




 本文详细介绍了MySQL索引的各个方面,包括B+Tree结构、索引类型如聚集索引和普通索引,以及ICP、MRR、BKA等优化技术。还讨论了索引的基本操作,如创建和查看索引,以及如何根据执行计划优化查询。最后总结了索引的优点和创建索引时应注意的事项,强调了索引选择性和避免使用NULL的重要性。
本文详细介绍了MySQL索引的各个方面,包括B+Tree结构、索引类型如聚集索引和普通索引,以及ICP、MRR、BKA等优化技术。还讨论了索引的基本操作,如创建和查看索引,以及如何根据执行计划优化查询。最后总结了索引的优点和创建索引时应注意的事项,强调了索引选择性和避免使用NULL的重要性。
文章目录
一、索引是什么?
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可以快速访问数据库表中的特定信息。
二、B+Tree结构
B+Tree由二叉树–>平衡二叉树–>B+tree演变过来。
所有数据保存在叶子节点上。


1.聚集索引和普通索引
聚集索引
InnoDB存储引擎表是索引组织表,聚集索引其实就是一种索引组织形式,索引键值的逻辑顺序决定了表数据行的物理存储顺序。聚集索引叶子结点存放表中所有行数据记录的信息
创建表时,如果不主动创建主键,那么InnoDB会选择第一个不包含有null值的唯一索引作为主键。如果连唯一索引都没有,InnoDB就会为该表默认生成一个6字节的rowid作为主键。
普通索引
普通索引在叶子结点并不包含所有行的数据记录,只是会在叶子结点存有自己本身的键值和主键的值。在检索数据时,通过普通索引叶子结点上的主键来获取到想要查找的行数据记录

2.ICP、MRR、BKA
ICP
Index Condition Pushdown(ICP)是MySQL使用索引从表中检索行数据的一种优化方式,MySQL5.6之后支持ICP,如果WHERE条件可以使用索引,MySQL会把这部分过滤操作放到存储引擎层,存储引擎通过索引过滤,把满足的行从表中读取出。ICP能减少引擎层访问基表的次数和Server层访问存储引擎的次数。
MySQL通过optimizer_switch参数中的index condition pushdown选项来控制,默认是开启的。
show variables like '%optimizer_switch%';
set optimizer switch="index condition pushdown=on|off";
MRR
MRR的全称是Multi-Range Read Optimization.
通过optimizer switch参数中两个重要的选项来控制,一个是mrr,另一个是mrr cost based。参数值默认也是开启状态的(mrr=on和mrr cost based=on)。
mrr cost based选项表示是否通过基于成本的算法来确定开启mrr特性:设置为on表示自行判断,要是为of则表示强制开启mr。extra列会显示
set optimizer switch="mrr =on|off,mrr cost based=on|off";
作用:
MRR的作用就是把普通索引的叶子结点上找到的主键值的集合存储到read _rnd_buffer中,然后在该buffer中对主键值进行排序,最后再利用已经排序好的主键值的集合,去访问表中的数据,这样就由原来的随机I/O变成了顺序/O,降低了查询过程中的I/O开销。
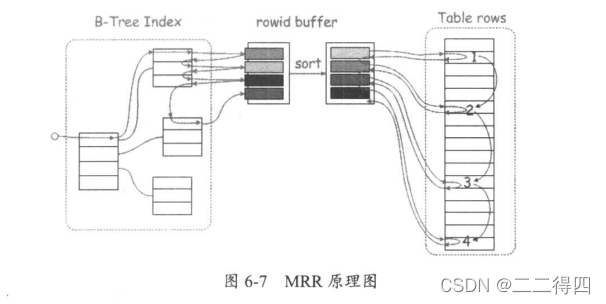
BKA
BKA的全称为Batched Key Access。它是提高表join性能的算法,其作用是在读取被join表的记录的时候使用顺序I/O。
BKA的原理很简单,对于多表join语句,当MySQL使用索引访问第二个join表时,使用一个join buffer来收集第一个操作对象生成的相关列值。BKA构建好key后,批量传给引擎层做索引查找。ky是通过MRR接口提交给引擎的,这样一来MRR使得查询更加高效。
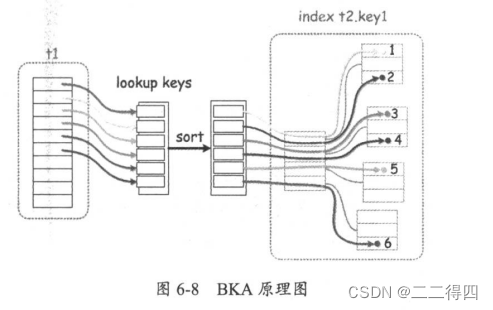
要想开启该参数,必须先要保证是在强制使用MRR的基础上才可以。执行如下操作才算开启BKA功能:extra列会显示Using join buffer(Batched Key Access)的关键字提示。
SET global optimizer switch='mrr=on,mrr cost based=off';
SET global optimizer switch='batched key access=on';
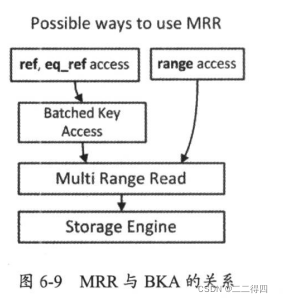
存储引擎上端是MRR,范围扫描中MySQL将扫描到的数据存入read
_rnd_buffer size,对其按照主键rowid进行排序,然后使用排序好的数据进行顺序回表,因为InnoDB中的叶节点数据是按照主键ROW ID进行排列的,这样就转换随机读取为顺序读取了。
而在BKA中,则在被连接表使用ref、eq ref索引扫描方式时,第一个表中扫描到的键值放到join buffer size中,然后调用MRR接口进行排序和顺序访问并且通过join条件得到数据,这样连接条件也成为了顺序比对。
3.主键索引和唯一索引
主键索引其实就是聚集索引,每张表中有且仅有一个主键,可以由表中一个或多个字段组成。主键索引必须满足三个条件,主键值必须唯一;不能包含nuul值;一定要保证该值是自增属性。
4.覆盖索引
检索id,会带出出现id的name值 extra:using index;
5.前缀索引
对于BLOB、TEXT,或者很长的VARCHAR类型的列,为它们的前几个字符建立索引,这样的索引就叫前缀索引。这样建立起来的索引更小,所以查询更快。但前缀索引也有它的坏处,它不能在ORDER BY或GROUP BY中使用前缀索引,也不能把它们用作覆盖索引。
alter table table name add key (column name (prefix length));
6.联合索引
联合索引又叫复合索引,是在表中两个或两个以上的列上创建的索引。利用索引中的附加列,可以缩小检索的段池范围,更快地搜索到数据。
为表t的cl、c2字段。
create index idx cl c2 on t (c1,c2);
联合索引的使用过程中,必须要满足最左前缀原则。一般把选择性高的列放在前面。一条查询语句可以只使用索引中的一部分,但必须从最左侧开始。
可以用到cl索引和c1,c2索引。
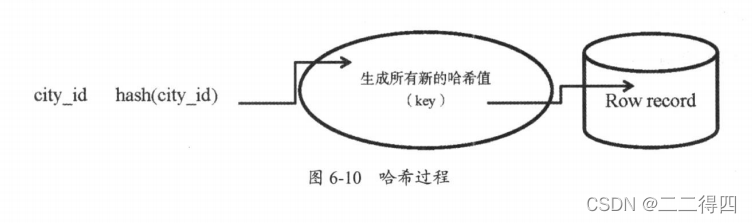
6.哈希索引
哈希索引采用哈希算法,把键值换算成新的哈希值,这里需要注意哈希索引只能进行等值查询,不能进行排序、模糊查找、范围查询等。检索时不需要像B+tree那样从根结点到叶子结点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,查询速度非常快。
二、基本操作
普通索引创建:
alter table table_name add index index_name(索引字段);
或者
create index index_name on table name(索引字段);
查看索引:
show index from table_name;
查看sql执行计划:
explain select * from t where name = 'name1';

如何查看
1.先从查询类型type列开始查看,如果出现all关键字,代表全表扫描。
2.再看key列,看是否使用了索引,null代表没有使用索引。
3.然后看rows列,该列用来表示在SQL执行过程中被扫描的行数,该数值越大,意味着需要扫描的行数越多,相应的耗时就更长。explain中输出的rows只是一个估算值。
4.最后再看extra列,在这列中要观察是否有Using filesort或者Using temporary这样的关键字出现,这些是很影响数据库性能的。
filtered它指返回结果的行占需要读到的行(rows列的值)的百分比。
如何优化
(1)先看表的数据类型是否设计得合理,有没有遵守选取数据类型越简单越小的原则。
(2)表中的碎片是否整理。
(3)表的统计信息是否收集,只有统计信息准确,执行计划才可以帮助我们优化SQL。
(4)查看执行计划,检查索引的使用情况,没有用到索引,考虑创建。
(5)在创建索引之前,还要查看索引的选择性,来判断这个字段是否合适创建索引。
所谓索引的选择性是指不重复的索引值和数据表的记录总数的
比值。索引的选择性越高则查询效率越高(越接近于1越高),因为选择性高的索引可以让MySQL在查找时过滤掉更多的行。主键索引和唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
(6)创建索引之后,再查看一下执行计划,对比这两次的结果,看是否查询效率提高了。
合理创建索引
(1)经常被查询的列(一般放在where条件后面)。
(2)经常用于表连接的列。
(3)经常排序分组的列(order by或者group by后面的字段)。
三、索引总结
优点
(1)提高数据检索效率。
(2)提高聚合函数效率。
(3)提高排序效率。
(4)使用覆盖索引可以避免回表。
索引创建的四个不要:
(1)选择性低的字段不要创建索引(例如,性别sex、状态status)。
(2)很少查询的列不要创建索引(项目初期就要确定好)。
(3)大数据类型字段不要创建索引。
(4)尽量避免不要使用NULL,应该指定列为NOT NULL(在MySQL中,含有空值的列很难进行查询优化,它们会使得索引、索引的统计信息及比较运算更加复杂。可以使用空字符串代替空值)。
使用不到索引的情况:
(1)通过索引扫描的行记录数超过全表的30%,优化器就不会走索引,而变成全表扫描。
(2)联合索引中,第一个查询条件不是最左索引列。
(3)联合索引中,第一个索引列使用范围查询,只能使用到部分索引,有ICP出现(范围查询是指<、=、<=、BETWEEN and)。
(4)联合索引中,第一个查询条件不是最左前缀列。
(5)模糊查询条件列最左以通配符%开始(可以考虑放到子查询里面)。
(6)两个单列索引,一个用于检索,一个用于排序。这种情况下只能使用到一个索引。因为查询语句中最多只能使用一个索引,考虑建立联合索引。
(7)查询字段上面有索引,但是使用了函数运算。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









