




元学习的基本概念可以参考【一文入门元学习】这篇文章,个人觉得写的很好!了解了基本概念之后再看联邦元学习的内容就很好理解了。
《Personalized Federated Learning: A Meta-Learning Approach》这篇文章利用元学习来实现联邦个性化学习,将用户看作元学习中的多个任务。和元学习一样,其目标是找到一个初始化模型,当前用户或新用户只需对他们的本地数据执行一步或几步梯度下降,便可将模型适应他们的本地数据集。这样当有一个新用户进来时,就可以通过一步或几步梯度下降快速获得一个高效的个性化模型。
文章主要内容有三点:
1、将元学习和FL进行结合,具体以FedAvg为框架,以MAML为内容,提出Per-FedAvg算法。
2、从理论角度分析Per-FedAvg在非凸函数下的收敛性。
3、描述“用户数据底层分布的相似度”对Per-FedAvg性能的影响。
Per-FedAvg
函数定义
FedAvg的优化目标如(1)所示

假设每个用户获取初始化参数w,使用相对于其自身损失函数 f i f_i fi的一次梯度下降对参数w进行更新,那么优化目标就由(1)变为(3)。其中a是学习率,n是参与训练的任务个数。优化目标F(w)就是所有元函数(用户更新后的本地目标函数)的平均。
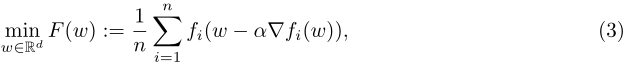
每个用户的元函数可以定义为 F i ( w ) F_i(w) Fi(w),如(4)所示。

算法步骤
完整的算法框架如Algorithm 1所示

-
首先第一步是计算元模型在每个本地元函数的梯度 ▽ F i ( w ) ▽F_i(w) ▽Fi(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 895
895




 到【灌水乐园】发言
到【灌水乐园】发言









