 Caffe训练数据打乱技巧
Caffe训练数据打乱技巧





 本文介绍在Caffe框架中如何有效打乱训练数据,包括通过修改参数和直接操作标签文件两种方法,以避免数据规律性导致的过拟合或不收敛问题。
本文介绍在Caffe框架中如何有效打乱训练数据,包括通过修改参数和直接操作标签文件两种方法,以避免数据规律性导致的过拟合或不收敛问题。
1、可以选择在将数据转换成lmdb格式时进行打乱;
设置参数–shuffle=1;(表示打乱训练数据)
默认值为0,表示忽略,不打乱。
- 打乱的目的有两个:
1)防止出现过分有规律的数据,导致过拟合或者不收敛。
2)在caffe中可能会使得,在模型进行测试时,每一个测试样本都输出相同的预测概率值。
2、直接打乱训练文件的标签文件:train.txt
方法如下:
1)将 train_191209-train.txt按行打乱,每行内容则保持不变,命令:
cd 存放文件的路径
awk 'BEGIN{ 100000*srand();}{ printf "%s %s\n", rand(), $0}' train_191209-train.txt |sort -k1n | awk '{gsub($1FS,""); print $0}'
2)但这样处理后只是在屏幕上输出显示,如果需要将输出写入新的文本train.txt,则在末尾加上 | tee train.txt:
sudo awk 'BEGIN{ 100000*srand();}{ printf "%s %s\n", rand(), $0}' train_191209-train.txt |sort -k1n | awk '{gsub($1FS,""); print $0}' | tee train.txt
3)如果不需要在屏幕上输出显示,直接将输出写入新的文本train.txt,则在末尾将 | tee 换作 > 即可:
sudo awk 'BEGIN{ 100000*srand();}{ printf "%s %s\n", rand(), $0}' train_191209-train.txt |sort -k1n | awk '{gsub($1FS,""); print $0}' > train.txt
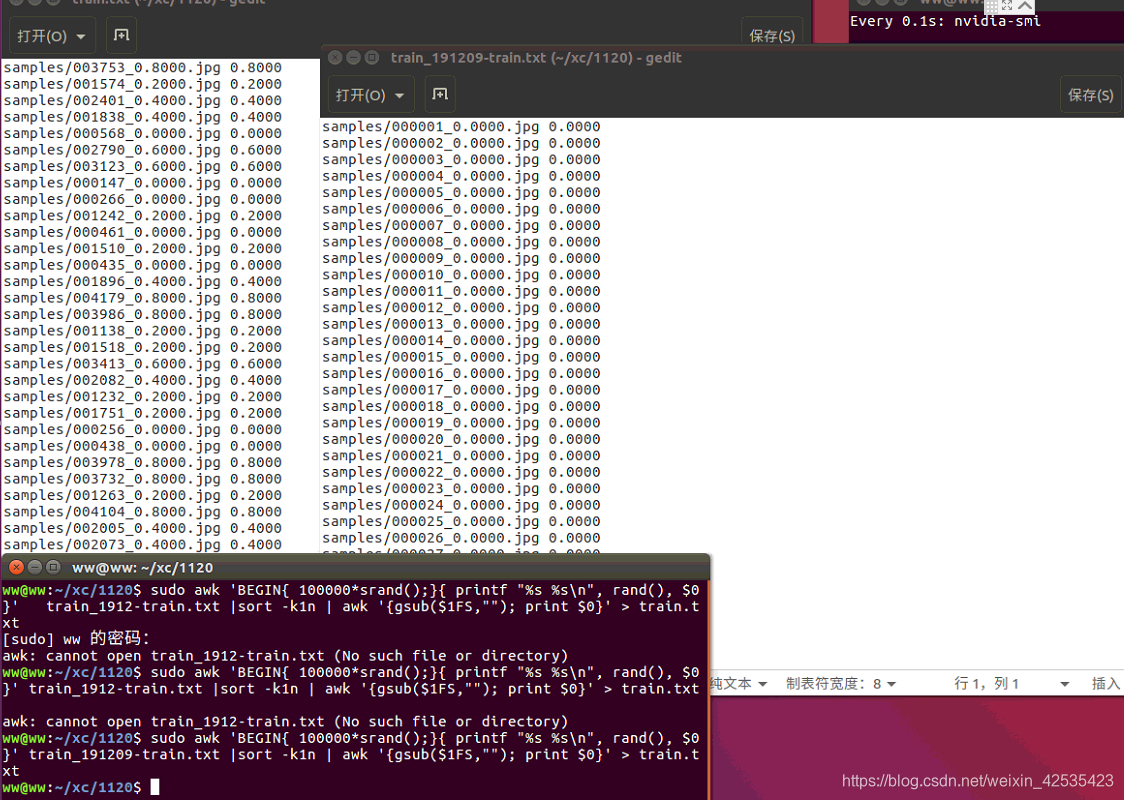
在需要打乱的txt文件所在文件夹进行运行命令。
- 得到的都是侥幸,失去才是常态!
- 钱到用时方恨少,点赞不够吃不饱,手有余香请点赞,您要赏点我不敢!


















 8339
8339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









