






 本文详细介绍了如何在三台服务器上部署Redis哨兵集群,包括安装Redis、配置防火墙、修改配置文件等步骤,并探讨了哨兵模型的优缺点。
本文详细介绍了如何在三台服务器上部署Redis哨兵集群,包括安装Redis、配置防火墙、修改配置文件等步骤,并探讨了哨兵模型的优缺点。
准备三台服务器:(vmware复制两个出来就行,建议先执行第一步在复制虚拟机,这样就都安装上了,嘿嘿偶然发现的)
我的准备:
主:192.168.1.104:6379
从1:192.168.1.103:6379
从2:192.168.1.105:6379
从3:192.168.1.106:6379
第一步:在每台上面安装redis
//下载软连接(不知道干啥的)
yum install -y http://rpms.famillecollet.com/enterprise/remi-release-7.rpm
//下载redis
yum --enablerepo=remi install redis//设置开机自启
systemctl enable redis
安装后地址默认一般是在:
/etc/redis-server
/etc/redis-cli
/etc/redis/redis-conf
/etc/sentinel-conf
第二步:防火墙开启端口
//查看端口:6379(redis)26379(sentinel)
firewall-cmd --query-port=6379/tcp
//开启端口(建议6379和26379全打开)
firewall-cmd --permanent --add-port=6379/tcp
//重启防火墙
firewall-cmd --reload
第三步修改配置文件(所有主从都要改):
redis-conf
# 默认绑定的是回环地址,默认不能被其他机器访问
bind 0.0.0.0
将`daemonize`由`no`改为`yes` 后台运行
daemonize yes
# 是否开启保护模式,由yes该为no
protected-mode no
# 从redis一定要添加这个(极其重要)主不加,只给从加
slaveof 主ip 主端口
例如:slaveof 192.168.1.104 6379sentinel-config
# 将`daemonize`由`no`改为`yes`
daemonize yes
# 哨兵sentinel监控的redis主节点的 ip port
sentinel monitor mymaster192.168.181.130 6379 2
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒,改成3秒
sentinel down-after-milliseconds mymaster 3000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
sentinel failover-timeout mymaster 180000
最后一步:启动redis和sentinel(都重启)
到 etc/下面运行
redis-server /etc/redis/redis-conf
redis-sentinel /etc/redis/sentinel-conf
测试:主服务器上
到 etc/下面运行
redis-cli
连接成功后输入:info
结果应该为: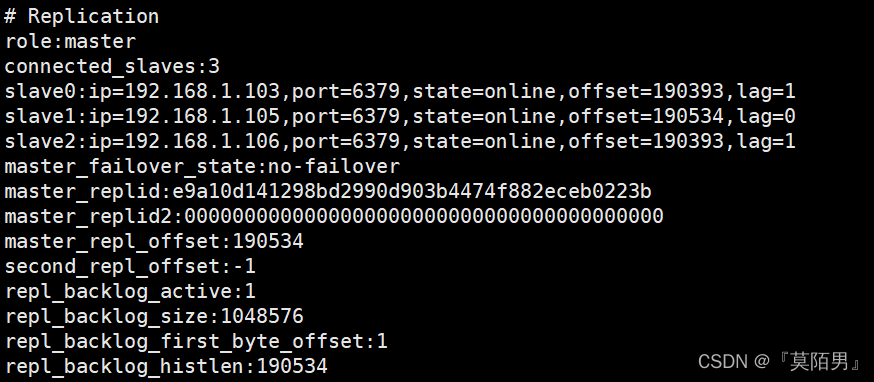
思考学习:
1、哨兵模型的优点:相比主从模型,如果发生宕机无需手动去更改master服务器,自动筛选符合的哨兵为主节点。
2、哨兵模型的缺点:保存数据都为master的全量数据,浪费内存,而且在筛选哨兵的时候,redis保护模型开启,无法进行读写(这里我个人想到的解决方案是使用mq进行消息重发机制),读写还是受单机影响比较大。(对单机服务器的性能要求比较高)
总结:
redis的哨兵模型不如redis cluster好用,(去中心化就能解决读写性能的问题)

















 6857
6857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









