




ABSTRACT
This paper reports our experiences with a mostly-concurrent incremental garbage collector, implemented in the context of a high performance virtual machine for the Java TM programming language. The garbage collector is based on the "mostly parallel" collection algorithm of Boehm et al. and can be used as the old generation of a generational memory system. It overloads efficient write-barrier code already generated to support generational garbage collection to also identify objects that were modified during concurrent marking. These objects must be rescanned to ensure that the concurrent marking phase marks all live objects. This algorithm minimises maximum garbage collection pause times, while having only a small impact on the average garbage collection pause time and overall execution time. We support our claims with experimental results, for both a synthetic benchmark and real programs.
本文报告了我们在JVM中使用大部分并发的增量式垃圾回收器的经验。垃圾回收器基于Boehm 的"大部分并行"回收算法。他重载写屏障,以记录并发标记期间的修改。这些对象必须重新扫描以保证标记到所有存活对象。他使得最大的垃圾回收暂停最小化,对平均垃圾回收暂停和总体执行时间只有很小的影响。综合性的基准测试和真实程序的试验结果用来支持我们的声明。
1. INTRODUCTION
Programming languages that rely on garbage collection have existed since the late 1950's [25]. Though the benefits of garbage collection for program simplicity and robustness are well-known and accepted, most software developers have continued to rely on traditional explicit memory management, largely because of performance concerns. Only recently has the wide acceptance of the Java TM programming language [13] allowed garbage collection to enter the mainstream and be used in large systems.
Developers have been skeptical about garbage collection for two reasons: throughput and latency. That is, they fear that collection will either slow down the end-to-end performance of their systems, or induce long collection pauses, or both. Large increases in computing power have not elimied these concerns, since they are typically offset by corresponding increases in memory requirements.
Gnerational garbage collection techniques [21, 26] can address both performance concerns. They split the heap into generations according to object age. Concentrating collection activity on the "young" generation increases throughput, because (in most programs) young objects are more likely to be garbage, so more free space is recovered per unit of collection work. Since the young generation is typically small relative to the total heap size, young-generation collections are usually brief, addressing the latency concern. However, objects that survive a sufficiently large number of young-generation collections are considered long-lived, and are "promoted" into an older generation. Even though the older generation is typically larger, it will eventually be filled and require collection. Old-generation collection has latency and throughput similar to full-heap collection; thus, generational techniques only postpone, but do not solve, the problem.
In this paper we present a garbage collection algorithm that has been designed to serve as the oldest generation of a generational memory system. It attempts to decrease the worst-case garbage collection pause time, while taking advantage of the benefits of a generational system. It is an adaptation of the "mostly parallel" algorithm of Boehm et al. [5]. It usually operates concurrently with the mutator, only occasionally suspending the mutator for short periods.
自从1950年开始就有基于垃圾回收的程序。尽管垃圾回收可以简化程序并增加鲁棒性,但出于性能考虑,大多数开发者还是采用传统的显示内存管理。随着Java语言的广泛接受,垃圾回收开始在大型系统中得到应用。
开发者对垃圾回收有两点怀疑:吞吐量和延迟。他们害怕回收会降低系统的端到端性能或产生长时间暂停。计算能力的大幅增加并未消除这些担忧,因为通常会被相应增加的内存需求抵消。随着硬件技术的发展,处理器的性能不断提高,这意味着应用程序能够处理更多的数据和更复杂的任务。然而,应用程序的内存需求也随之增长。例如,现代应用程序可能会处理更大的数据集、更复杂的对象图,或者同时运行更多的线程。这些因素都会导致堆内存的使用量增加。
分代垃圾回收技术可以处理这两种性能问题。他根据对象年龄将堆分为不同的代。专注与年轻代回收增加了吞吐量,因为年轻代对象可能是垃圾。所有每次能回收更多空间,因为年轻代相对与整个堆很小,年轻代收集很简明,这解决了延迟的问题。然而在多次年轻代回收中幸存下来的对象会被放到老年代。尽管老年代很大,他最终也会被填满,需要回收。老年代回收的代价与全堆回收相似,因此分代技术只是推迟了问题,并没有解决。
本文提出了一个老年代回收算法。他试图减轻在使用分代回收系统时回收暂停时间的最坏情况。是Boehm大部分并行的一个变种。通常与用户线程并发执行,只是偶尔暂停用户线程一小段时间。
端到端性能(End-to-End Performance):端到端性能指的是系统从开始到完成任务所需的总时间。这不仅包括应用程序逻辑的执行时间,还包括诸如垃圾回收等后台任务所花费的时间。开发人员通常担心垃圾回收(GC)可能会引入显著的开销,从而降低应用程序的整体性能。
1.1 A Note on Terminology
In this paper, we call a collector concurrent if it can operate interleaved with the mutator, either truly concurrently, or by working in small increments, i.e., piggy-backed on a frequent operation (such as object allocation). We propose to contrast this with parallel collectors, which accomplish collection using multiple cooperating threads, and can therefore achieve parallel speedups on shared-memory multiprocessors.
It is unfortunate that this terminology clashes with that used by Boehm et al. [5], since they use "parallel" for the concept we have named "concurrent." The choice is arbitrary; a local tradition led to the choice we make, Thus, we use "mostly concurrent" to mean what Boehm et al. termed "mostly' parallel."
如果回收器的操作与用户操作交错执行,我们就称这个回收器是并发的,不论是真正的并发还是在小的增量中工作,即附加到一个频繁的操作(如对象分配)上。我们提出这个概念以与并行回收器区分,并行回收使用多个协作线程,可以在多处理器上获得并行加速。
很不幸这与Boehm的术语冲突,因为他使用parallel而我们使用concurrent。
1.2 Paper Overview
Section 2 briefly describes the platform on which we based our implementation and experiments, and Section 3 describes the original mostly-concurrent algorithm. Our adaptation of this algorithm is described in Section 4, with Section 5 containing the results of the experiments that we undertook in order to evaluate our implementation. Finally, related work on incremental garbage collectors is given in Section 6 and the conclusions and future work in Section 7.
第2章简要描述了我们基于的平台。第3章描述了原始的mostly concurrent算法。第4章描述了我们的改变。第5章是试验结果。第6章是相关工作,第7章是总结和后续工作。
2. EXPERIMENTAL PLATFORM
The Sun Microsystems Laboratories Virtual Machine for Research, henceforth Researeh VM, is a high performance Java virtual machine developed by Sun Mierosystems. This virtual machine has been previously known as the "Exact VM", and has been incorporated into products; for example, the Java TM 2 SDK (1.2.1_05) Production Release, for the Solaris TM operating environment. It employs an optimising just-in-time compiler [8] and a fast synchronisation mecha- nism [2].
More relevantly, it features high-performance exact (i.e., non-conservative [6], also called precise) memory management [1]. The memory system is separated from the rest of the virtual machine by a well-defined GC Interface [27]. This interface allows different garbage collectors to be "plugged in" without requiring changes to the rest of the system. A variety of collectors implementing this interface have been built. In addition to the GC interface, a second layer, called the generational framework, facilitates the implementation of generational garbage collectors [26, 19, 28].
One of the authors learned these interfaces and implemented a garbage collector in a matter of weeks, so there is some evidence that it is relatively easy to implement to the interfaces described above.
我们使用Sun的实验室虚拟机。
更重要的是他提供高性能的精确内存管理,内存系统通过一个明确定义的GC接口与虚拟机的其余部分分隔开来。这个接口允许在不修改系统其他部分的情况下插入不同的垃圾回收器。另外分代框架促进了分代垃圾回收的实现。
一个作者用几个星期实现了这个接口,这表明接口的实现很简单。
3. MOSTLY-CONCURRENT COLLECTION
The original mostly-concurrent algorithm, proposed by Boehm et al. [5], is a concurrent "tricolor" collector [9]. It uses a write barrier to cause updates of fields of heap objects to shade the containing object gray. Its main innovation is that it trades off complete concurrency for better throughput, by allowing root locations (globals, stacks, registers), which are usually updated more frequently than heap locations, to be written without using a barrier to maintain the tricolor invariant. The algorithm suspends the mutator to deal properly with the roots, but usually only for short periods. In more detail, the algorithm is comprised of four phases:
1. Initial marking pause. Suspend all mutators and record all objects directly reachable from the roots (globals, stacks, registers) of the system.
2. Concurrent marking phase. Resume mutator operation. At the same time, initiate a concurrent marking phase, which marks a transitive closure of reachable objects. This closure is not guaranteed to contain all objects reachable at the end of marking, since concurrent updates of reference fields by the mutator may have prevented the marking phase from reaching some live objects.
To deal with this complication, the algorithm also arranges to keep track of updates to reference fields in heap objects. This is the only interaction between the mutator and the collector.
3. Final marking pause. Suspend the mutators once again, and complete the marking phase by marking from the roots, considering modified reference fields in marked objects as additional roots. Since such fields contain the only references that the concurrent marking phase may not have observed, this ensures that the final transitive closure includes all objects reachable at the start of the final marking phase. It may also include some objects that became unreachable after they were marked. These will be collected during the next garbage collection cycle.
4. Concurrent sweeping phase. Resume the mutators once again, and sweep concurrently over the heap, deallocating unmarked objects. Care must be taken not to deallocate newly-allocated objects. This can be accomplished by allocating objects "live" (i.e., marked) at least during this phase.
This description abstracts somewhat from that given by Boehm et al. Tracking individual modified fields is the finest possible tracking granularity; note that this granularity can be coarsened, possibly trading off decreased accuracy for more efficient (or convenient) modification tracking. In fact, Boehm et al. use quite a coarse grain, as discussed in Section 4.2.
The algorithm assumes a low mutation rate of reference-containing fields in heap objects; otherwise, the final marking phase will have to rescan many dirty reference-containing fields, leading to a long, possibly disruptive, pause. Even though some programs will break this assumption, Boehm et al. report that in practice this technique performs well, especially for interactive applications [5].
原始的并发回收算法是并发三色回收。他使用写屏障将被修改字段的对象标记为灰色。主要的创新点是他权衡了(减少了)完全并发以获取更高的吞吐量,这种权衡是通过允许根位置(全局变量,栈变量即线程栈中的局部变量和方法参数,寄存器中存储的变量)不使用写屏障来实现的,因为这些位置的更新很频繁,使用写屏障会显著影响吞吐量。算法会在用户线程暂停时妥善处理这些根位置,占用时间很短,算法被分为4个阶段:
1. 初始标记阶段:暂停所有用户线程,记录根位置的所有直接引用。
2. 并发标记阶段:恢复用户线程。同时开始并发标记阶段,用来标记可达对象的传递闭包。标记结束时,这个闭包不能保证包含所有的可达对象,因为用户线程的并发更新可能会导致有的对象没被标记。
为了处理这种复杂性,算法对堆中对象的更新持续追踪。这是用户线程和回收线程之间唯一的交互。
3. 最终标记阶段:暂停用户线程,完成标记阶段,通过从根标记,把被标记对象中被修改的字段作为新的根。因为这些字段含有并发标记阶段没有被观测到的引用,这保证最终的传递闭包包含所有的可达对象(最终标记阶段开始时的所有可达对象)。他也可能包含一些在被标记后变为不可达的对象,这些对象将会在下次垃圾回收周期中被回收。
4. 并发清理阶段:重启用户线程,并发的清理堆,释放未标记的对象。
这章简单描述了Boehm的论文。追踪单独的被修改的字段是最细粒度的追踪。这种粒度可以粗化来提升效率.Boehm也用了一个粗粒度的在4.2章描述。
算法假设堆中字段的修改率很低,否则最终标记阶段会重新扫描dirty字段,导致很长的暂停。尽管一些程序会打破这种假设,Beohm表示这种技术在实际中表现的很好,特别是交互程序。
3.1 A Concrete Example
一个具体的例子
Figure 1 illustrates the operation of the mostly-concurrent algorithm. In this simple example, the heap contains 7 objects and is split into 4 pages. During the initial marking pause (not illustrated), all 4 pages are marked as clean and object a is marked live, since it is reachable from a thread stack.
Figure la shows the heap halfway through the concurrent marking phase. Objects b, c, and e have been marked. At this point, the mutator performs two updates: object g drops its reference to d, and object b has its reference field, which pointed to c, overwritten with a reference to d. The result of these updates is illustrated in Figure lb. Also note that the updates caused pages 1 and 3 to be dirtied.
Figure lc shows the heap at the end of the concurrent marking phase. Clearly, the marking is incomplete, since a marked object b points to an unmarked object d. This is dealt with during the final marking pause: all marked objects on dirty pages (pages 1 and 3) are rescanned. This causes b to be scanned, and thus object d to be marked. Figure ld shows the state of the heap after the final marking pause, with marking now complete. A concurrent sweeping phase will follow, and will reclaim the unmarked object f.
Objects such as f that are unreachable at the beginning of a garbage collection cycle are guaranteed to be reclaimed. Objects such as c, however, that become unreachable during a collection cycle, are not guaranteed to be collected in that cycle, but will be collected in the next.
图1展示了大部分并发标记算法的操作。在这个例子中堆包含7个对象,被分成4页。初始标记暂停期间(未显示)所有4页都被标记为clean,对象a被标记为存活,因为他是线程栈可达的。
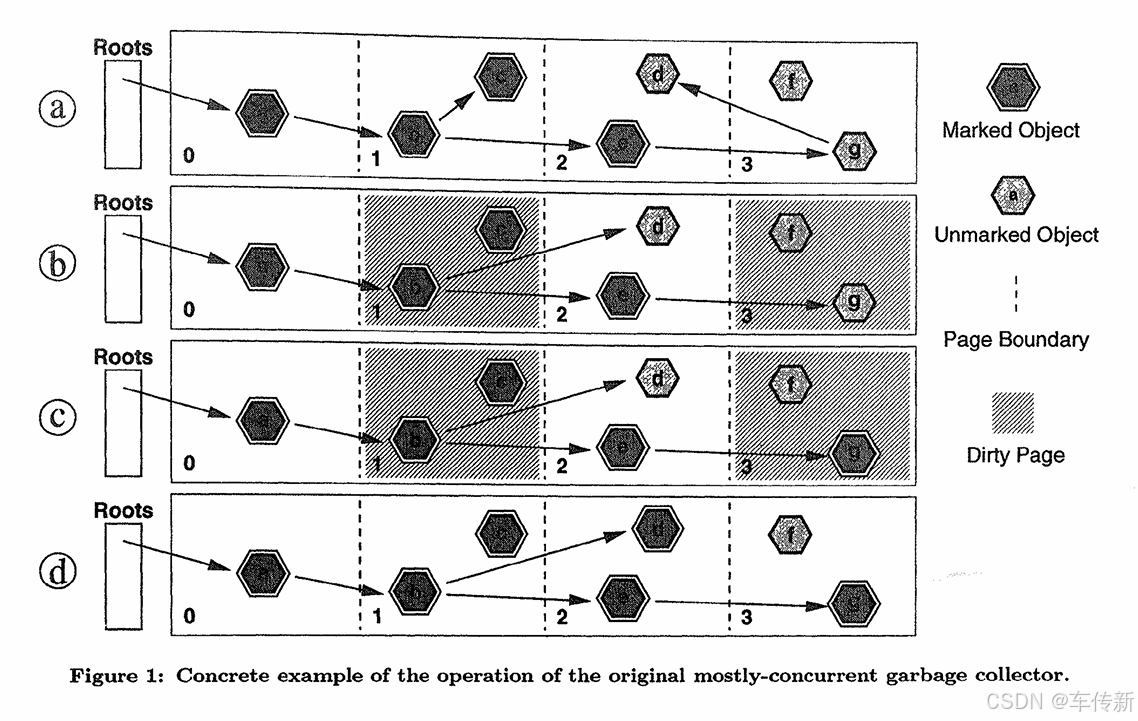
图 1a 显示并发标记阶段的中途。对象b、ce被标记。此时,用户线程执行了两个更新:对象g移除了对d的引用,对象b到c的引用改为到d。其结果在 1b 中显示。更新导致页1和3 dirty。
图 1c 显示并发标记阶段结束时的状态。很明显标记还未完成,d未被标记。这会在最终标记暂停期间被处理:dirty页中所有被标记的对象被重新扫描。这样b被扫描,d从而被标记。1d 显示最终标记暂停后堆的状态,标记现在是完整的。接着是并发清理阶段,将会清理未标记的对象f。
像f这种在回收开始时不可达的对象肯定会被回收。然而,像c这种在回收期间变成不可达的对象则不一定会被回收,但是会在下个回收周期被回收。
4. MOSTLY-CONCURRENT COLLECTION IN A GENERATIONAL SYSTEM
This section describes our generational mostly-concurrent garbage collector in detail, and records some of the decisions we took during its design and implementation. Whenever possible, we also present alternative solutions that might be more appropriate for different systems.
Most aspects of the design are independent of the use of the collector as a generation in the generational framework, and we will describe these first. Later, we will describe complications specific to the use of the collector in a generational context.
这章详细描述分代大部分并发垃圾回收,并且记录我们在设计和实现期间的一些决定。在可能的情况下,我们还提供可能更适用于不同系统的替代解决方案的展示。
设计的大多方面与回收其使用是独立的,这些会先描述,然后我们将会介绍在分代中使用回收器的复杂性。
4.1 The Allocator
The default configuration of the ResearchVM uses an older generation that performs mark-sweep collection, with a compaction pass [19, 28] to enable efficient allocation later. We will refer to this collector implementation as mark-compact. The object relocation implied by compaction requires updating of references to the relocated objects; this reference updating is difficult to perform concurrently. Therefore, mostly-concurrent collection does not attempt relocation. Thus, its allocator uses free lists, segregated by object size, with one free list per size for small objects (up to 100 4-byte words) and one free list per group of sizes for larger objects (these groups were chosen using a FibonaccMike sequence).
It can be argued that a smarter allocator with better speed / fragmentation trade-offs could have been used. In fact, Johnstone and Wilson claim that the segregated free-list allocation policy is one of the policies that cause the worst fragmentation [18]. However, this work assumed explicit "on-line" deallocation, as represented by C's malloc/free interface. It is easier and more efficient to coalesce contiguous free areas to decrease fragmentation in an "off-line" garbage collector with a sweeping phase that iterates over the entire heap.
ResearchVM默认使用带压缩的标记-清除回收器。我们称之为标记-压缩。对象重定位需要更新相关引用。引用更新很难并发处理。因此mostly-concurrent不使用重定位。因此内存分配器使用空闲列表,不同对象尺寸有不同空闲列表。
使用更好权衡速度/碎片化的分配器。隔离的空闲列表策略导致严重的碎片化。
4.2 Using the Card Table
Generational garbage collection requires tracking of references from objects in older generations to objects in younger generations. This is necessary for correctness, since some young-generation objects may be unreachable except through such references. A better scheme than simply traversing the entire older generation is required, since that would make the work of a young-generation collection similar to the work of a collection of the entire heap.
分代回收需要追踪老年代到年轻代的引用。需要找一个更好的方法替代遍历老年代(开销与全堆回收差不多)。
Several schemes for tracking such old-to-young references have been used, with different cost/accuracy tradeoffs. The generational framework of the ResearchVM (see Section 2) uses a card table for this tracking [31, 15, 30]. A card table is an array of values, each entry corresponding to a subregion of the heap called a card. The system is arranged so that each update of a reference field within a heap object by mutator code executes a write barrier that sets the card table entry corresponding to the card containing the reference field to a dirty value. In compiled mutator code, the extra code for card table update can be quite efficient: a two-instruction write barrier proposed by H61zle [14] is used.
ResearchVM的分代框架使用card table来追踪。使用写屏障,将表中有修改的card设置为dirty。卡表更新代码的效率很高(两个指令)。
One of the fundamental decisions of our design is to exploit the happy coincidence that this efficient card-table-based write barrier can be used, almost without modification, to perform the reference update tracking required for mostly-concurrent collection. Thus, using mostly-concurrent collection for the old generation will add no extra mutator overhead beyond that already incurred for the generational write barrier.
我们利用写屏障来追踪引用更新,不需要除此之外其他的开销。
Boehm et al. used virtual memory protection techniques to track pointer updates at virtual memory page granularity: a "dirty" page contains one or more modified reference fields. Using a card-table-based write barrier has several advantages over this approach.
Boehm使用虚拟内存保护技术在页的粒度追踪指针更新。相比之下卡表有以下优点:
• Less overhead. The cost of invoking a custom handler for memory protection traps is quite high in most operating systems. Hosking and Moss [16] found a five-instruction card-marking barrier to be more efficient than a page-protection-based barrier; the two- or three-instruction implementation used in ResearchVM will be more efficient still.
更少的开销,写屏障2、3个指令
• Finer-gralned information. The granularity of a card table can be chosen according to an accuracy/space overhead tradeoff. The "card size" in a virtual memory protection scheme is the page size, which is chosen to optimize properties, such as efficiency of disk transfer, that are completely unconnected with the concerns of garbage collection. Generally, these concerns lead to pages that are larger than optimal for reference update tracking, typically at least 4 Kbytes. In contrast, the card size of ResearchVM is 512 bytes.
粒度更细,card 512 字节
• More accurate type information. The ResearchVM dirties a card only when a field of a reference type on that card is updated. A virtual-memory-based systern cannot distinguish between updates of scalar and reference fields, and thus may dirty more pages than are necessary to track modified pointers. Furthermore, their approach was conservative elsewhere, as well: it assumed all words were potential pointers.
更精确,只在引用字段更新时触发
Hosking, Moss, and Stefanovic [15] present a detailed discussion of the tradeoffs between software and page-protection-based barrier implemcntations. Their basic conclusion is that software mechanisms are more efficient than those using virtual memory protection.
软件写屏障比页保护写屏障更高效
In fairness, we should note that the system of Boehm et al. was attempting to satisfy a further constraint not present in our system: accomplishing garbage collection for uncooperative languages (C and C++) without compiler support. This constraint led to the conservative collection scheme [6] on which the mostly-concurrent extension is based, and also favored the use of the virtual-memory technique for reference update tracking, since this technique required no modification of the mutator code.
公平来讲,Boehm的系统不依赖于编译器。
Adapting the card table for the needs of the generational mostly-concurrent algorithm was straightforward. In fact, as discussed above, the write barrier and card table data structure were left unchanged. However, we took careful note of the fact that the card table is used in subtly different ways by two garbage collection algorithms that may be running simultaneously. The mostly-concurrent algorithm requires tracking of all references updated since the beginning of the current marking phase. Young-generation collection requires identification of all old-to-youn pointers. In the base generational system, a young-generation collection scans all dirty old-space cards, searching for pointers into the young generation. If none are found, there is no need to scan this card in the next collection, so the card is marked as clean. Before a young-generation collection cleans a dirty card, the information that the card has been modified must be recorded for the mostly-concurrent collector.
This is accomplished by adding a new datastructure, the mod union table, shown in Figure 2, which is le-named because it represents the union of the sets of cards modified between each of the young-generation collections that occur during concurrent marking. The card table itself contains a byte per card in the ResearchVM; this allow a fast write barrier implementation using a byte store. The mod-union table, on the other hand, is a bit vector with one bit per card. It therefore adds little space overhealI beyond the card table, and also enables fast traversal to find modified cards when the table is sparsely populated. We maintain an invariant on the mod union and card tables: any card containing a reference modified since the beginning of the current concurrent marking phase either has its bit set in the mod union table, or is marked dirty in the card table, or both. This invariant is maintained by young-generation collections, which set the mod union bits for all cards dirty in the card table before scanning those dirty cards.
unio table在年轻代回收时,扫描一个dirty card前置位。
4.3 Marking Objects
Our concurrent garbage collector uses an array of external mark bits. This bitmap contains one bit for elrery four-byte word in the heap. This use of external mark bits, rather than internal mark bits in object headers, prevenies interference between mutator and collector use of the objdct headers.
回收器使用一个外部标记位数组。该位图1位表示堆中4字节,使用外部标记位而不是对象头的原因是避免用户线程和gc线程对对象头的争抢。
Root scanning presents an interesting design choice, since it is influenced by two competing concerns. As we described in Section 3, the mostly-concurrent algorithm scans roots while the mutator is suspended. Therefore, we would like this process to be as fast as possible. On the other hand, any marking process requires some representation of the set of objects that have been marked but not yet scanned (henceforth the to-be-scanned set). Often this set is represented using some data structure external to the heap, such as a stack or queue. A strategy that minimizes stop-the-world time is simply to put all objects reachable from the roots in this external data structure. However, since garbage collection is intended to recover memory when that is a scarce resource, the sizes of such external data structures are always important concerns. Since the Java language is multithreaded, the root set may include the registers and stack frames of many threads. In our generational system, objects in generations other than the one being collected are also considered roots. So the root set may indeed be quite large, arguing against this simple strategy.
根扫描要考虑两方面,1. 尽可能快以减少用户线程暂停.2. 所有标记过程都需要一个存放待扫描对象的数据结构,为了减少stw暂停时间,一个简单的策略是把根可达的所有对象放到这个数据结构中。但root set很大时不可行。
An alternative strategy that minimizes space cost is one that marks all objects reachable from a root immediately on considering the root. Many objects may be reachable from roots, but we place such objects in the to-be-scanned set one at a time, minimising the space needed in this data structure (because of roots) at any given time. While suitable for non-concurrent collection, this strategy is incompatible with the mostly-concurrent algorithm, since it accomplishes all marking as part of the root scan.
一个可以节省空间的替代方法是当扫描到一个根时立刻把这个根所有的可达对象都标记上。我们一次放1个对象到待扫描集中,这样就节省了空间。但是不适用与并发标记算法,因为他在根扫描时完成标记。
We use a compromise between these two approaches. The compromise takes advantage of the use of an external marking bitmap. The root scan simply marks objects directly reachable from the roots. This minimizes the duration of the stop-the-world root scan, and imposes no additional space cost, by using the mark bit vector to represent the to-be-scanned set. The concurrent marking phase, then, consists of a linear traversal of the generation, searching the mark bit vector for live objects. (This process has cost proportional to the heap size rather than amount of live data, but the overall algorithm already has that complexity because of the sweeping phase). For every live object cur found, we push cur on a to-be-scanned stack, and then enter a loop that pops objects from this stack and scans their references, until the stack is empty. The scanning process for a reference value ref (into the mostly-concurrent generation) works as follows:
我们采用一个折中,根扫描时只标记根直接引用的对象。这样即减少了stw时间,同时因为使用位图而没有占用额外空间。并发标记阶段会线性遍历堆中的代,通过扫描标记位寻找存活对象(该过程与堆大小成比例),对于每一个找到的存活对象cur,把cur放到待扫描栈,然后不断弹出对象并扫描其引用,直到栈为空。扫描过程如下:
• if ref points ahead of cur, the corresponding object is simply marked, without being pushed on the stack; it will be visited later in the linear traversal.
如果引用指针在cur前面,相应的对象被标记,不用推到栈中,因为他会在后续的线性遍历中被访问。
• if ref points behind cur, the corresponding object is both marked and pushed on the stack.
如果引用指针在cur后面,相应的对象被标记,并且被推到栈中。
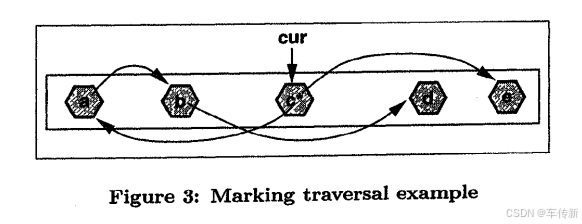
Figure 3 illustrates this process. The marking traversal has just discovered a marked object c, whose address becomes the value of cur. Scanning c finds two outgoing references, to a and e. Object e is simply marked, since its address follows cur. Object a is before cur, so it is both marked and scanned. This leads to b, which is also before cur, so it too is marked and scanned. Object b's reference to d, however, only causes d to be marked, since it follows cur, and will therefore be scanned later in the traversal.
图3显示了这一过程,线性遍历刚发现一个被标记的对象c,cur的值变成c,扫描c时发现两个引用a和e。e只是被标记,因为他在cur后面。a被标记并推入标记栈等待扫描。这会扫描到b,在cur前,b被标记并入栈,b有到d的引用,由于d在curl后面,因此d只是被标记,将会在线性遍历的后续被扫描。
This technique reduces demand on the to-be-scanned stack since no more than one object directly reachable from the root set is ever on the stack. A potential disadvantage of this approach is the linear traversal searching for live objects, which makes the algorithmic complexity of marking contain a component proportional to the size of the generation, rather than just the number of nodes and edges in the pointer graph. This is a practical difficulty only if the cost of searching for marked objects outweighs the cost of scanning them if when found, which will occur only if live objects are sparse. Note that if live objects are sparse, the use of a bitmap allows large regions without live objects to be skipped efficiently, by detecting zero words in the bit vector. A similar technique was used by Printezis [23] in the context of a disk garbage collector.
没有一个根直接可达对象被放到栈中。潜在的缺点是全堆线性扫描。存活对象稀疏的情况下,搜索对象的成本高于扫描对象的成本。对象稀疏的话可以跳过位图中的0字来跳过大的空区域。
4.4 The Sweeping Phase
When the concurrent marking phase is complete, a sweeping process must identify all objects that are not marked as reachable, and return their storage to the pool of available storage. The allocation process will often "split" a free block, creating an allocated block and a remaining free block, both smaller than the original free block. Therefore, to prevent the average block size from continuously decreasing, the sweeping process must also perform some form of coalescing, that is, combination of consecutive free chunks into one larger free chunk.
并发标记完成后,清理过程要识别未标记对象并回收空间。分配过程会产生碎片,清理时要合并连续的空闲空间。
In a non-concurrent free-list-based collector, sweeping and coalescing are most easily accomplished by throwing away the existing free lists and reconstructing them "from scratch" during the sweeping process. This will not work, however, in a concurrent collector, which must be prepared to satisfy allocation requests during sweeping.
在非并发空闲列表回收器中,清理和合并简单的从头构建空闲列表。这在并发清理中不可行。
Concurrent allocation complicates sweeping in two ways. First, a mutator thread could be attempting to allocate from a free list while the sweeping process is attempting to add to that free list. This contention is handled fairly easily with mutual exclusion locks. More subtly, the sweeping process could also be competing with mutator threads to remove blocks from free lists. Consider a situation where blocks a, b, and c are contiguous. Block b is on a free list; blocks a and c had been allocated to contain objects, but both have been found to be unreachable. We wish to put the coalesced block abc onto a free list. To do so, however, we must first remove block b from its free list, or else we risk that storage being allocated for two purposes.
并发分配有两种方式:1. 用户线程从一个空闲列表中分配,清理线程并发的向这个空闲列表添加或移除。
Mutual exclusion locks can still manage this competition. However, note that this scenario places a new requirement on the free list data structures of the heap: we must be able to delete an arbitrary block from its free list. Allocation removes objects from free lists, but only at the heads of the lists. While singly-linked free lists are efficient when free blocks are deleted only from the head, deletion of arbitrary blocks favors doubly-linked free lists, which allow this operation to be done in constant, rather than linear, time. Note that this adds no space overhead, since the same memory is used to contain object information when a block is allocated and free-list links when it is not.
移除需要双向链表保证O(1)时间,可以使用block的对象空间存放链表指针,从而不会产生多余空间开销。
4.5 The Garbage Collector Thread
Our system uses a dedicated garbage collection thread. This approach allows us to take advantage of multiple CPUs. For example, a single-threaded program can run on a dual processor machine and have most garbage collection work accomplished on the second processor. Similarly, collection activity can proceed while the mutator is inactive, for example, while performing I/O. In contrast, Boehm etal. perform collection functions incrementally, "piggy-backed" on frequent operations performed by mutator threads, such as object allocation. We believe this approach was chosen to increase portability.
我们的系统使用一个单独的垃圾回收线程。相反的Boehm使用增量式方法将回收操作附加到频繁的用户操作上(为了可移植性),如对象分配。
We also decided to label the garbage collector thread as a "fake" mutator thread, which means that it is suspended during young-generation collections. This has two advantages: it does not slow down young-generation collections, which need to be fast, and it minimises any synchronisation with the rest of the system (see Section 4.8).
我们把gc线程叫做fake用户线程。其在年轻代回收时被暂停。
4.6 Interaction with Young-Generation Collection
There are some ways in which our mostly-concurrent collector has been optimized or modified to work as the older generation in a generational collector. First, we recognize that, for most programs, a large majority of allocation in the older generation will be done via promotion from the young generation. (The remainder is "direct" allocation by the mutator in the older generation, which usually occurs only for objects too large to be allocated in the young generation). Promotion occurs while mutator threads and the concurrent garbage collector thread are suspended, which simplities matters. We take advantage of this simplification by supporting a linear allocation mode during young-generation collection. Linear allocation can be considerably faster than free-list-based allocation (especially when doubly-linked free lists are used), since fewer pointers are compared and modified. When linear allocation mode is in force, we maintain linear allocation for small allocation requests as long as there exist sufficiently large free chunks from which to allocate. This significantly speeds up allocation for promotion, which can be a major component of the cost of young-generation collection.
大部分老年代是又年轻代晋升而来,其余直接分配一般是对象太大以至于年轻代无法分配。晋升在用户线程和并发回收线程暂停时,晋升需要将对象从年轻代移动到老年代。线性分配加速了这一过程。
这句话解释了为什么**线性分配(Linear Allocation)**比基于空闲链表(Free-List-Based Allocation)的分配方式更快,尤其是当使用双向链表(Doubly-Linked Free Lists)时。为了更好地理解这句话,我们需要先了解线性分配和空闲链表分配的基本概念及其性能特点。
线性分配(Linear Allocation)
线性分配是一种简单的内存分配策略,其核心思想是维护一个指针(通常称为
alloc_ptr或free指针),指向当前可用内存的起始位置。每次分配对象时,只需将该指针向前移动对象的大小,即可完成分配。工作原理
分配过程:
当需要分配一个大小为
n字节的对象时,分配器检查当前的alloc_ptr指针和limit指针(表示分配上下文的边界)。如果
alloc_ptr + n不超过limit,则将alloc_ptr向前移动n字节,返回alloc_ptr作为新对象的起始地址。如果
alloc_ptr + n超过limit,则表示当前分配上下文没有足够的空间,需要分配新的内存块。内存块分配:
如果当前分配上下文空间不足,分配器会分配一个新的内存块(例如32KB),并将
alloc_ptr和limit指针更新到新块的起始和结束位置。如果要分配的对象大于预设的块大小(如32KB),则直接分配一个精确大小的内存块。
优点
高效性:线性分配非常快速,因为它避免了复杂的内存管理操作,只需简单地移动指针即可完成分配。
局部性优化:由于对象是连续分配的,因此具有较好的空间局部性,有助于提高缓存利用率。
基于空闲链表的分配(Free-List-Based Allocation)
基于空闲链表的分配是一种更复杂的内存分配策略,其核心思想是维护一个链表,链表中的每个节点代表一个空闲内存块。每次分配对象时,分配器会从链表中查找一个足够大的空闲块,并将其分割成所需大小的对象和剩余的空闲块。
工作原理
分配过程:
当需要分配一个大小为
n字节的对象时,分配器会遍历空闲链表,查找一个足够大的空闲块。如果找到一个足够大的空闲块,分配器会将该空闲块分割成所需大小的对象和剩余的空闲块,并更新空闲链表。
如果没有找到足够大的空闲块,分配器会分配一个新的内存块,并将其添加到空闲链表中。
内存块分配:
每次分配对象时,分配器需要维护空闲链表的完整性,这涉及到多个指针的比较和修改。
优点
灵活性:空闲链表分配可以处理不同大小的内存块,适用于对象大小不一的场景。
内存利用率:通过分割和合并空闲块,可以减少内存碎片化,提高内存利用率。
缺点
复杂性:空闲链表分配需要维护链表的完整性,涉及到多个指针的比较和修改,因此比线性分配更复杂。
性能开销:每次分配对象时,需要遍历空闲链表,查找合适大小的空闲块,这增加了分配的开销。
为什么线性分配更快
线性分配比基于空闲链表的分配更快,原因如下:
指针操作简单:线性分配只需简单地移动一个指针即可完成分配,不需要复杂的链表操作。
减少指针比较和修改:线性分配不需要遍历空闲链表,也不需要维护链表的完整性,因此减少了指针的比较和修改操作。
局部性优化:线性分配的对象是连续分配的,具有较好的空间局部性,有助于提高缓存利用率。
总结
线性分配是一种简单高效的内存分配策略,特别适用于对象分配频繁且对性能要求较高的场景。它通过维护一个指针来管理内存分配,具有快速分配和良好的空间局部性特点。相比之下,基于空闲链表的分配虽然更灵活,但涉及到更多的指针操作,因此在性能上不如线性分配高效。
In the default configuration of the ResearchVM, the use of a compacting older generation simplifies the implementation of one function required for young-generation collection. One of the most elegant aspects of Cheney-style copying collection [7] is that the set of objects still to be scanned are contiguous. In a generational system, where some from-space objects may be copied to to-space and others may be promoted to the older generation, the promoted objects are also part of the to-be-scanned set. When the older generation uses compaction, and thus linear allocation, the set of promoted-but-not-yet-scanned objects is contiguous. However, in a non-compacting collector, the promoted objects may not be contiguous. This complicates the problem of locating them so that they may be scanned.
使用紧缩老年代简化了年轻代垃圾回收的一个功能。复制回收最优雅的一方面是待扫描对象集是连续的。非压缩回收器中晋升对象不连续,这使得定位他们很困难。
We solve this problem by representing the set of promoted-but-unscanned objects with a linked list. Every promoted object was promoted from the current from-space of the young generation, and the from-space version of the object contains a forwarding pointer to the object's new address in the older generation. These from-space copies of the promoted objects are used as the "nodes" of the linked list. The forwarding pointer indicates the element of the set, and a subsequent header word is used as a "next" field.
我们把promoted-but-unscanned对象放到一个单独链表。

















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









