




简介:数据库是应用程序数据支撑的基础工具,涉及基本概念、不同类型、SQL语言使用、数据库设计、数据查询与操作、事务处理以及安全性和备份策略的全面解析。本文详细探讨了数据库系统的选择、SQL的熟练应用、数据库模式的有效设计、数据的有效查询和操作方法、事务处理的ACID原则,以及保障数据库安全和数据备份的必要措施。为IT专业人员提供了数据库使用和管理的实用指南。 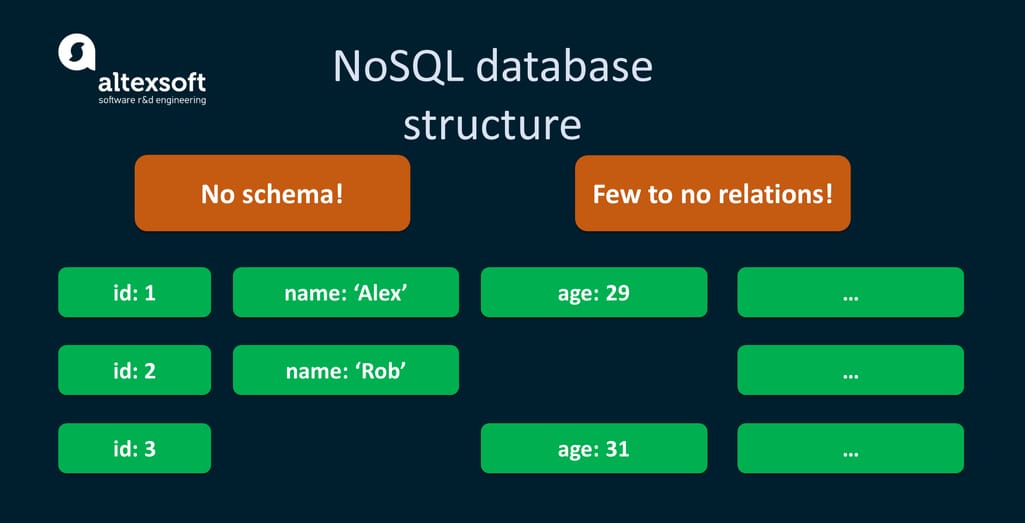
1. 数据库基本概念和重要性
1.1 数据库简介
数据库是按照特定的数据结构来组织、存储和管理数据的仓库。它们允许快速的信息检索、数据插入、更新和删除操作。在今天的数字时代,几乎每个行业都会用到数据库来存储关键信息,无论是用于简化运营流程、数据分析还是处理大量事务。
1.2 数据库的重要性
在企业和组织中,数据库的重要性不言而喻。它们为企业提供了数据的持久性存储解决方案,确保了数据的安全性和完整性。有了数据库,业务分析变得更加可行,因为企业能够从大量数据中提取有用的信息,辅助决策制定。此外,数据库还能提高数据处理效率和系统的可靠性。
1.3 数据库分类
数据库分为关系型数据库和非关系型数据库。关系型数据库利用表格的形式存储数据,适用于处理结构化数据,而非关系型数据库(NoSQL)则适用于存储大量的、格式多变的数据。接下来的章节将深入讨论关系型数据库的特点、应用、SQL语言的使用,以及数据库的设计、查询优化、事务处理等高级主题。
2. 关系型数据库的特点和应用
2.1 关系型数据库核心概念
关系型数据库是由一系列以表的形式组织的数据组成的,表之间可以通过关键字(Key)来相互关联。理解和掌握这些核心概念,对于任何数据库操作和设计至关重要。
2.1.1 数据表、记录和字段的理解
数据表(Table)是关系型数据库中用于存储数据的基本单位,它由行(Row)和列(Column)组成,通常也被称为记录(Record)和字段(Field)。每行代表一条数据记录,而每列则代表了记录中的一个字段,字段定义了数据类型和可接受值的范围。
一个简单的例子如下:
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
BirthDate DATE,
Email VARCHAR(100)
);
在这个例子中, Employees 是数据表的名称,包含了多条记录,每个记录包含五个字段: EmployeeID 、 FirstName 、 LastName 、 BirthDate 和 Email 。
2.1.2 关键字与约束的定义和作用
关键字(如主键 Primary Key, 外键 Foreign Key, 唯一键 Unique Key 等)是用于确保数据完整性和表之间关系的工具。约束(如 NOT NULL, CHECK 等)确保了数据符合业务规则和要求。
- 主键(Primary Key):唯一标识表中的每条记录,不允许重复且必须有值。
- 外键(Foreign Key):用于建立表之间的引用关系,一个表的外键字段值必须是另一表主键字段的值。
- 唯一键(Unique Key):确保字段值的唯一性,但允许为空。
逻辑分析: 主键是识别每条记录的唯一性标识,确保了数据的唯一性和表内记录的唯一性。例如,在用户表中,每个用户都有一个唯一的ID作为主键。 外键是关系型数据库设计中的重要概念,主要用于表与表之间的关联。例如,订单表中的"用户ID"可能作为外键关联到用户表的主键。 唯一键保证了某一字段值的唯一性,但与主键不同,唯一键允许空值,也就是说,它不要求该字段在每条记录中都有值。
2.2 关系型数据库的体系结构
关系型数据库遵循客户端与服务器模型,以存储引擎为支持,确保数据的稳定存储、有效管理和高效访问。
2.2.1 客户端与服务器模型
客户端与服务器模型是关系型数据库最典型的应用架构。客户端发送请求到服务器,服务器处理请求,并将结果返回给客户端。
在实际的数据库操作中,客户端可以是命令行工具、图形用户界面、编程语言的数据库接口等。服务器则是数据库管理系统(DBMS),负责管理所有的数据库操作。
2.2.2 存储引擎的作用和选择
存储引擎负责存储、检索和管理数据库中的数据。它影响数据库的性能、稳定性和特点。
不同的数据库系统提供了不同的存储引擎,比如:
- MySQL的InnoDB和MyISAM
- PostgreSQL的B-tree和Gin
选择合适的存储引擎,需要根据应用的需求进行权衡,例如:
- 如果需要事务支持,InnoDB是更好的选择。
- 如果重视读写性能,MyISAM可能更合适。
2.3 关系型数据库的实际应用场景
关系型数据库因其强大的数据操作和事务管理能力,在多个领域有着广泛的应用。
2.3.1 商业智能与数据仓库
商业智能(BI)利用数据仓库中的数据,帮助企业分析历史数据,从而支持决策过程。
数据仓库的特点是面向主题、集成、相对稳定和时间变化的,它能处理大量的历史数据。
2.3.2 大数据处理与实时分析
关系型数据库在大数据处理和实时分析方面也有所应用。虽然非关系型数据库(NoSQL)在大数据场景中逐渐崭露头角,但许多公司仍然使用关系型数据库来处理实时数据。
以Hadoop与关系型数据库的集成为例,可以实现数据的存储和分析,即先将数据存储在Hadoop中,然后利用SQL对这些数据进行查询和分析。
通过以上这些应用实例,我们可以看出关系型数据库的多样性和在数据管理领域的广泛应用。在下一章节中,我们会深入探讨SQL语言的操作和应用,以及如何优化SQL查询以提升性能。
3. SQL语言的操作和应用
3.1 SQL语言基础
3.1.1 SQL语言的语法结构
SQL(Structured Query Language)是用于存储、检索和操作关系型数据库的标准编程语言。其基本语法结构包括数据定义语言(DDL)、数据操纵语言(DML)和数据控制语言(DCL)。DDL用于定义和修改数据库结构,如创建表、视图、索引等;DML用于执行基本数据操作,如查询、插入、更新和删除数据;DCL则用于设置数据库用户权限。
-- 示例:创建一个名为 "users" 的表
CREATE TABLE users (
id INT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
在上述示例中, CREATE TABLE 是DDL命令,用于创建新表。表中包含了四个字段: id 作为主键, username 和 email 作为普通字段,以及 created_at 字段,后者在插入新记录时会自动设置当前时间戳。
3.1.2 常用的DDL、DML和DCL命令
DDL 命令除了 CREATE ,还包括 ALTER (修改表结构)、 DROP (删除表)、 TRUNCATE (删除所有表数据)等。DML 命令包括 SELECT (查询数据)、 INSERT (插入数据)、 UPDATE (更新数据)和 DELETE (删除数据)。DCL 命令主要是用于权限管理,如 GRANT (授权)和 REVOKE (撤销权限)。
-- 示例:向 "users" 表插入一条新记录
INSERT INTO users (username, email) VALUES ('johndoe', 'john@example.com');
-- 示例:更新 "users" 表中 id 为 1 的记录的 email 字段
UPDATE users SET email = 'new_john@example.com' WHERE id = 1;
-- 示例:删除 "users" 表中所有记录
DELETE FROM users;
-- 示例:授予权限给用户 'johndoe'
GRANT SELECT, INSERT ON database_name.* TO 'johndoe'@'localhost';
上述的 INSERT 、 UPDATE 、 DELETE 命令演示了如何使用DML进行数据的基本操作。这些命令中的条件语句(如 WHERE )对于指定操作的准确性和效率至关重要。
3.2 SQL高级操作
3.2.1 联合查询与子查询技巧
联合查询(JOIN)允许从两个或更多的表中查询数据。SQL 中有多种类型的JOIN,包括内连接(INNER JOIN)、左连接(LEFT JOIN)、右连接(RIGHT JOIN)和全外连接(FULL OUTER JOIN)。联合查询是复杂查询的基础,可以将不同表中相关联的数据组合在一起。
子查询是指一个查询嵌套在另一个查询内部,通常作为条件表达式或用于返回单个值。在某些情况下,子查询可以优化为JOIN查询,提高执行效率。
-- 示例:使用内连接查询两个表中的数据
SELECT orders.order_id, customers.name
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id;
-- 示例:使用子查询选择价格高于平均值的商品
SELECT product_id, product_name, price
FROM products
WHERE price > (SELECT AVG(price) FROM products);
在内连接的示例中,通过在 ON 子句中指定的连接条件,将 orders 表和 customers 表联合起来。子查询示例中,内部的SELECT语句计算所有产品的平均价格,外部查询则选出价格高于平均值的产品。
3.2.2 视图、索引和触发器的使用
视图(View)是虚拟表,基于SQL语句的结果集。它们使得复杂的SQL操作容易重复使用,并提供了一定程度的数据抽象。
索引是用于快速查找表中特定记录的数据结构。索引能够显著提高查询的速度,但也需要额外的空间和维护成本。
触发器(Trigger)是数据库中自动执行的存储过程,它会在满足特定条件时被触发。触发器常用于强制实体完整性规则、记录日志等任务。
-- 示例:创建一个视图
CREATE VIEW product_info AS
SELECT product_id, product_name, price, category_name
FROM products
JOIN categories ON products.category_id = categories.id;
-- 示例:创建一个索引
CREATE INDEX idx_product_price ON products(price);
-- 示例:创建一个触发器
DELIMITER //
CREATE TRIGGER before_product_insert
BEFORE INSERT ON products
FOR EACH ROW
BEGIN
IF NEW.price < 0 THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = 'Product price cannot be negative';
END IF;
END;
DELIMITER ;
视图的示例中,通过 CREATE VIEW 语句定义了一个名为 product_info 的视图,它将 products 表和 categories 表连接起来,为用户提供了简化的产品信息。索引示例中,通过 CREATE INDEX 语句为 products 表中的 price 字段创建了索引。触发器示例中,定义了一个在向 products 表插入数据前执行的触发器,确保了产品的价格不为负数。
4. 数据库设计流程及规范化
在数据库管理系统的设计与实施中,设计流程及规范化是确保数据一致性和高效访问的关键步骤。本章将详细介绍数据库设计的基本步骤,包括需求分析、概念设计、逻辑设计和物理设计,以及规范化理论的应用和反规范化策略的考量。
4.1 数据库设计的基本步骤
设计一个数据库首先需要明确需求,然后根据需求进行概念设计,最终通过逻辑和物理设计将需求转化为可实现的数据库结构。
4.1.1 需求分析与概念设计
在需求分析阶段,数据库设计者需要与相关业务部门紧密沟通,获取业务需求,包括数据的输入、存储、处理和输出。需求分析的结果将直接影响数据库的设计目标和约束条件。需求分析后的概念设计阶段涉及创建一个概念模型,这个模型反映了实体及其之间的关系,常用的模型化工具包括实体-关系图(ER图)。
erDiagram
CUSTOMER ||--o{ ORDER : places
CUSTOMER {
string name
string email
}
ORDER ||--|{ LINE-ITEM : contains
ORDER {
int order-id
string order-date
}
LINE-ITEM {
string part-number
int quantity
float price
}
上述示例展示了顾客、订单和订单项之间关系的ER图,其中顾客下单,一个订单包含多个订单项。
4.1.2 逻辑设计与物理设计
概念模型确定之后,接下来的步骤是逻辑设计,将概念模型转化为具体的数据库逻辑结构,如表、视图、索引等。此时需考虑规范化理论,确保数据的合理组织,避免数据冗余和更新异常。
最后是物理设计阶段,根据特定的数据库管理系统(DBMS)进行数据库结构的物理实现。这包括选择合适的存储引擎、定义存储参数、以及考虑索引策略等。此阶段设计的结果是生成具体的数据库创建脚本,用来在DBMS中建立数据库。
4.2 数据库规范化理论
规范化是数据库设计中的一个核心概念,目的在于减少数据冗余、提高数据一致性。
4.2.1 函数依赖与规范化过程
规范化过程依赖于函数依赖理论,函数依赖描述了在关系表中属性间的依赖关系。规范化的目标是将一个大的、包含多个数据项的表分解为多个小表,每个表都聚焦于一个主题,从而达到减少数据冗余和提高数据完整性的目的。
常用的规范化级别包括第一范式(1NF)、第二范式(2NF)、第三范式(3NF)和巴斯-科德范式(BCNF)。每一级范式都是在前一级的基础上增加了一些新的要求。
例如,第三范式(3NF)要求表中的所有非主键字段都必须直接依赖于主键,而不是依赖于其他的非主键字段。通过达到这些级别的规范化,可以确保数据表不会产生插入、更新和删除异常。
4.2.2 规范化程度对数据库性能的影响
虽然规范化有助于避免数据冗余,但过度规范化可能会对数据库性能产生负面影响。这是因为规范化增加了表之间的关联查询操作,这可能会影响查询速度。因此,在设计数据库时,应根据实际情况找到规范化与性能之间的平衡点。
4.3 反规范化策略与应用
反规范化是规范化设计的对立面,目的是为了优化查询性能而故意引入数据冗余。
4.3.1 反规范化的必要性和应用场景
在一些特定的场景下,如报表生成、数据分析等对性能要求极高的场合,可能需要采用反规范化策略。反规范化策略包括合并表、添加冗余列、创建汇总表等,这些操作可减少连接操作,从而提升查询性能。
4.3.2 反规范化方法和性能权衡
反规范化虽然能够提升查询性能,但也带来了数据一致性和维护上的挑战。在实施反规范化时,数据库设计师需要仔细权衡利弊,可以通过实施部分反规范化、视图、触发器等来最小化反规范化带来的负面影响。
总之,在数据库设计中,规范化和反规范化是需要综合考虑的两个方面。设计者应根据系统的实际需求和运行环境,灵活运用这两种技术,确保数据库既能保持高效的数据操作,又能满足业务的特定需求。
5. 数据查询与数据操作方法
5.1 高效的数据查询技巧
在数据库管理中,数据查询是最为常见的操作之一。正确的使用索引可以显著提高查询效率,减少查询所需的时间。索引优化的关键在于理解查询语句的执行计划,并合理地为表创建和管理索引。
索引优化与查询性能
索引优化的第一步是确定哪些字段需要建立索引。通常,这些字段是经常用于WHERE子句或者JOIN操作的列。接下来,考虑索引类型的选择,例如单列索引、复合索引等,以及是否使用唯一索引。
-- 创建单列索引
CREATE INDEX idx_column ON table_name (column_name);
-- 创建复合索引
CREATE INDEX idx_column1_column2 ON table_name (column1, column2);
执行计划分析是优化查询的另一个重要工具。例如,通过EXPLAIN命令分析MySQL的查询执行计划:
EXPLAIN SELECT * FROM table_name WHERE column_name = 'value';
通过分析执行计划,我们可以了解查询优化器是否使用了我们创建的索引,以及如何优化查询。
复杂查询案例分析
对于包含多个表的复杂查询,理解如何使用JOIN操作是关键。同时,合理使用子查询和联合查询可以帮助我们构建更复杂的查询逻辑。
-- 使用JOIN进行复杂查询
SELECT a.*, b.*
FROM table_a a
JOIN table_b b ON a.key = b.foreign_key
WHERE a.column = 'value';
在执行复杂查询时,要确保每个被连接的表都有适当的索引,这样可以提高连接的效率。
5.2 数据的增删改操作
在数据库中,数据的增加、删除和修改是基础且必要的操作,它们直接影响数据的完整性和准确性。
INSERT、UPDATE、DELETE语句的使用
使用INSERT语句向表中添加新数据是最直接的操作之一:
-- 插入数据
INSERT INTO table_name (column1, column2) VALUES (value1, value2);
更新数据时使用UPDATE语句:
-- 更新数据
UPDATE table_name
SET column1 = value1, column2 = value2
WHERE condition;
而删除数据则使用DELETE语句:
-- 删除数据
DELETE FROM table_name WHERE condition;
在编写这些语句时,要特别注意WHERE子句的条件,以防止错误地修改或删除了不应该改变的数据。
批量数据处理与事务控制
对于批量数据的处理,使用事务可以保证数据操作的原子性、一致性、隔离性和持久性。在MySQL中,可以通过BEGIN, COMMIT, ROLLBACK来控制事务:
-- 开始事务
BEGIN;
-- 执行数据操作...
-- ...
-- 提交事务
COMMIT;
-- 或者在出现错误时回滚事务
ROLLBACK;
事务控制对于维护数据的一致性至关重要,尤其是在多用户同时操作数据时。
5.3 高级数据操作技术
高级数据操作技术如存储过程和触发器,为数据库操作提供了更多的控制力和灵活性。
存储过程和函数的创建与应用
存储过程是一组为了完成特定功能的SQL语句集合,可以通过名称被直接调用。它们通常用于执行复杂的业务逻辑:
-- 创建存储过程
DELIMITER //
CREATE PROCEDURE proc_name()
BEGIN
-- SQL statements
END //
DELIMITER ;
存储函数类似于存储过程,但它们返回一个值,并且必须有一个返回类型:
-- 创建存储函数
DELIMITER //
CREATE FUNCTION func_name() RETURNS type
BEGIN
-- SQL statements
RETURN value;
END //
DELIMITER ;
触发器在数据完整性维护中的作用
触发器是一种特殊类型的存储过程,它会在对表进行INSERT、UPDATE或DELETE操作之前或之后自动执行。它们用于强制数据完整性约束:
-- 创建触发器
DELIMITER //
CREATE TRIGGER trigger_name BEFORE/AFTER INSERT ON table_name
FOR EACH ROW
BEGIN
-- Trigger logic
END //
DELIMITER ;
通过使用触发器,可以在数据被修改时自动检查和处理数据,这样可以减少应用层的负担,同时保证数据的一致性。
简介:数据库是应用程序数据支撑的基础工具,涉及基本概念、不同类型、SQL语言使用、数据库设计、数据查询与操作、事务处理以及安全性和备份策略的全面解析。本文详细探讨了数据库系统的选择、SQL的熟练应用、数据库模式的有效设计、数据的有效查询和操作方法、事务处理的ACID原则,以及保障数据库安全和数据备份的必要措施。为IT专业人员提供了数据库使用和管理的实用指南。

















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









