






—、系统环境初始化
1、机器资源介绍
2、设置IP为static模式
3、设置hosts映射文件
4、关闭 firewalld,iptables 与 selinux
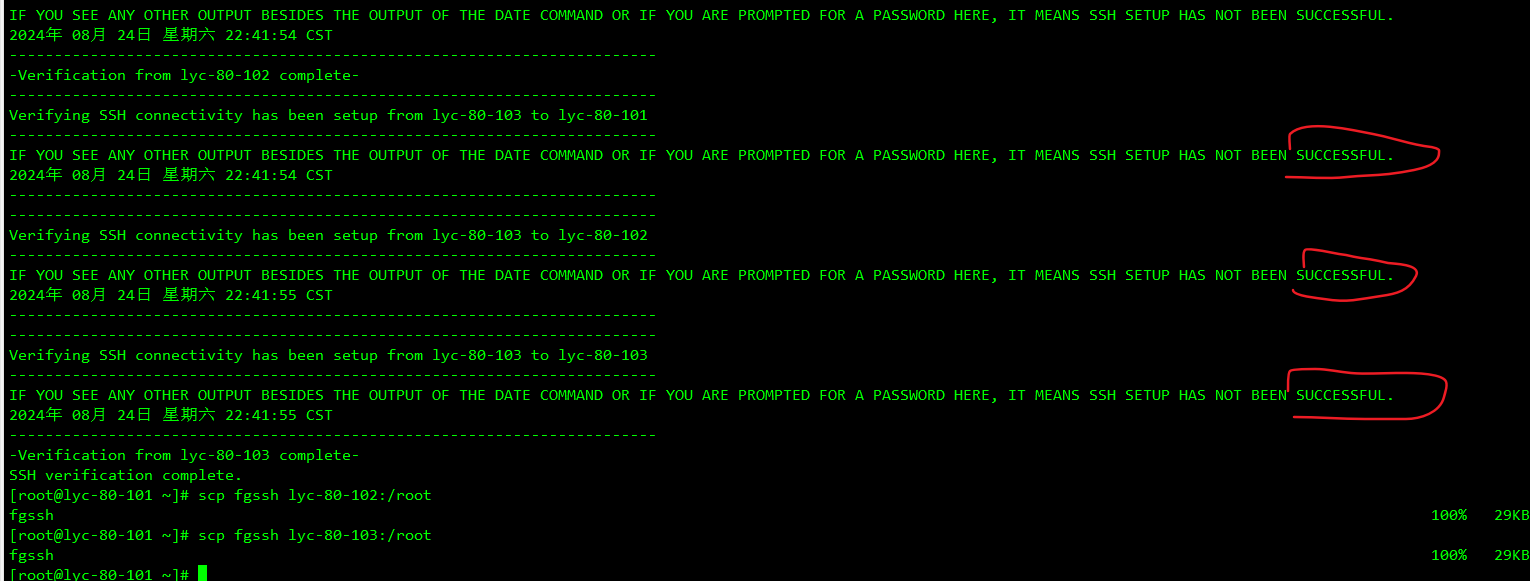
5、设置免密登录
6、更换源文件
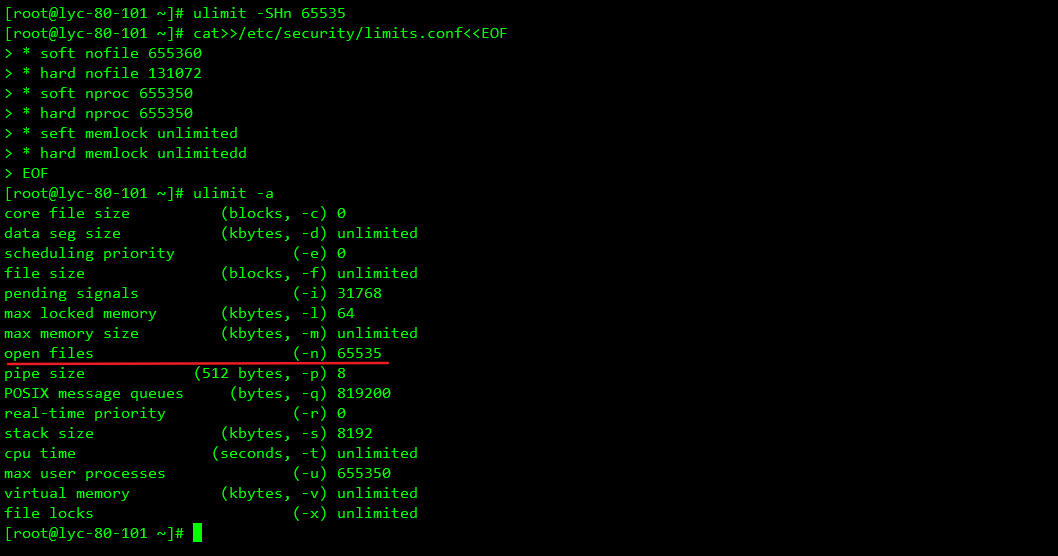
7、更改系统句柄
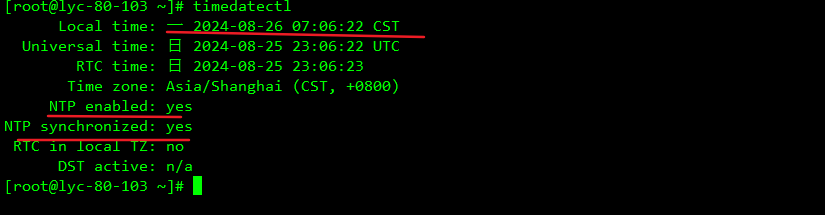
8、3台机器时间同步
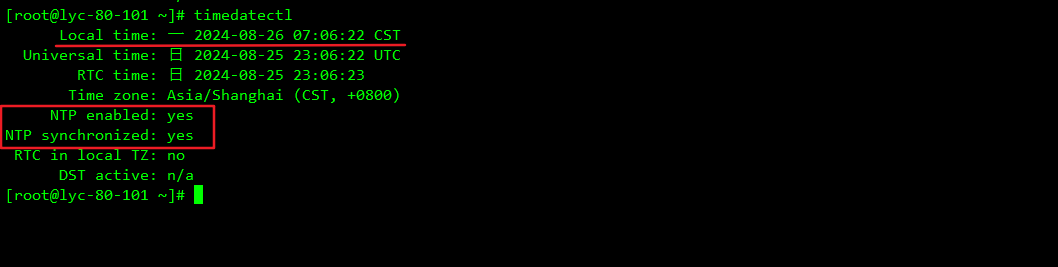

二、配置系统环境依赖
1、准备安装资源
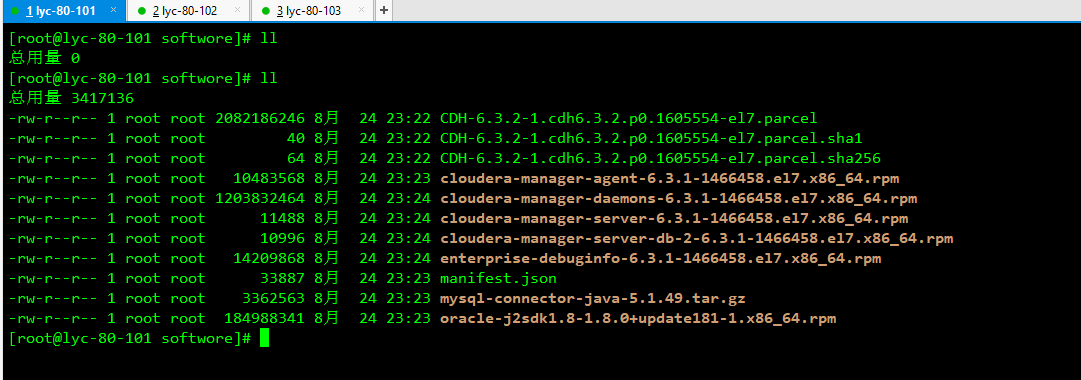
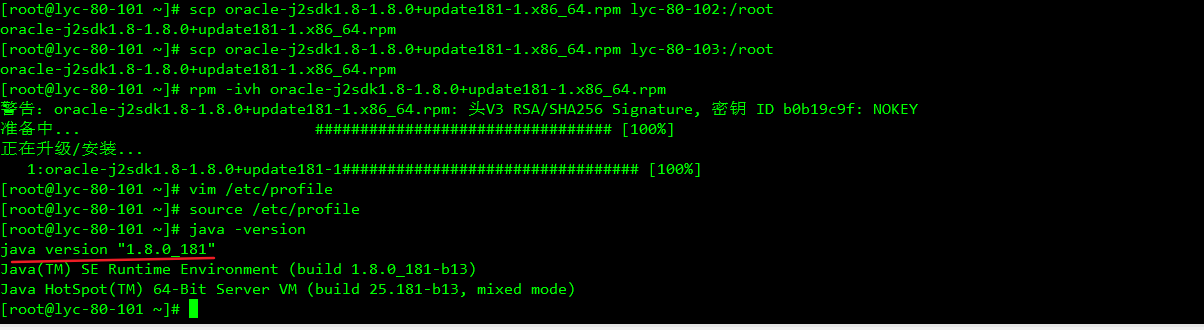
2、安装jdk
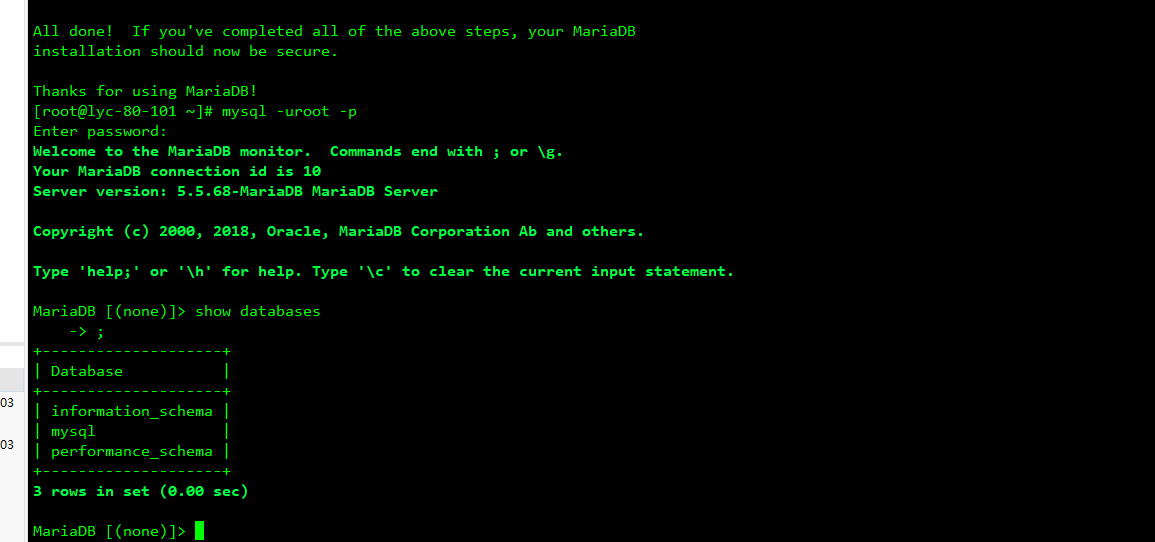
3、安装mariadb-server
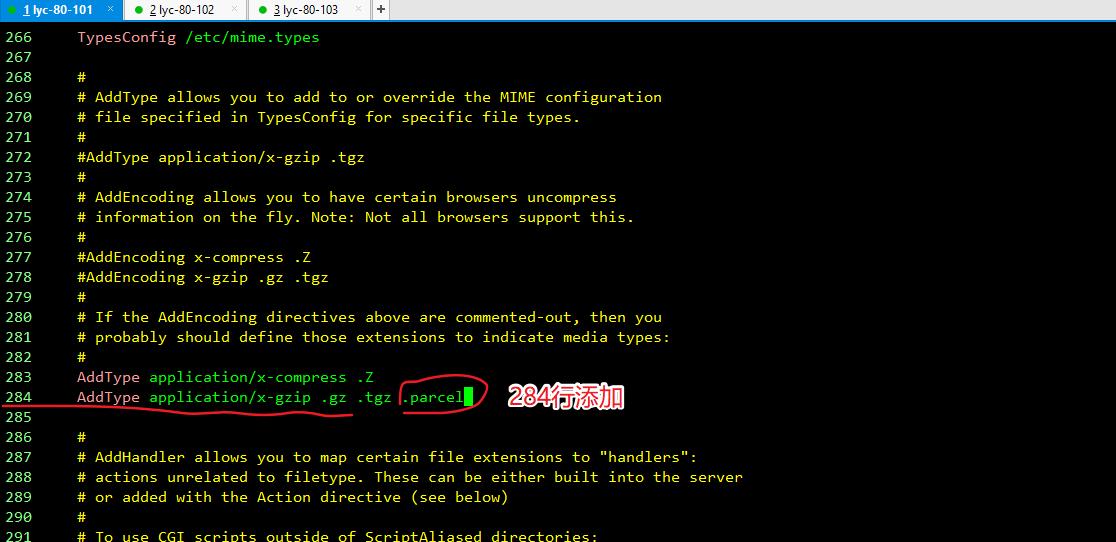
4、配置 httpd 分发服务器
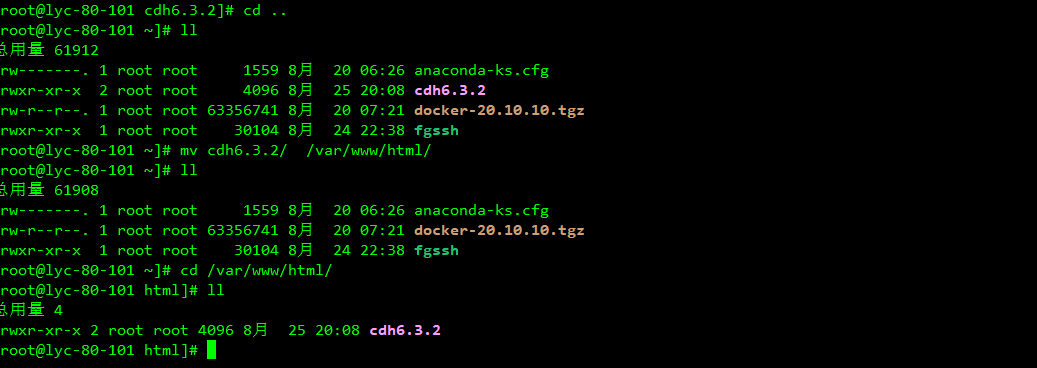
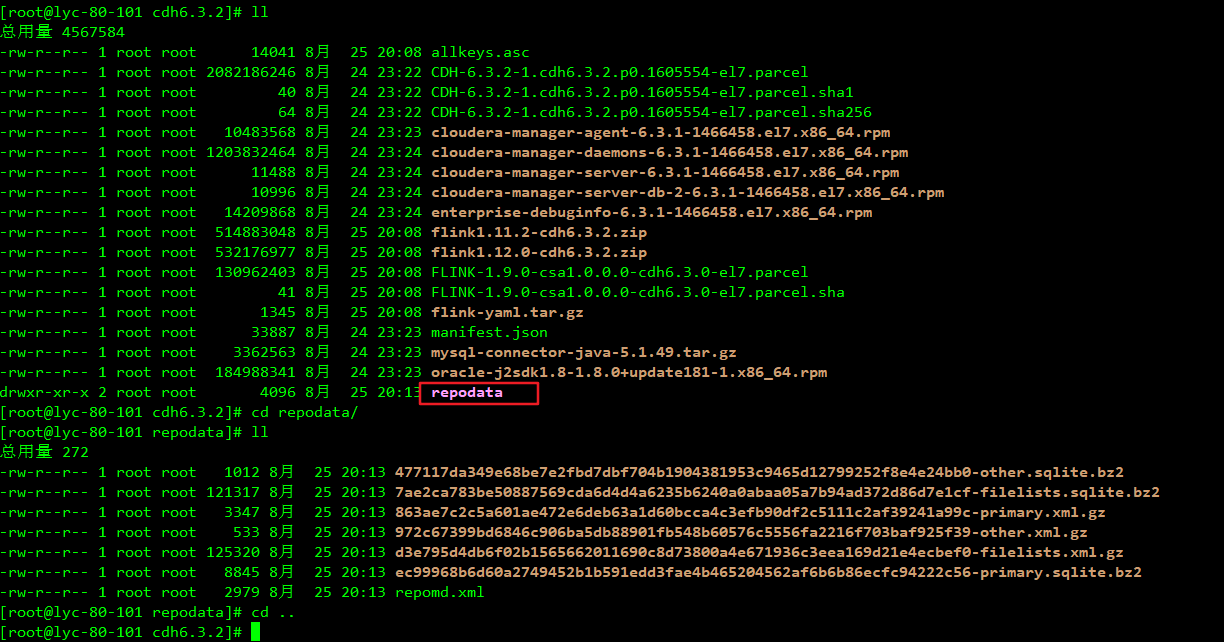
5、制作自定义源

6、配置mysql-jdbc
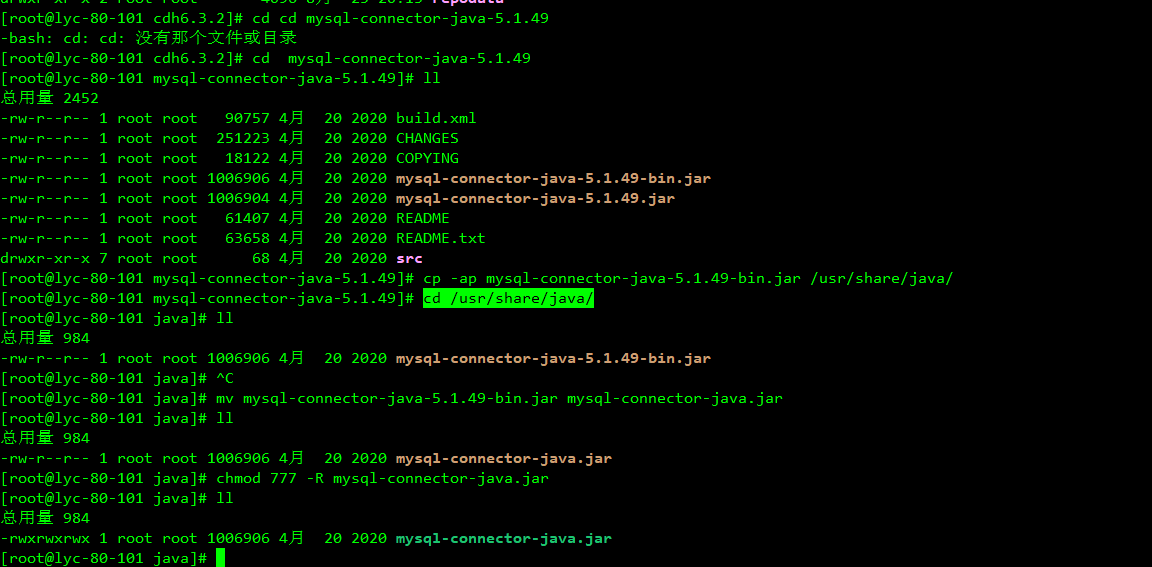
三、安装CDH6.3.2所需环境
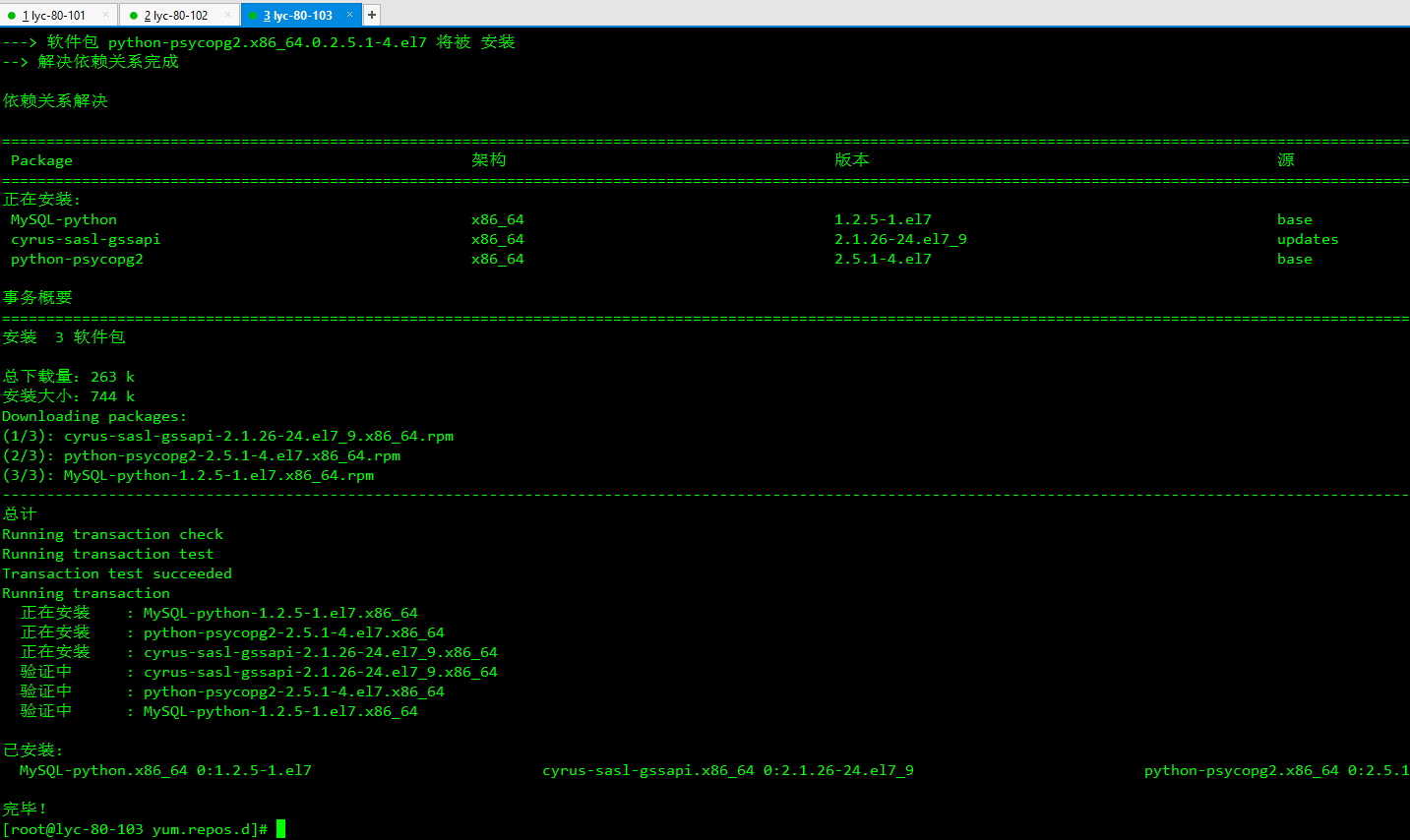
1、安装所需依赖包
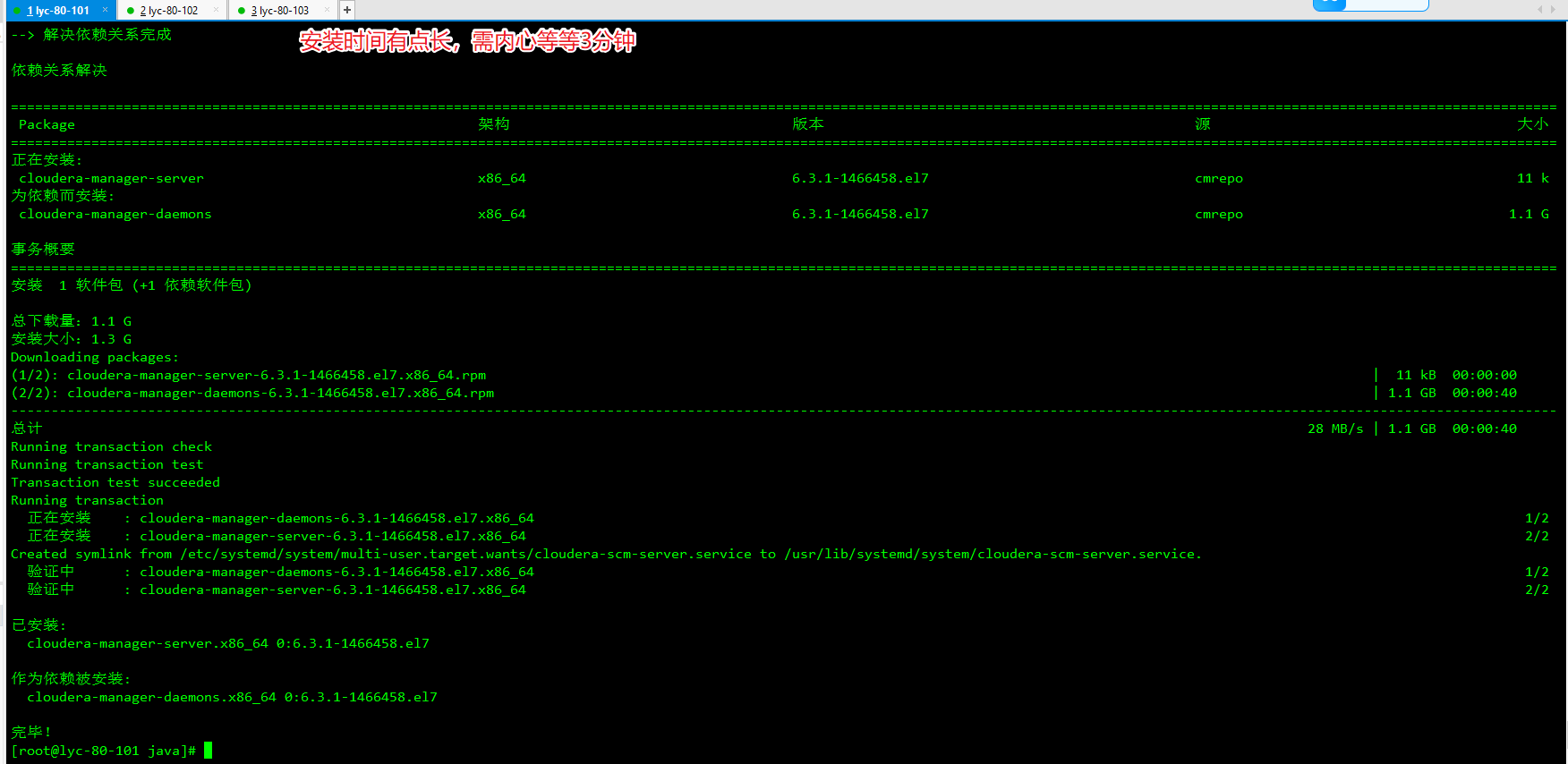
2、安装cloudera-server
3、在mysql中建CM需要库
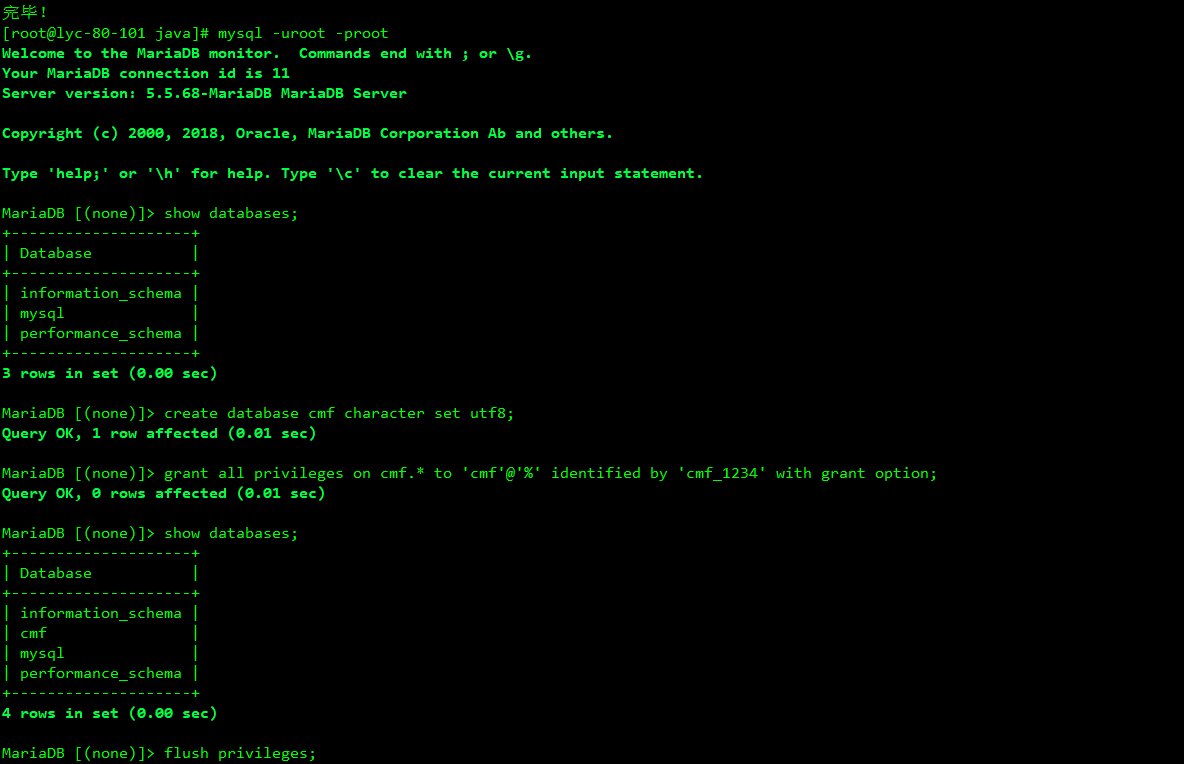
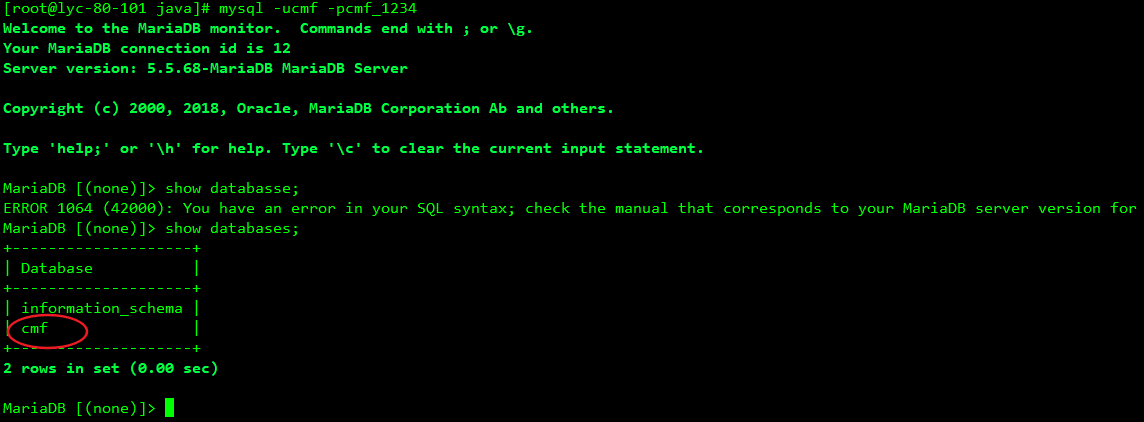
4、注入需要的库
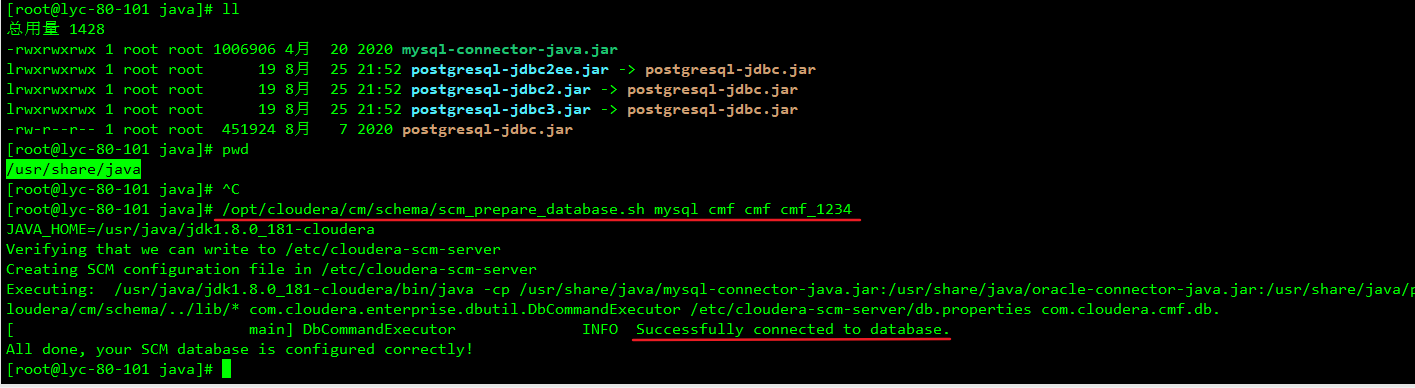
四、配置Cloudera-Manager端
1、安装启动CM
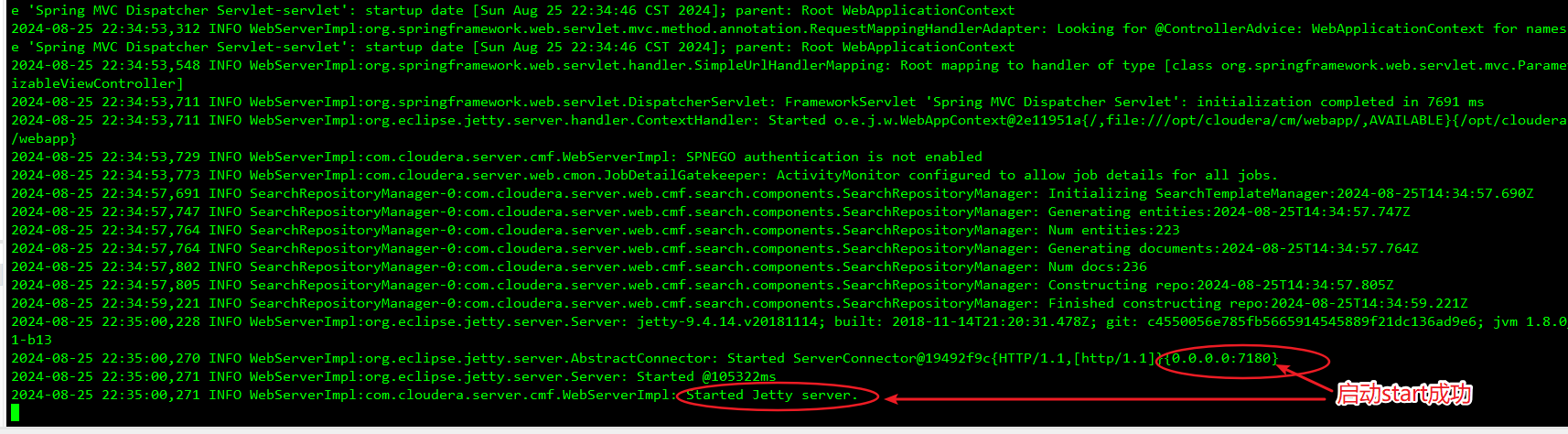
2、打开主机7180页面
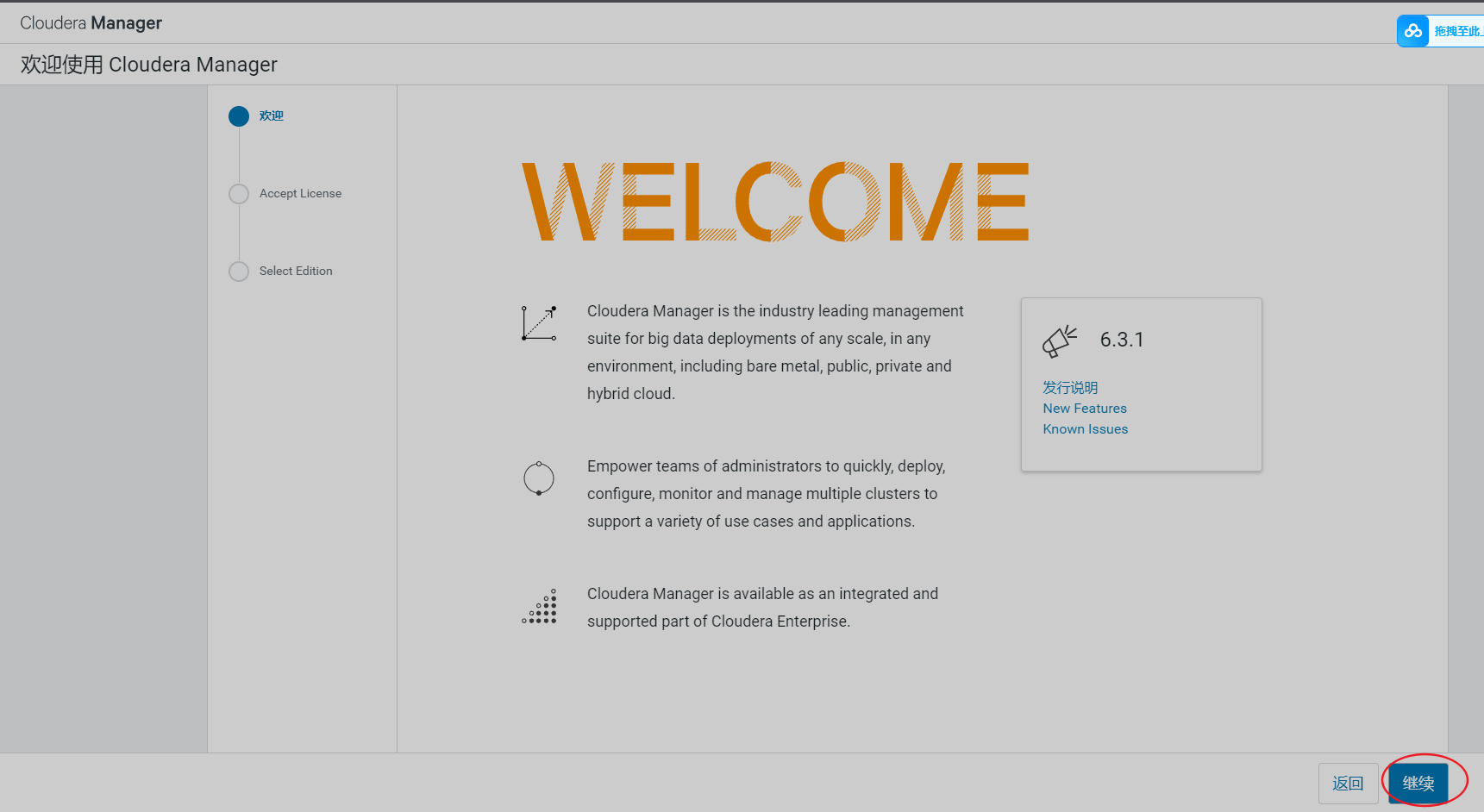
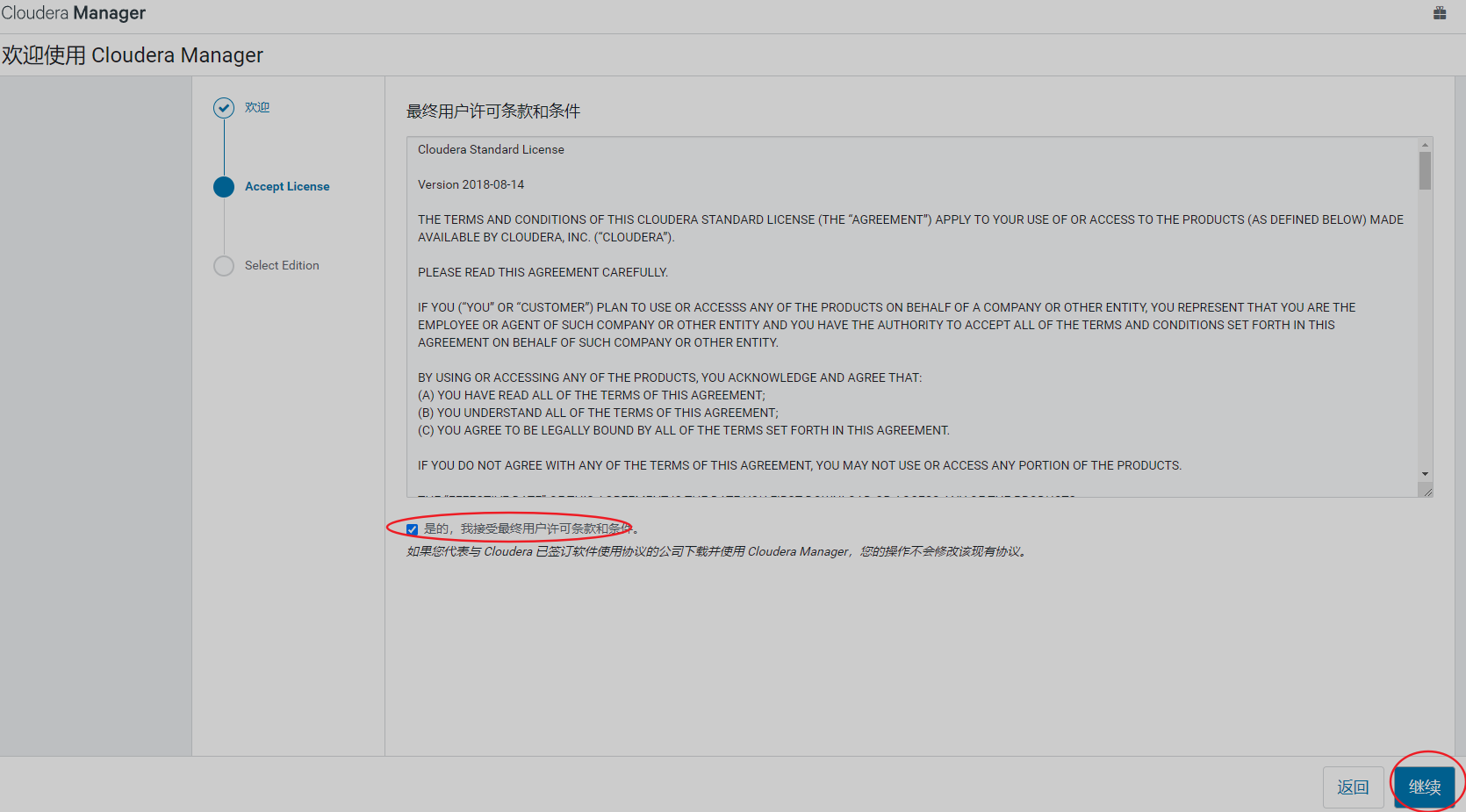
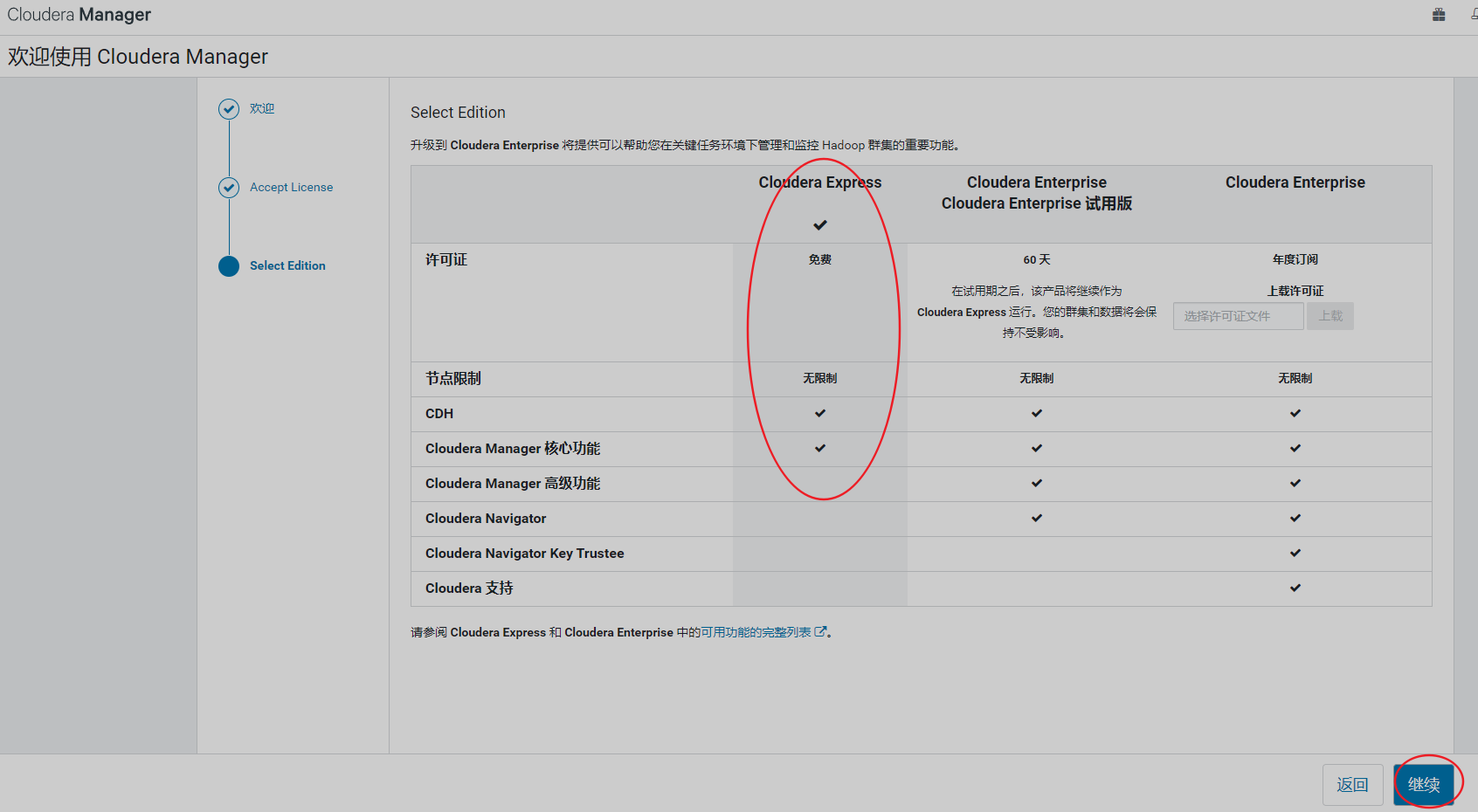
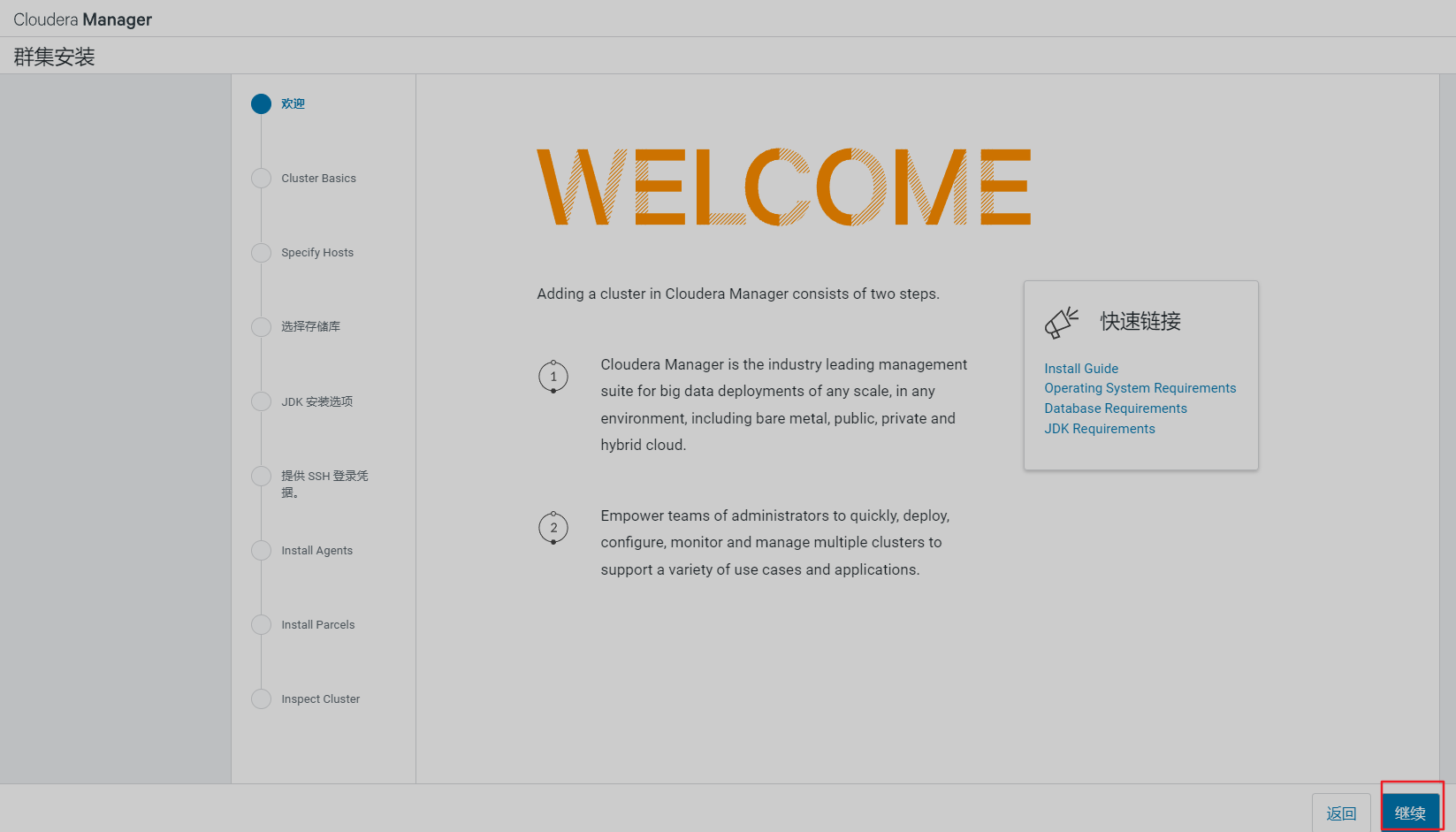
实验环境,选择免费版即可
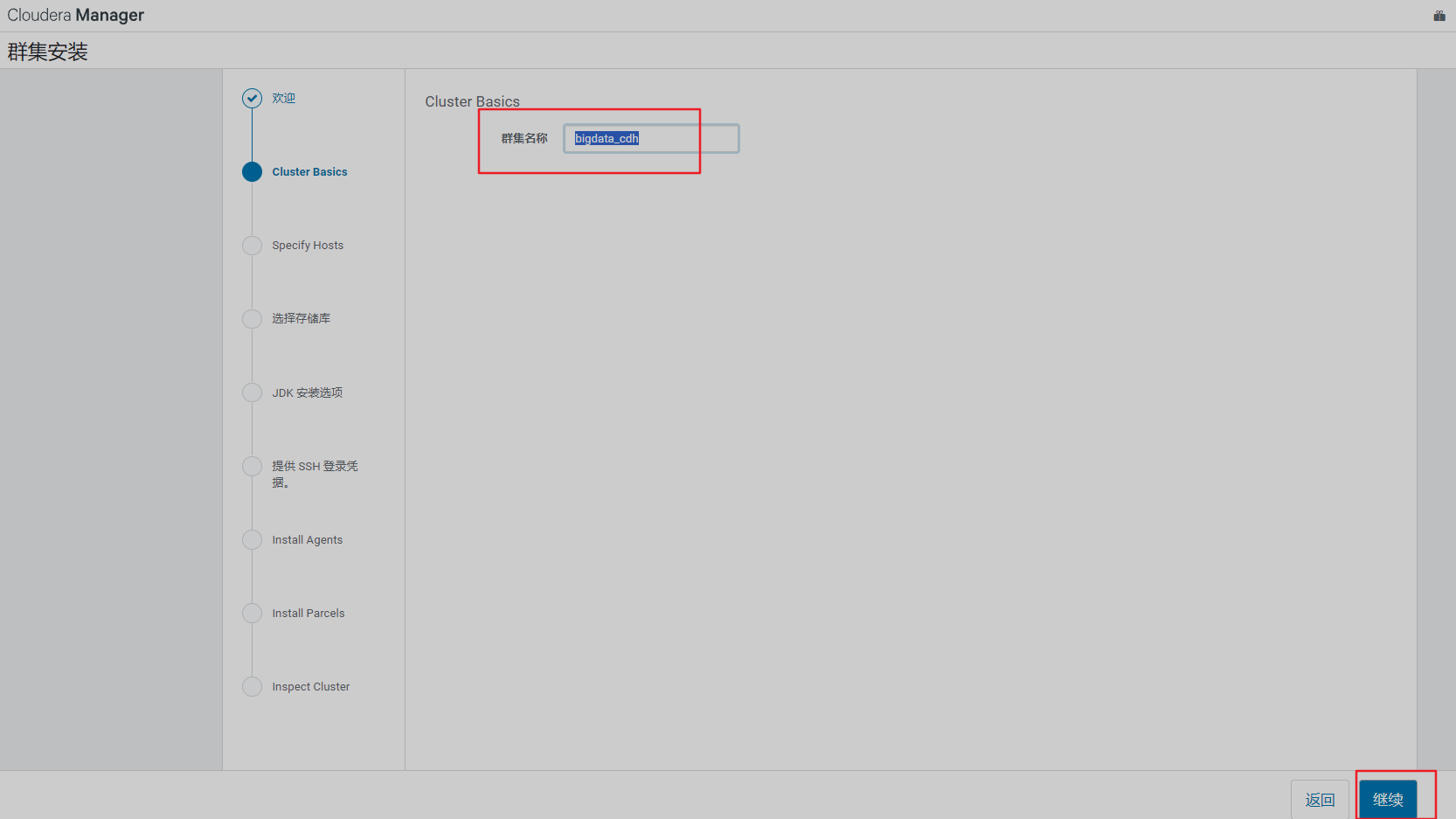
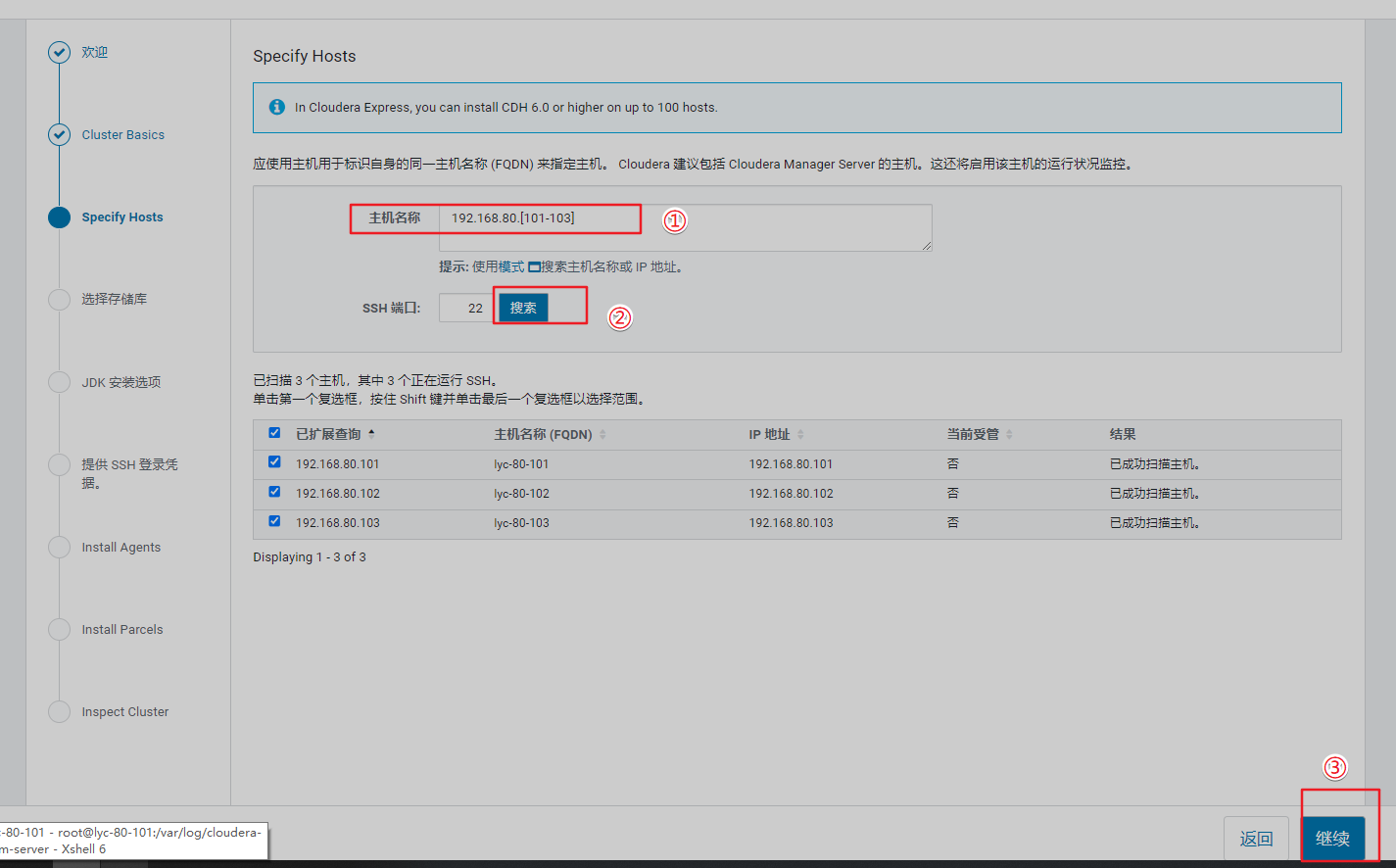
添加集群主机IP
192.168.80.[101-103]
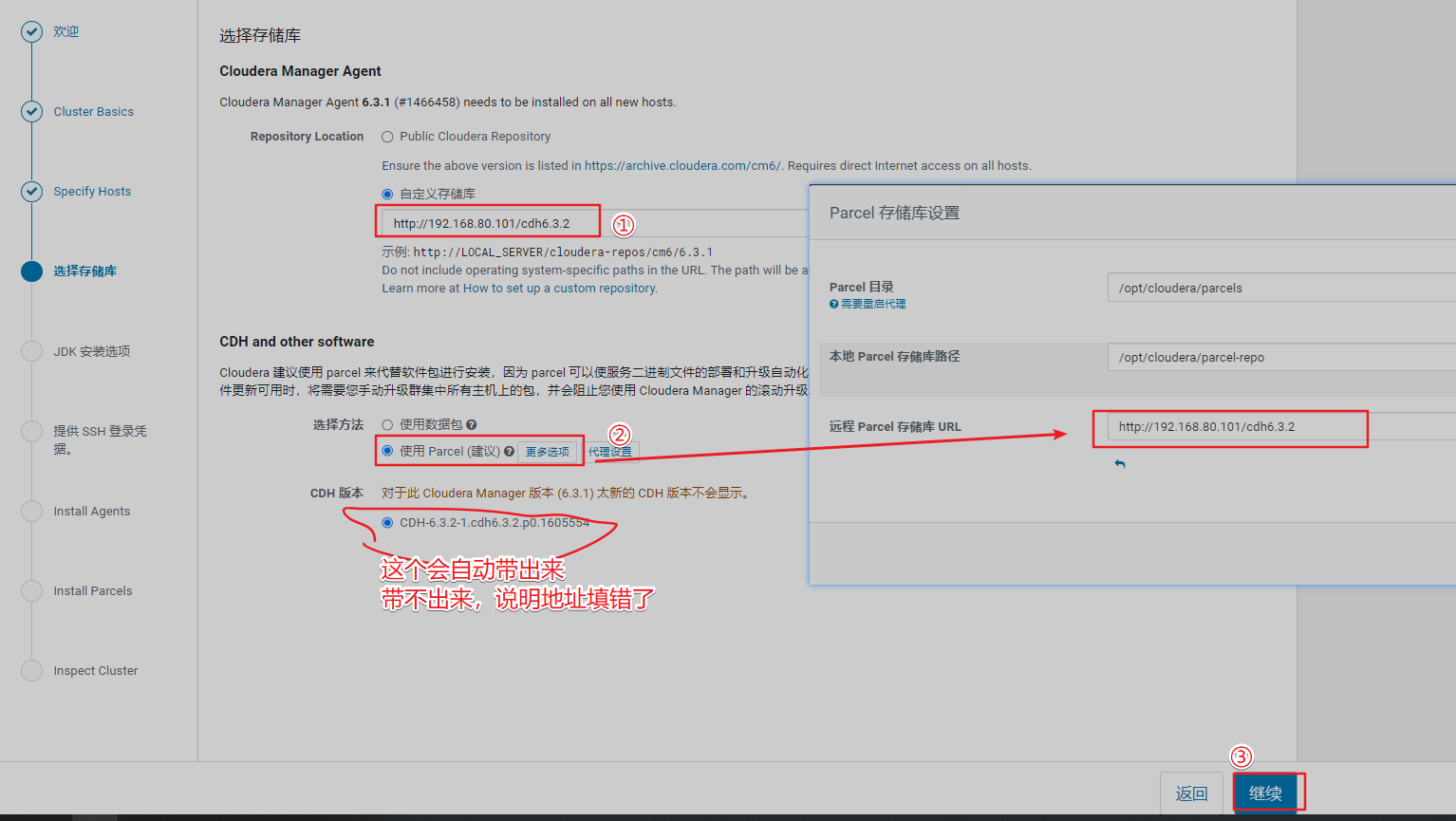
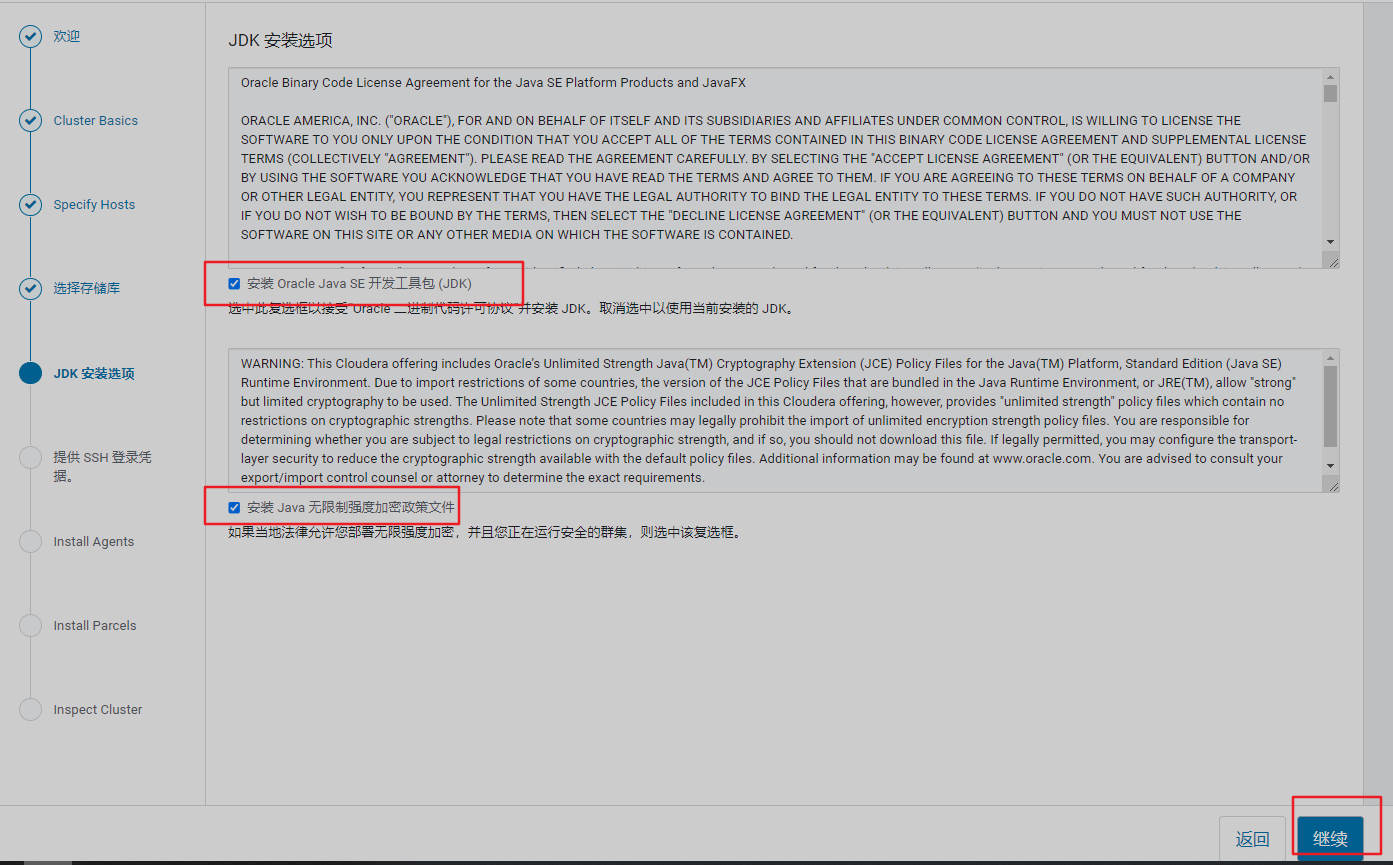
3、选择存储库
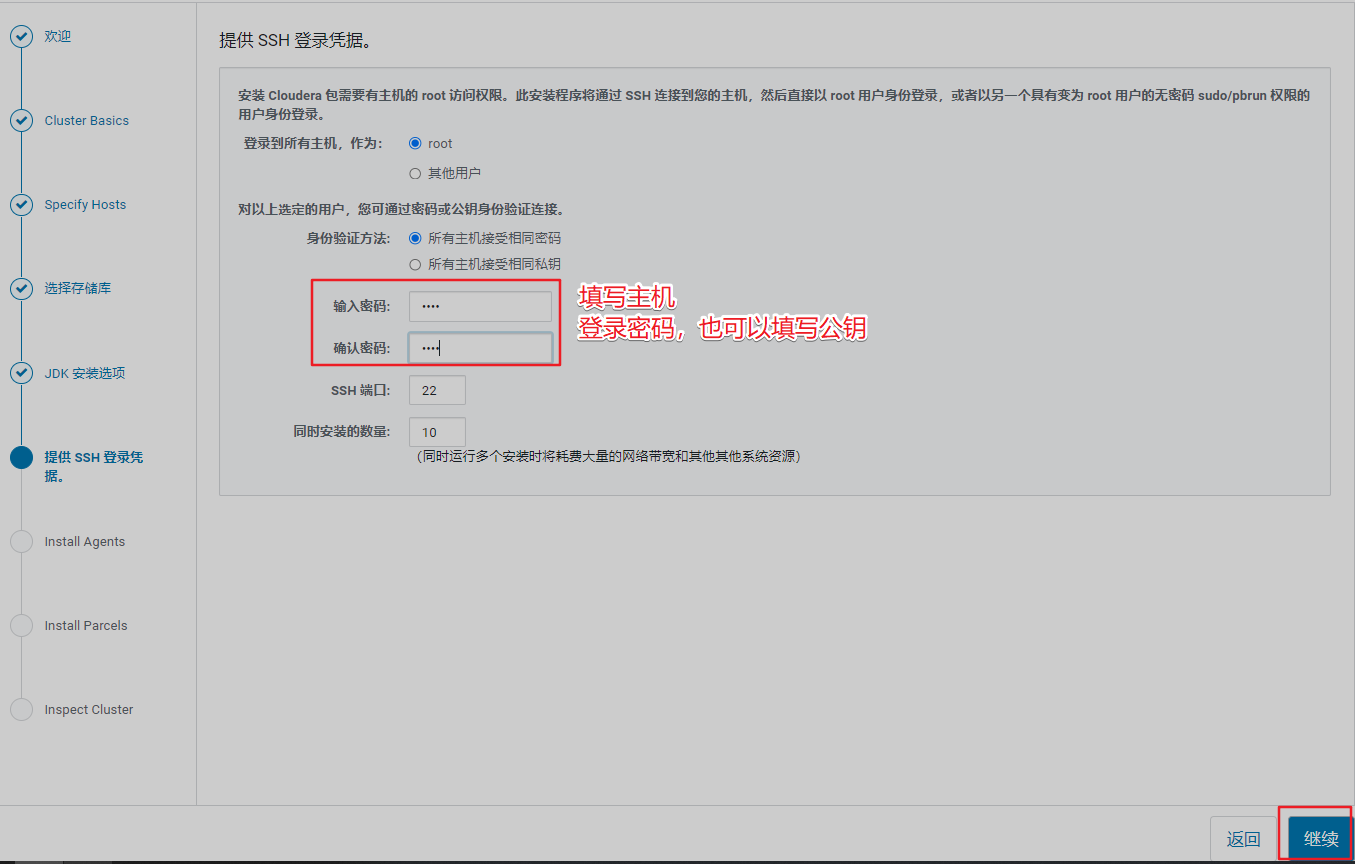
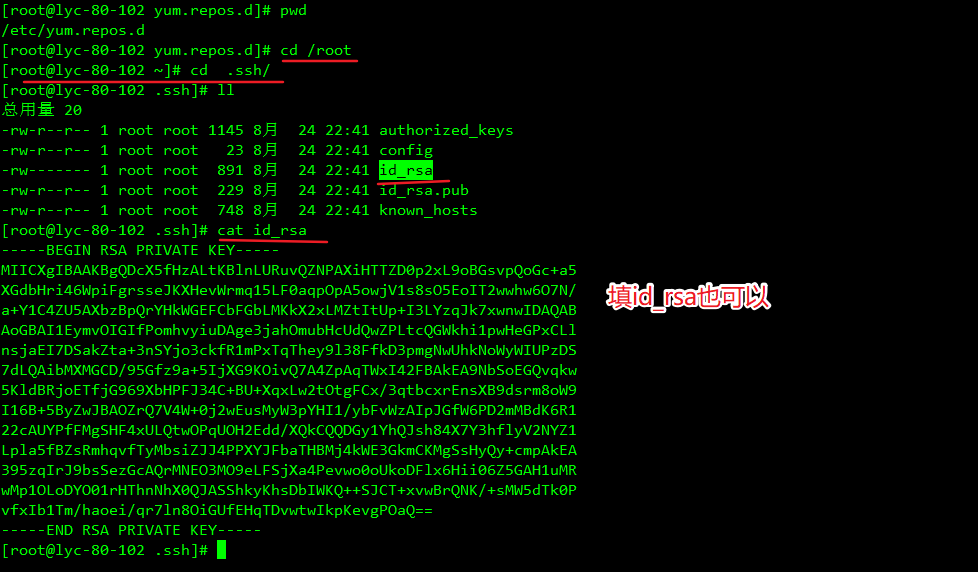
4、填写SSH 登录凭据
分发数据到各节点,注意是否报错-----ps等待时间大约10分钟
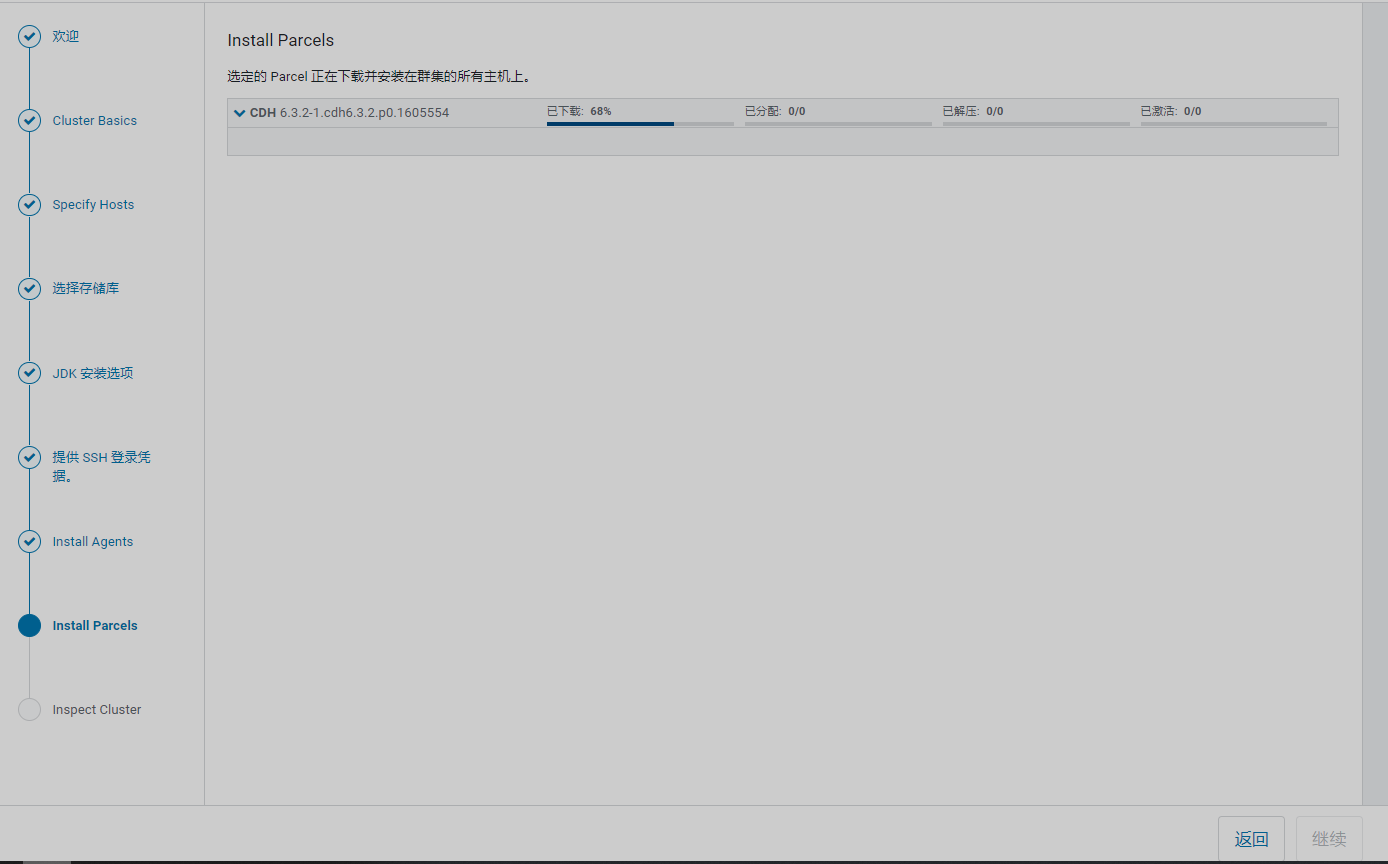
注意观察后台日志
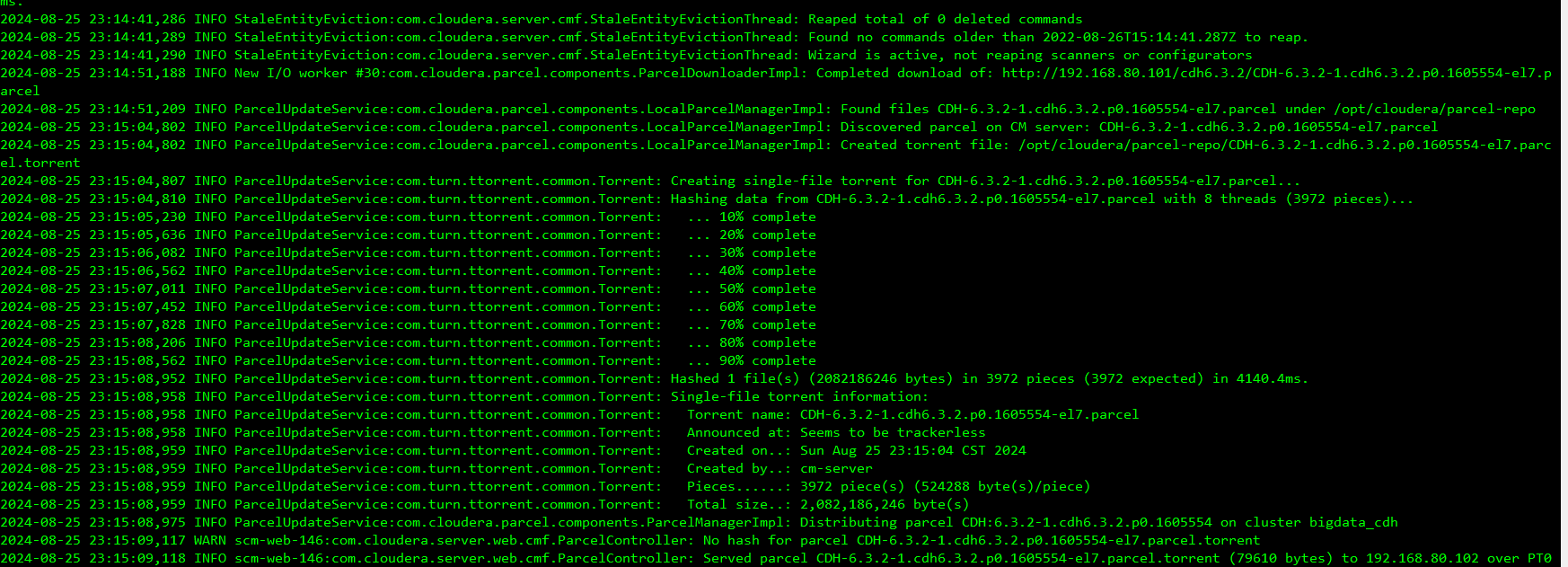

持续观察后台日志
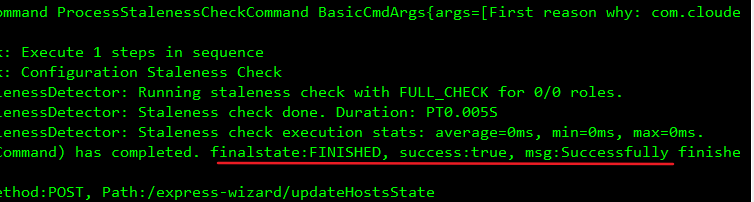
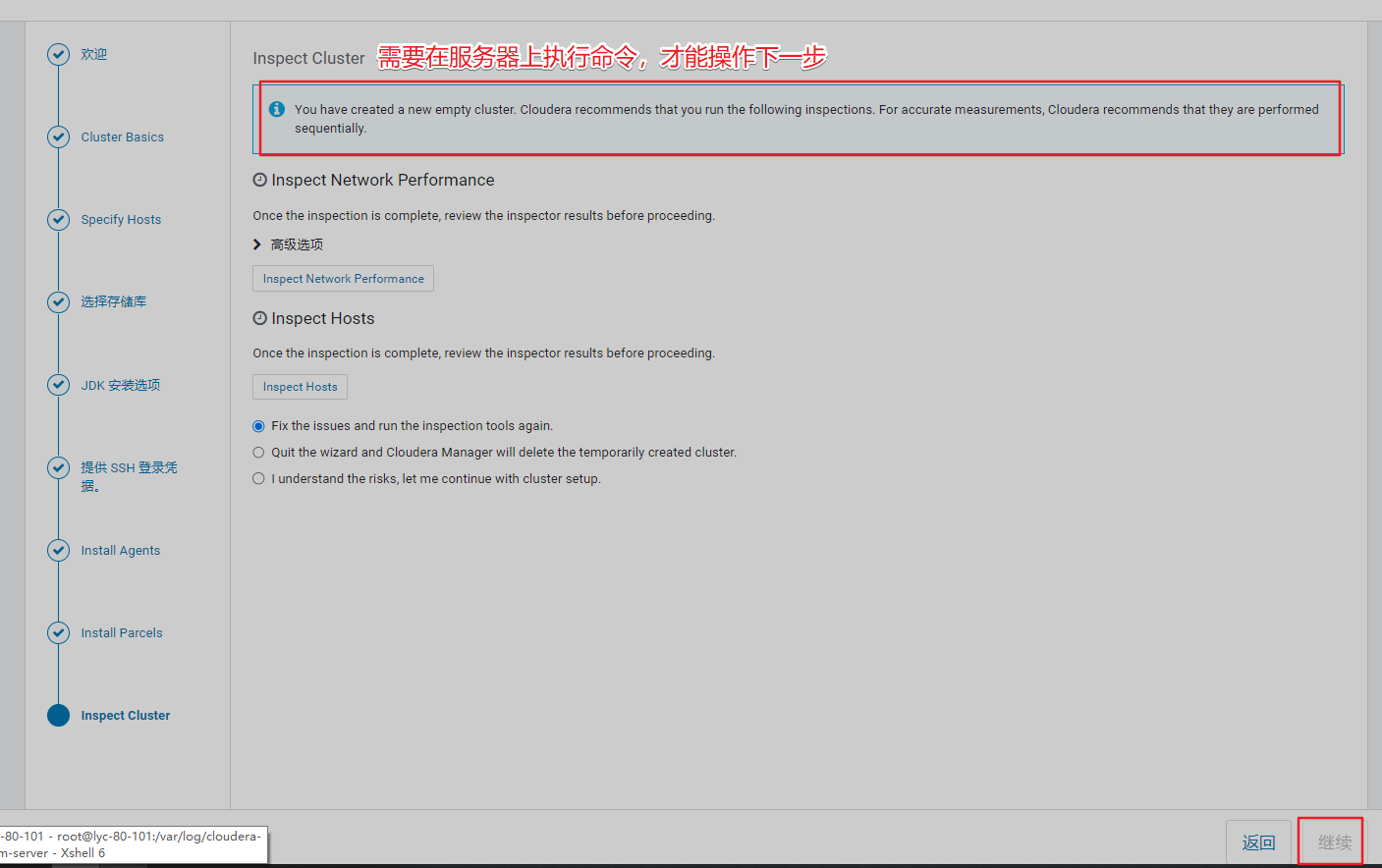
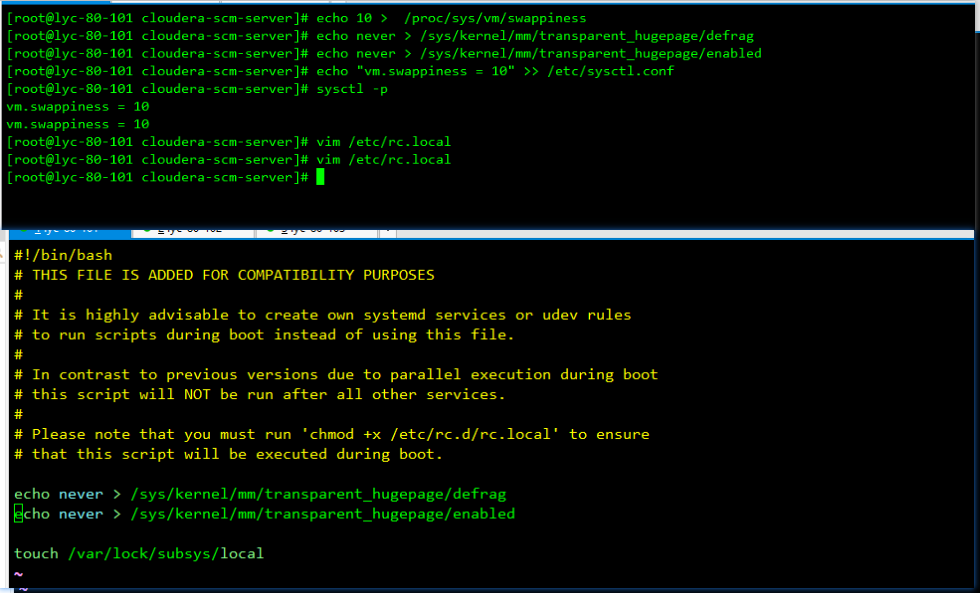
5、在3台机器上全部执行以下命令
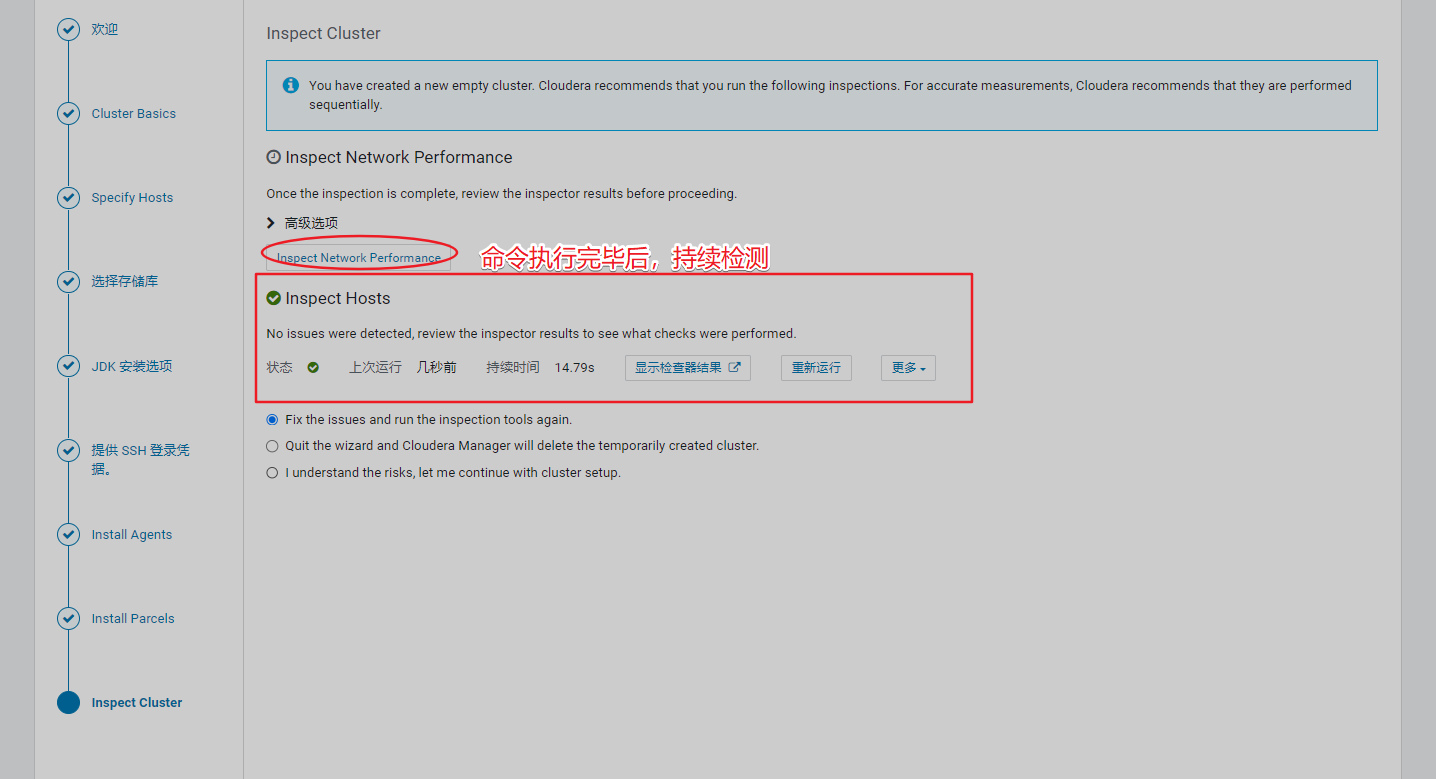
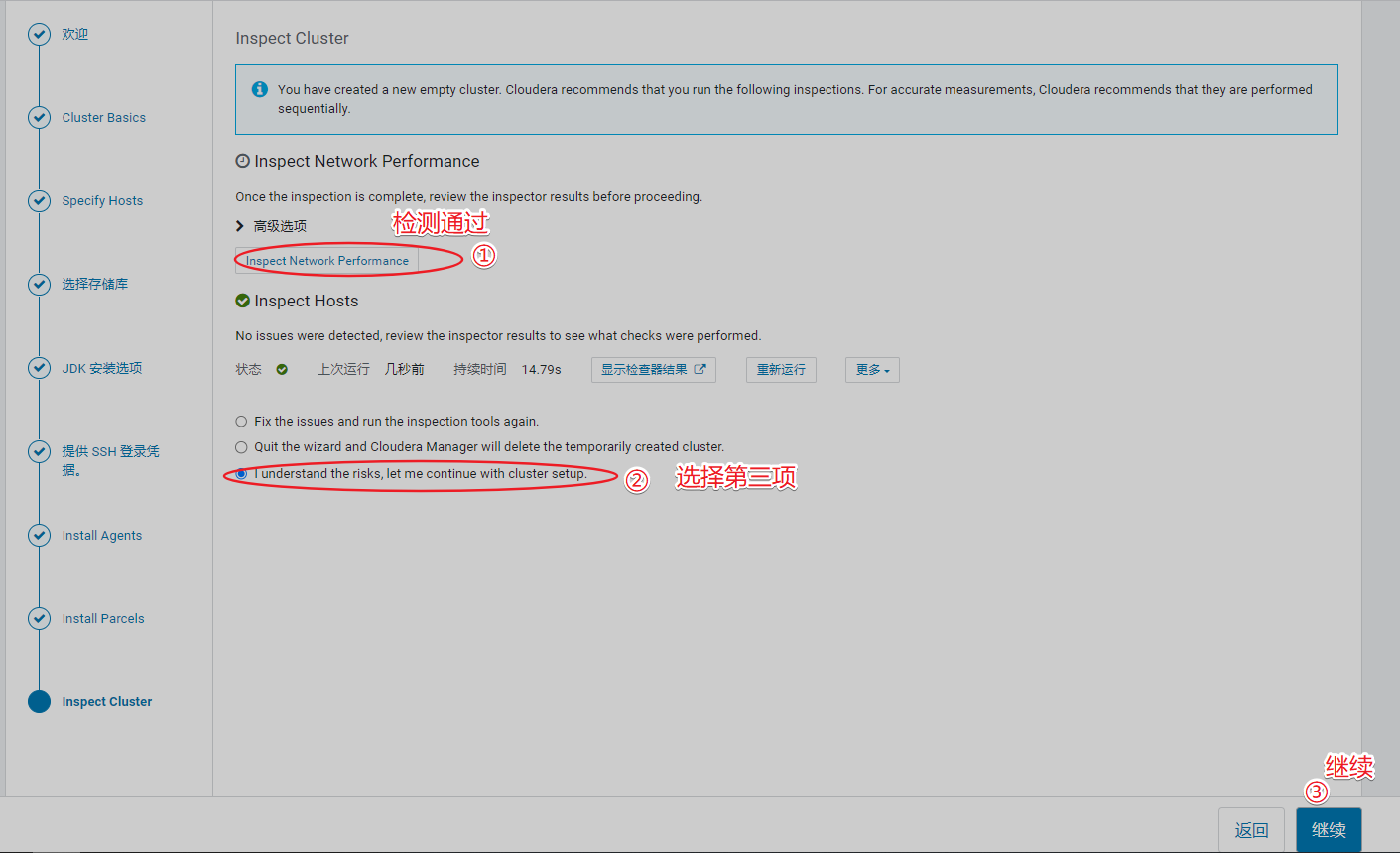
6、必须先安装zk组件
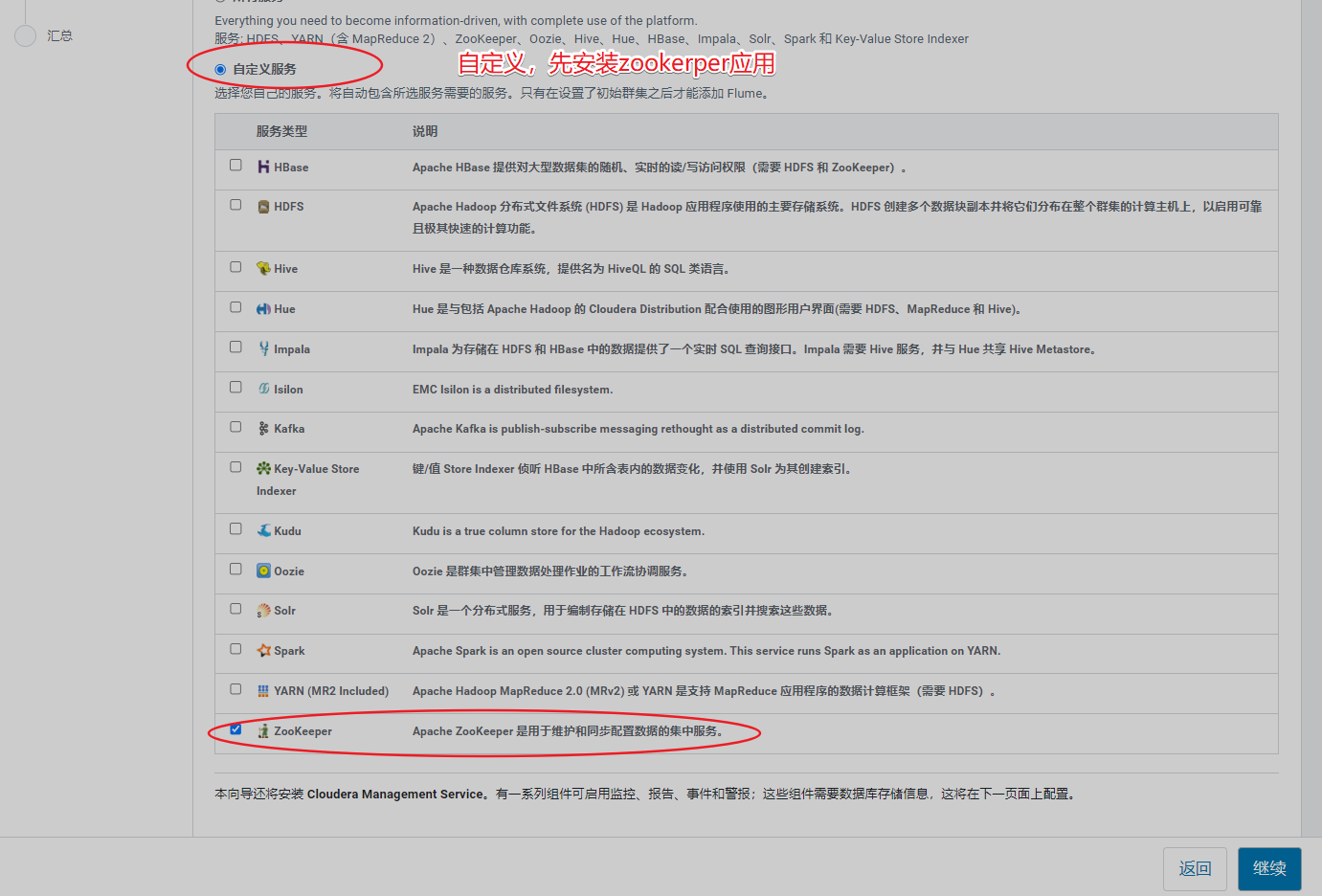
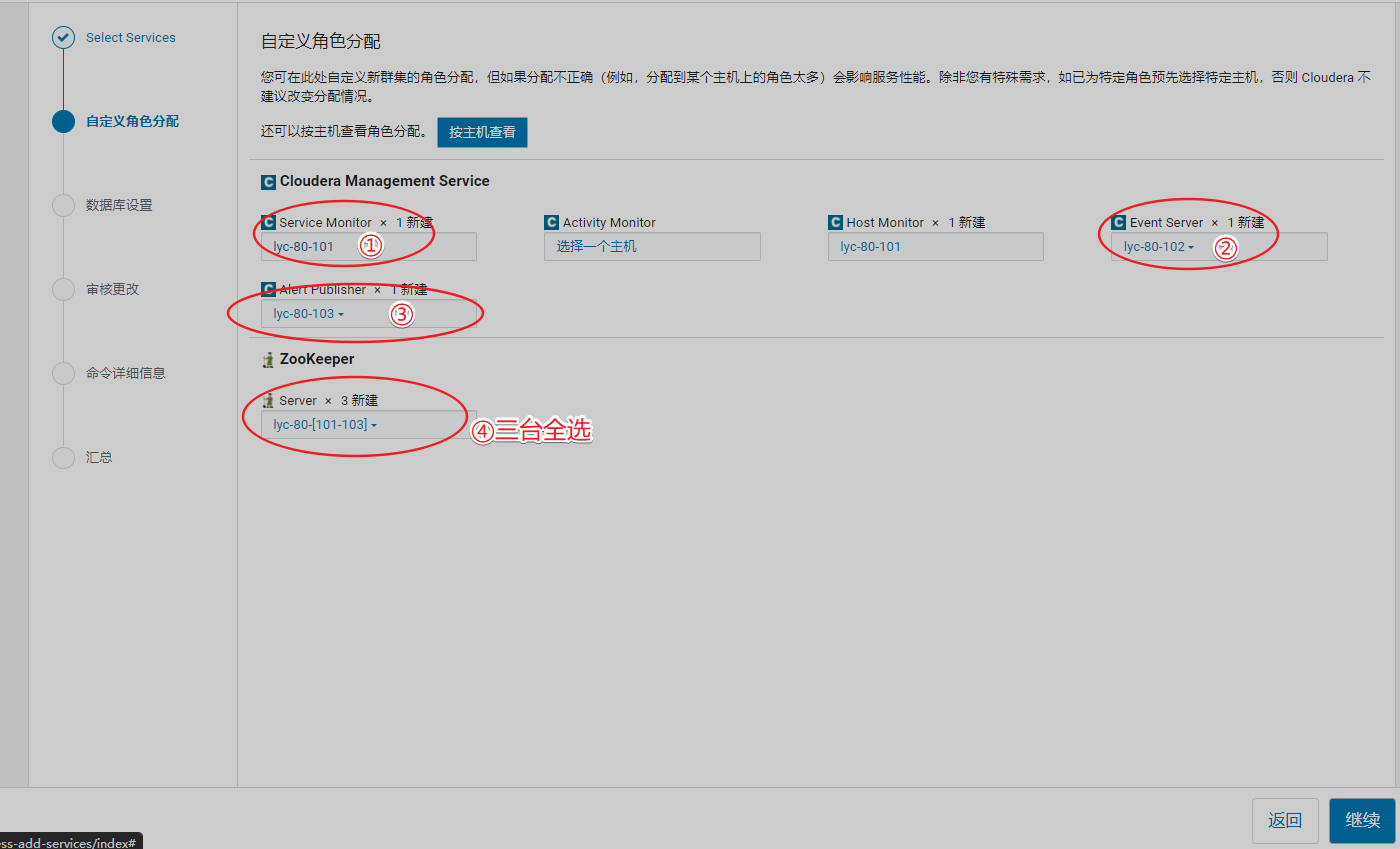
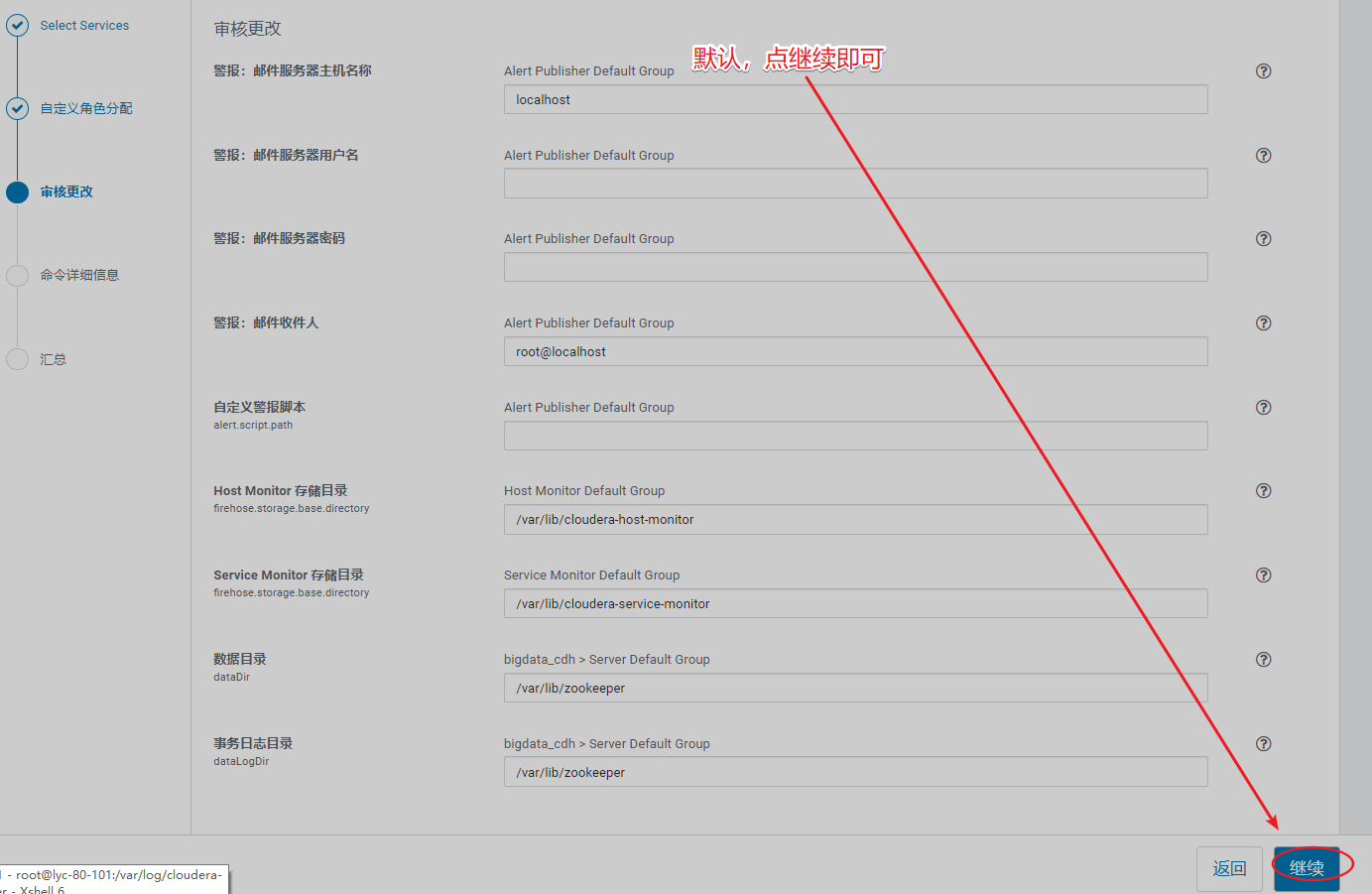
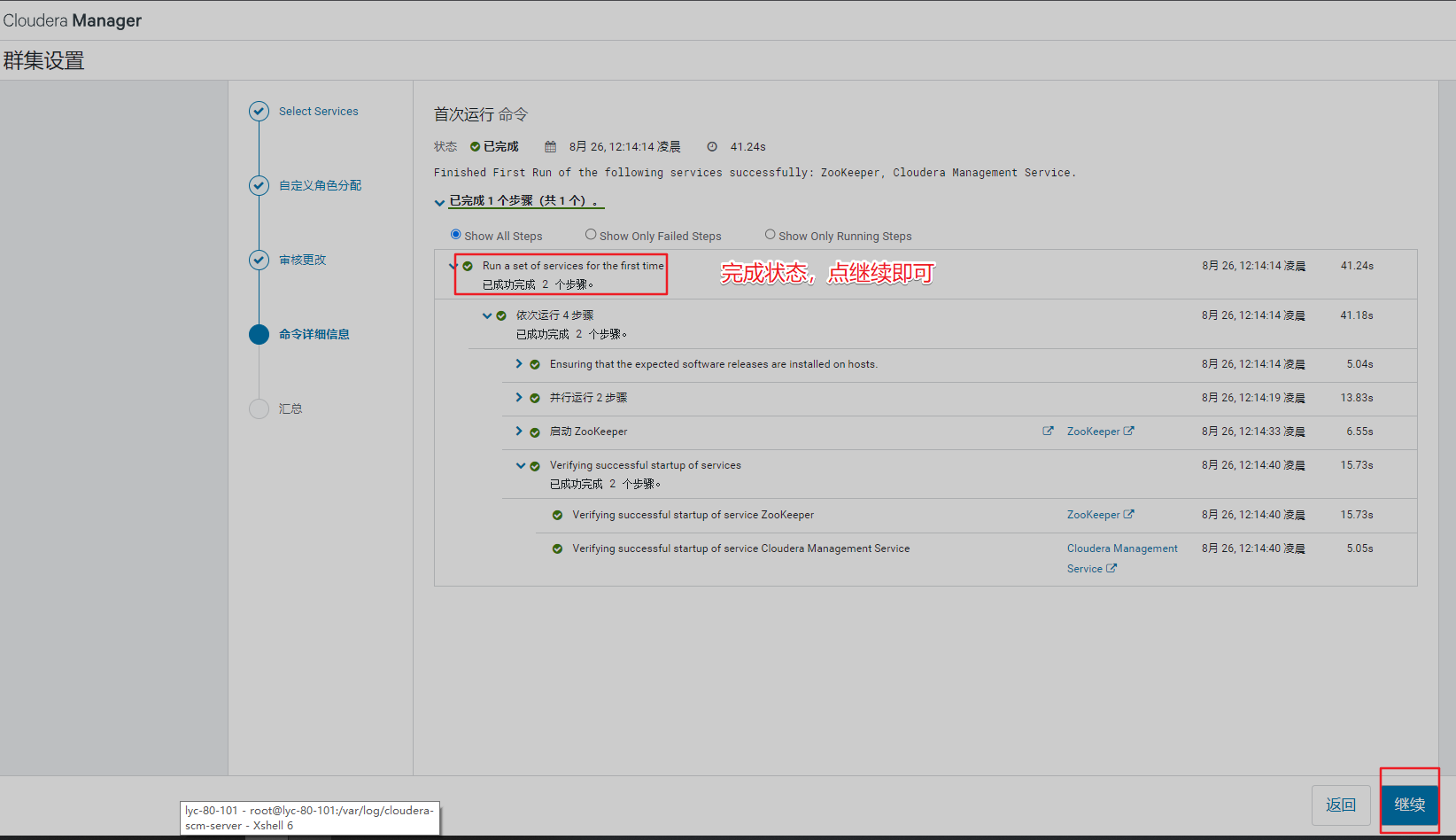
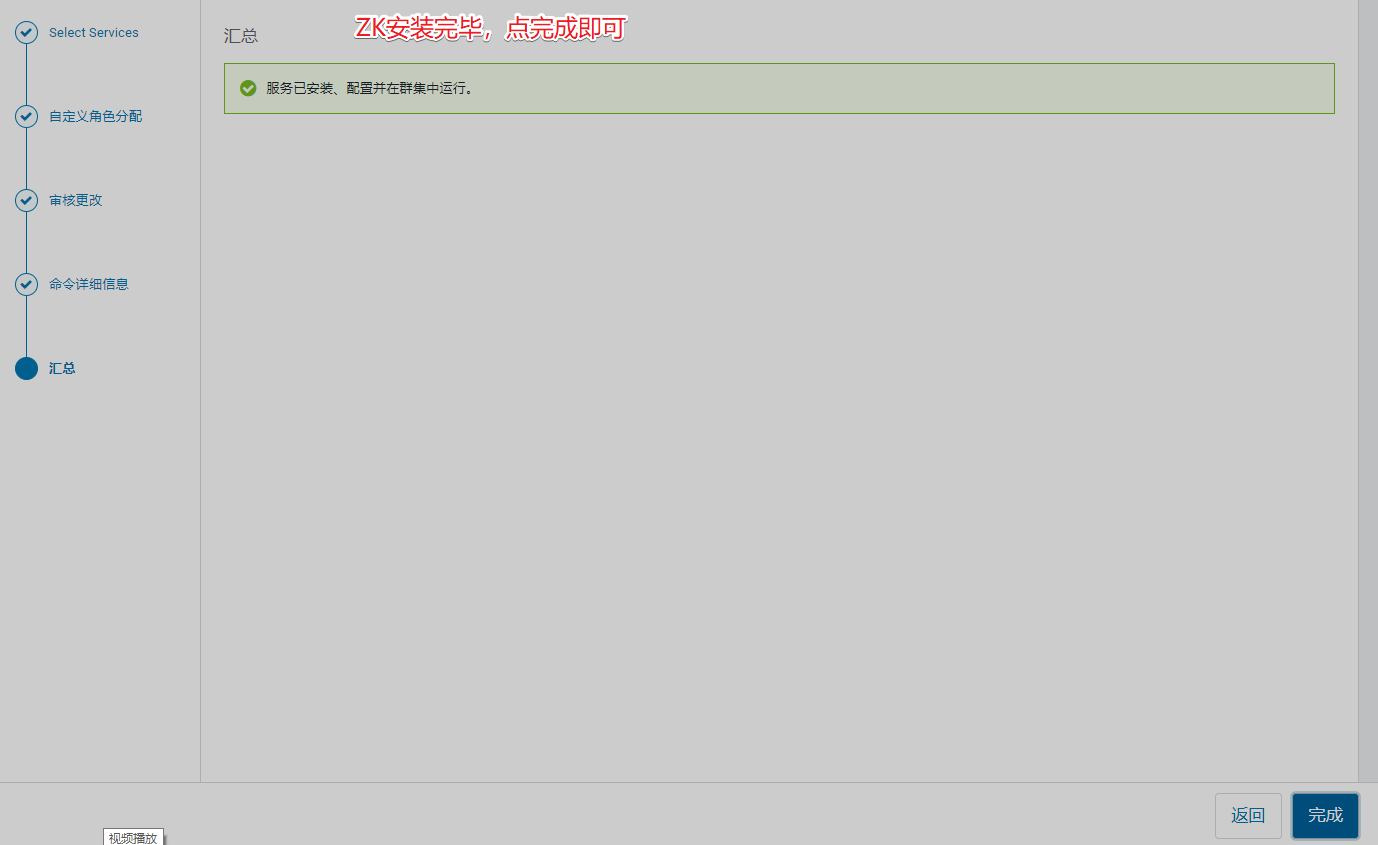
五、安装集群组件
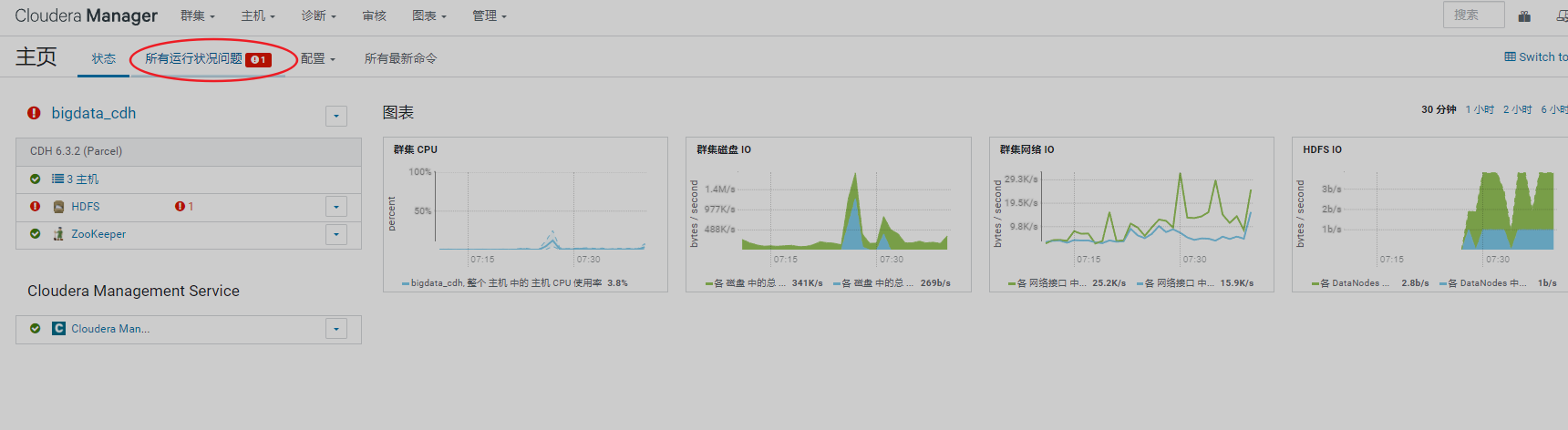
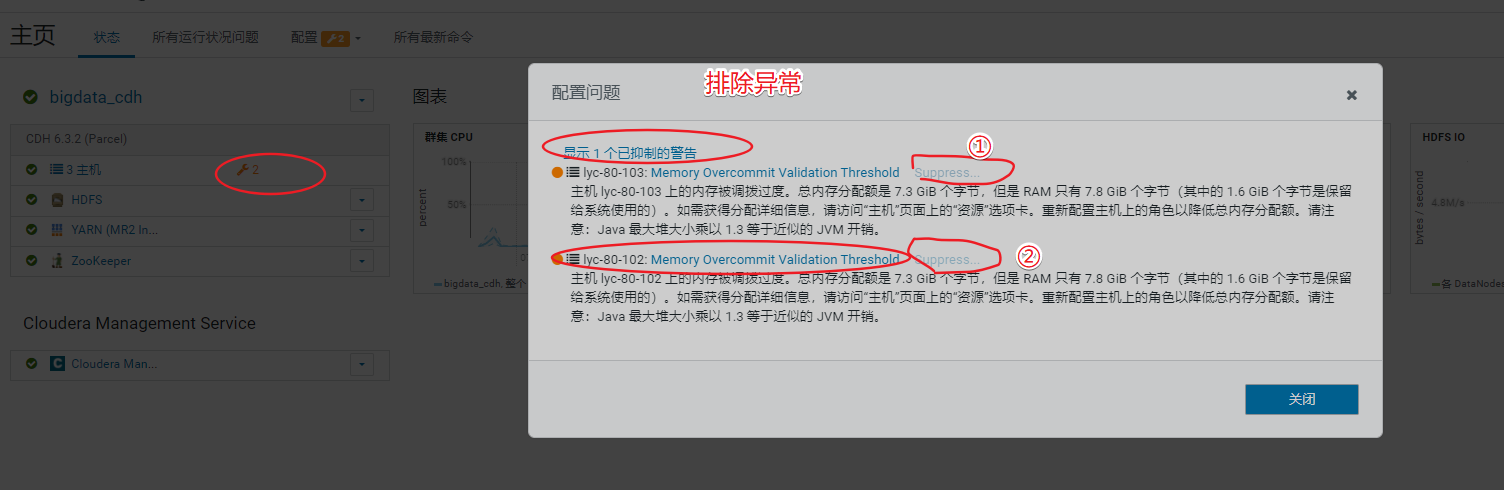
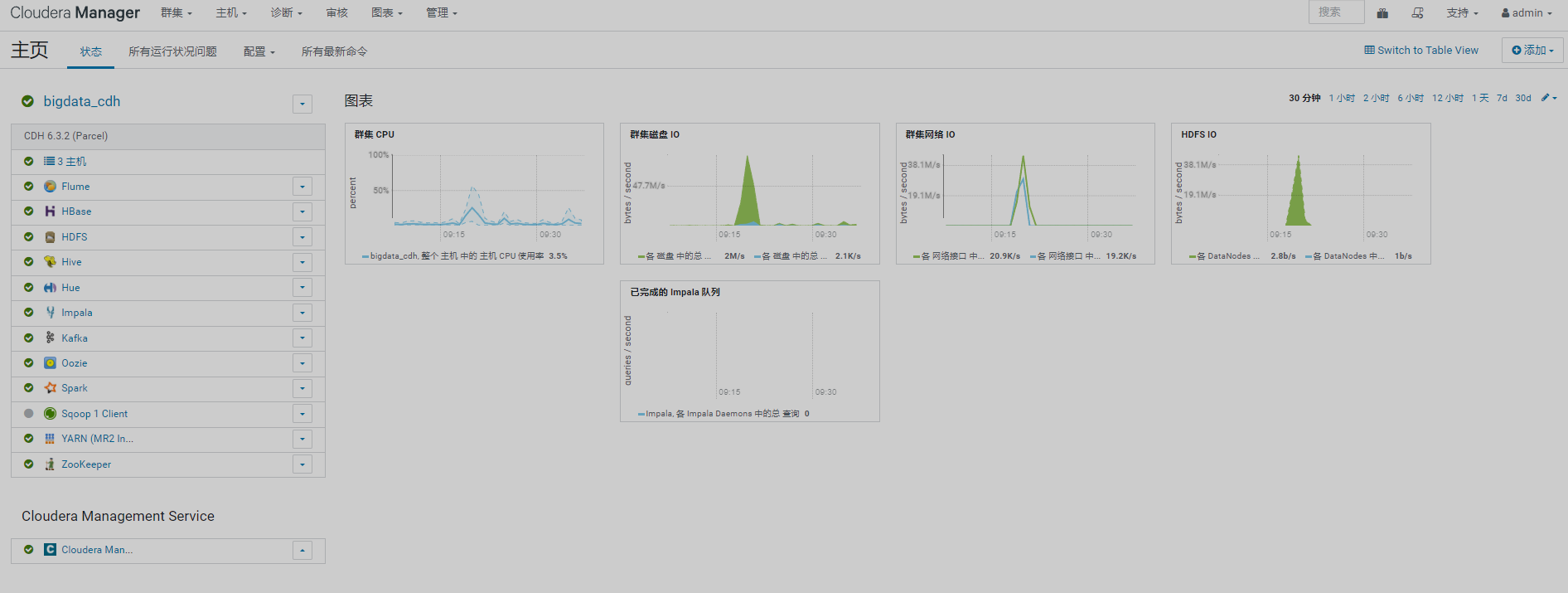
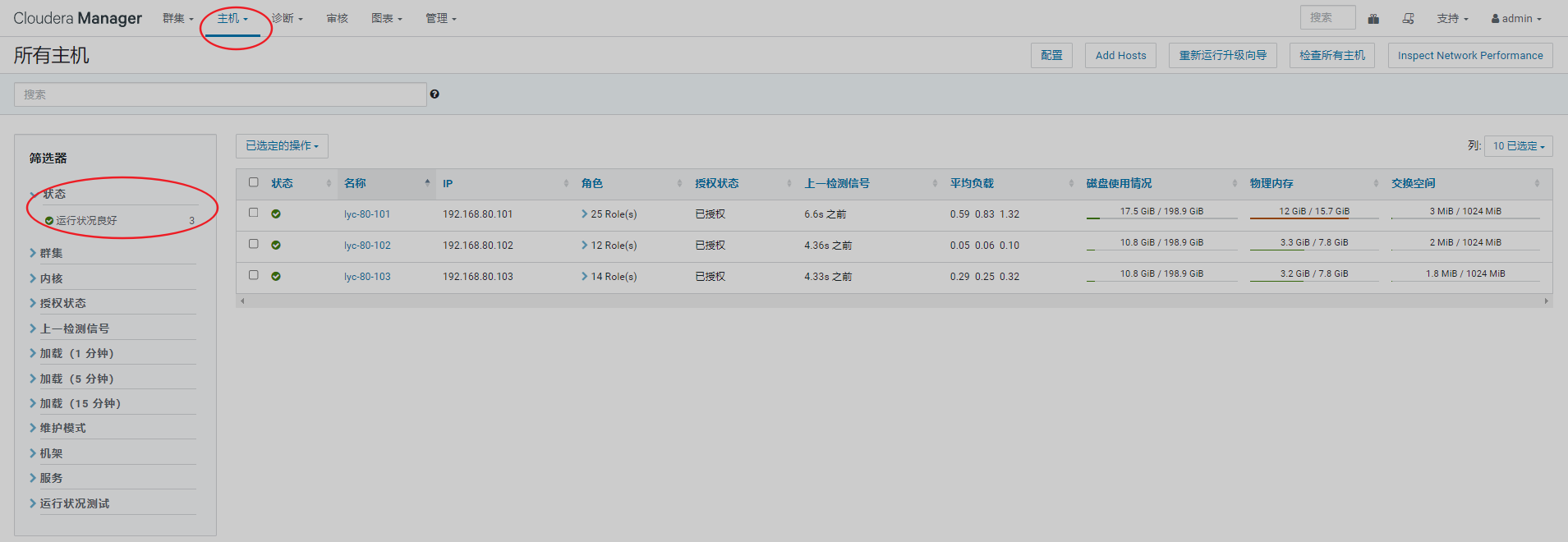
1、排查页面集群信息
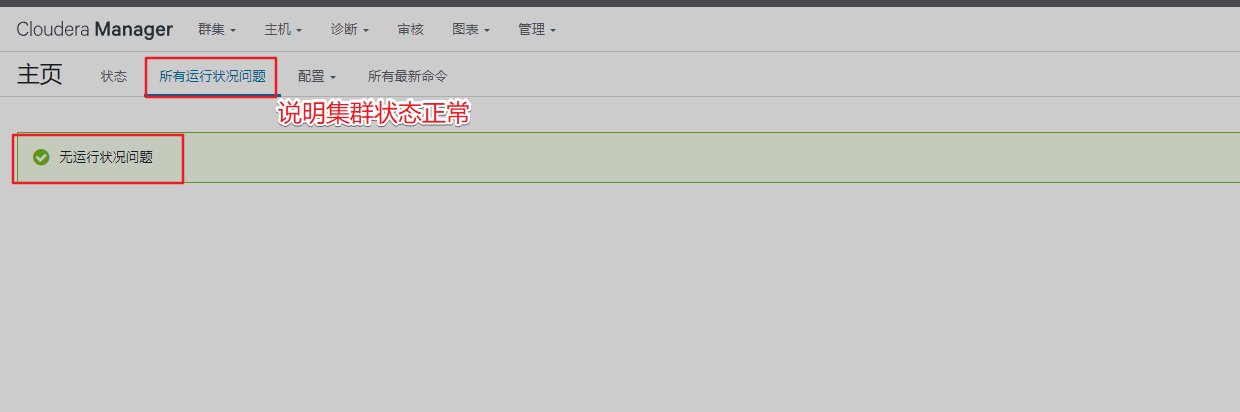
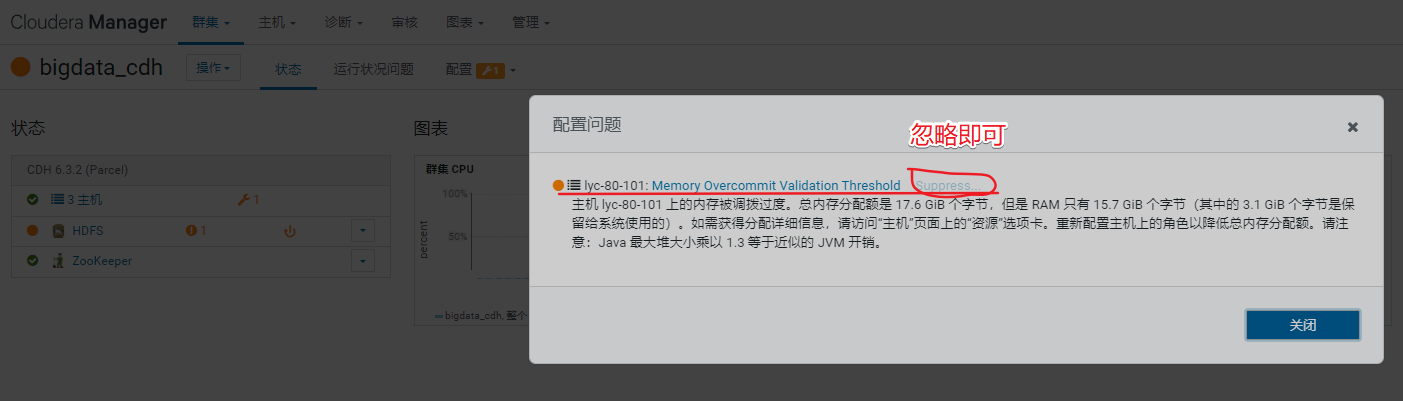
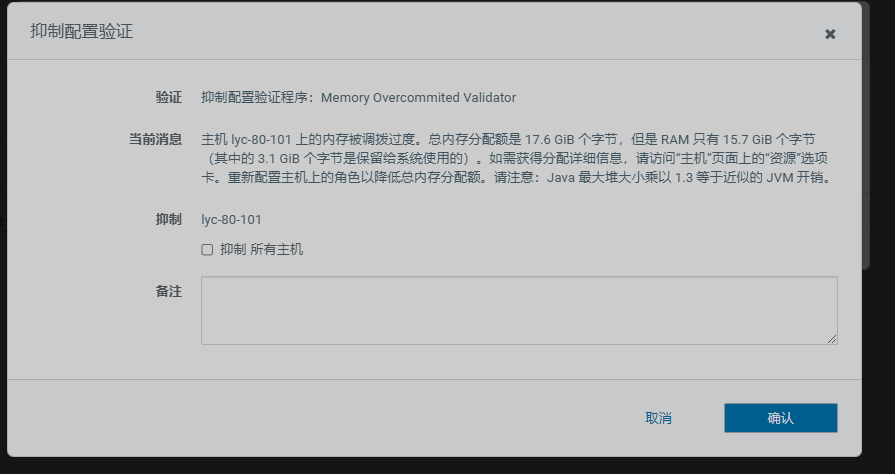
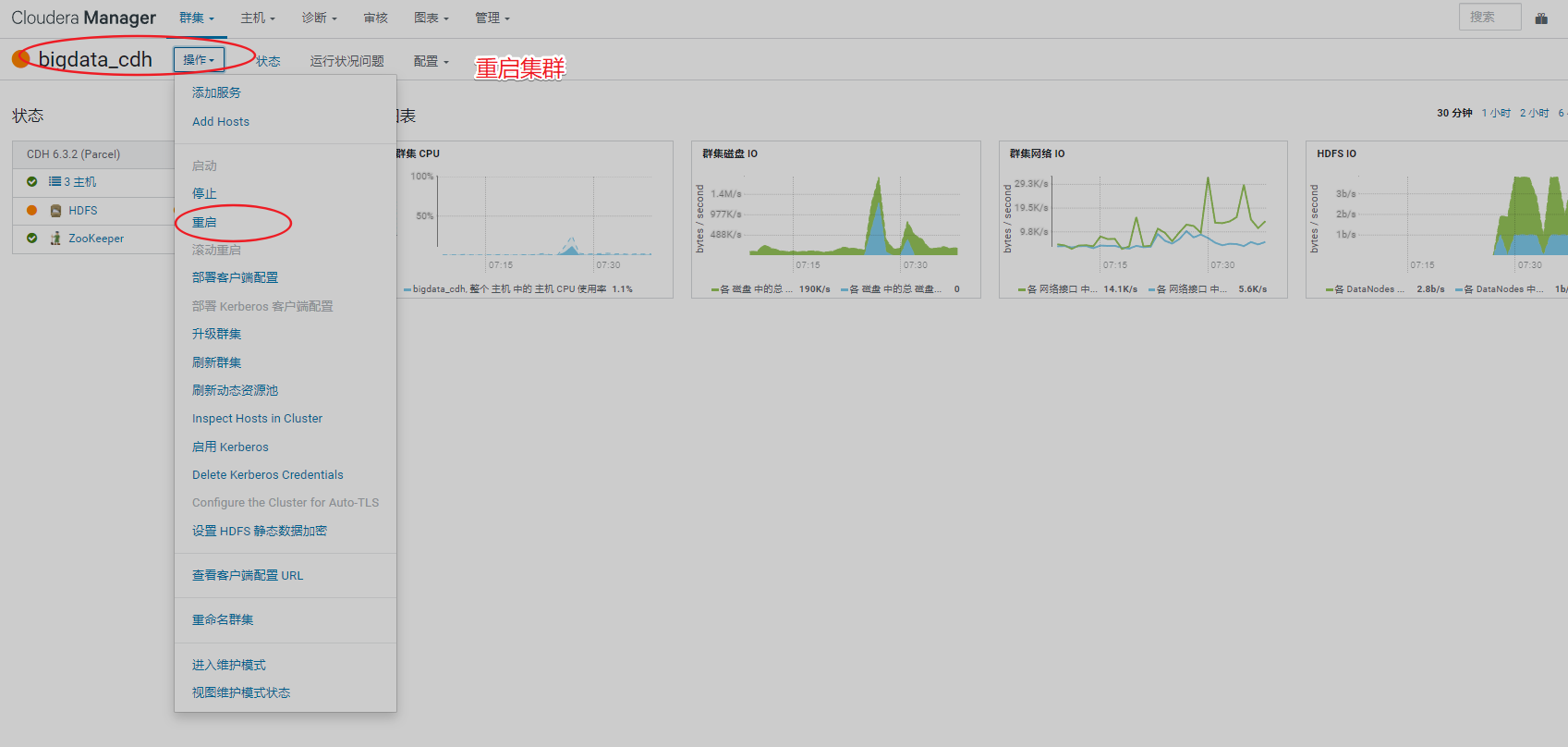
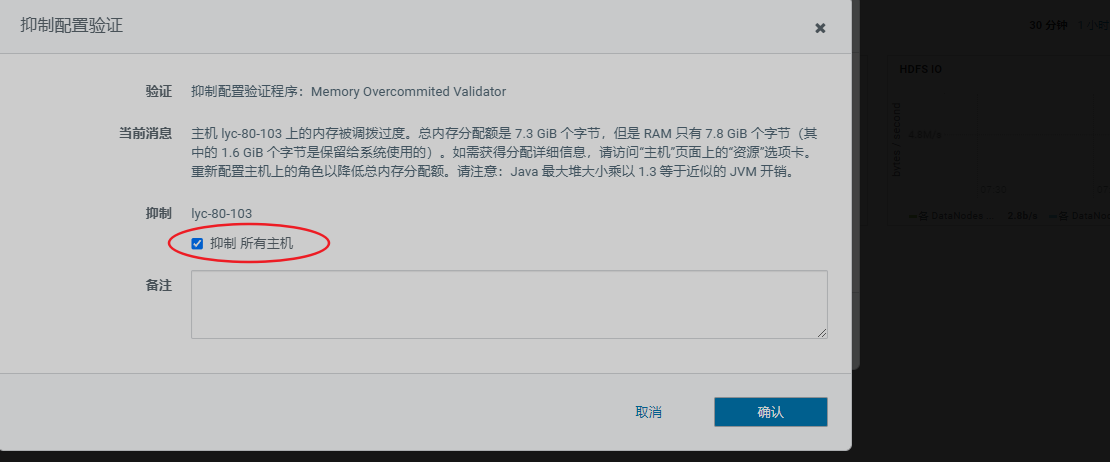
查看管理页面报错,需先处理掉报错信息
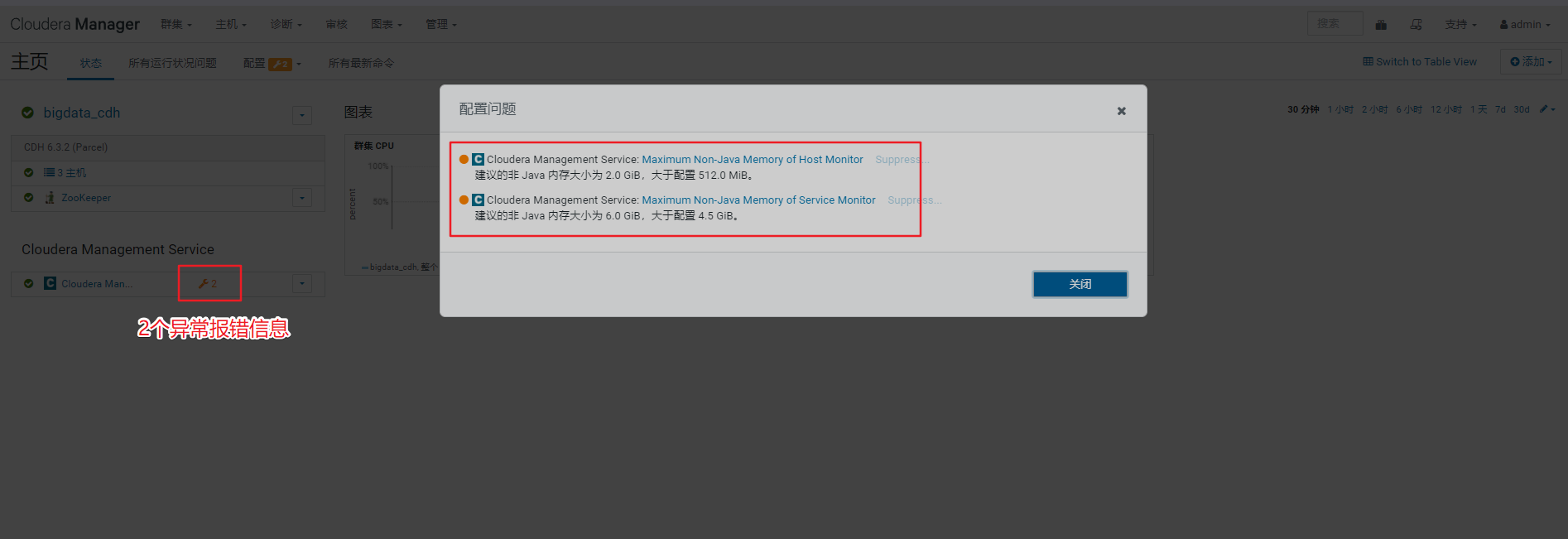
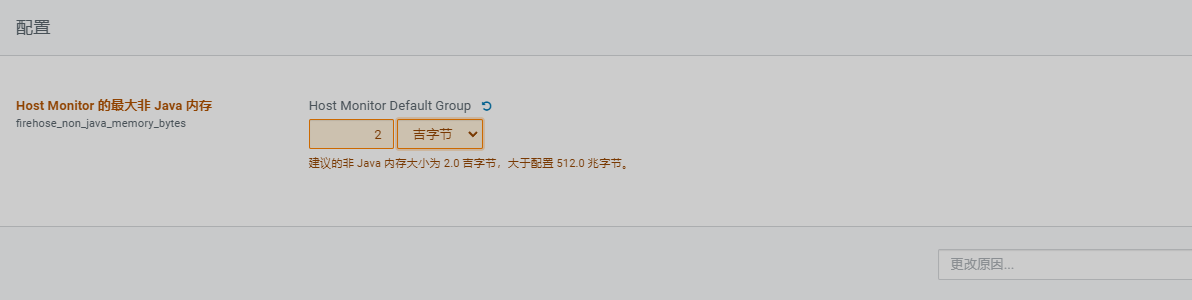

重启集群后再看管理页面已经没异常信息了

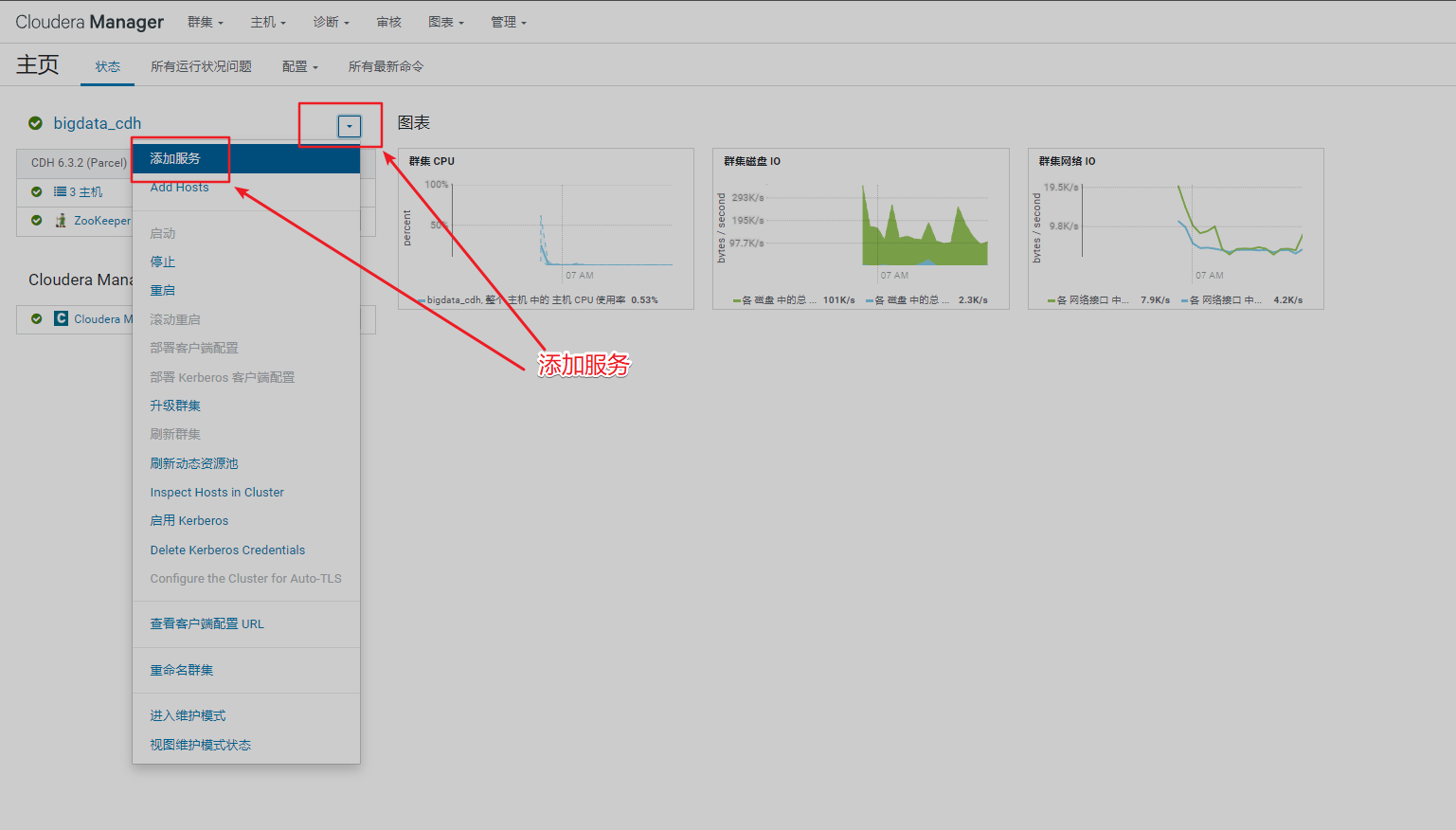
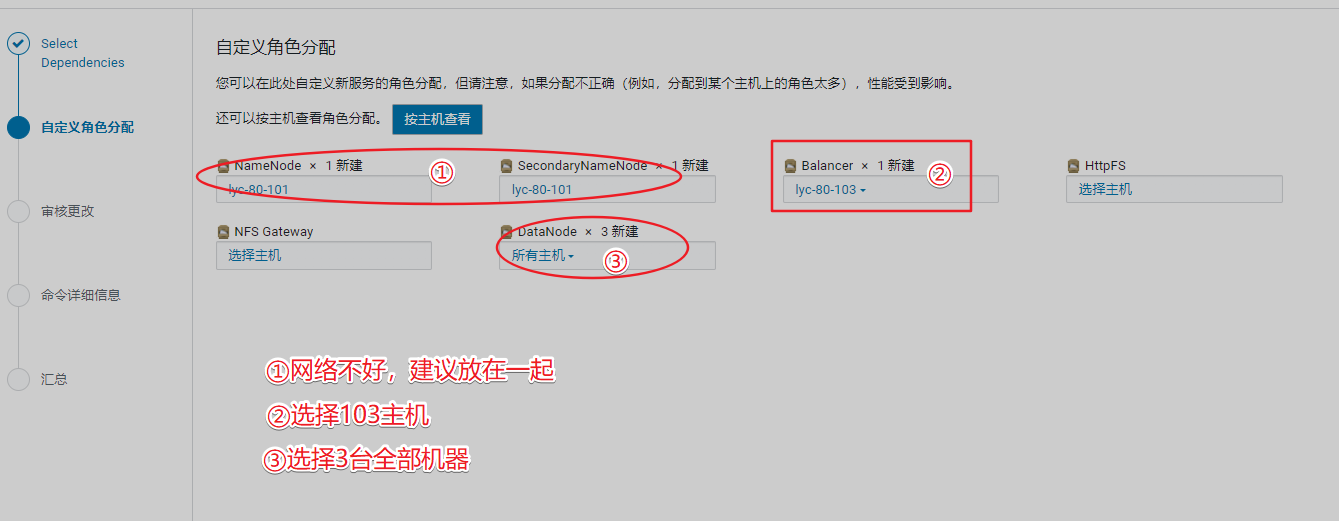
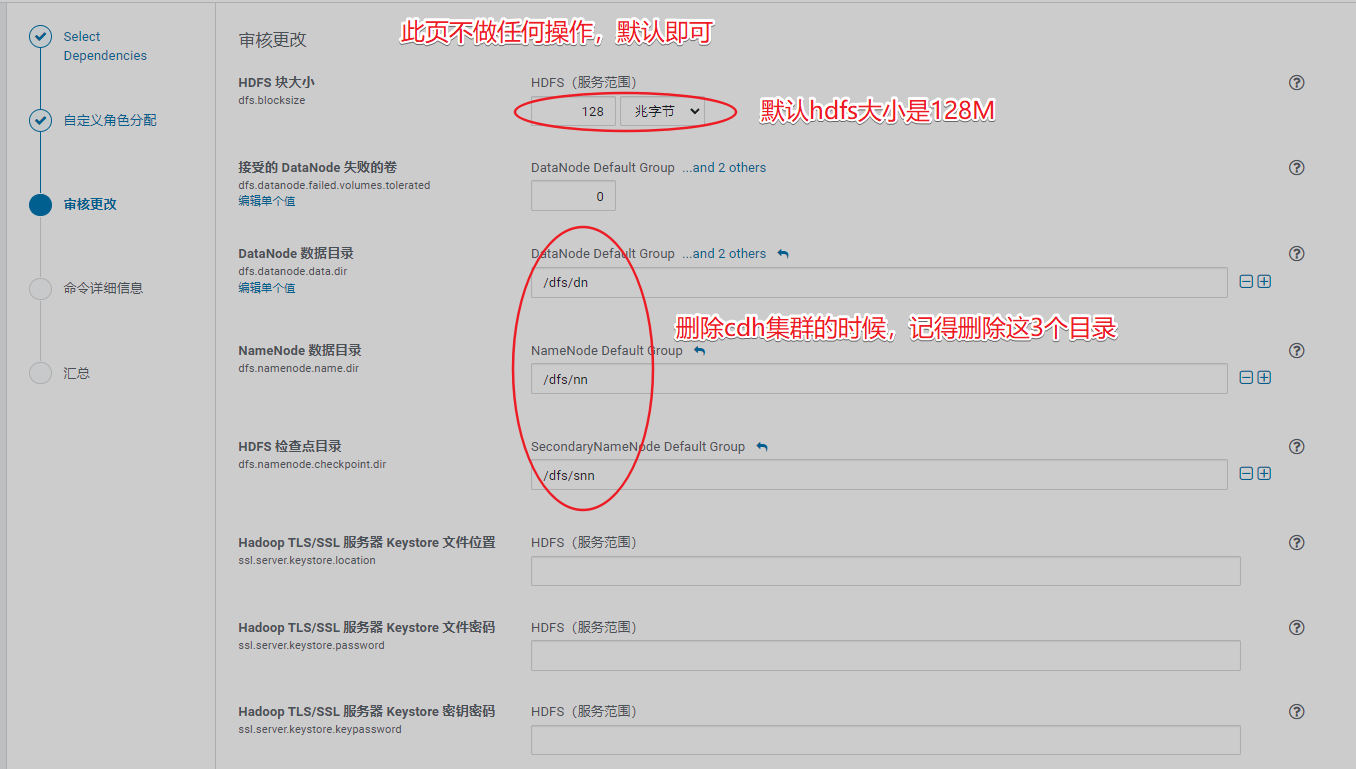
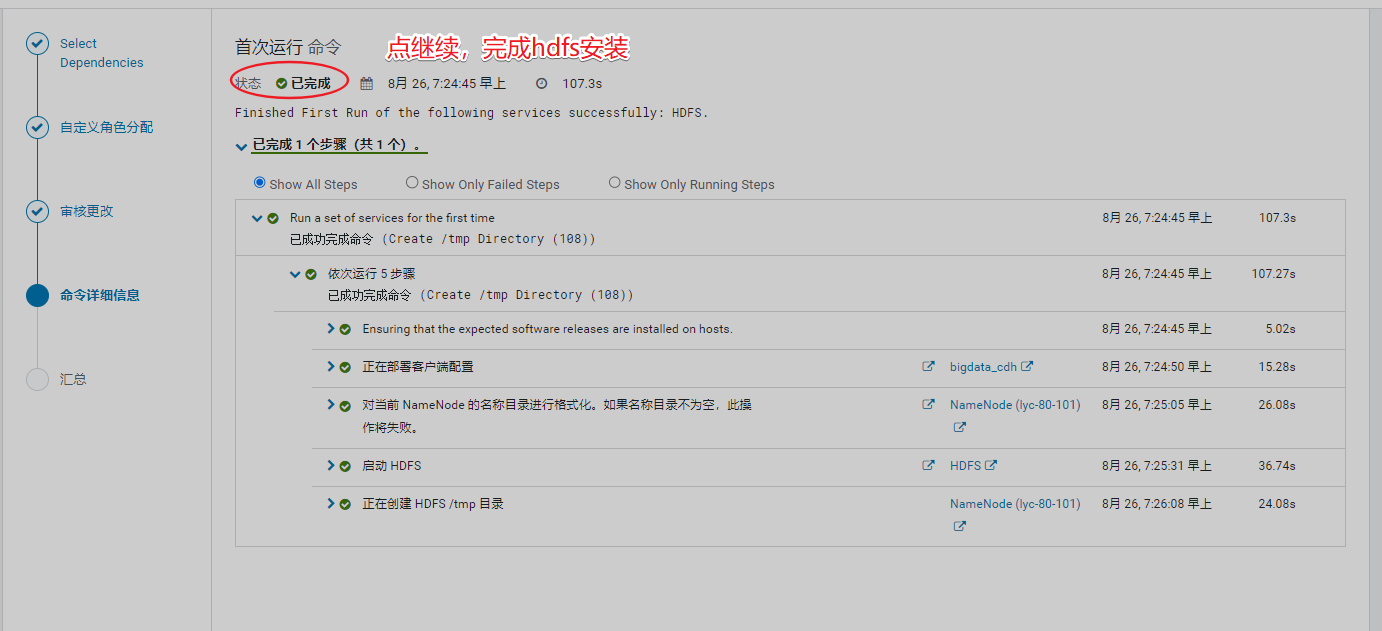
2、安装hdfs组件

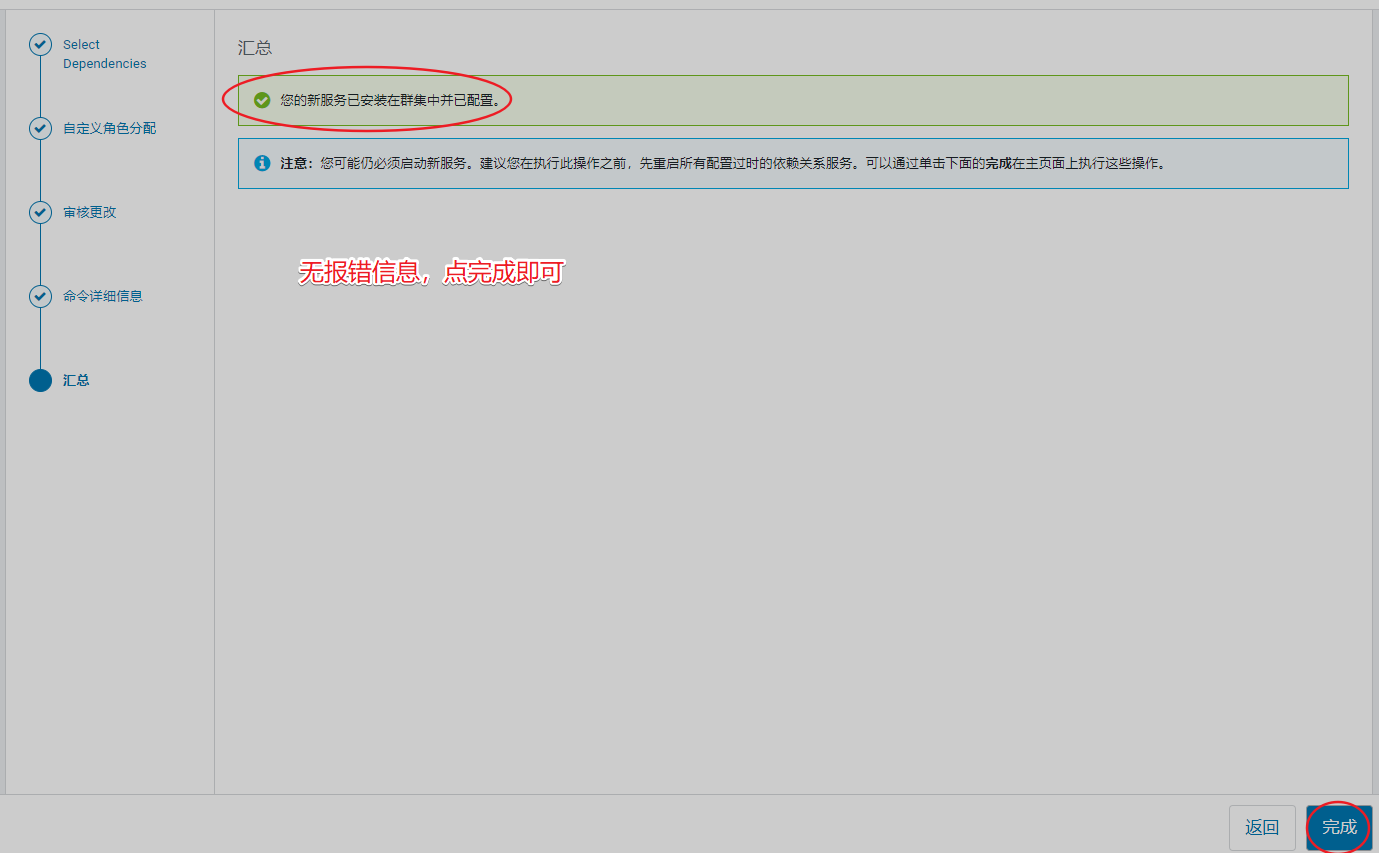
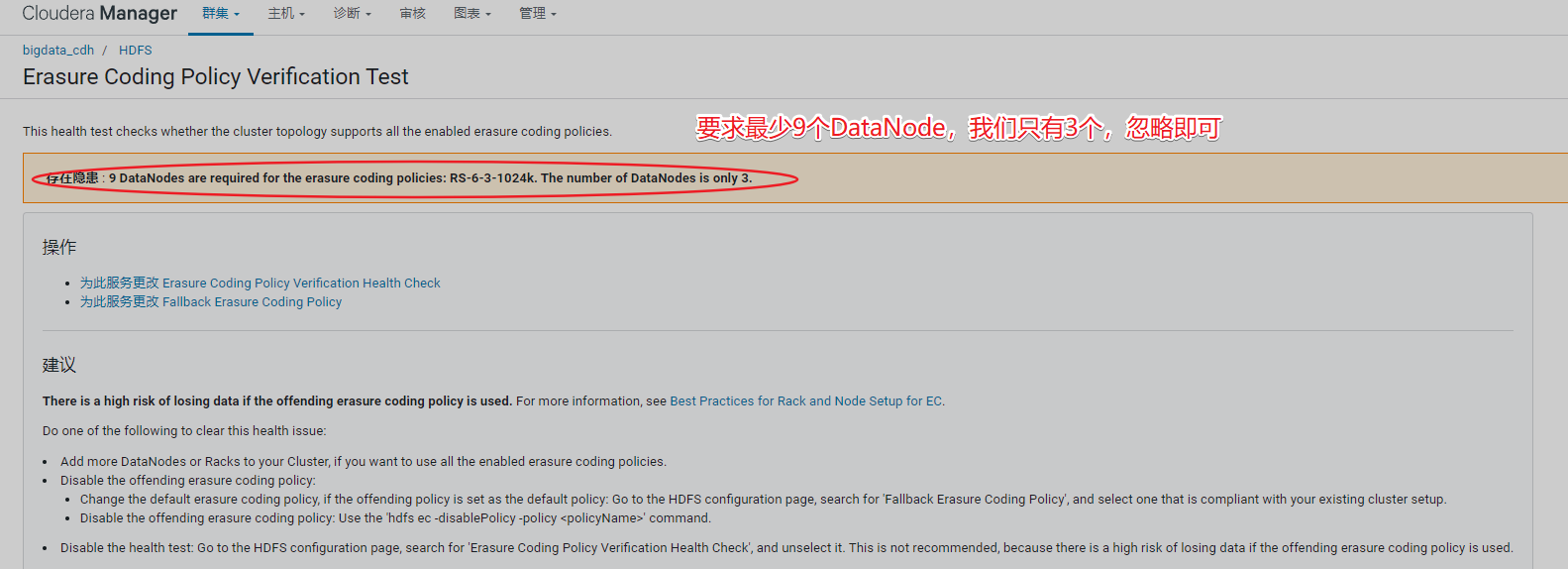
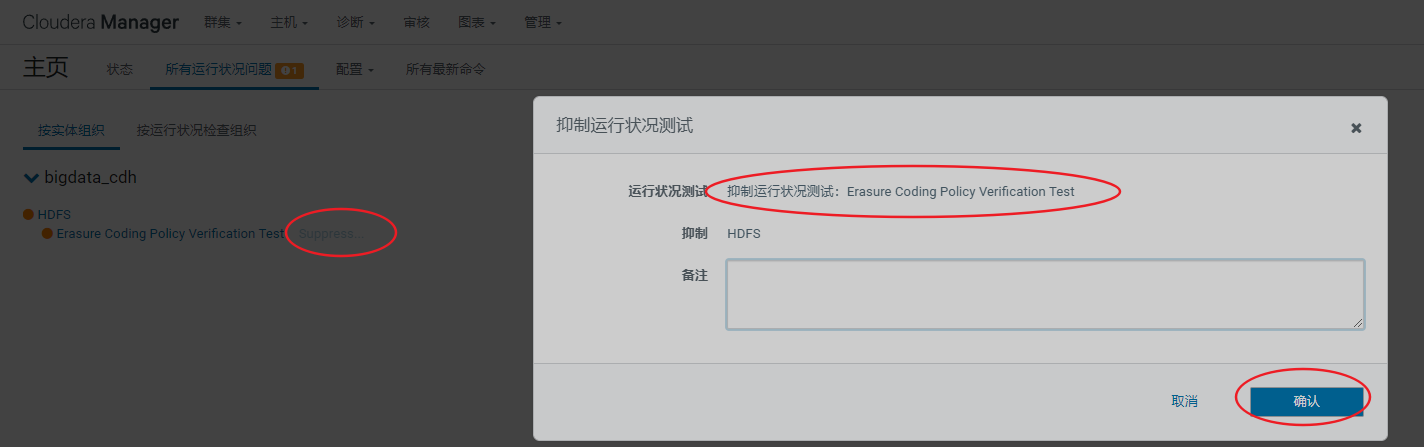
排除hdfs告警信息
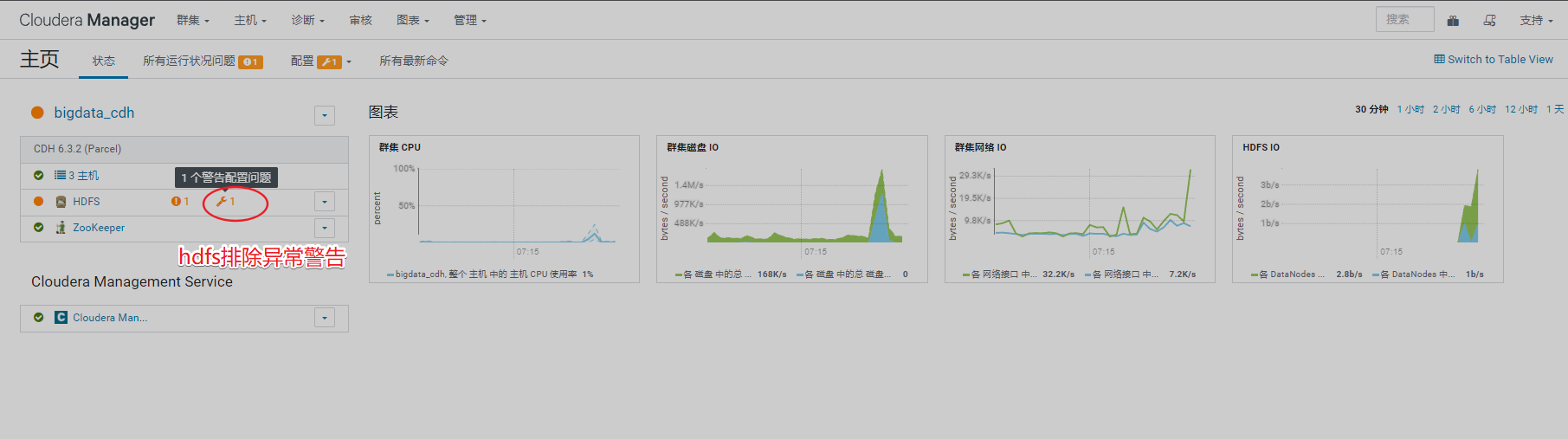
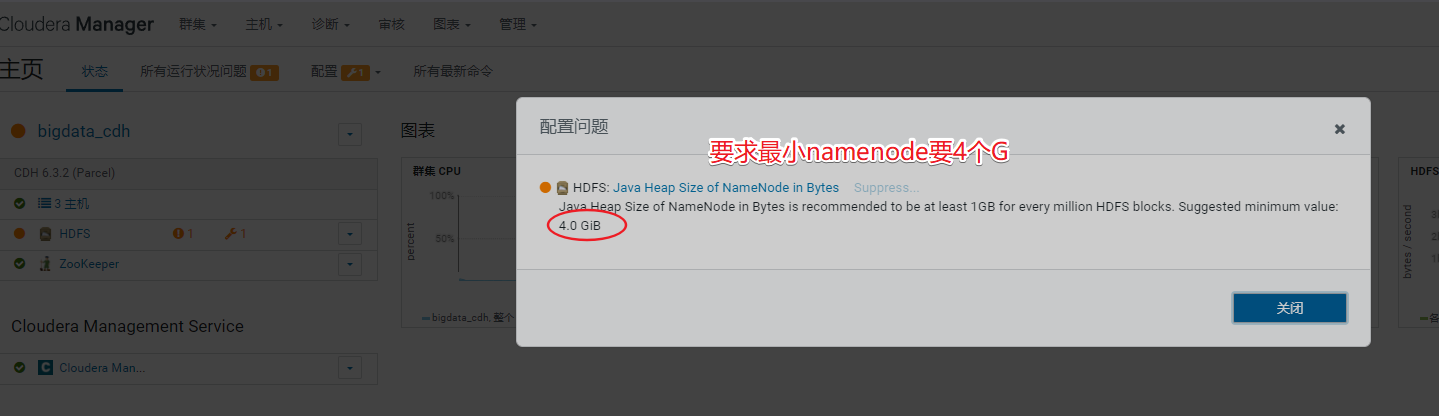
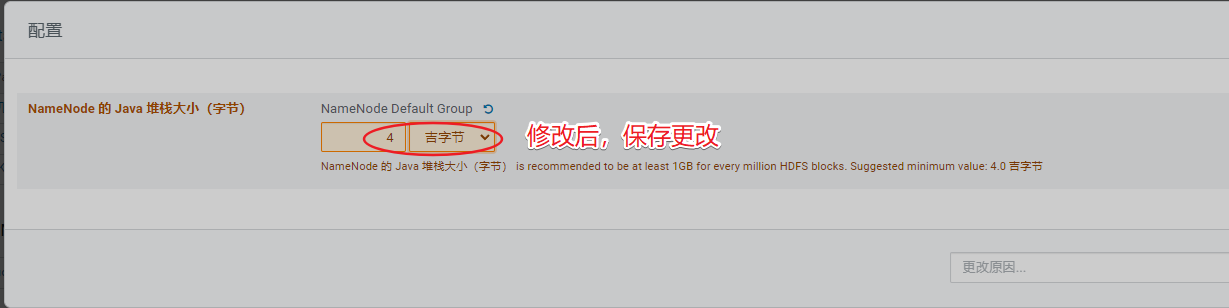
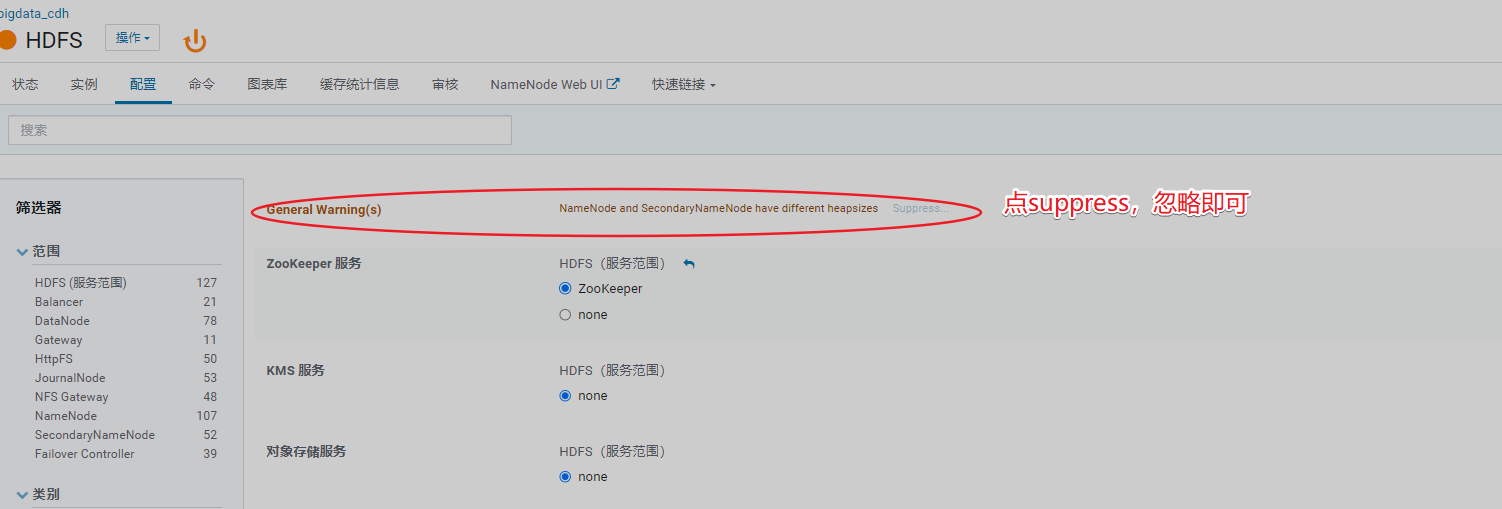
排除集群告警信息
排除DataNode节点告警
3、安装YARN
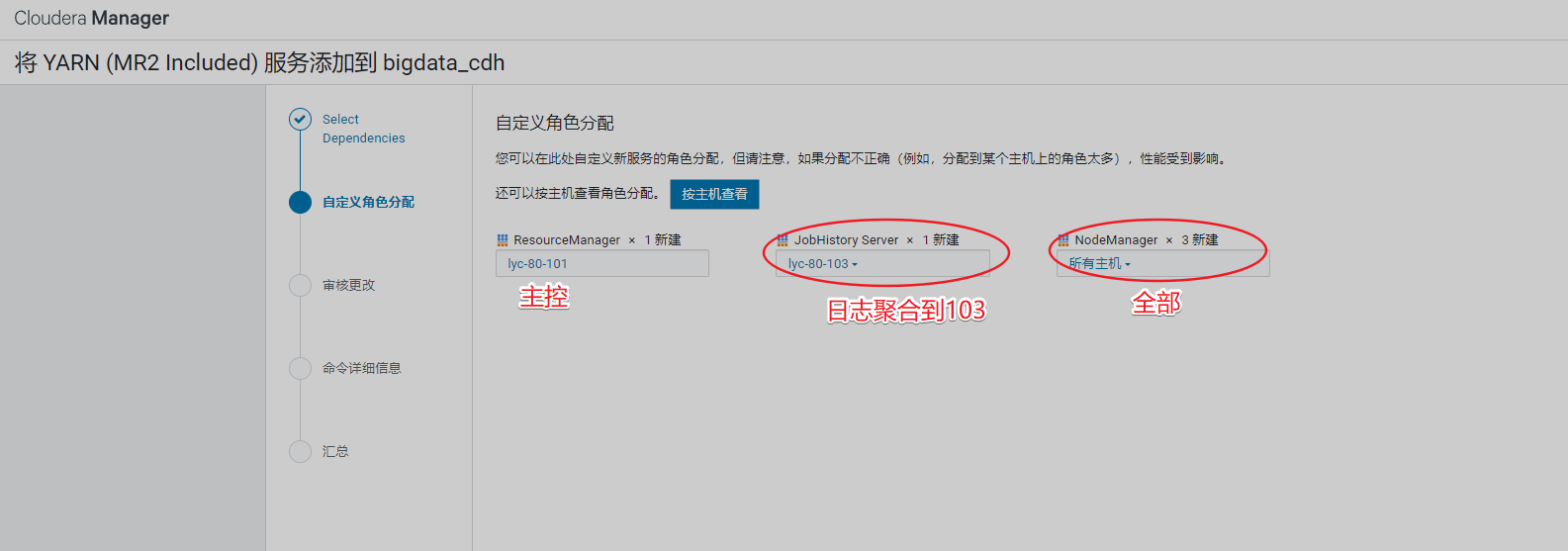
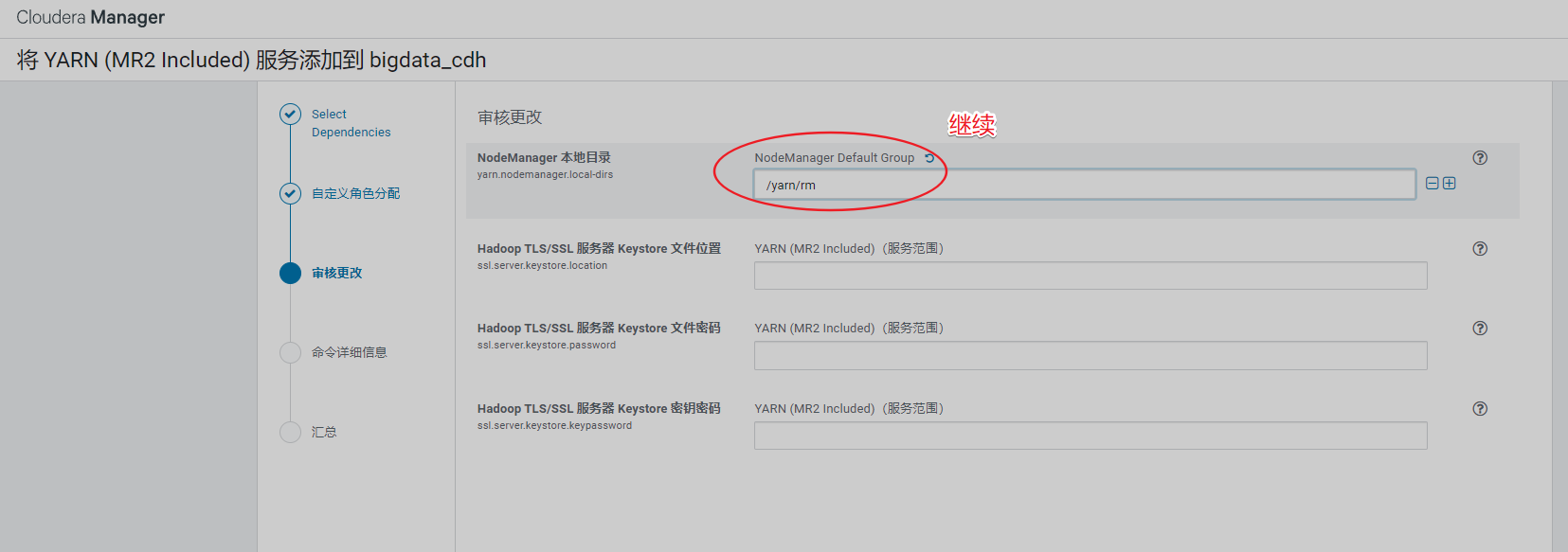
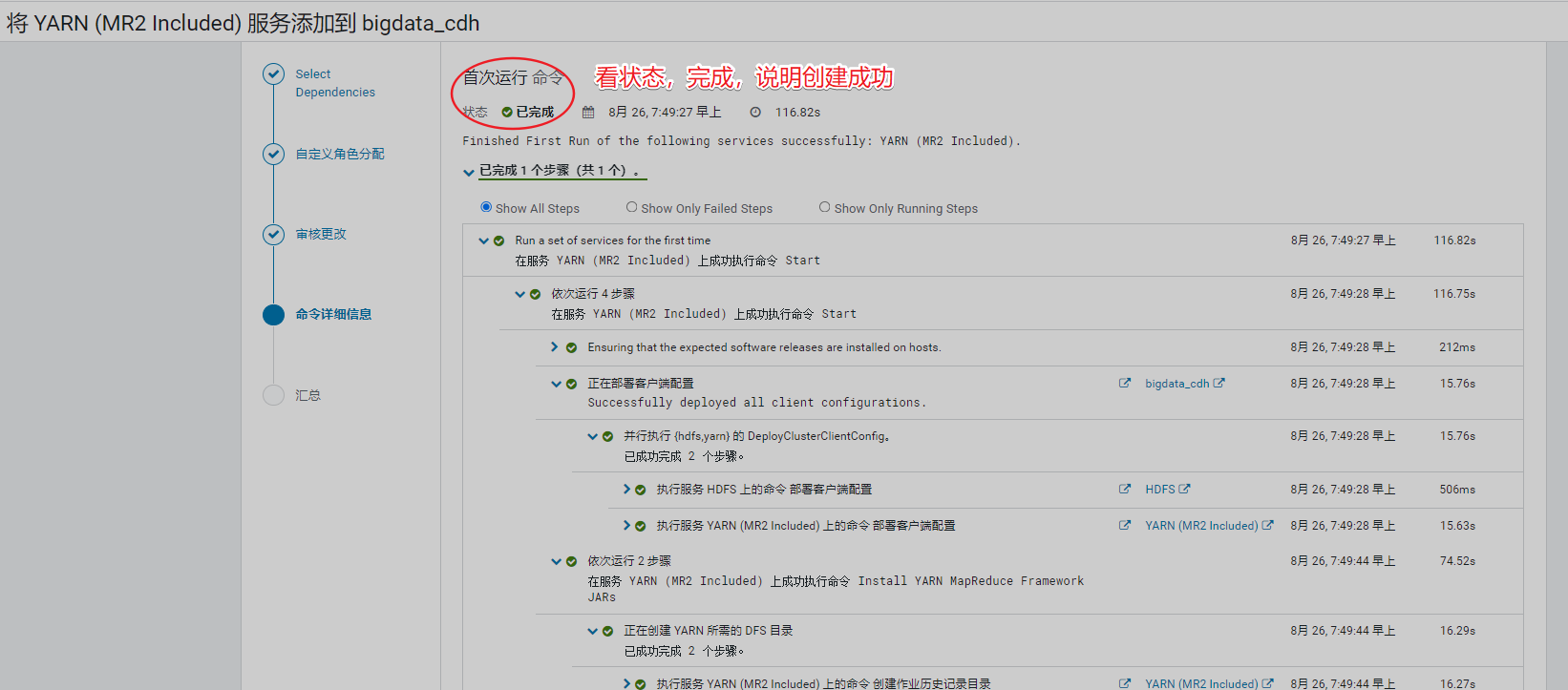
安装过程如下
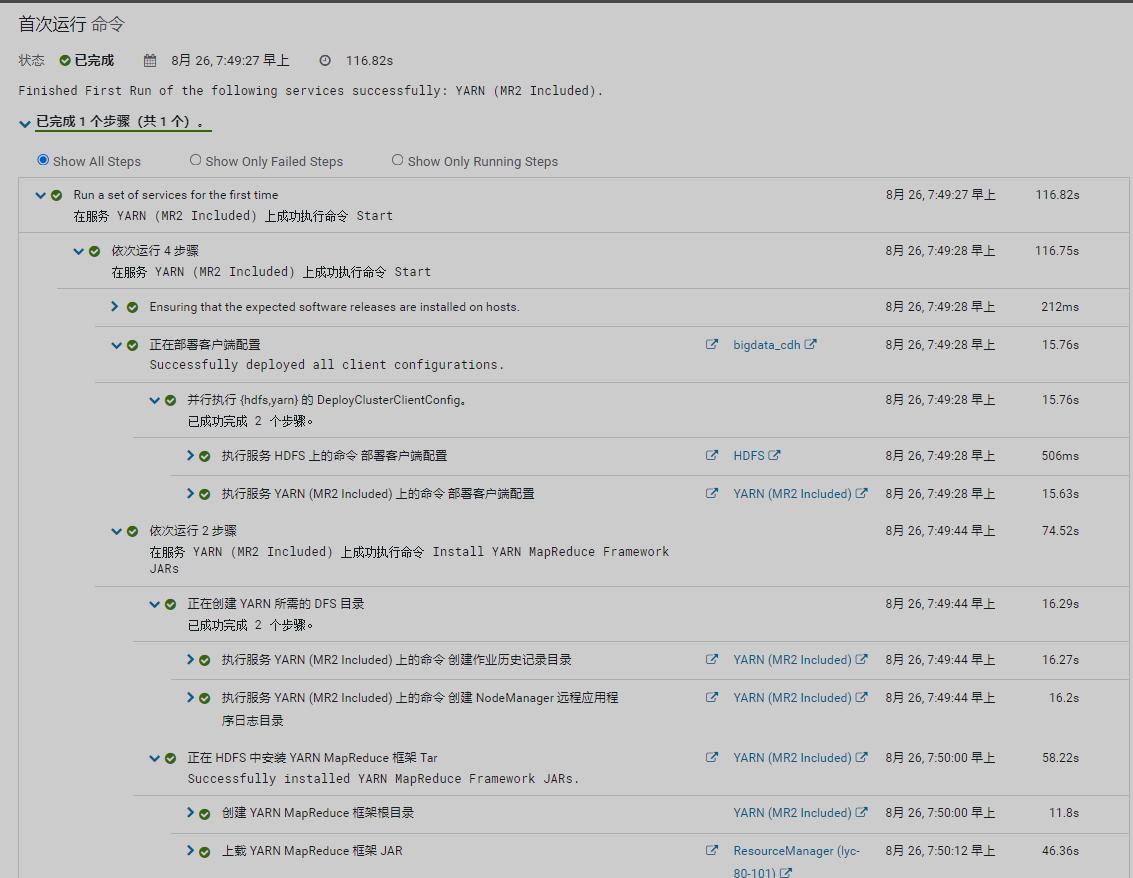
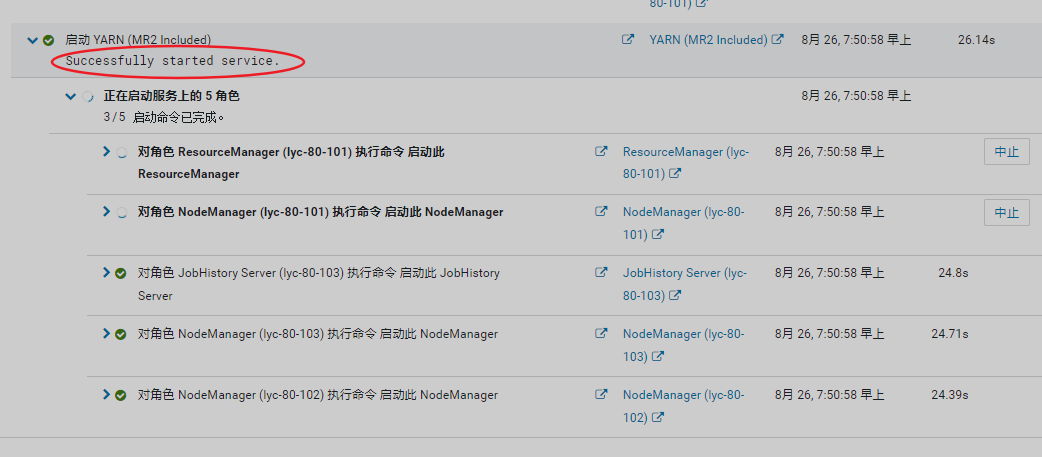
查看告警信息
告警已消除

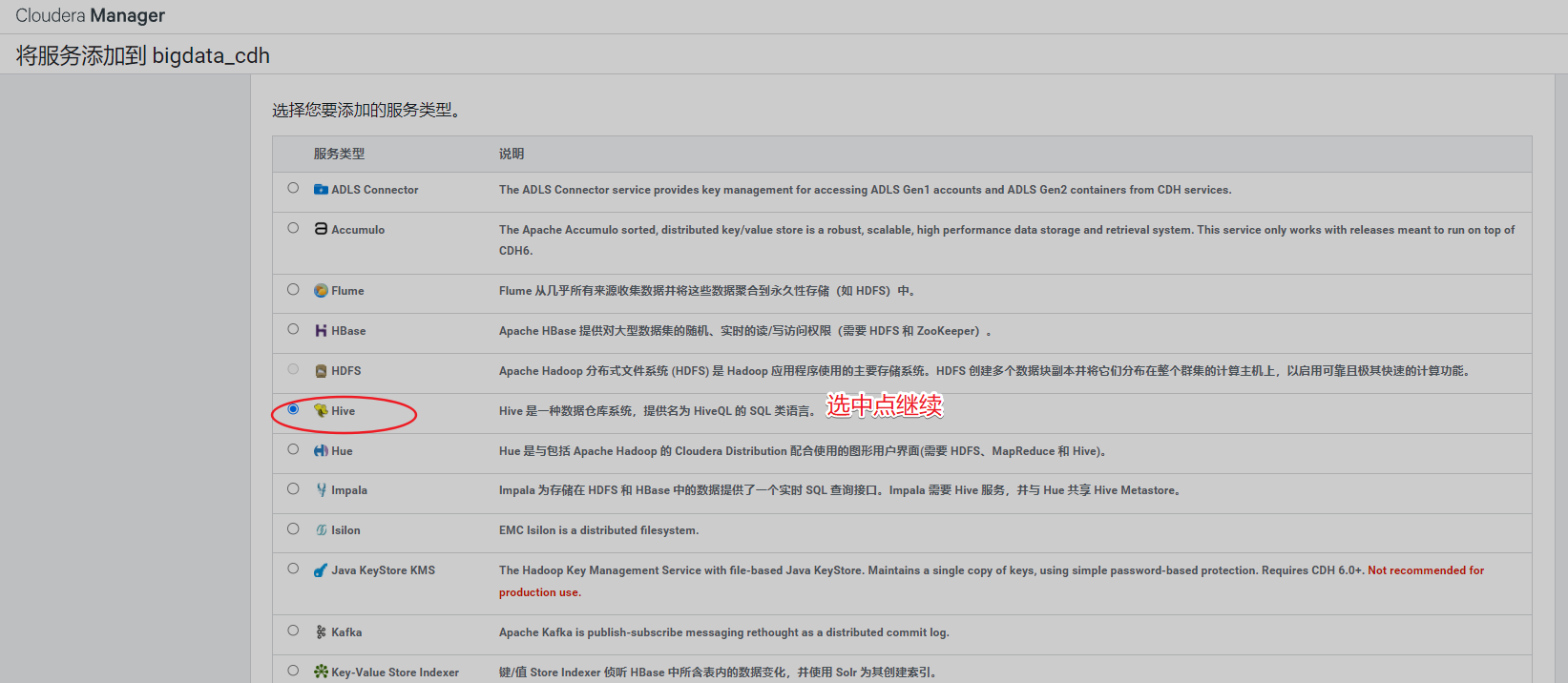
4、安装hive
安装hive之前,先创建数据库

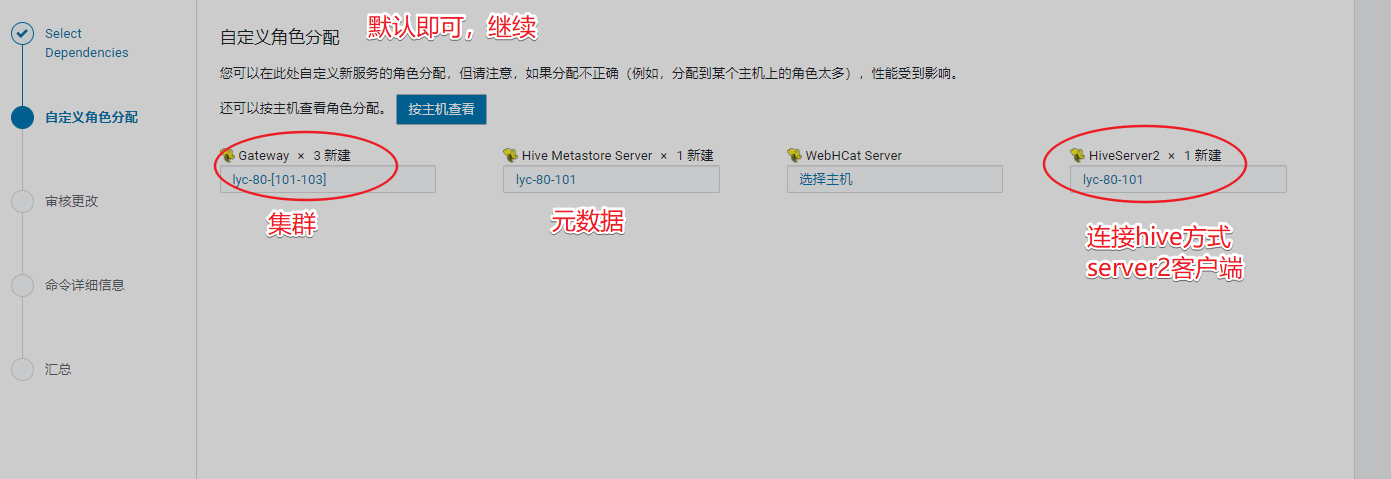
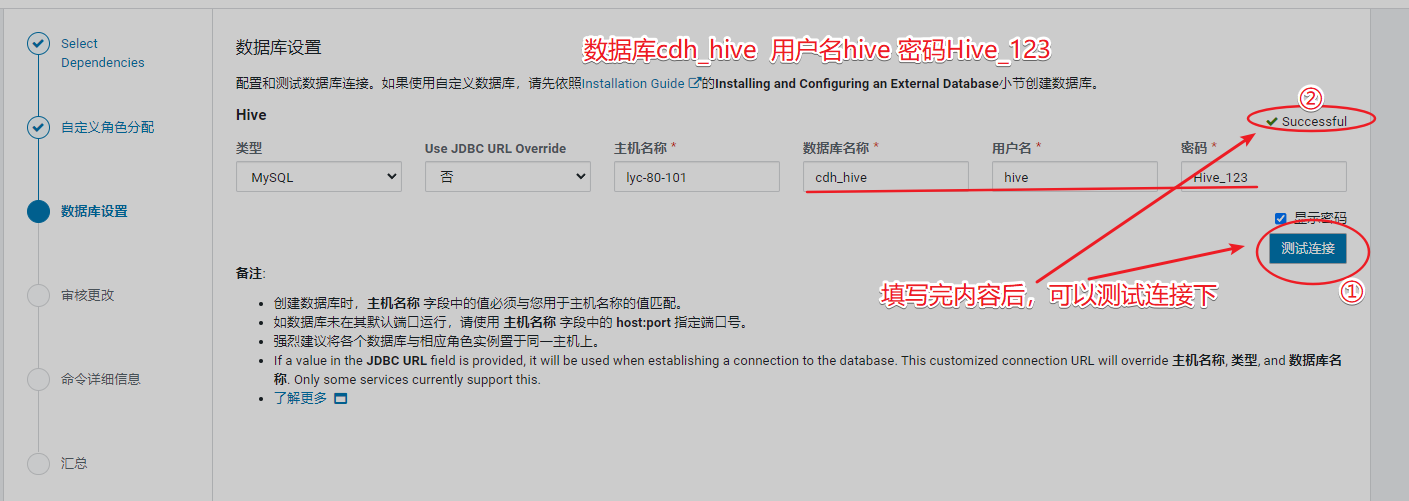
记住端口号
Hive Metastore 服务器端口 9083
Hive Server2 服务器端口 10000
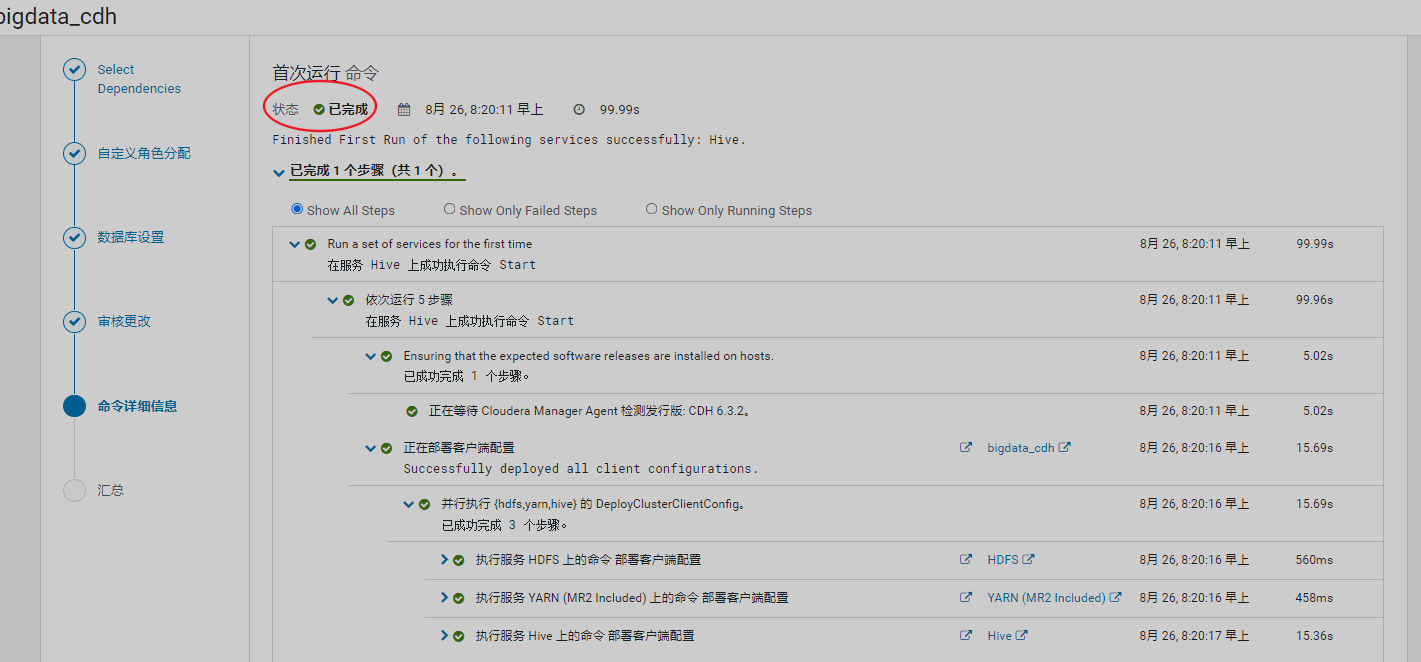
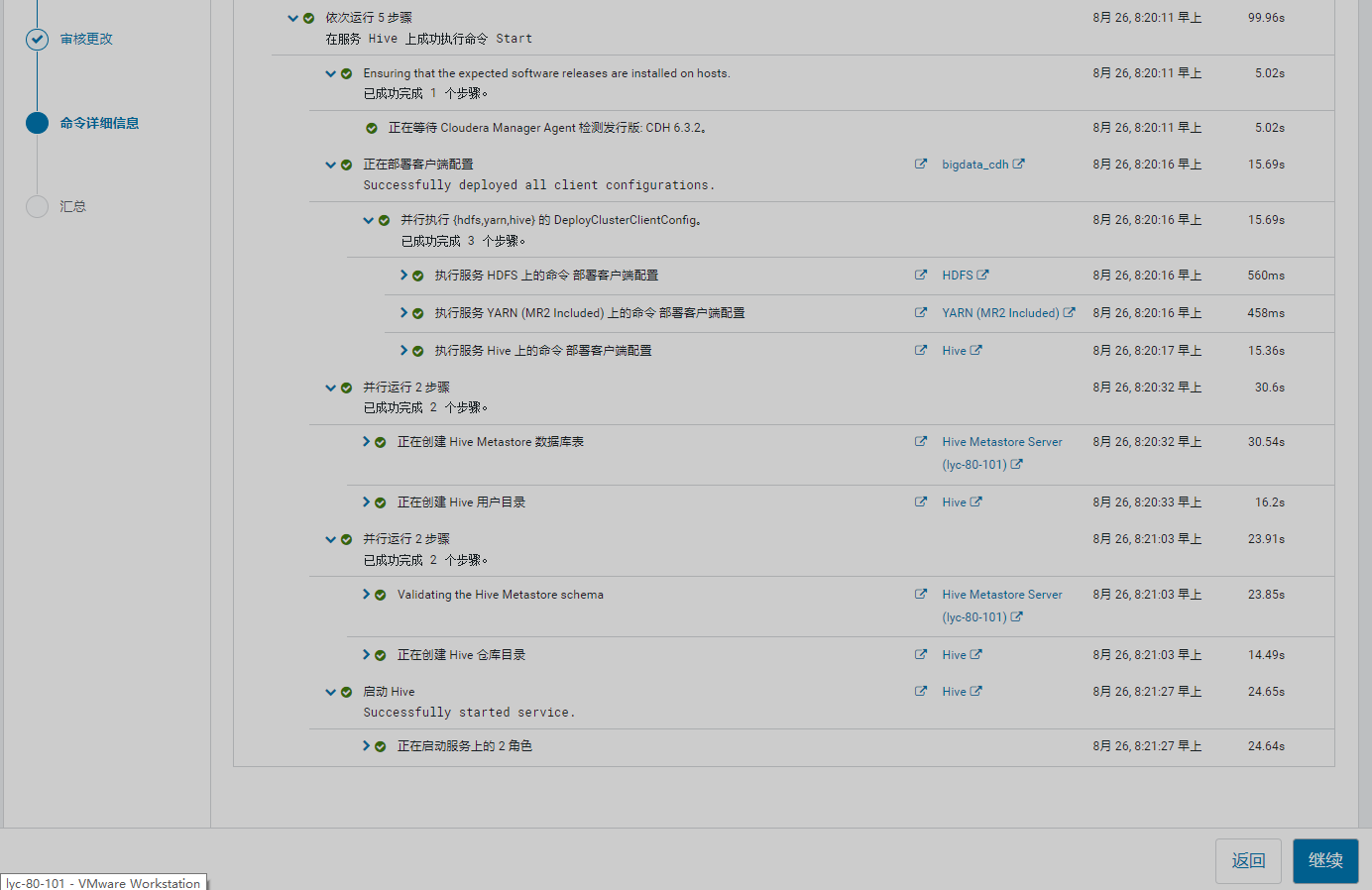
5、安装Impala
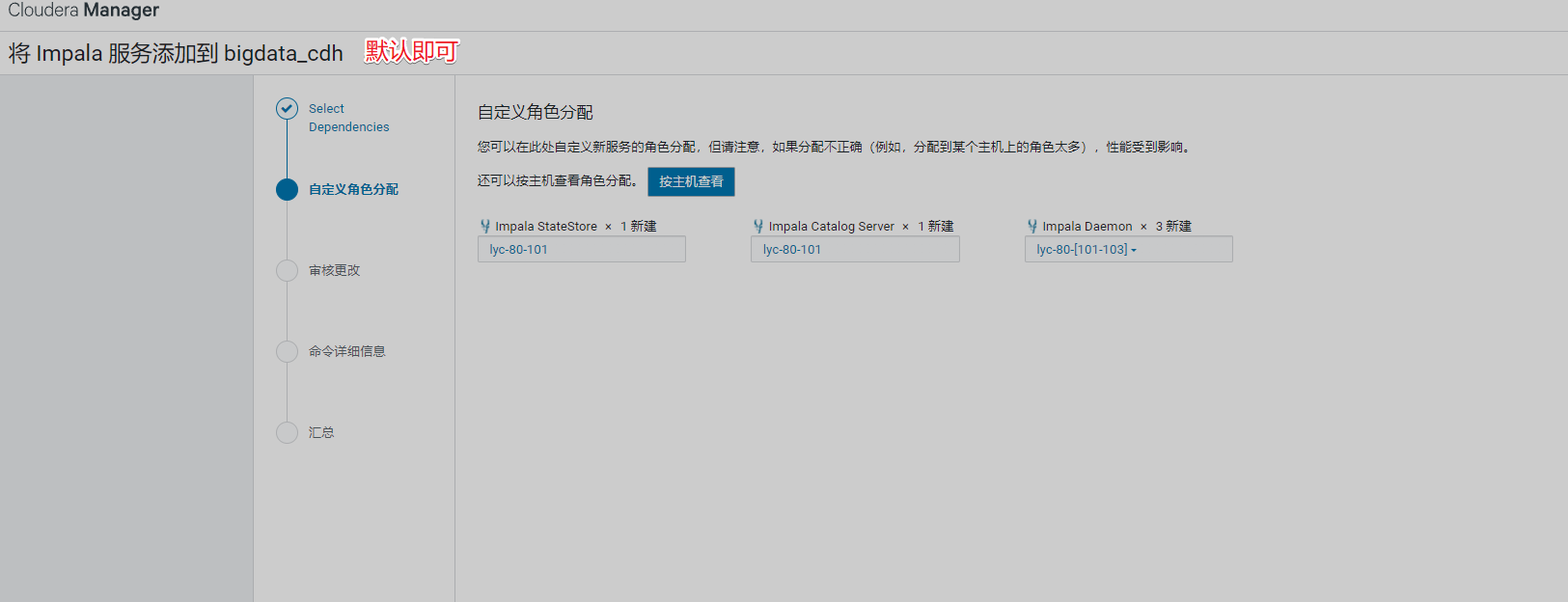

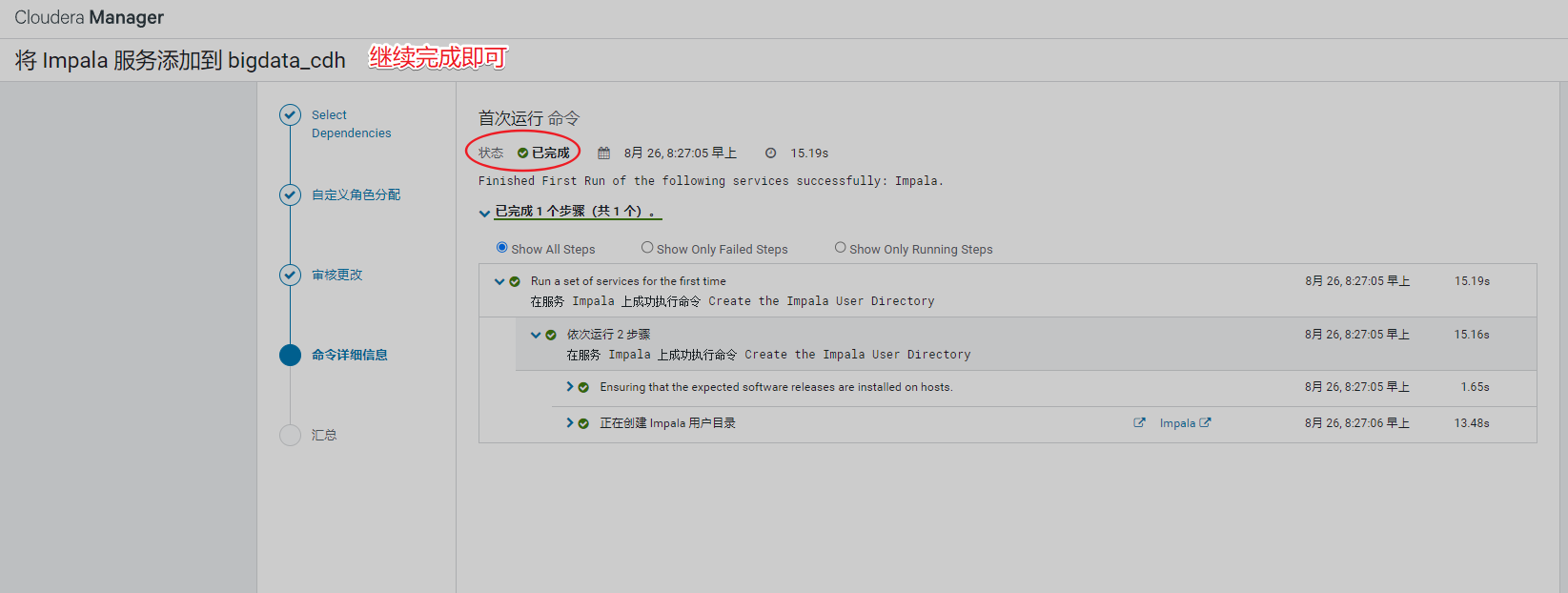
警告提醒,要求重启hdfs,重启即可
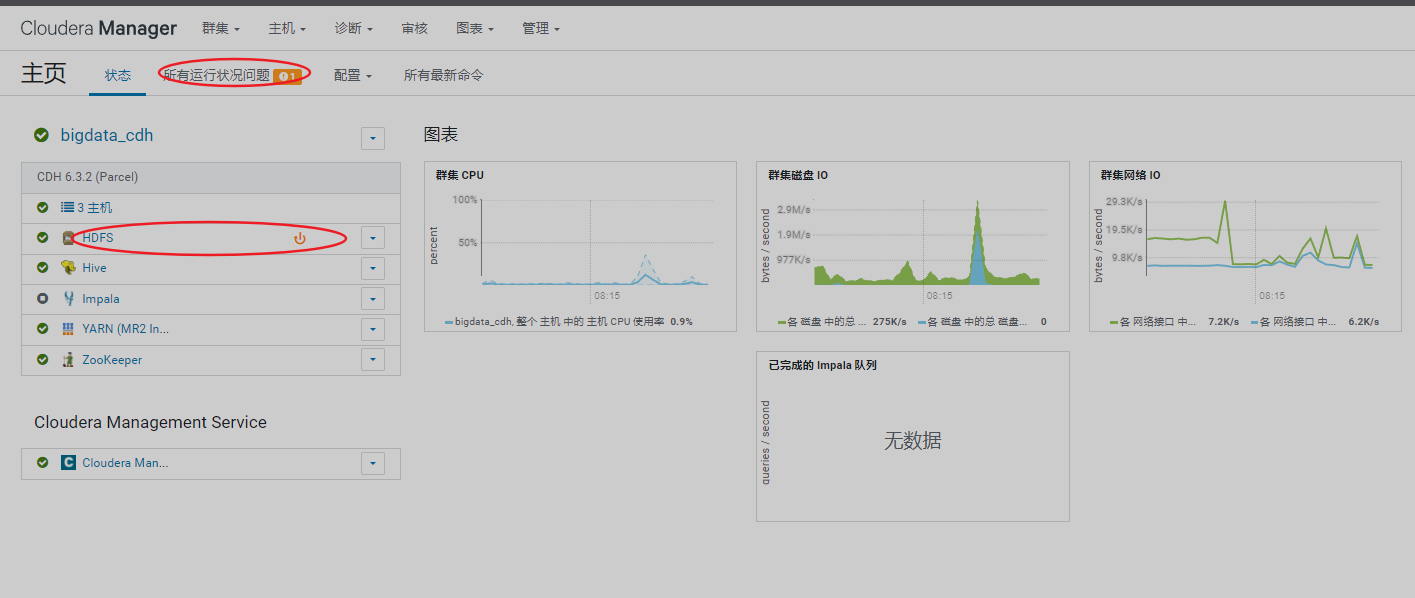
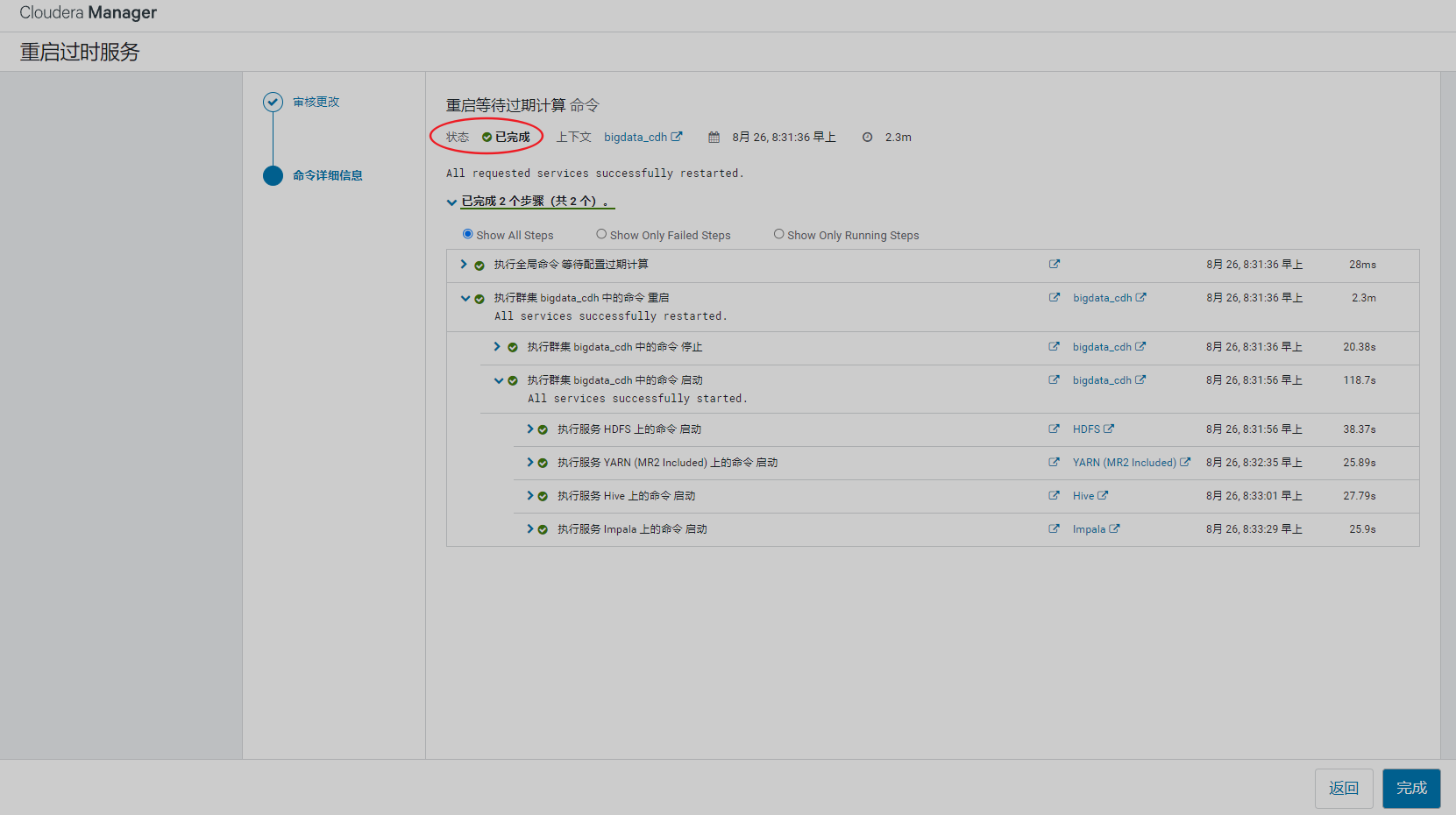
6、安装spark
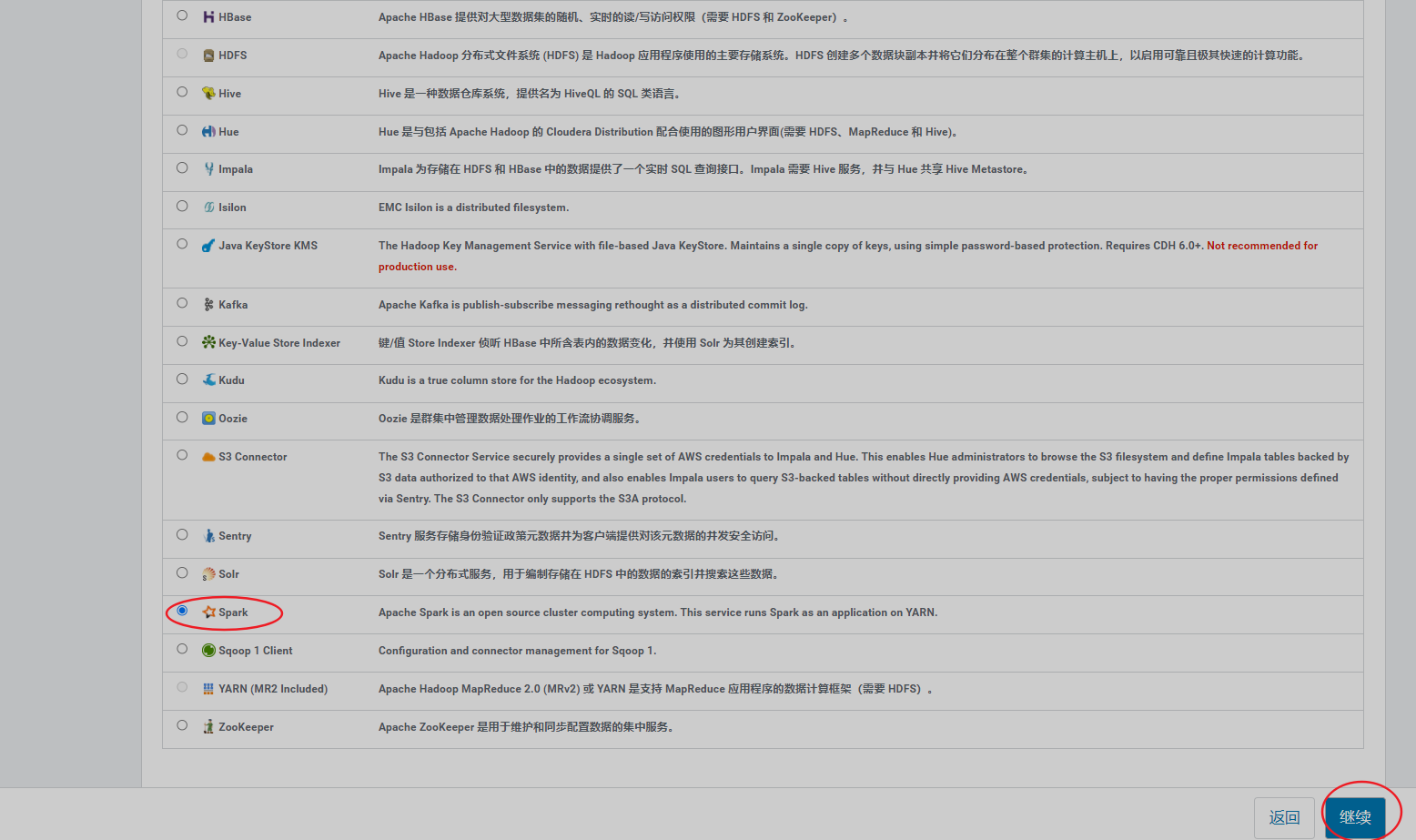
告警提示,需要重启Yarn
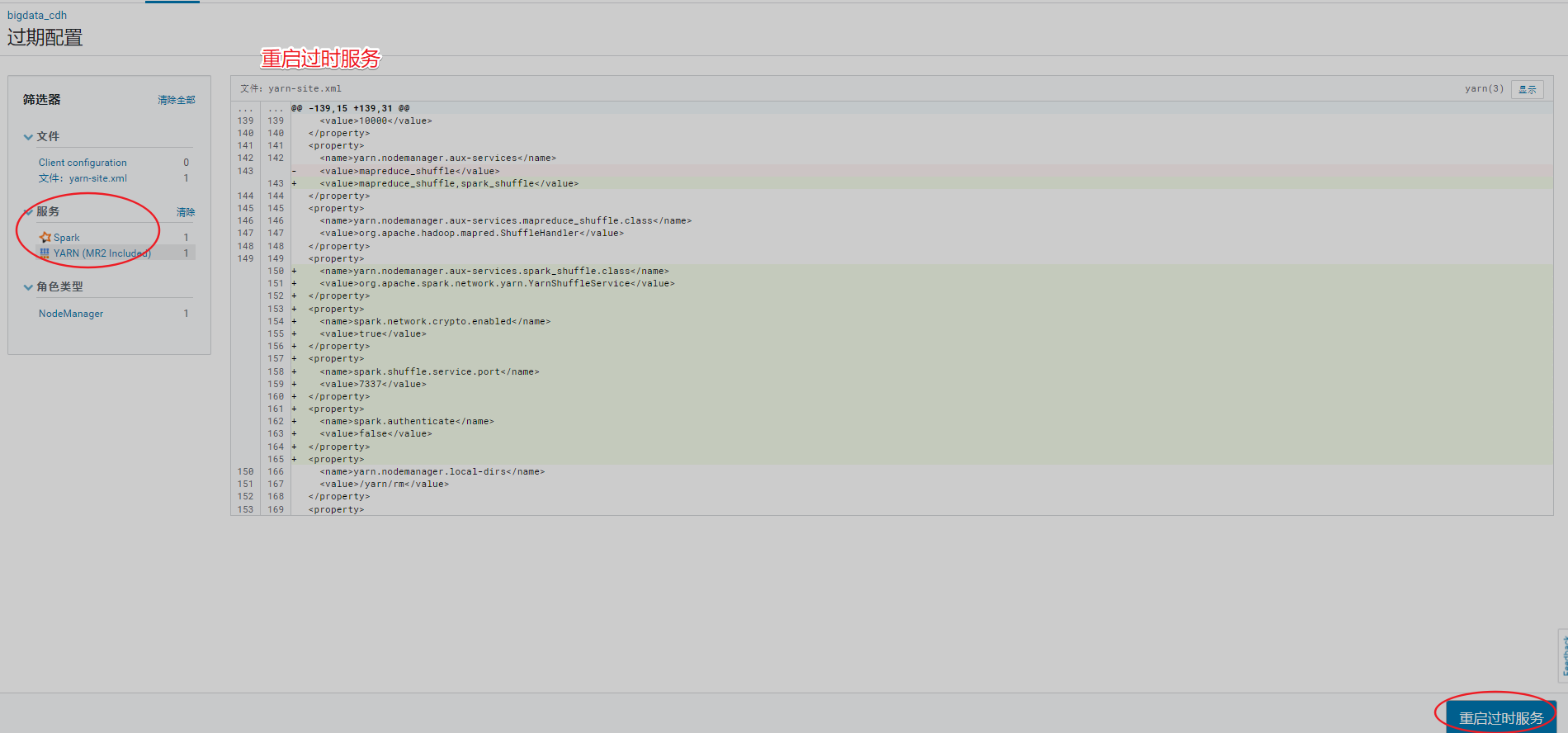
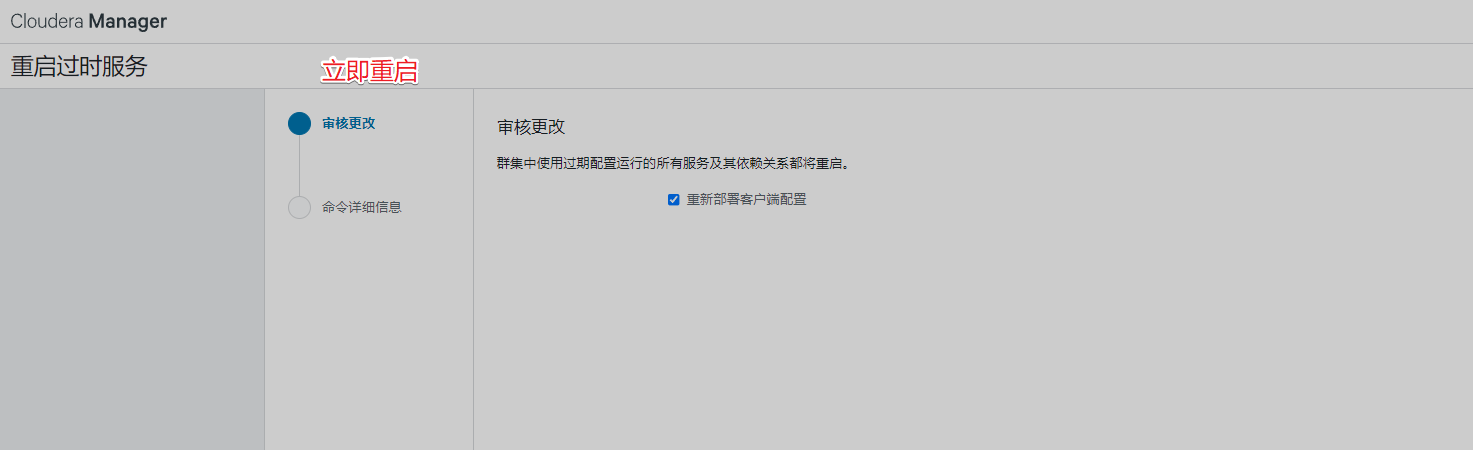
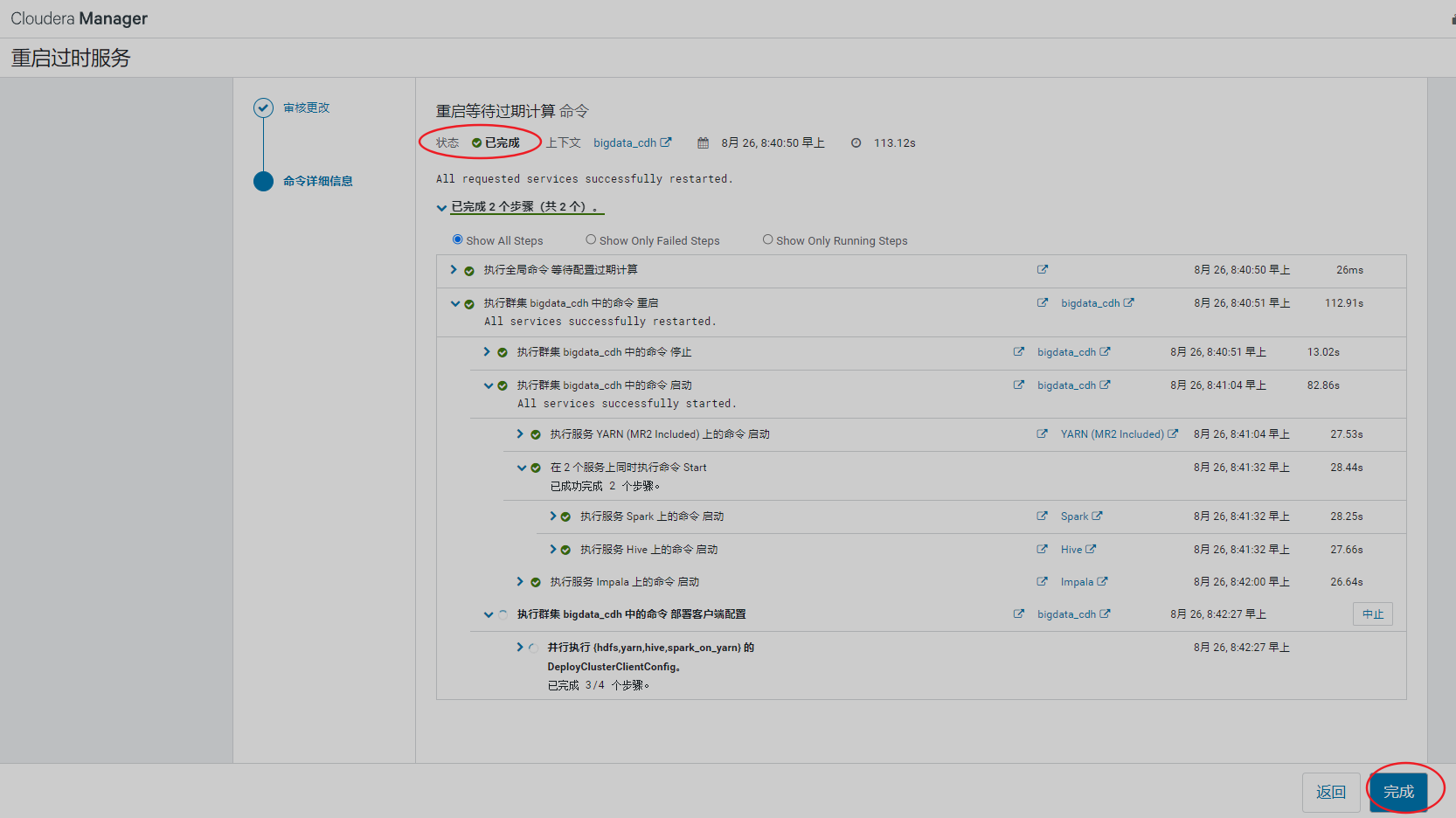
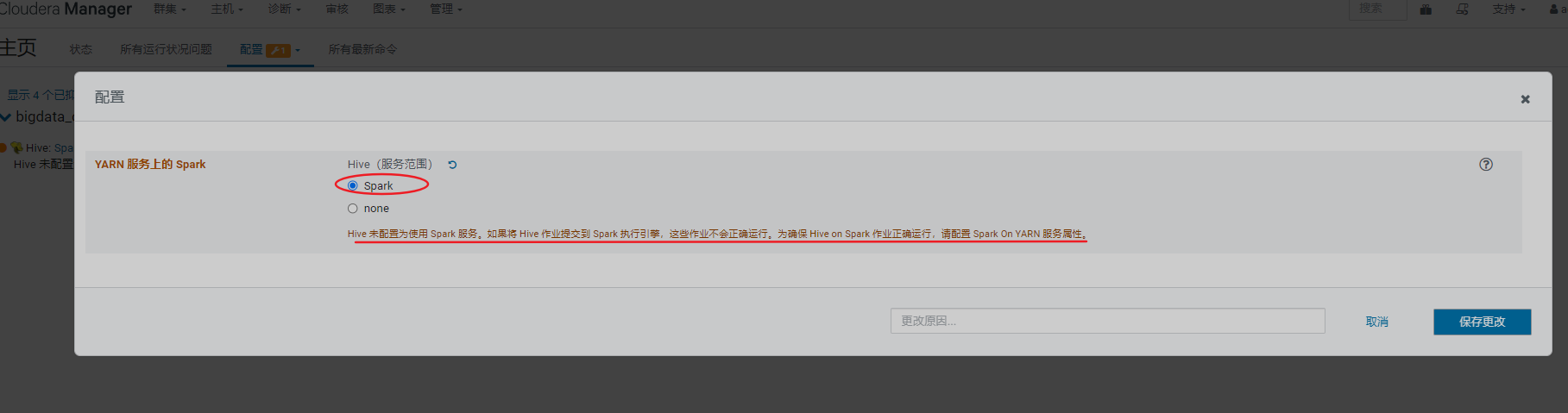
配置hive计算引擎,由MapReduce变为spark
7、安装Hbase
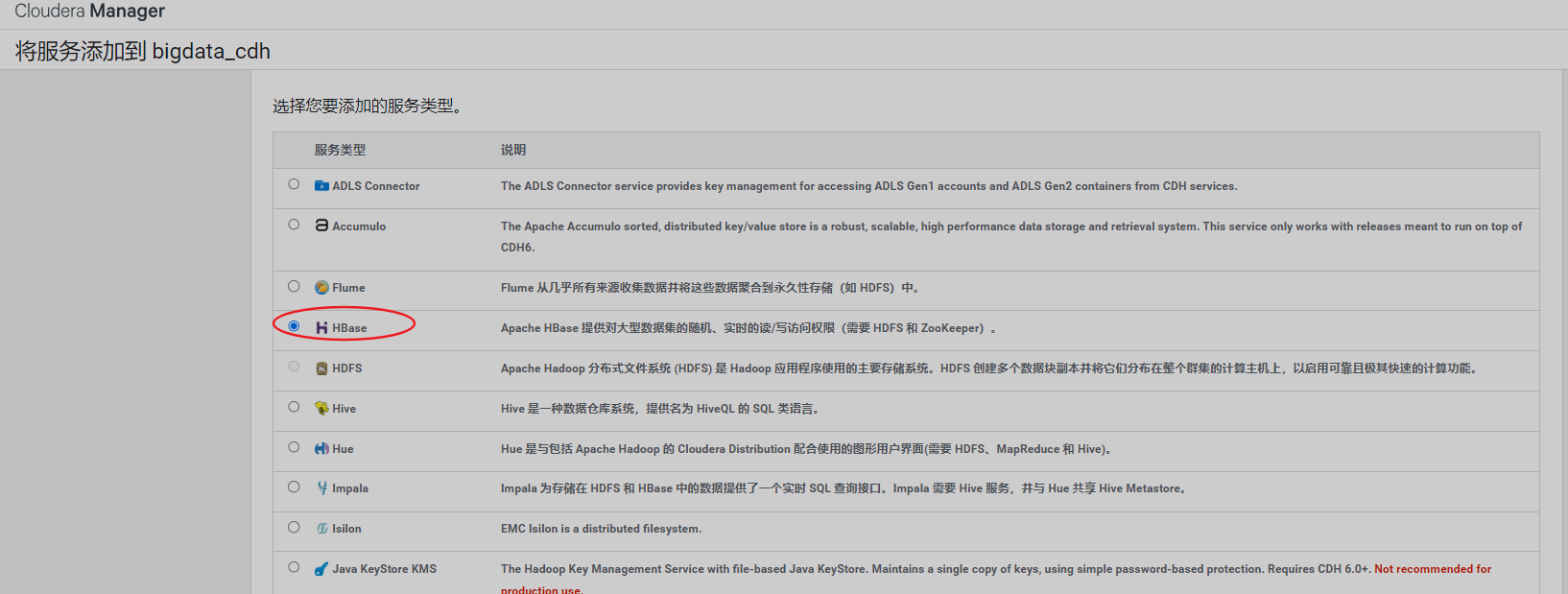
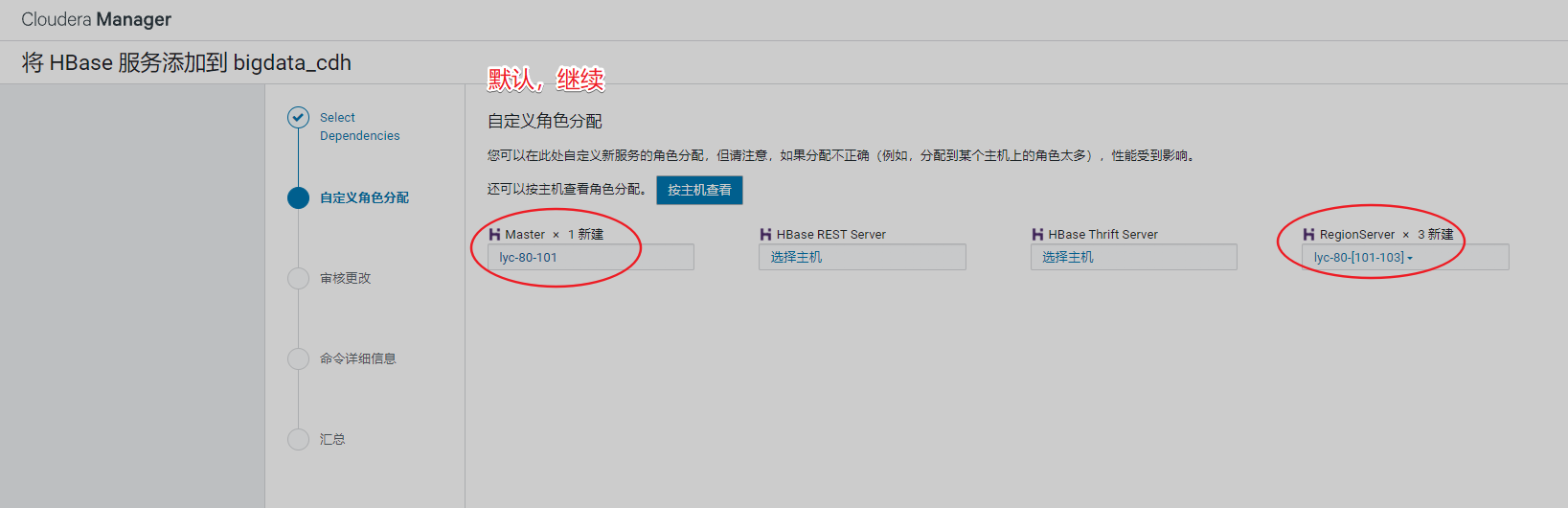
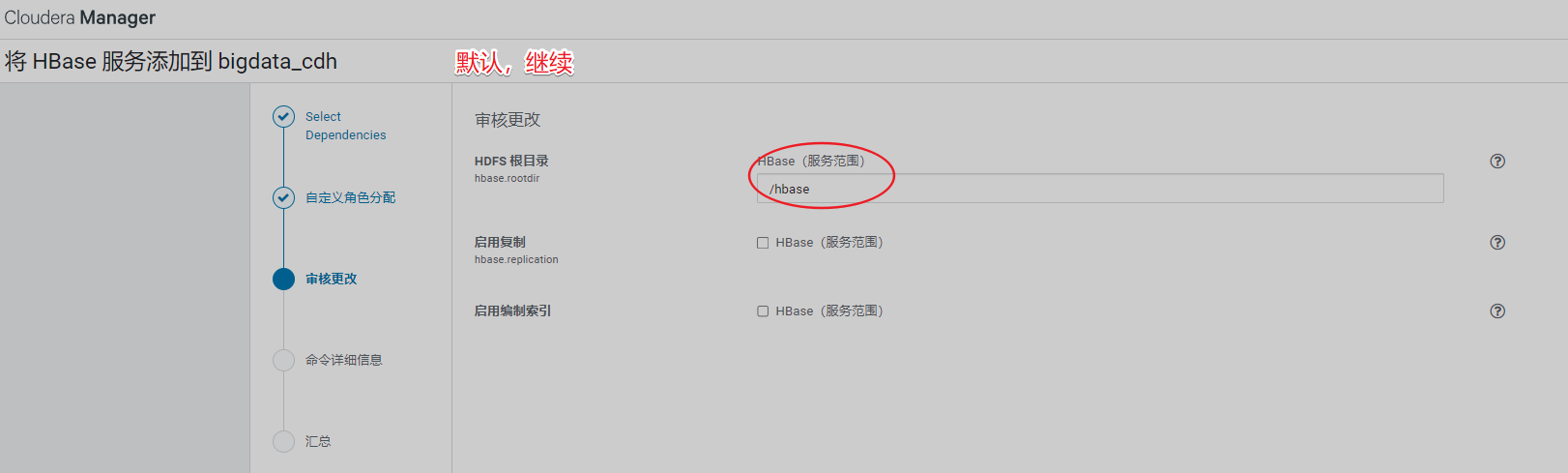
安装完成即可
8、安装Flume
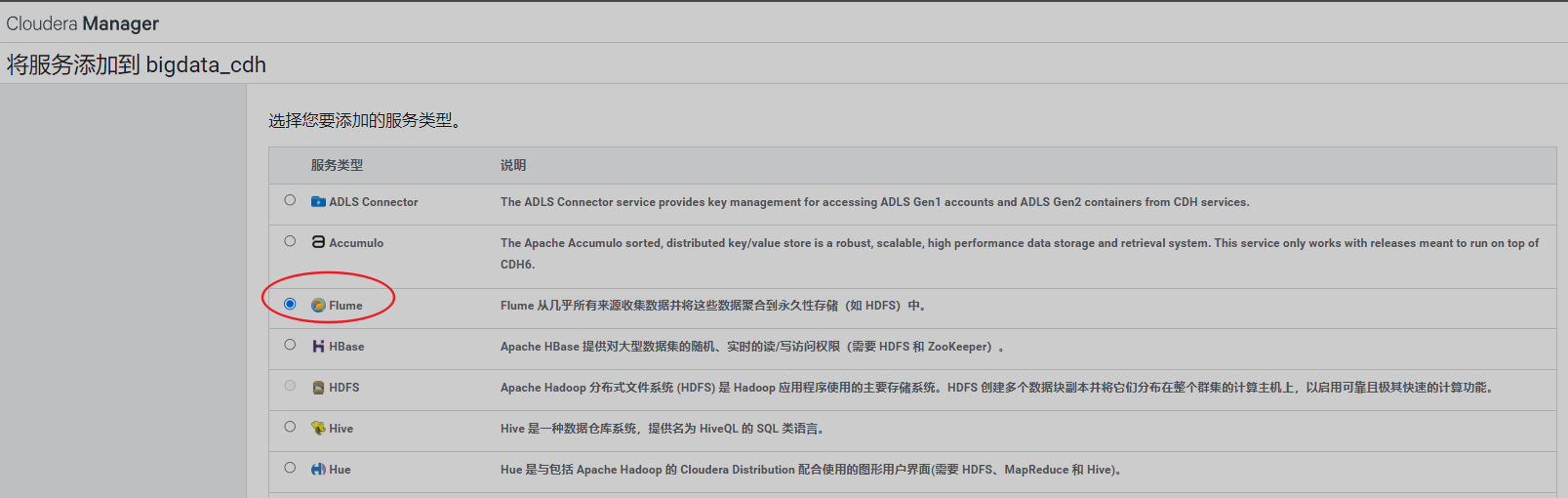
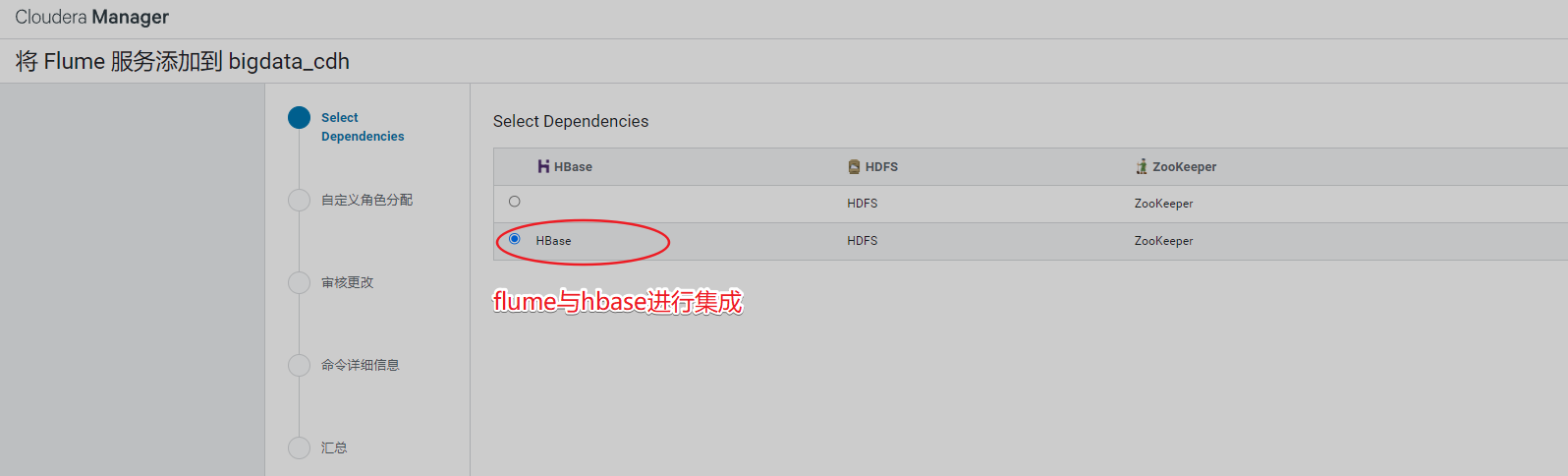
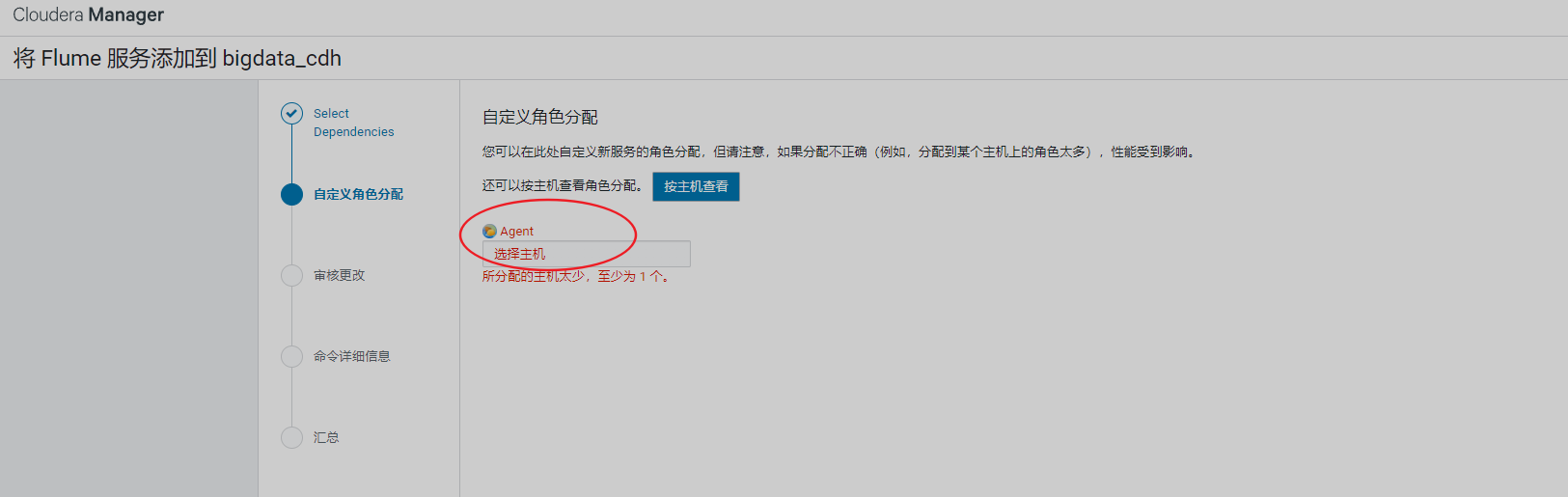
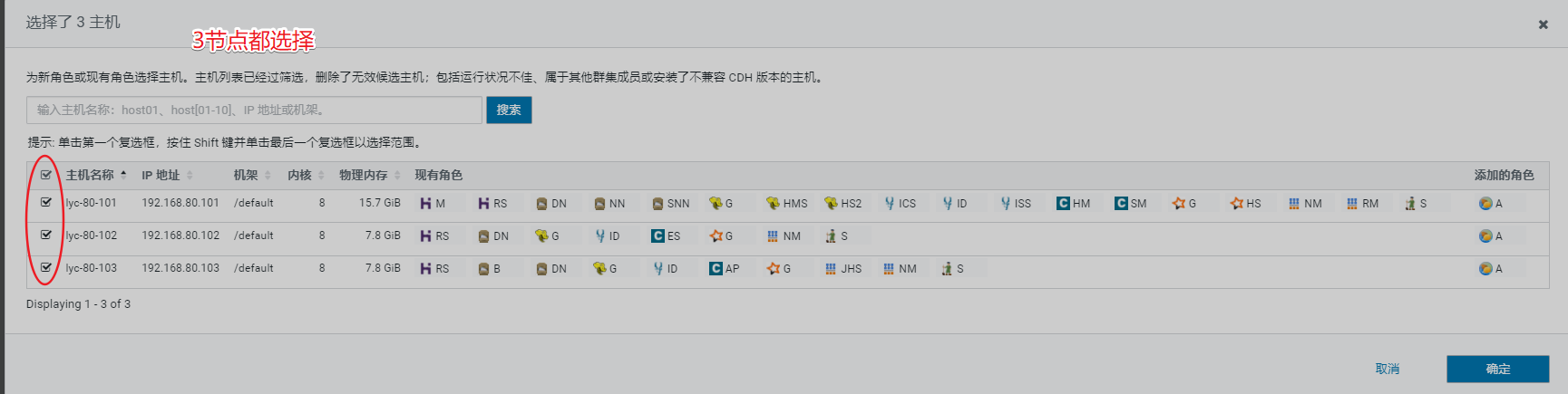
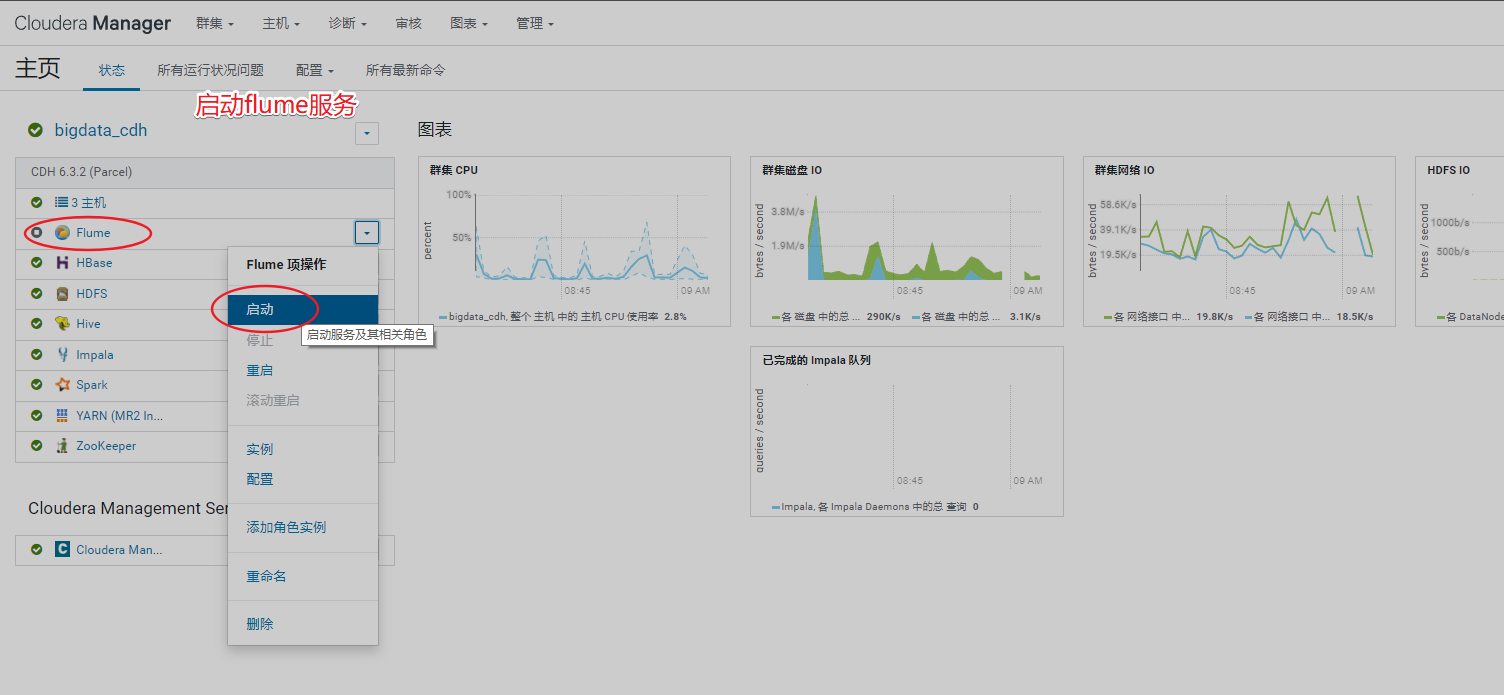

9、安装Sqoop
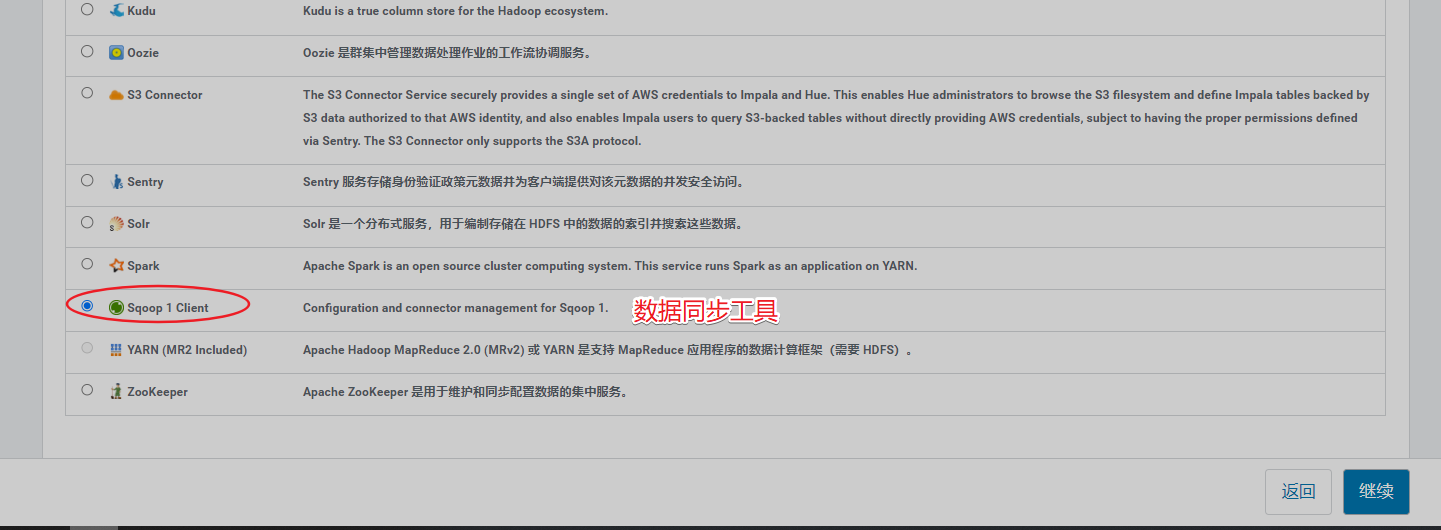
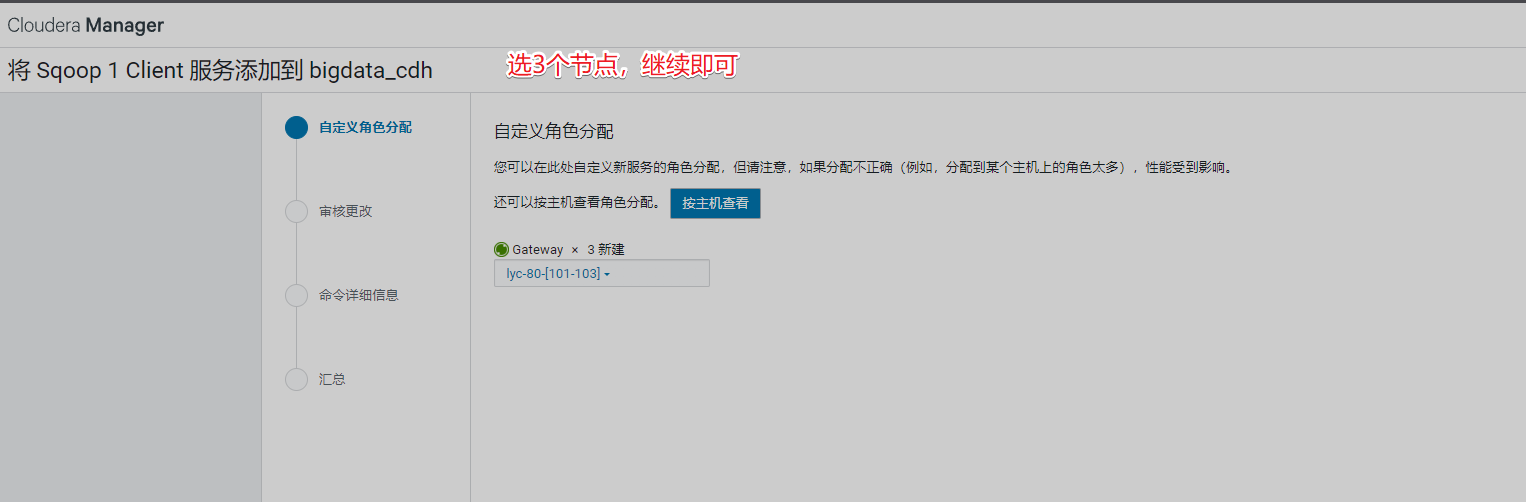
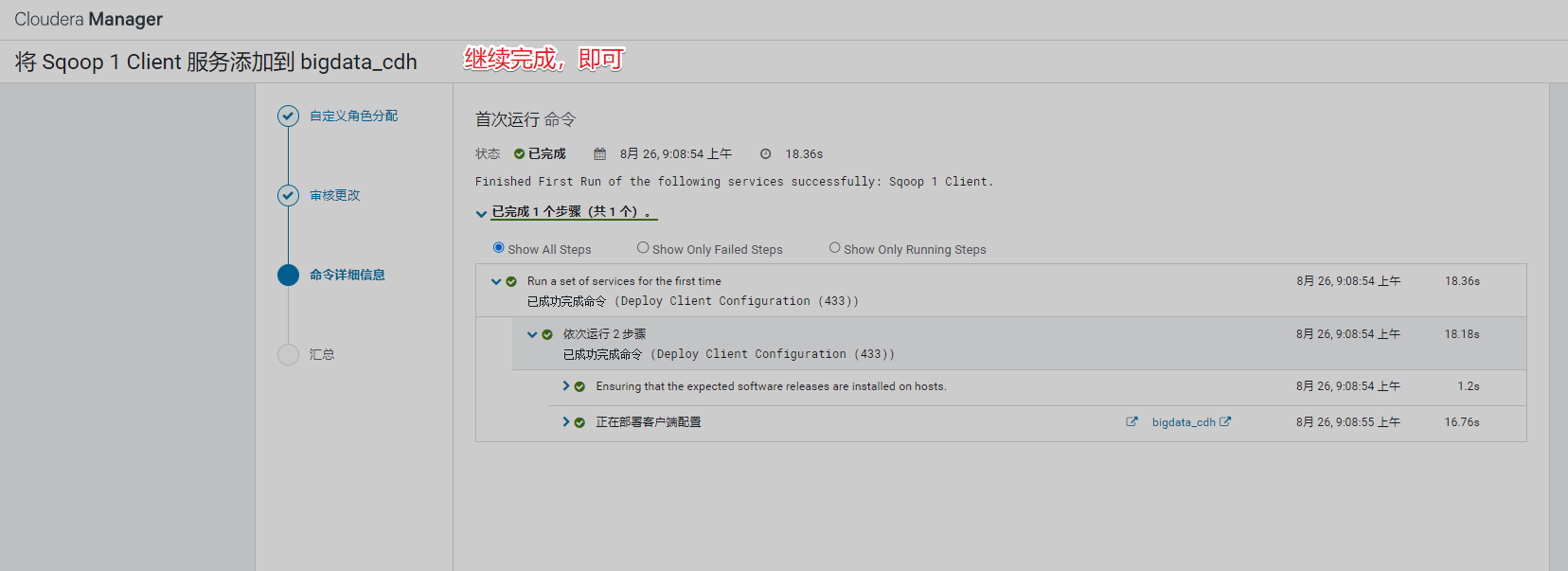
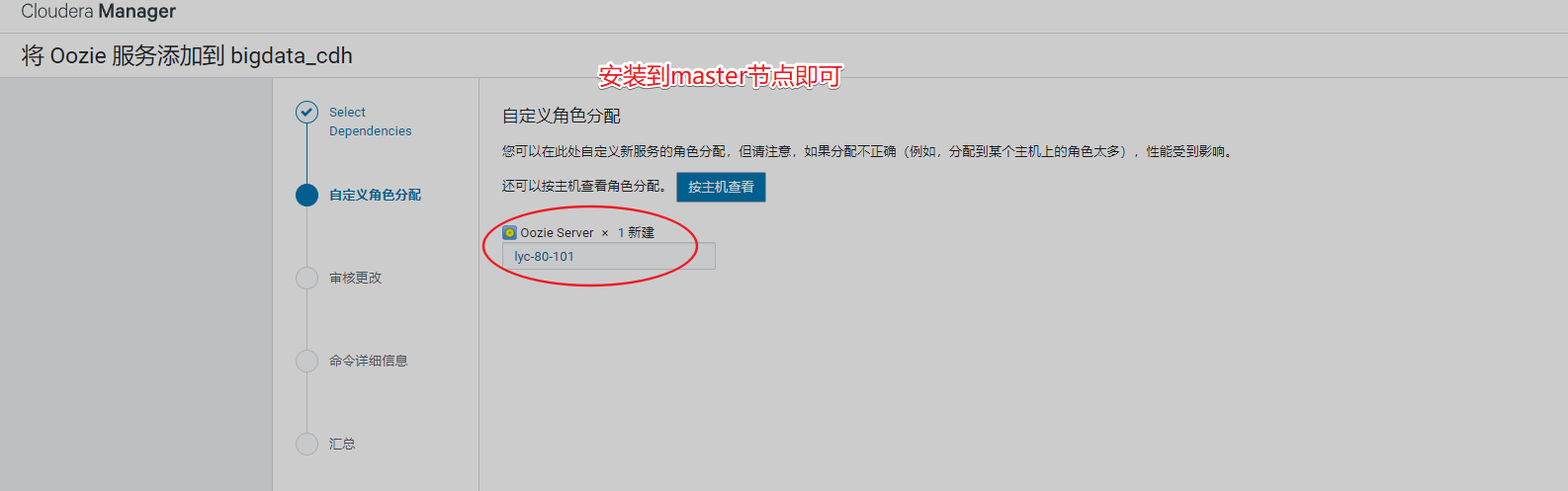
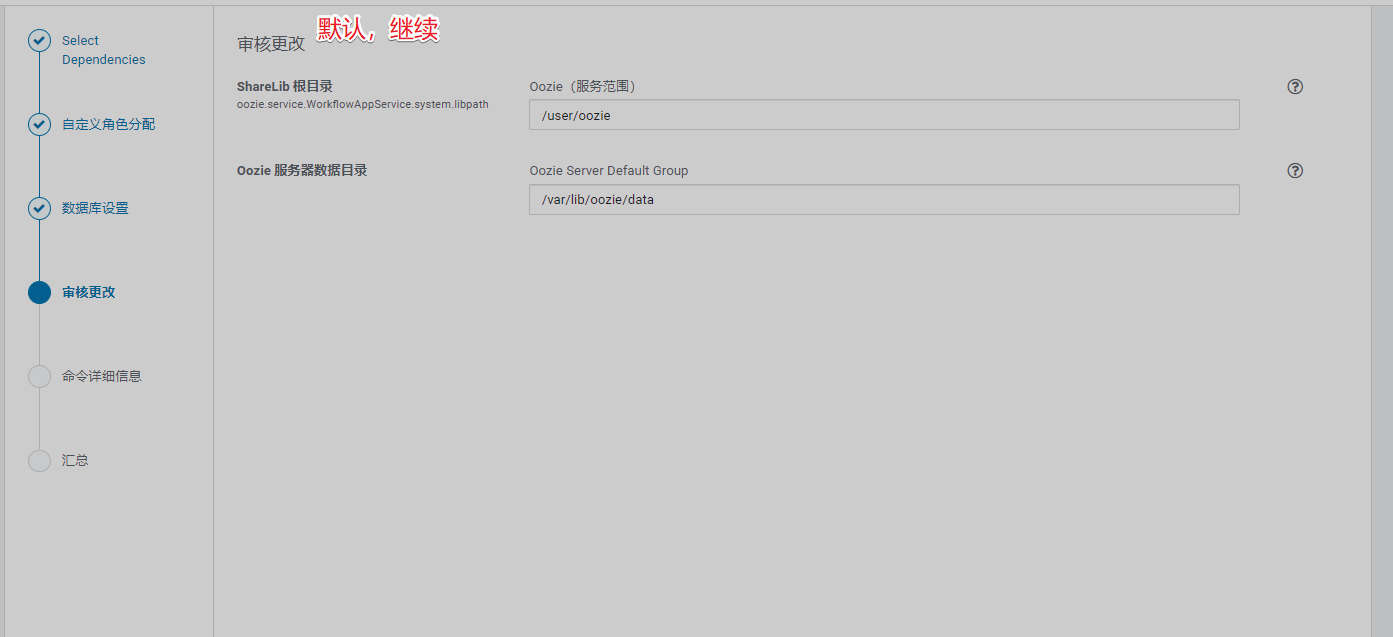
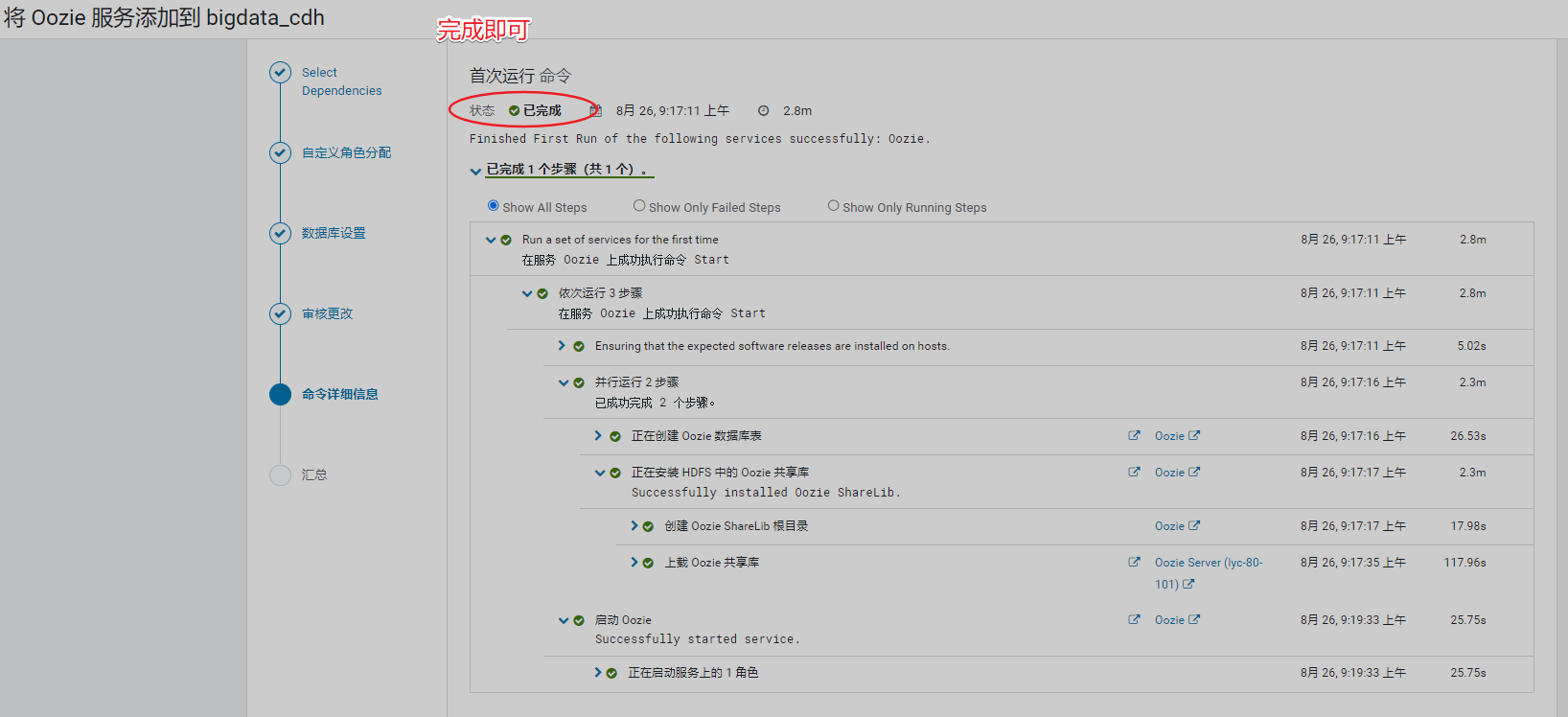
10、安装Oozie
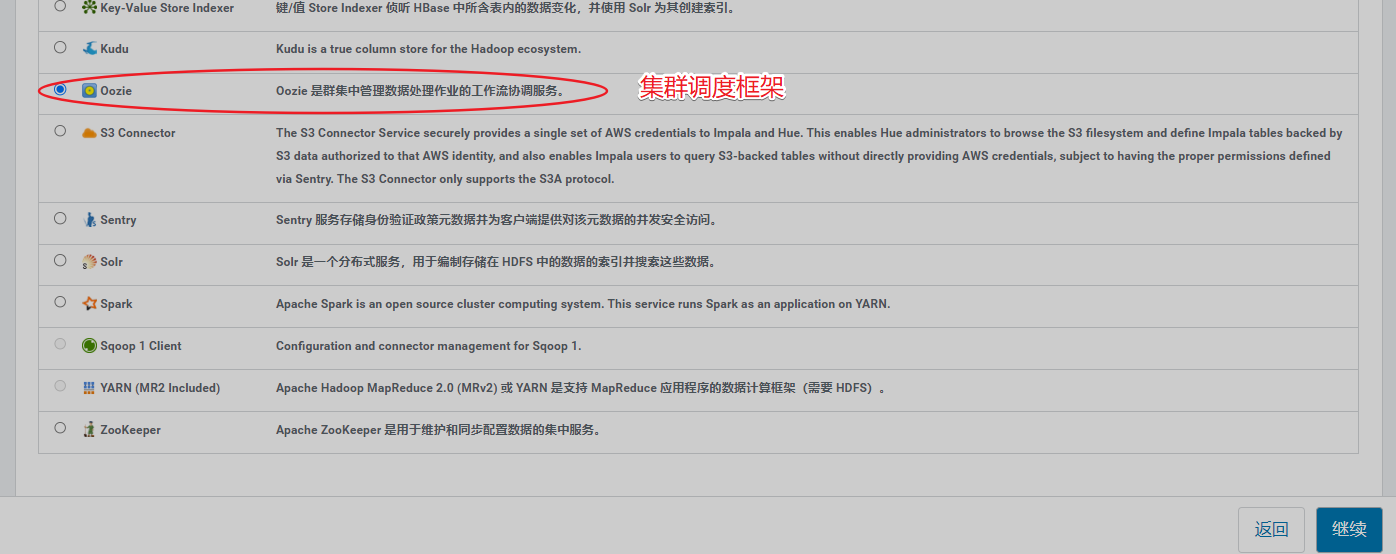
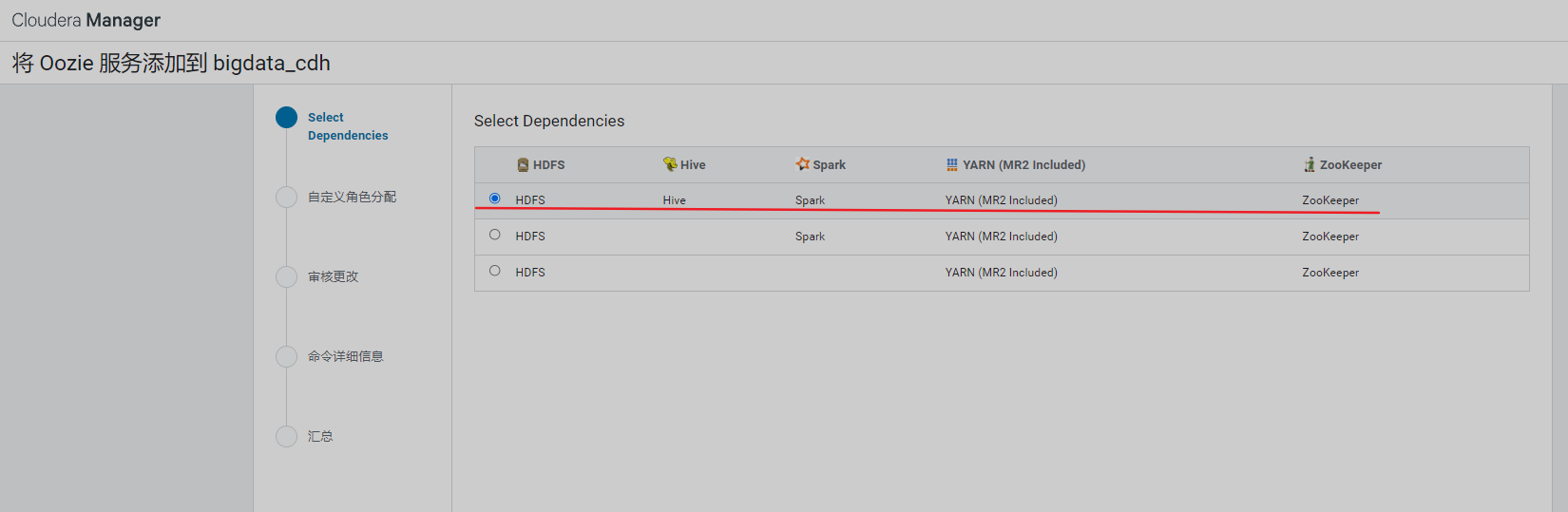
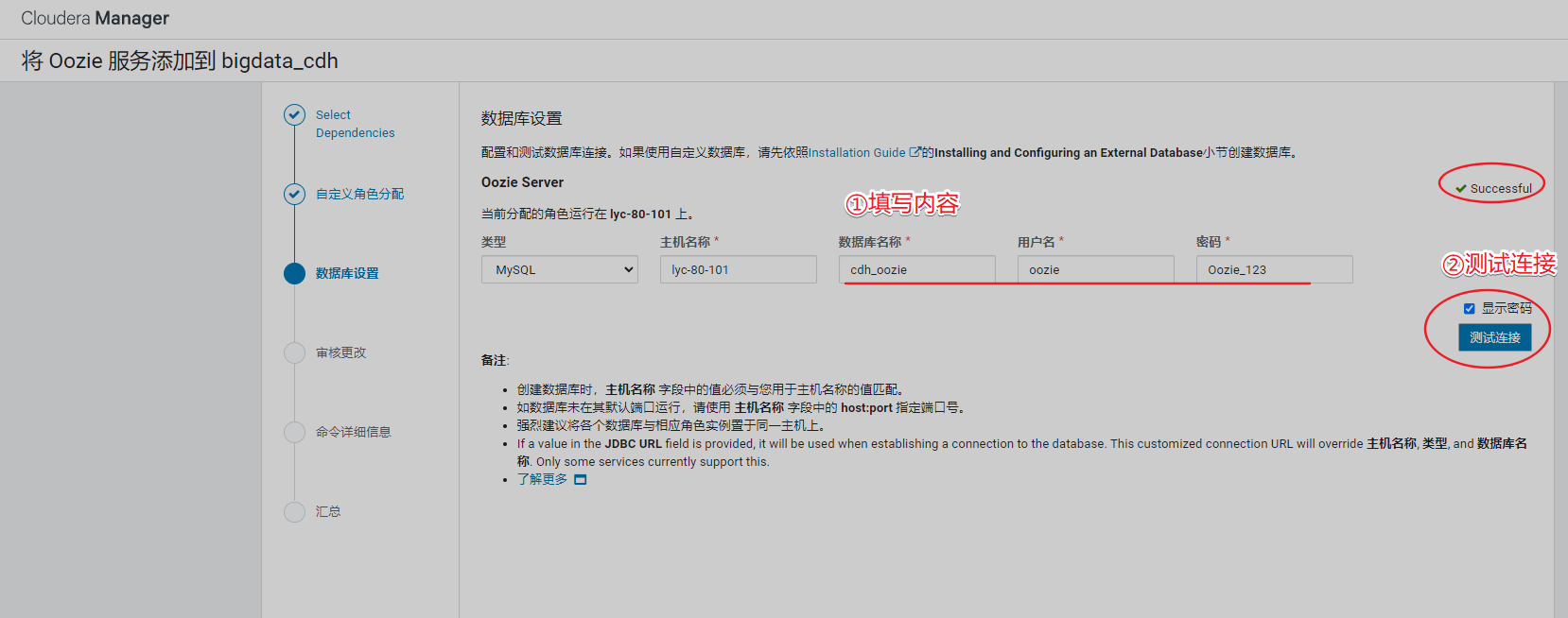
由于需要有数据库支撑,填写数据库账号、密码,测试后正常
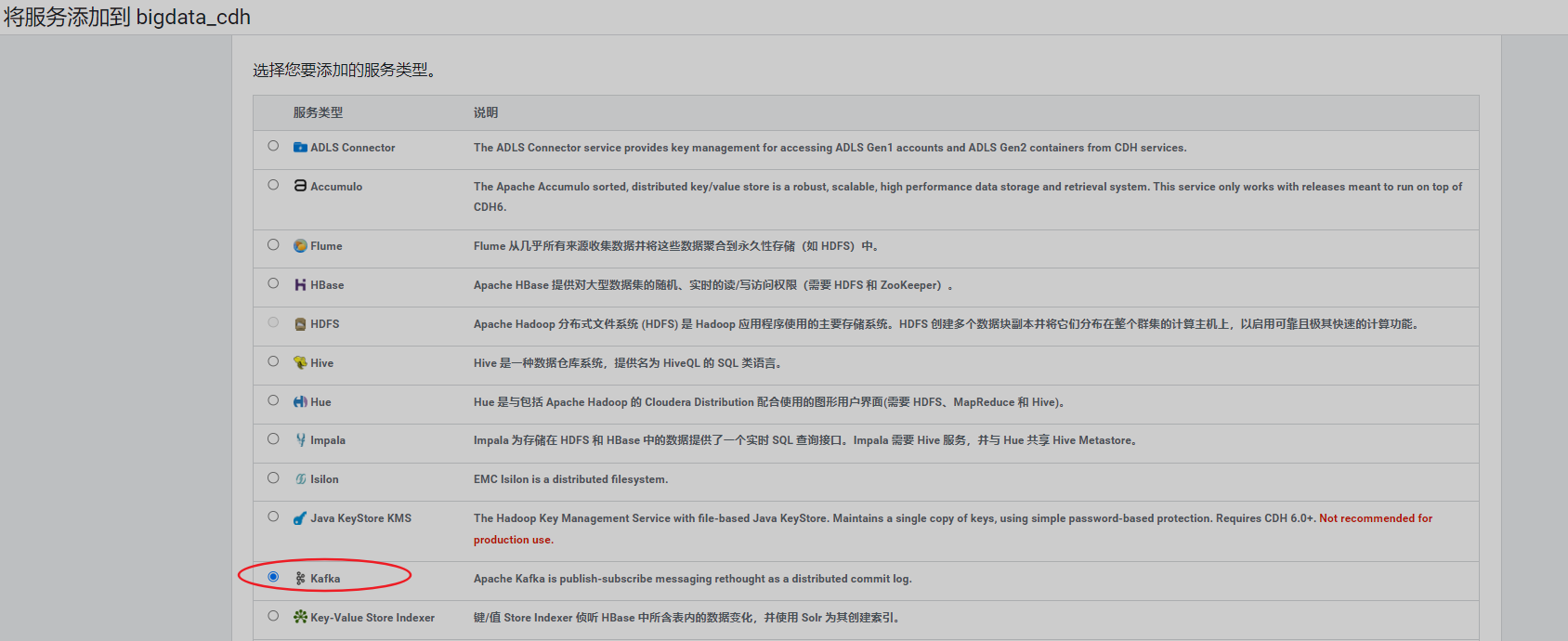
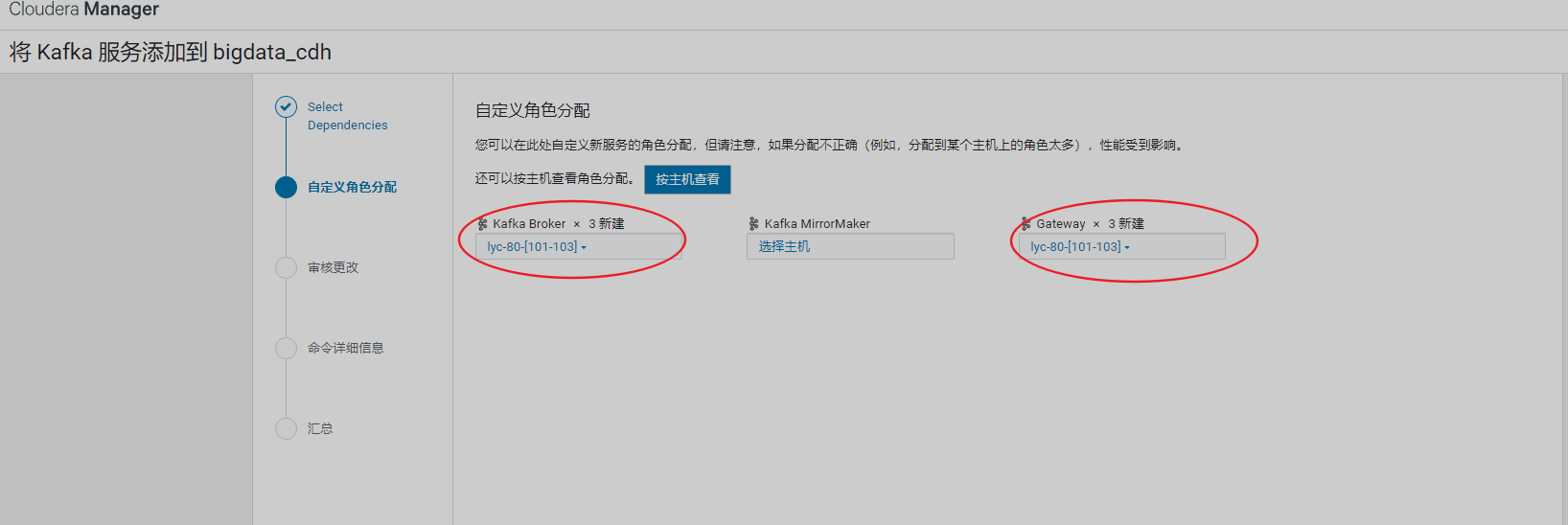
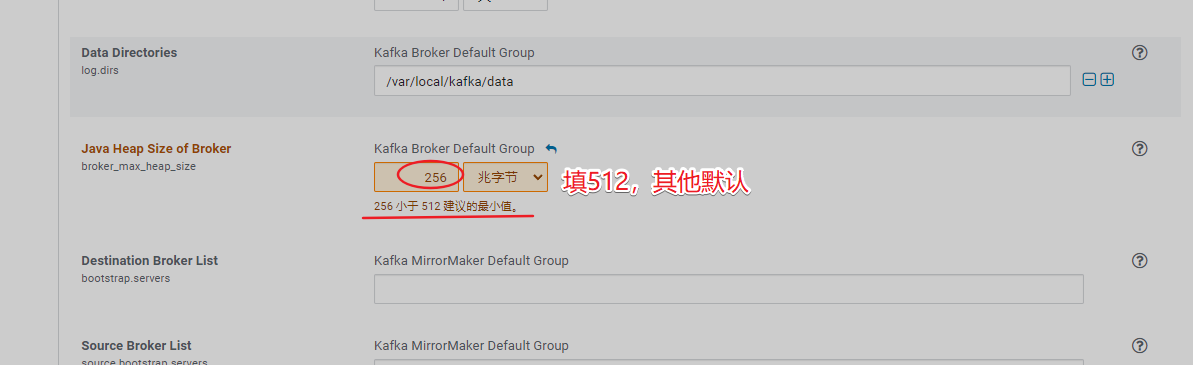
11、安装Kafak
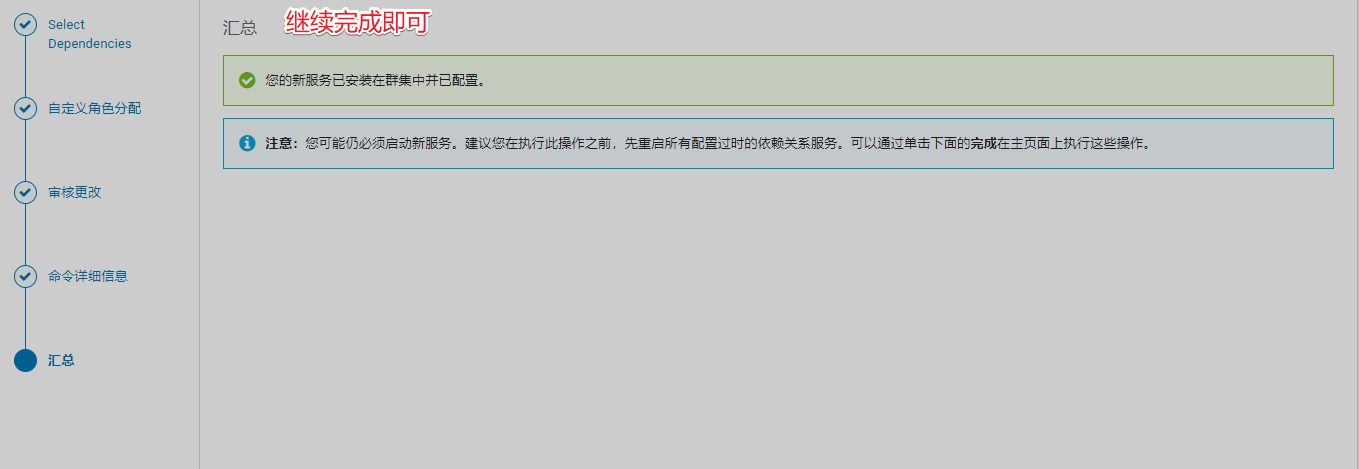
12、安装Hue

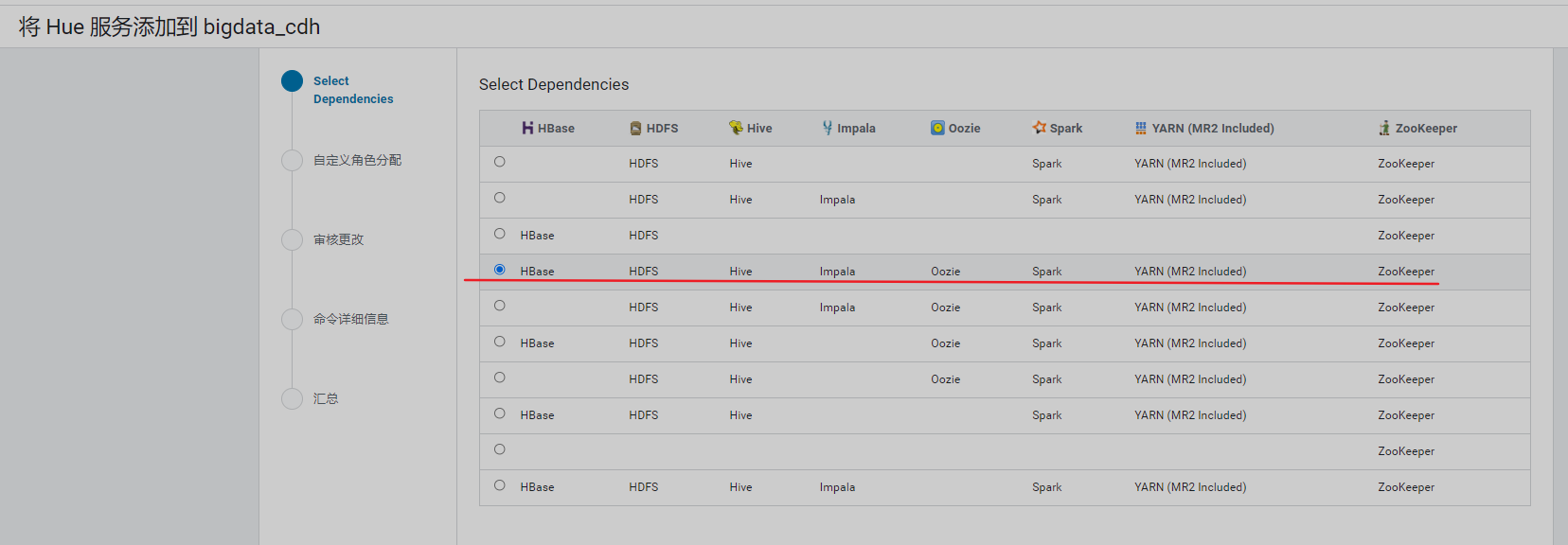
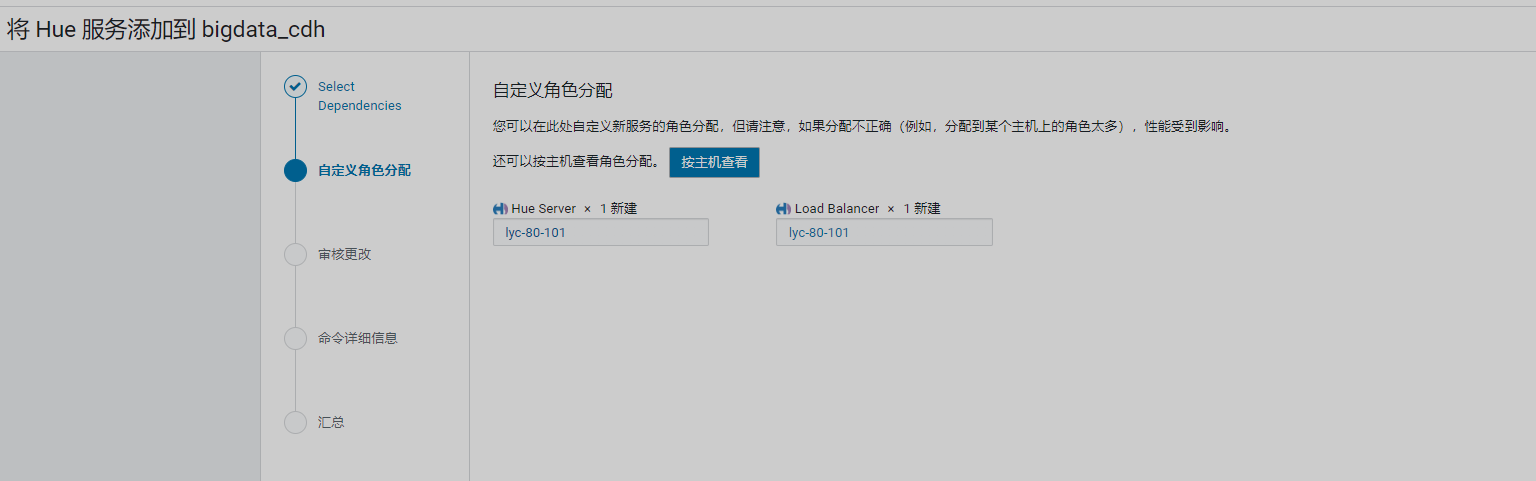
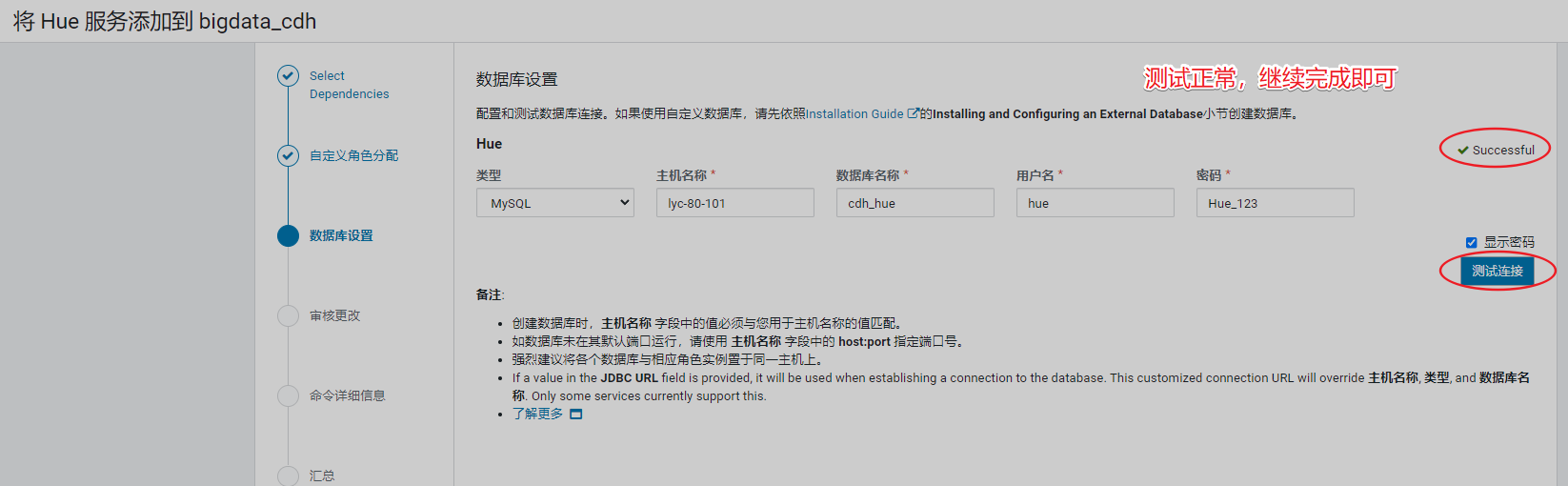
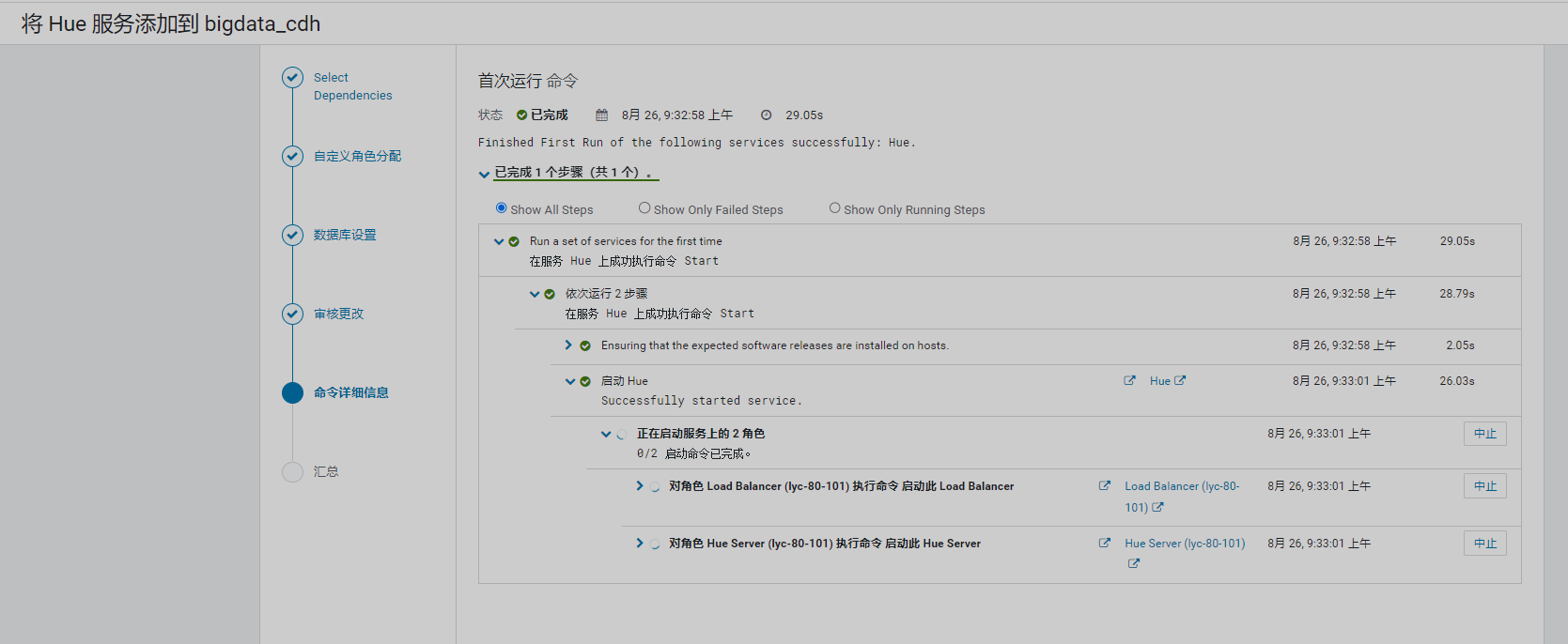
13、其他操作
开启hdfs权限
vim /etc/passwd
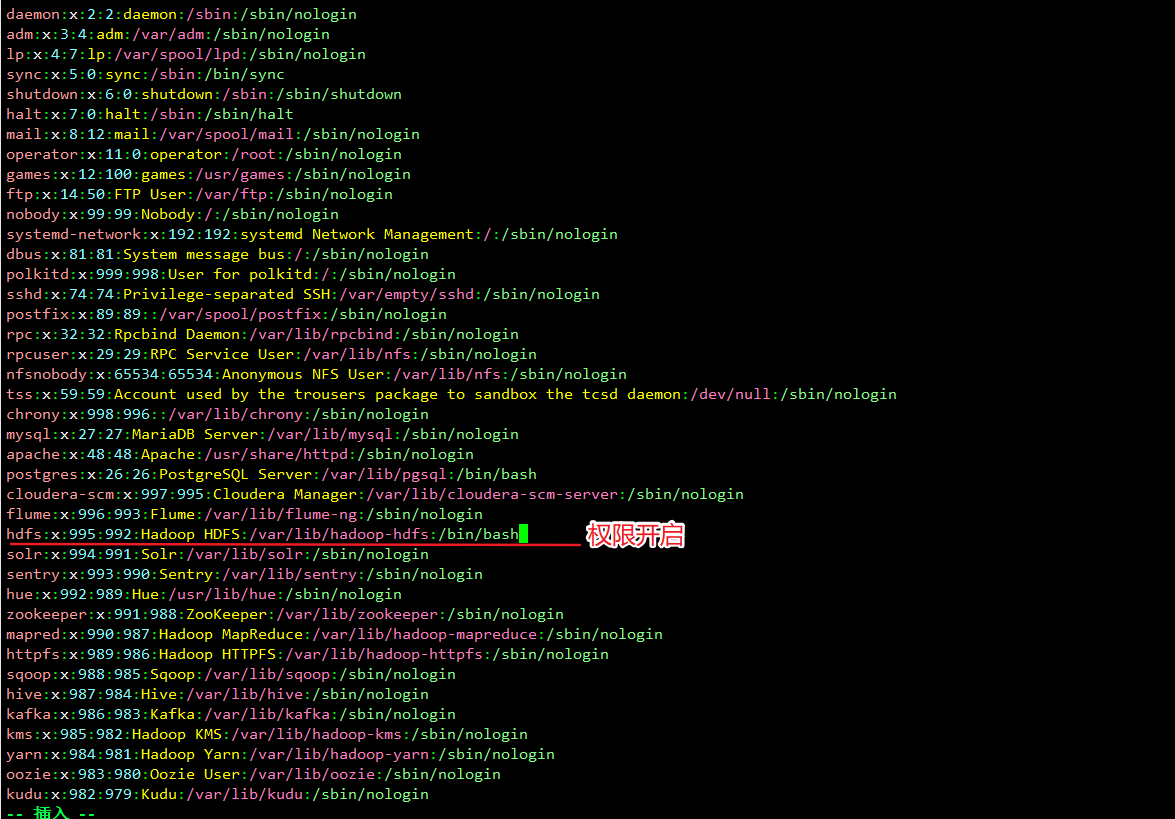
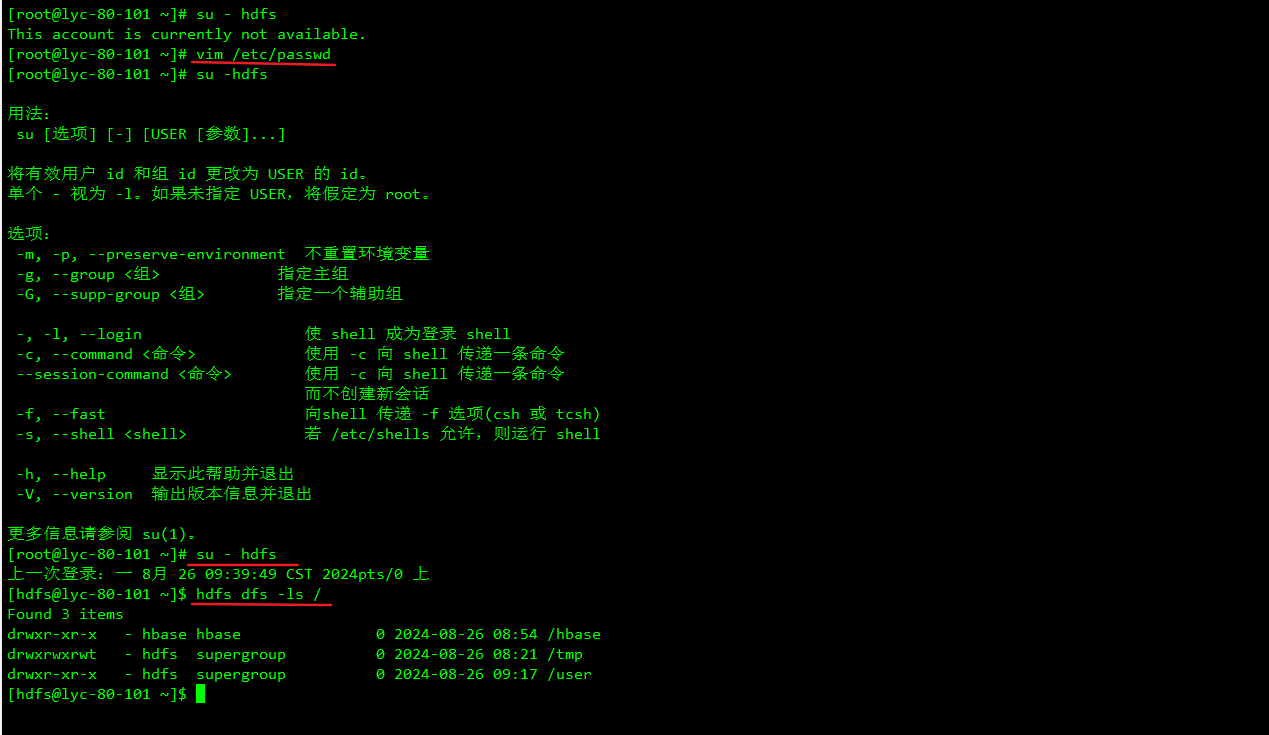
查看hdfs状态
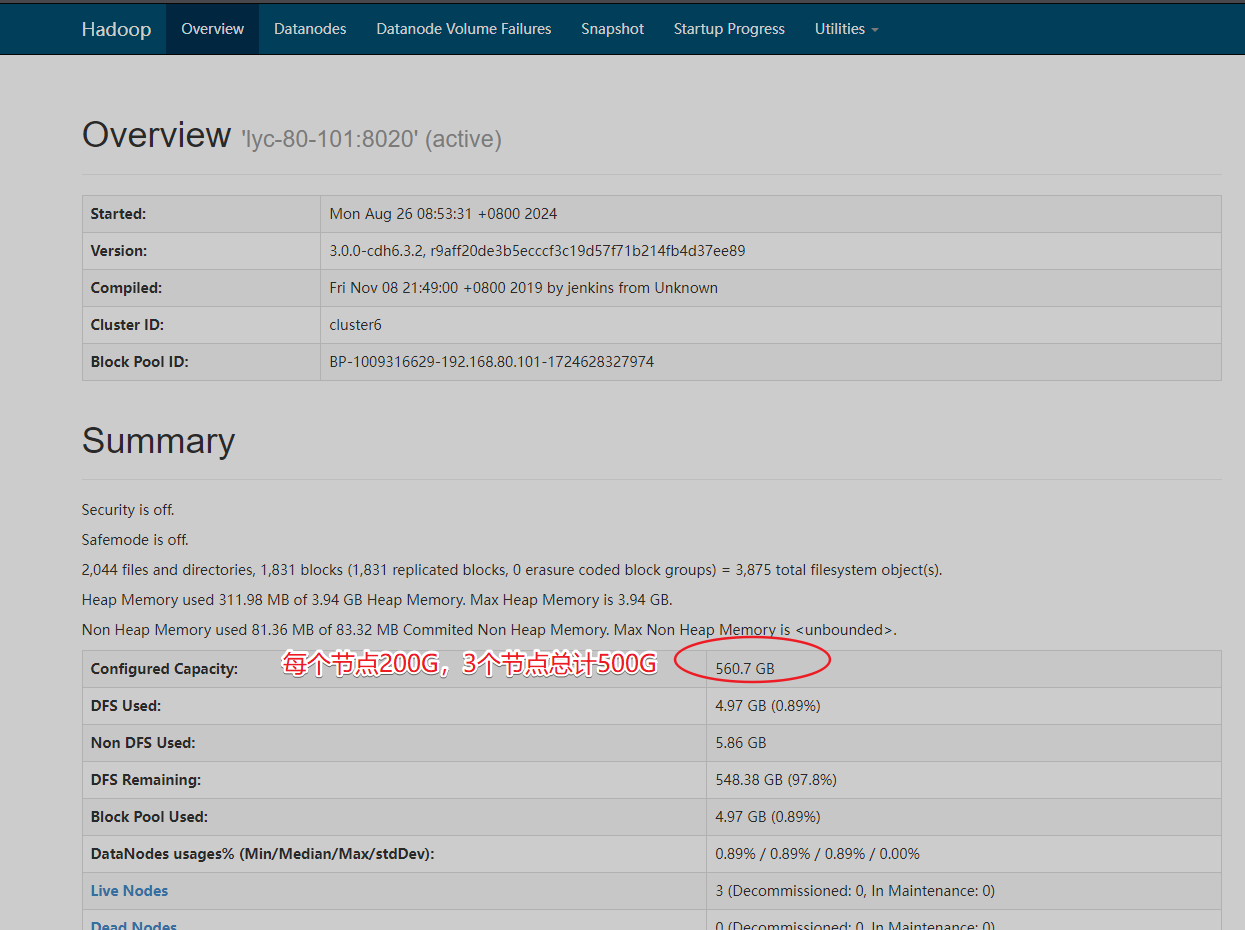
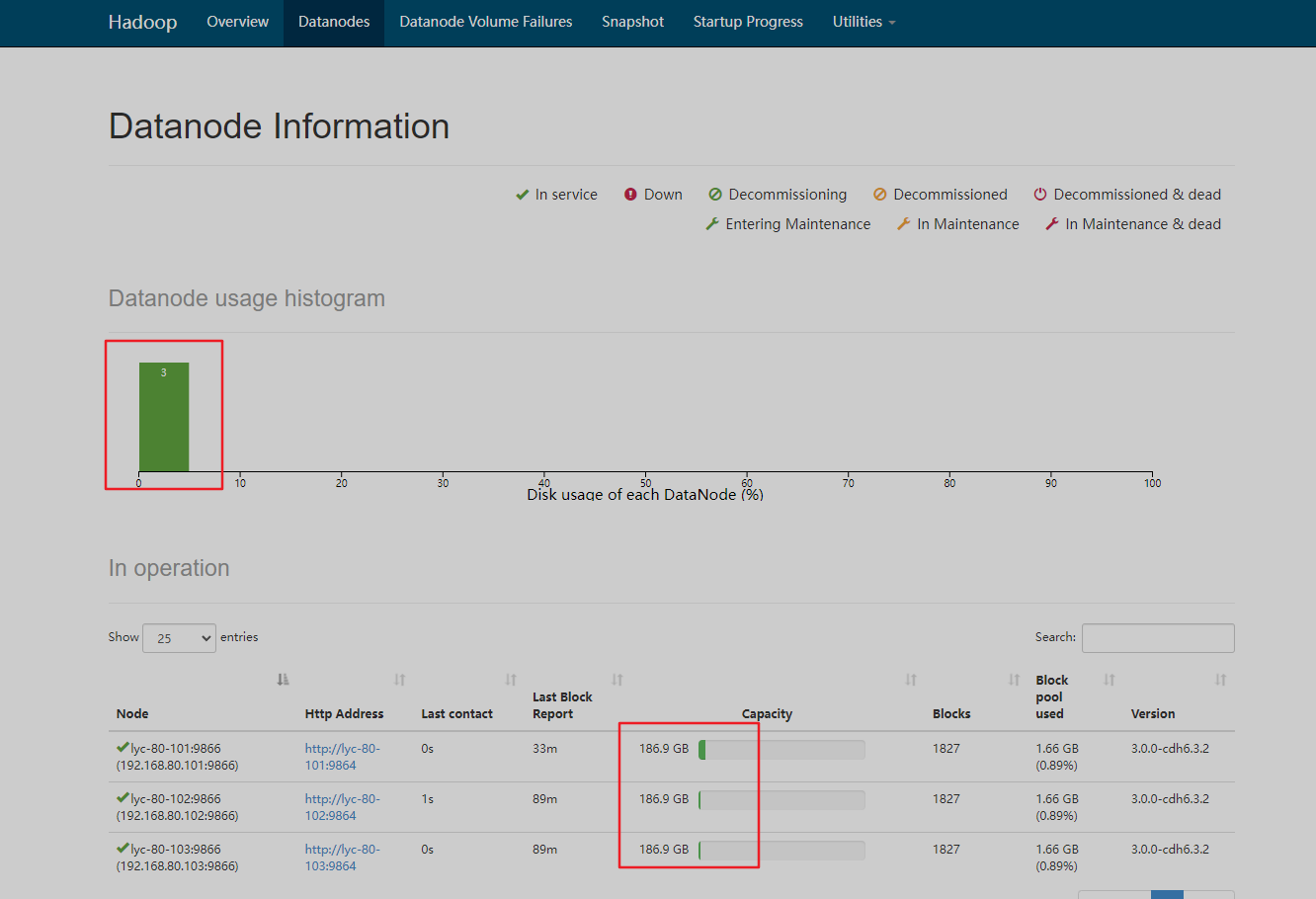
查看yarn界面
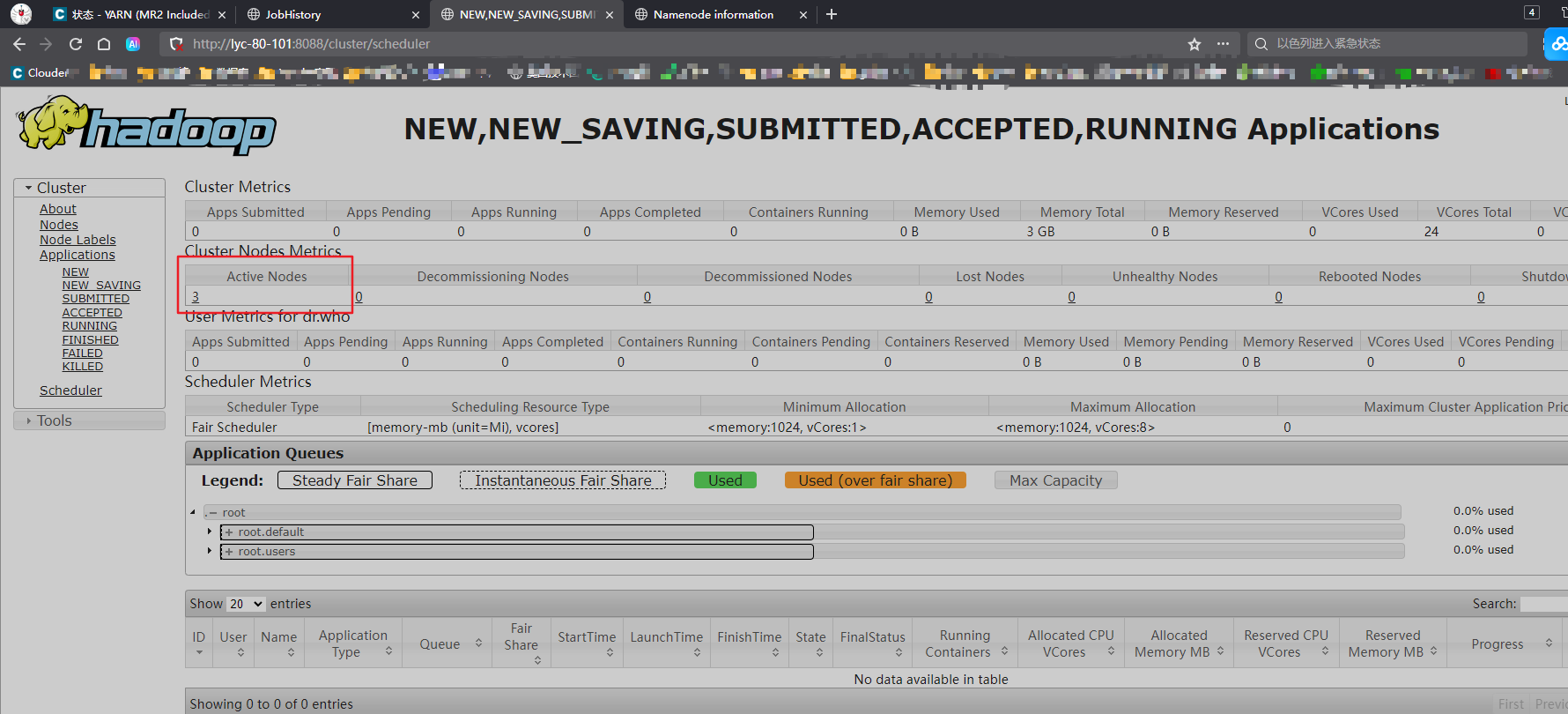
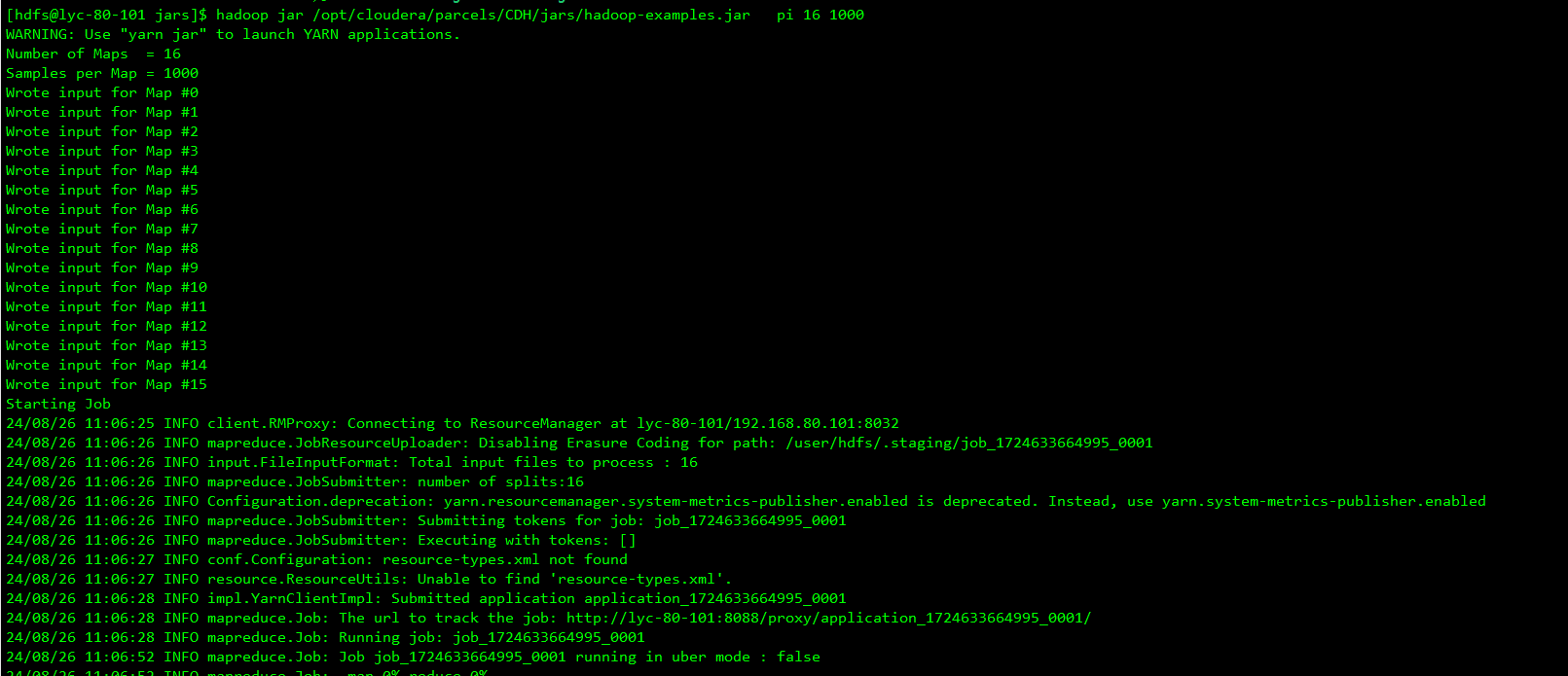
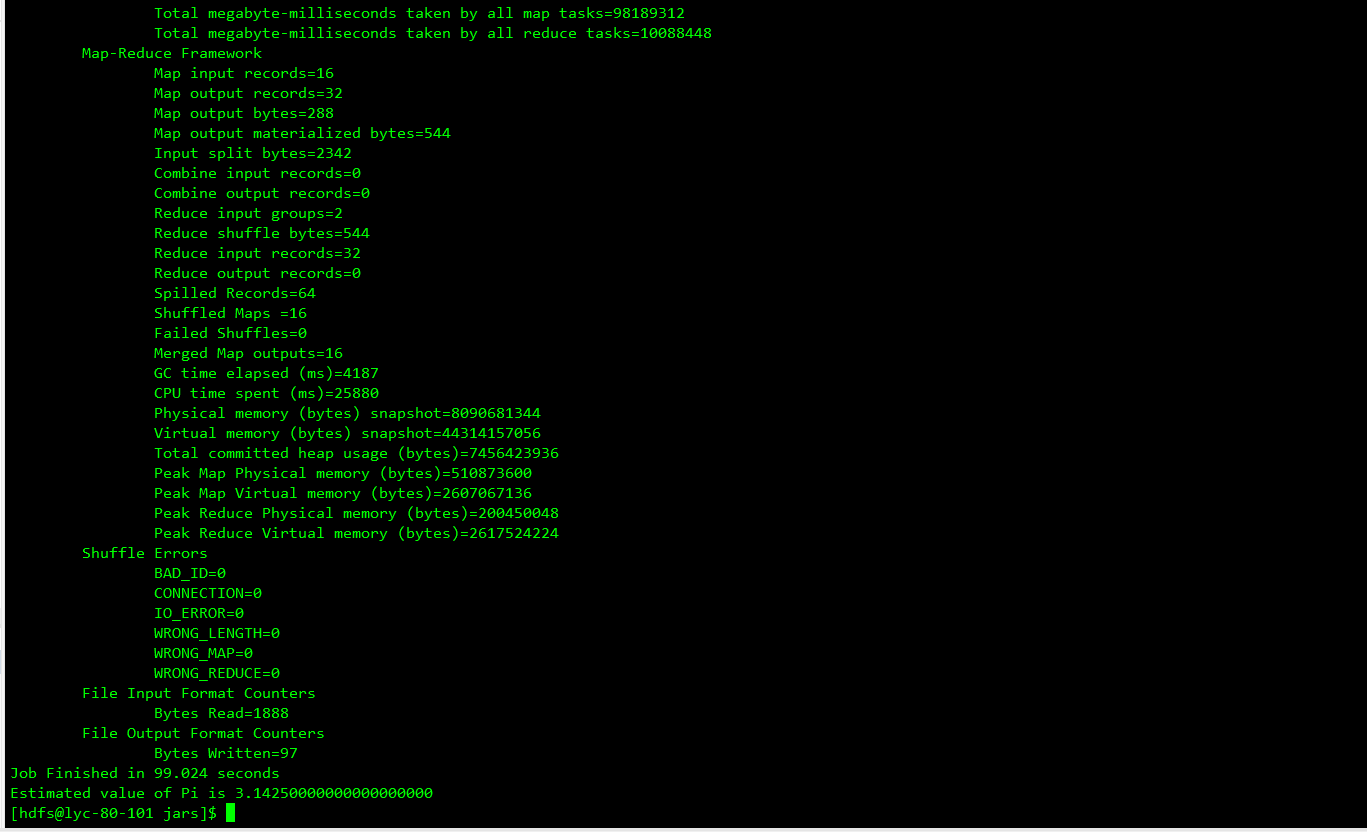
去yarn的webUI界面查看计算提交状态
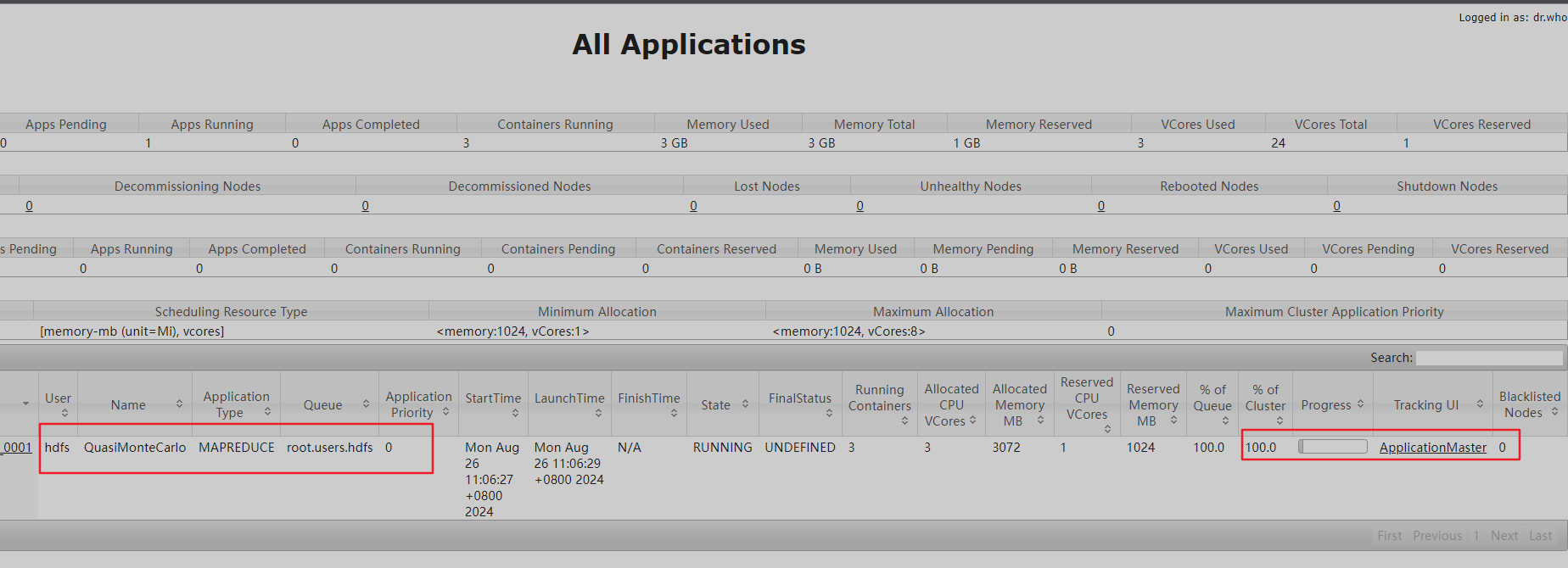

跑完后的状态
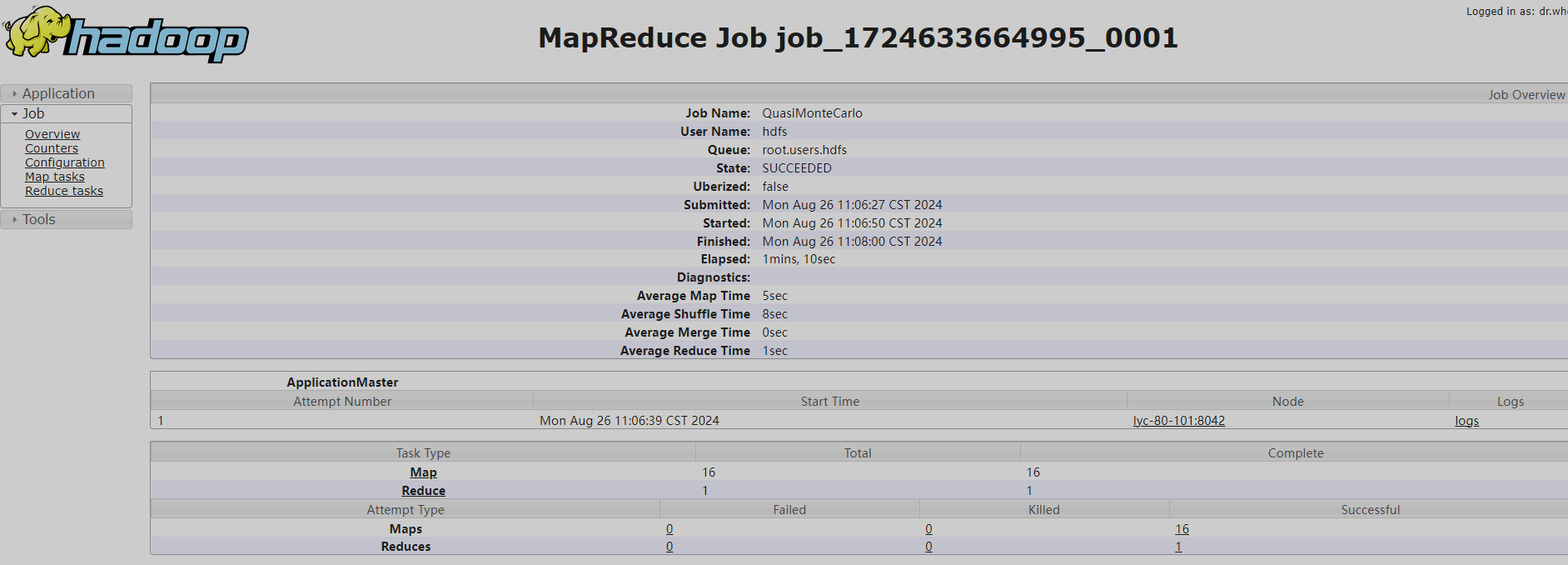
点log可以查看日志
查看map task
查看reduce task
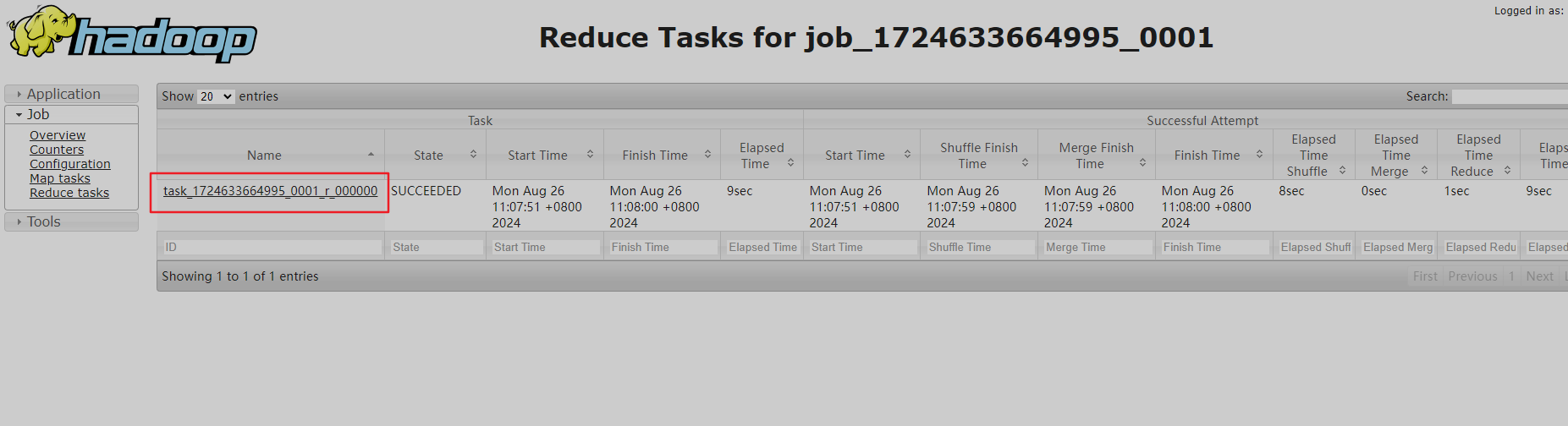
为什么map task有16个?二reduce task只有1个?
因为MR计算的时候,map端是分开计算的,reduce端是合并计算结果,然后进行结果输出,体现的‘分而治之’思维。
查看下MR计算后hdfs上的文件夹
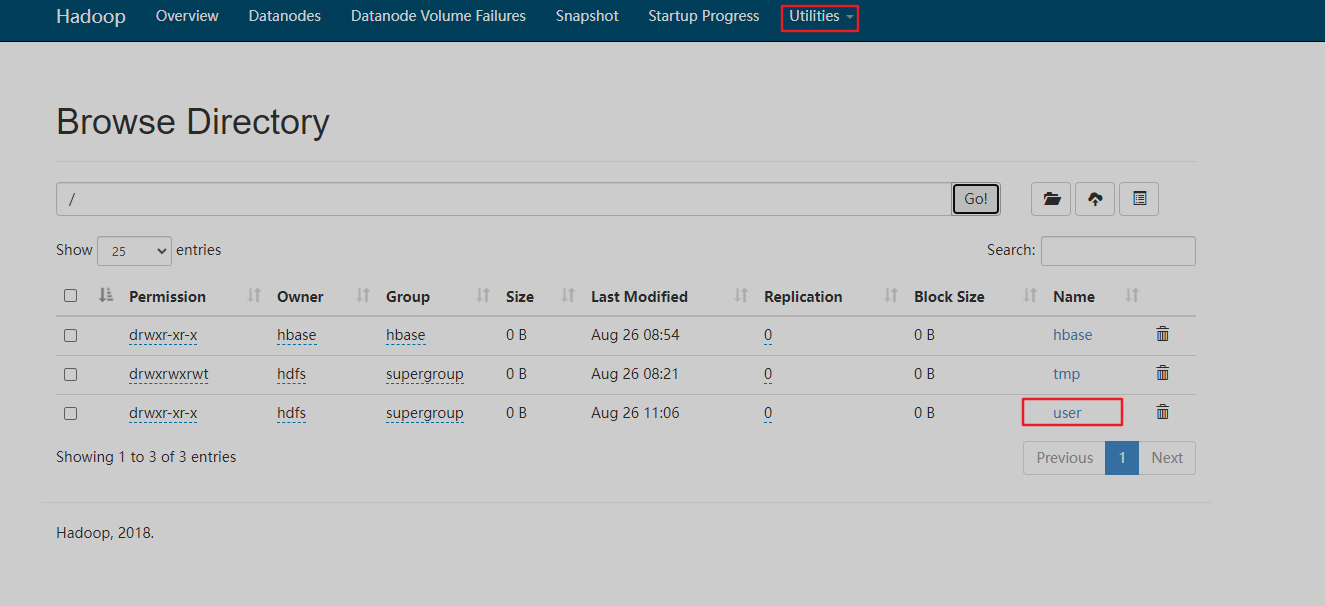
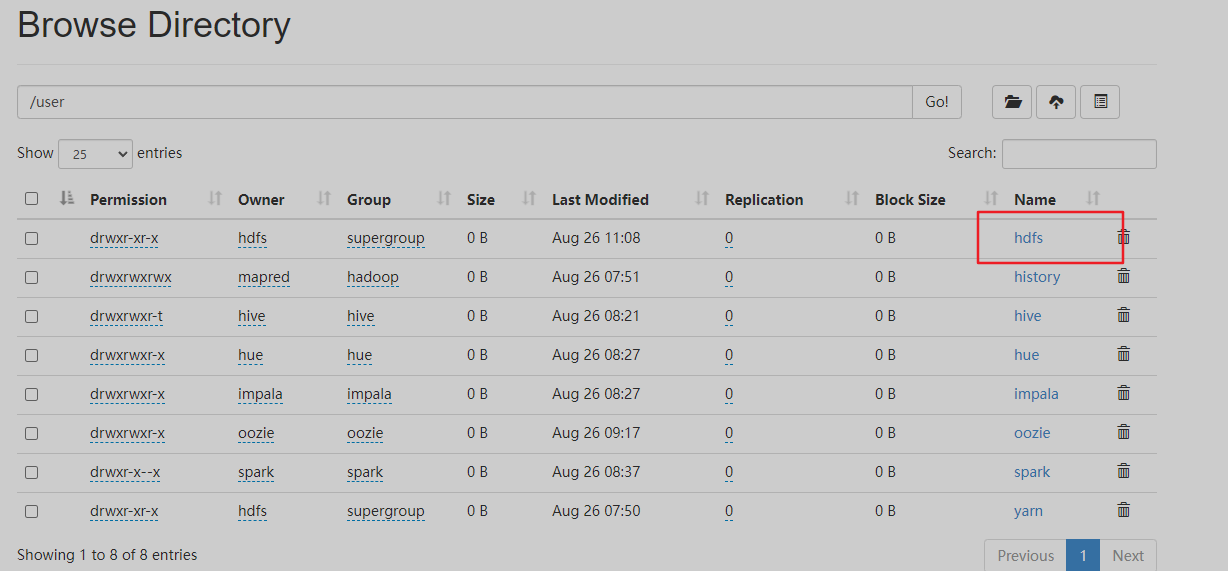
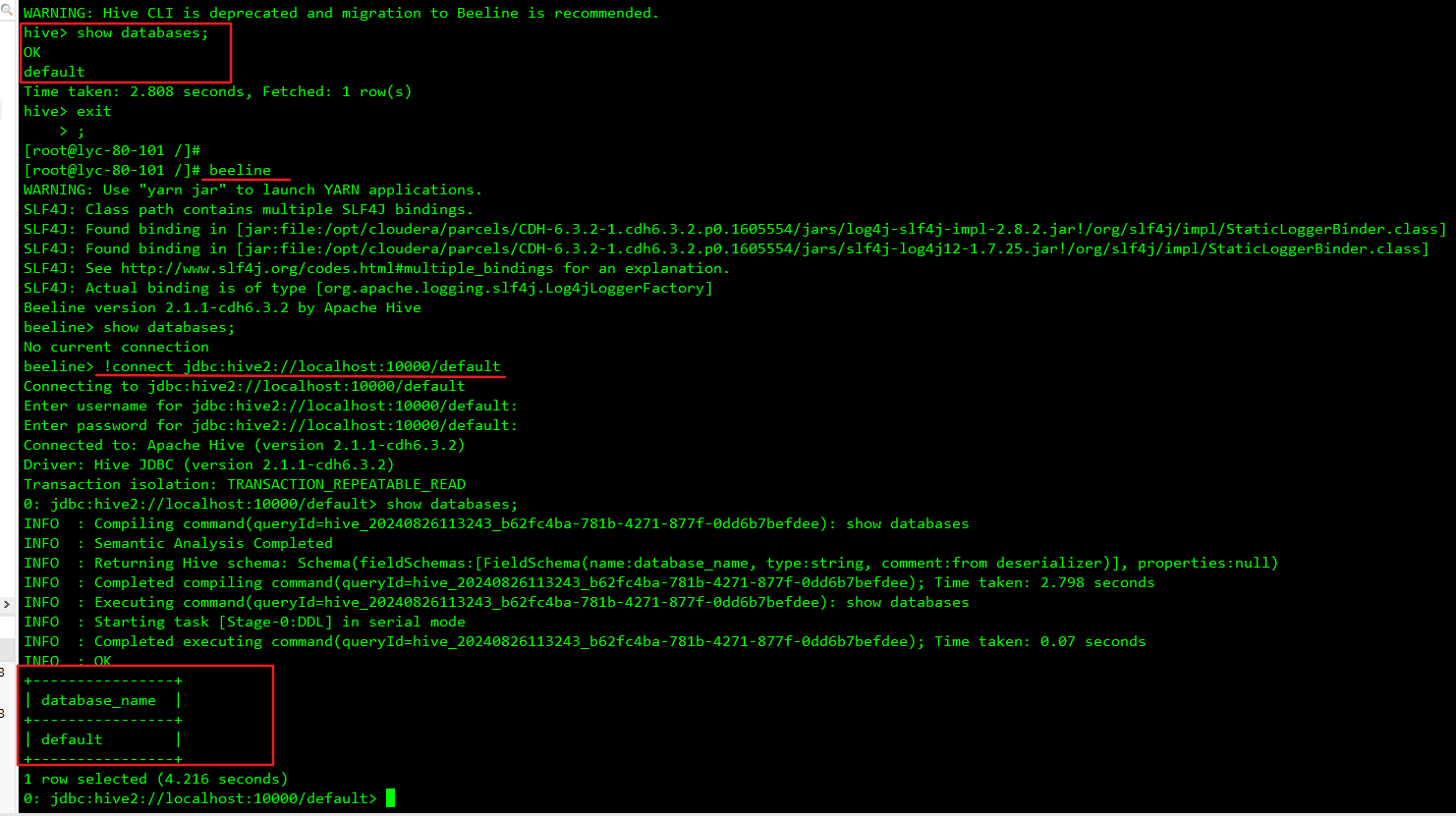
14、测试hive
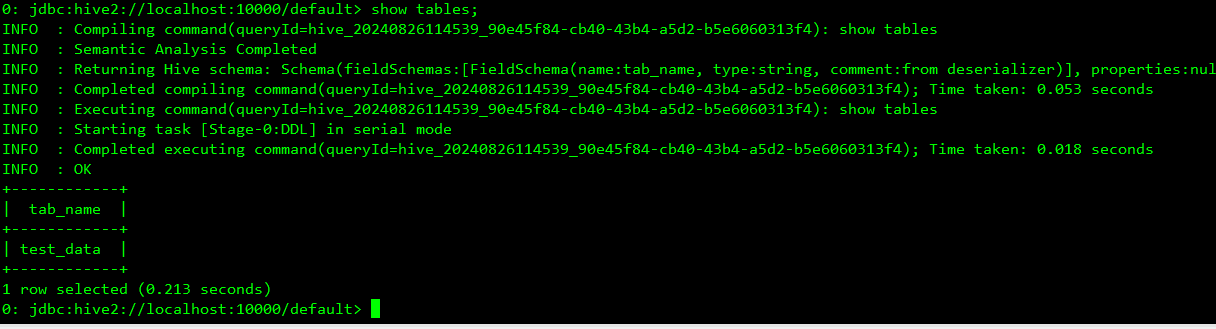
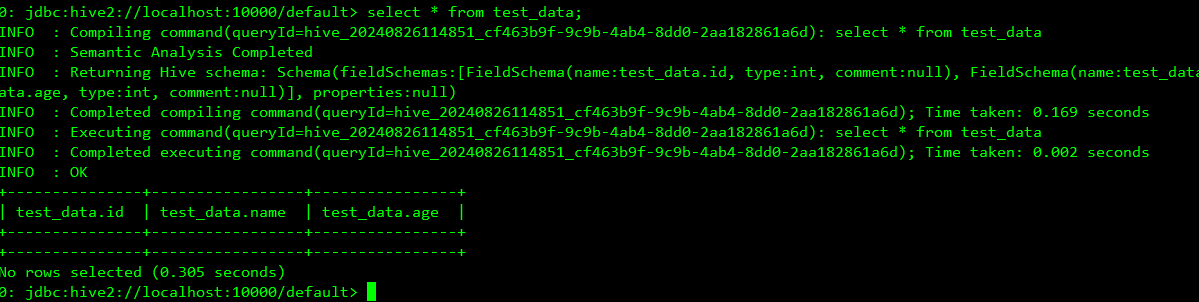
15、hue查看
主要查看作业界面
其他功能,有时间再慢慢研究
【总结】
CDH确实可以简化大数据集群的安装,但是资源开销比较大
对于平时做测试实验的我们来说,二进制安装单台机器测试数据即可
在企业真是的生产环境中,CDH确实优势明显,能快速部署大数据集群。

















 2192
2192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









