内存缓存并持久化到本地文件 | 如 /var/lib/myapp/config.json |
| 3 | 若失败,尝试从本地磁盘读取上一次缓存的配置 | fallback 模式 |
| 4 | 若仍失败,使用内置默认配置(hardcoded) | 最终兜底 |
| 5 | 后台持续尝试 reconnect 并恢复 Watcher | 异步恢复 |
以下是一个增强版的配置加载器伪代码结构:
public class ResilientConfigLoader {
private static final String LOCAL_CACHE_FILE = "/tmp/latest_config.json";
public AppConfiguration load() {
try {
byte[] data = zk.getData("/configs/current", watcher, null);
AppConfiguration config = parse(data);
saveToLocalCache(config); // 步骤2
return config;
} catch (ConnectionLossException | SessionExpiredException e) {
log.warn("ZooKeeper unreachable, falling back to local cache");
return loadFromLocal(); // 步骤3
} catch (Exception e) {
log.error("Unexpected error loading config", e);
return getDefaultConfig(); // 步骤4
}
}
private void saveToLocalCache(AppConfiguration config) {
try (FileWriter fw = new FileWriter(LOCAL_CACHE_FILE)) {
fw.write(JsonUtils.toJson(config));
} catch (IOException ignored) {}
}
private AppConfiguration loadFromLocal() {
File f = new File(LOCAL_CACHE_FILE);
if (f.exists()) {
return JsonUtils.fromJson(FileUtils.readFileToString(f), AppConfiguration.class);
}
throw new RuntimeException("No local cache available");
}
}
该策略有效保障了服务的可用性,即使在配置中心完全宕机的情况下,只要本地有有效缓存,服务仍可正常运行。
5.2.3 配置变更审计日志记录方案
出于合规与故障排查需求,任何配置变更都应被完整记录。虽然 ZooKeeper 自身的日志( zookeeper.out 和事务日志 log.* )包含所有写操作,但不易解析且缺乏上下文信息。因此,应在应用层建立独立的审计日志系统。
常见做法是在配置更新入口处插入日志记录逻辑,例如通过 REST API 修改配置时:
@PostMapping("/configs/{path}")
public ResponseEntity updateConfig(@PathVariable String path, @RequestBody String value) {
String fullPath = "/configs/" + path;
try {
// 获取操作人(从 JWT 或 Header)
String operator = getOperator(request);
// 执行 ZooKeeper 更新
zk.setData(fullPath, value.getBytes(), -1);
// 记录审计日志
auditLogService.log(
AuditEvent.builder()
.type("CONFIG_UPDATE")
.target(fullPath)
.oldValue(getOldValue(fullPath))
.newValue(value)
.operator(operator)
.timestamp(Instant.now())
.build()
);
return ok().build();
} catch (Exception e) {
auditLogService.logFailure("CONFIG_UPDATE", path, e.getMessage());
return badRequest().build();
}
}
审计日志建议存储在 Elasticsearch 或 Kafka 中,便于后续搜索、报警与可视化分析。典型字段包括:
| 字段名 | 描述 |
|---|---|
event_id | 唯一事件 ID |
type | 事件类型(UPDATE/DELETE) |
target | 被修改的 Znode 路径 |
old_value , new_value | 变更前后的内容(脱敏处理敏感信息) |
operator | 操作者身份 |
ip_address | 操作来源 IP |
timestamp | 操作时间 |
success | 是否成功 |
结合这些日志,可构建出完整的“谁在什么时候改了什么”的追溯能力,满足金融、医疗等行业监管要求。
5.3 高可用配置服务的部署实践
5.3.1 多机房容灾下的数据同步考量
在跨地域多机房部署场景中,ZooKeeper 集群通常只部署在一个主区域(Primary Region),以保证 ZAB 协议的强一致性。然而,这会导致远程机房的客户端面临较高网络延迟,影响配置读取效率。
解决方案有两种主流模式:
- 同城多副本 + 异步复制 :在异地机房部署只读副本(Observer 模式),通过 ZAB 协议异步同步数据,降低写一致性压力;
- 本地缓存代理层(Proxy Cache) :在每个机房部署轻量级配置网关,定期从主集群拉取配置并提供 HTTP 接口,客户端直连本地网关。
推荐采用第二种方案,因其解耦性强、易于监控。架构示意如下:
graph LR
A[ZooKeeper Primary DC] -->|sync every 1s| B(Config Gateway - DC1)
A -->|sync every 1s| C(Config Gateway - DC2)
B --> D[Service Instances in DC1]
C --> E[Service Instances in DC2]
Config Gateway 使用长轮询或 Watcher 监听主集群,本地缓存配置并通过 RESTful API 对外暴露,同时记录请求指标用于熔断与限流。
5.3.2 权限隔离与敏感信息加密存储
ZooKeeper 支持基于 ACL 的访问控制,可按 Scheme(如 digest、ip、auth)设置节点权限。对于配置中心,建议至少实施以下策略:
# 设置用户名密码访问控制
addauth digest user:password
setAcl /configs/service-prod/auth digest:user:pxv+...:rwcda
其中 rwcda 表示读、写、创建、删除、管理权限。敏感配置(如数据库密码)应进一步加密后再写入 Znode:
String encrypted = AESUtils.encrypt("my-secret-pwd", MASTER_KEY);
zk.setData("/configs/db/password", encrypted.getBytes(), -1);
解密密钥可通过外部 KMS(Key Management Service)获取,禁止硬编码。也可结合 Hashicorp Vault 等专用密钥管理系统,ZooKeeper 仅作索引用途。
综上所述,基于 ZooKeeper 的集中式配置管理不仅是可行的,而且在一致性、实时性和可靠性方面具有显著优势。通过合理的架构设计与编码实践,完全可以支撑企业级的大规模动态配置需求。
6. ZooKeeper 3.4.9部署与运维实战
6.1 集群搭建与参数调优
在生产环境中,ZooKeeper通常以集群模式(即“ensemble”)运行,推荐由奇数个节点(如3、5或7台服务器)组成,以确保在部分节点故障时仍能维持多数派共识。以下为基于ZooKeeper 3.4.9版本的典型集群部署流程和关键参数优化建议。
6.1.1 myid配置与server列表定义规范
每台ZooKeeper服务器必须在其数据目录中创建一个名为 myid 的文件,内容为唯一的整数ID(范围1~255),用于标识该节点在整个集群中的身份。例如:
# 假设当前主机为第一台ZooKeeper节点
echo "1" > /opt/zookeeper/data/myid
zoo.cfg 配置文件中需明确定义所有集群成员,格式如下:
tickTime=2000
dataDir=/opt/zookeeper/data
clientPort=2181
initLimit=10
syncLimit=5
# 集群节点定义
server.1=zoo1.example.com:2888:3888
server.2=zoo2.example.com:2888:3888
server.3=zoo3.example.com:2888:3888
其中:
- 2888 是Follower与Leader之间进行数据同步的通信端口;
- 3888 是Leader选举过程中用于投票通信的端口;
- server.X 对应 myid=X 的节点。
注意:DNS解析必须正确配置,或使用IP地址替代域名以避免网络延迟或连接失败。
6.1.2 tickTime、initLimit、syncLimit合理设置
| 参数 | 默认值 | 推荐设置 | 说明 |
|---|---|---|---|
tickTime | 2000ms | 2000~5000ms | 心跳基本时间单位,不宜过小导致误判超时 |
initLimit | 10 ticks | 10~20 | Follower初始连接并完成数据同步的最大时间(initLimit × tickTime) |
syncLimit | 5 ticks | 5~10 | Follower与Leader间心跳响应最大容忍间隔 |
示例计算:
- 若 tickTime=2000 , initLimit=10 → 允许最长20秒完成初始化同步;
- syncLimit=5 → 单次通信最多10秒未响应则断开。
对于跨机房部署场景,可适当增大上述值以应对高延迟。
6.1.3 JVM堆内存分配与GC策略建议
ZooKeeper是Java应用,其性能受JVM配置影响显著。建议根据节点角色和负载情况调整堆大小。
# 示例:启动脚本中设置JVM参数
export JVMFLAGS="-Xms4g -Xmx4g -XX:+UseG1GC -XX:MaxGCPauseMillis=100"
关键建议:
- 堆内存不建议超过8GB,避免长时间GC停顿;
- 使用G1垃圾回收器(适用于大堆且低延迟需求);
- 启用GC日志便于后续分析:
-XX:+PrintGCApplicationStoppedTime \
-XX:+PrintGCDateStamps -Xloggc:/var/log/zookeeper/gc.log
可通过监控GC频率与暂停时间判断是否需要进一步调优。
6.2 安全机制:SASL与SSL加密支持
6.2.1 用户身份认证配置(Digest/Mechanism)
ZooKeeper支持通过SASL进行用户认证,常用于限制客户端访问权限。
启用SASL Digest-MD5认证步骤如下:
- 在
jaas.conf中定义服务端登录模块:
Server {
org.apache.zookeeper.server.auth.DigestLoginModule required
user_zkadmin="admin_password";
};
- 设置JVM系统属性指向JAAS配置:
-Djava.security.auth.login.config=/opt/zookeeper/conf/jaas.conf
- 修改
zoo.cfg开启认证:
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
requireClientAuthScheme=sasl
客户端连接时需提供用户名密码,并使用支持SASL的ZooKeeper客户端库。
6.2.2 启用SSL传输层加密通信链路
为防止监听攻击,可在ZooKeeper 3.4.9中启用SSL加密(需自行编译支持Netty+OpenSSL)。
主要步骤包括:
1. 生成服务器证书并导入密钥库(keystore)和信任库(truststore);
2. 配置 zoo.cfg 添加SSL相关参数:
ssl.keyStore.location=/opt/zookeeper/conf/keystore.jks
ssl.keyStore.password=changeit
ssl.trustStore.location=/opt/zookeeper/conf/truststore.jks
ssl.trustStore.password=changeit
clientPortAddress=0.0.0.0
secureClientPort=2281
- 客户端使用
zookeeper.clientCnxnSocket指定安全套接字类:
System.setProperty("zookeeper.clientCnxnSocket", "org.apache.zookeeper.ClientCnxnSocketNetty");
注意:原生ZooKeeper 3.4.9对SSL支持有限,建议升级至3.5+系列以获得更完善的TLS能力。
6.3 监控诊断:JMX集成与日志分析
6.3.1 关键MBean指标解读(ZooKeeperServer、Connections)
ZooKeeper内置JMX接口,可通过JConsole或Prometheus + JMX Exporter采集指标。
常用MBean路径及含义:
| MBean ObjectName | 属性字段 | 含义 |
|---|---|---|
org.apache.ZooKeeperService:name0=StandaloneServer_port-x | AvgRequestLatency | 平均请求延迟(毫秒) |
MaxRequestLatency | 最大延迟,突增可能表示GC或磁盘瓶颈 | |
OutstandingRequests | 当前待处理请求数,持续大于0表示过载 | |
name0=Connections,name1=Connection_<ip> | NumAliveConnections | 活跃连接数 |
PacketsReceived/Sent | 流量统计 |
建议设置告警规则:当 MaxRequestLatency > 1s 或 OutstandingRequests > 100 时触发预警。
6.3.2 四字命令(ruok, stat, mntr)日常巡检应用
ZooKeeper提供一系列“四字命令”用于快速诊断状态,通过telnet或nc发送:
echo "stat" | nc zoo1.example.com 2181
常见命令输出示例:
Zookeeper version: 3.4.9--1, built on 03/15/2016 17:38 GMT
Clients:
/192.168.1.10:54321[1](queued=0,recved=123,sent=123)
Latency min/avg/max: 0/1/15
Received: 123456
Sent: 123455
Connections: 1
Outstanding: 0
Zxid: 0x10000000a
Mode: follower
Node count: 245
推荐定期轮询以下命令:
- ruok → 返回 imok 表示服务正常;
- mntr → 输出结构化监控数据,适合机器解析;
- wchs → 查看Watcher总数,预防内存溢出;
可编写自动化脚本每日巡检:
#!/bin/bash
for host in zoo1 zoo2 zoo3; do
echo "=== $host ==="
echo "ruok: $(echo ruok | nc $host 2181)"
echo "followers: $(echo srvr | nc $host 2181 | grep Followers)"
done
6.3.3 日志级别调整与异常排查技巧
ZooKeeper默认日志级别为INFO,可通过修改 log4j.properties 提升调试能力:
zookeeper.root.logger=DEBUG, CONSOLE
log4j.logger.org.apache.zookeeper.server.FastLeaderElection=DEBUG
重点关注日志关键词:
- LEADING / FOLLOWING / LOOKING :节点状态变迁;
- CommitProcessor: :事务提交延迟;
- SessionTracker : 会话超时与清理记录;
- Exception causing close of session :客户端异常断开原因。
若出现频繁Leader切换,检查是否有网络分区或GC停顿过长。
6.4 性能优化策略:同步、延迟与内存管理
6.4.1 提升写性能的批处理与异步提交权衡
ZooKeeper写操作需经过ZAB协议广播并持久化到事务日志( logDir )。为提升吞吐,可考虑:
- 将多个小更新合并为批量操作;
- 使用异步API( async 系列方法)降低阻塞;
- 避免高频更新同一节点,引发锁竞争。
但注意:异步提交无法保证顺序性,需结合业务逻辑判断是否适用。
6.4.2 快照频率与事务日志清理策略
ZooKeeper自动定期生成快照(snapshot),保存在 dataDir ,同时将事务写入 logDir 。
关键参数控制归档行为:
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
表示保留最近3个快照,每天执行一次清理。
建议:
- 分离 dataDir 和 logDir 到不同磁盘,减少IO争抢;
- 监控 zoo.cfg 中 dataLogDir 磁盘使用率,避免写满导致崩溃;
- 手动触发清理旧日志脚本(谨慎操作):
java -cp zookeeper-3.4.9.jar:lib/* org.apache.zookeeper.server.PurgeTxnLog \
/opt/zookeeper/data /opt/zookeeper/logs -n 3
6.4.3 OOM预防与大数据节点拆分建议
单个Znode存储不应超过1MB(官方建议),否则容易引起序列化压力和网络阻塞。
若需存储大型配置或元数据,建议:
- 拆分为多个子节点,按功能或版本划分;
- 使用外部存储(如HDFS、S3)存放实际数据,ZooKeeper仅保存引用路径;
- 定期审计大节点:
# 查询节点大小(需解析get输出)
echo "get /large_node" | nc localhost 2181 | wc -c
同时启用堆外缓存(如OffHeapCache)可缓解内存压力,但ZK 3.4.9不原生支持,需定制开发。
简介:ZooKeeper 3.4.9是Apache Hadoop生态中的关键分布式协调组件,提供命名服务、配置管理、集群同步和分布式事件通知等核心功能。其树形数据模型、主从复制架构与Watcher监听机制,确保了高可用性与强一致性。本解析涵盖ZooKeeper在分布式系统中的核心应用场景与技术实现,结合API设计、性能优化与安全机制,帮助开发者深入掌握该版本在真实环境下的部署与运维,提升分布式系统稳定性与可维护性。

















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









