






 本文深入探讨MySQL性能优化的关键技术和实践方法,通过实例讲解如何利用慢查询日志、性能剖析工具等手段诊断并解决数据库性能瓶颈,提升系统整体效能。
本文深入探讨MySQL性能优化的关键技术和实践方法,通过实例讲解如何利用慢查询日志、性能剖析工具等手段诊断并解决数据库性能瓶颈,提升系统整体效能。
前言:
高效读书,一张逻辑图带你读懂、读薄书中重点。
深入学习MySQL系列,解读的目的是为了把书读薄,抽出重点进行梳理、理解、运用。因大量文字很容易让人觉得枯燥无味,为此博主花费一定精力和时间整理输出为逻辑思维图,以便大家学习和参考。
--------------------------------------------------------------------------------------
注:下面文字只是对逻辑思维图的”翻译“,节省时间,只看图即可。
目录
服务器性能剖析思维逻辑图
性能优化简介
最常碰到的三个性能相关的服务端问题是
两个原则
通过性能剖析进行优化
理解性能剖析
对应用程序进行性能剖析
应用性能瓶颈可能的影响因素
一个不错的工具:New Relic
测量PHP应用程序
剖析MySQL查询
剖析服务器负载
剖析单条查询
使用性能剖析
诊断间歇性问题
一些间歇性数据库性能问题的实际案例
单条查询问题还是服务器问题
捕获诊断数据
一个诊断案例
其他剖析工具
总结
基本知识点
服务器性能剖析思维逻辑图
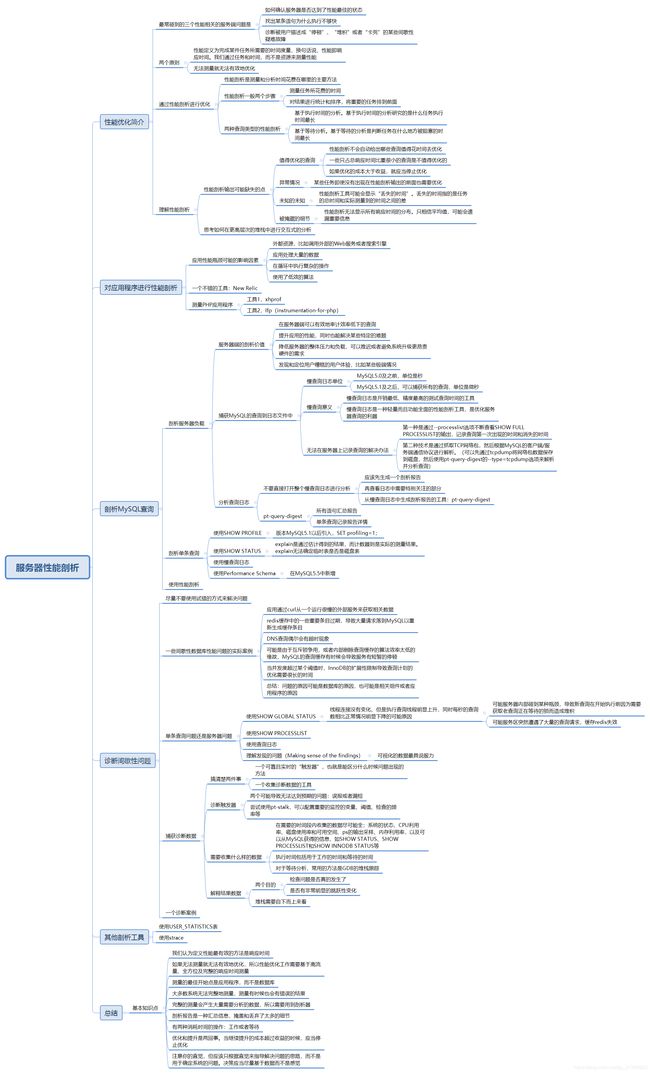 服务器性能剖析思维逻辑图
服务器性能剖析思维逻辑图
性能优化简介
最常碰到的三个性能相关的服务端问题是
如何确认服务器是否达到了性能最佳的状态
找出某条语句为什么执行不够快
诊断被用户描述成“停顿”、“堆积”或者“卡死”的某些间歇性疑难故障
两个原则
性能定义为完成某件任务所需要的时间度量,换句话说,性能即响应时间。我们通过任务和时间,而不是资源来测量性能
无法测量就无法有效地优化
通过性能剖析进行优化
性能剖析是测量和分析时间花费在哪里的主要方法
性能剖析一般两个步骤
测量任务所花费的时间
对结果进行统计和排序,将重要的任务排到前面
两种查询类型的性能剖析
基于执行时间的分析。基于执行时间的分析研究的是什么任务执行时间最长
基于等待分析。基于等待的分析是判断任务在什么地方被阻塞的时间最长
理解性能剖析
性能剖析输出可能缺失的点
值得优化的查询
性能剖析不会自动给出哪些查询值得花时间去优化
一些只占总响应时间比重很小的查询是不值得优化的
如果优化的成本大于收益,就应当停止优化
异常情况
某些任务即使没有出现在性能剖析输出的前面也需要优化
未知的未知
性能剖析工具可能会显示“丢失的时间”。丢失的时间指的是任务的总时间和实际测量到的时间之间的差
被掩藏的细节
性能剖析无法显示所有响应时间的分布。只相信平均值,可能会遗漏重要信息
思考如何在更高层次的堆栈中进行交互式的分析
对应用程序进行性能剖析
应用性能瓶颈可能的影响因素
外都资源,比如调用外部的Web服务或者搜索引擎
应用处理大量的数据
在循环中执行复杂的操作
使用了低效的算法
一个不错的工具:New Relic
测量PHP应用程序
工具1,xhprof
工具2,Ifp(instrumentation-for-php)
剖析MySQL查询
剖析服务器负载
服务器端的剖析价值
在服务器端可以有效地审计效率低下的查询
提升应用的性能,同时也能解决某些特定的难题
降低服务器的整体压力和负载,可以推迟或者避免系统升级更昂贵硬件的需求
发现和定位用户糟糕的用户体验,比如某些极端情况
捕获MySQL的查询到日志文件中
慢查询日志单位
MySQL5.0及之前,单位是秒
MySQL5.1及之后,可以捕获所有的查询,单位是微秒
慢查询意义
慢查询日志是开销最低、精度最高的测试查询时间的工具
慢查询日志是一种轻量而且功能全面的性能剖析工具,是优化服务器查询的利器
无法在服务器上记录查询的解决办法
第一种是通过--processlist选项不断查看SHOW FULL PROCESSLIST的输出,记录查询第一次出现的时间和消失的时间
第二种技术是通过抓取TCP网络包,然后根据MySQL的客户端/服务端通信协议进行解析。(可以先通过tcpdump将网络包数据保存到磁盘,然后使用pt-query-digest的--type=tcpdump选项来解析并分析查询)
分析查询日志
不要直接打开整个慢查询日志进行分析
应该先生成一个剖析报告
再查看日志中需要特别关注的部分
从慢查询日志中生成剖析报告的工具:pt-query-digest
pt-query-digest
所有语句汇总报告
单条查询记录报告详情
剖析单条查询
使用SHOW PROFILE
版本MySQL5.1以后引入,SET profiling=1;
使用SHOW STATUS
explain是通过估计得到的结果,而计数器则是实际的测量结果。explain无法确定临时表是否是磁盘表
使用慢查询日志
使用Performance Schema
在MySQL5.5中新增
使用性能剖析
诊断间歇性问题
尽量不要使用试错的方式来解决问题
一些间歇性数据库性能问题的实际案例
应用通过curl从一个运行很慢的外部服务来获取相关数据
redis缓存中的一些重要条目过期,导致大量请求落到MySQL以重新生成缓存条目
DNS查询偶尔会有超时现象
可能是由于互斥锁争用,或者内部删除查询缓存的算法效率太低的缘故,MySQL的查询缓存有时候会导致服务有短暂的停顿
当并发度超过某个阈值时,InnoDB的扩展性限制导致查询计划的优化需要很长的时间
总结:问题的原因可能是数据库的原因,也可能是相关组件或者应用程序的原因
单条查询问题还是服务器问题
使用SHOW GLOBAL STATUS
线程连接没有变化、但是执行查询线程明显上升,同时每秒的查询数相比正常情况明显下降的可能原因
可能服务器内部碰到某种瓶颈,导致新查询在开始执行前因为需要获取老查询正在等待的锁而造成堆积
可能服务区突然遭遇了大量的查询请求,缓存redis失效
使用SHOW PROCESSLIST
使用查询日志
理解发现的问题(Making sense of the findings)
可视化的数据最具说服力
捕获诊断数据
搞清楚两件事
一个可靠且实时的“触发器”,也就是能区分什么时候问题出现的方法
一个收集诊断数据的工具
诊断触发器
两个可能导致无法达到预期的问题:误报或者漏检
尝试使用pt-stalk,可以配置重要的监控的变量、阈值、检查的频率等
需要收集什么样的数据
在需要的时间段内收集的数据尽可能全;系统的状态、CPU利用率、磁盘使用率和可用空间、ps的输出采样、内存利用率,以及可以从MySQL获得的信息,如SHOW STATUS、SHOW PROCESSLIST和SHOW INNODB STATUS等
执行时间包括用于工作的时间和等待的时间
对于等待分析,常用的方法是GDB的堆栈跟踪
解释结果数据
两个目的
检查问题是否真的发生了
是否有非常明显的跳跃性变化
堆栈需要自下而上来看
一个诊断案例
其他剖析工具
使用USER_STATISTICS表
使用strace
总结
基本知识点
我们认为定义性能最有效的方法是响应时间
如果无法测量就无法有效地优化,所以性能优化工作需要基于高流量、全方位及完整的响应时间测量
测量的最佳开始点是应用程序,而不是数据库
大多数系统无法完整地测量,测量有时候也会有错误的结果
完整的测量会产生大量需要分析的数据,所以需要用到剖析器
剖析报告是一种汇总信息,掩盖和丢弃了太多的细节
有两种消耗时间的操作:工作或者等待
优化和提升是两回事。当继续提升的成本超过收益的时候,应当停止优化
注意你的直觉,但应该只根据直觉来指导解决问题的思路,而不是用于确定系统的问题。决策应当尽量基于数据而不是感觉
以上内容均为博主原创手码梳理。码字不易,但只要能提高,都是值得的。如果您觉得,这篇文章对您的基础知识学习、巩固、提高有帮助,欢迎点赞、分享、收藏,谢谢。 --天天water


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









