




 本文全面介绍了SQL的基本概念,包括SQL的定义、通用语法、注释、分类及其应用。深入讲解了DDL、DML、DQL、DCL的具体操作,涵盖了数据库和表的创建、查询、修改、删除等操作。同时,探讨了数据类型、聚合函数、约束、多表关系和查询,以及事务处理等关键主题。
本文全面介绍了SQL的基本概念,包括SQL的定义、通用语法、注释、分类及其应用。深入讲解了DDL、DML、DQL、DCL的具体操作,涵盖了数据库和表的创建、查询、修改、删除等操作。同时,探讨了数据类型、聚合函数、约束、多表关系和查询,以及事务处理等关键主题。
SQL
1,什么是SQL?
Structured Query Language:结构化查询语言
就是定义了操作所有关系型数据库的规则。每一种数据库操作的方式存在不一样的地方,称为“方言”。
2,SQL通用语法:
- SQL语句可以单行或多行书写,以分号结尾。
- 可使用空格和缩进来增强语句的可读性
- MySQL数据库的SQL语句不区分大小写,关键字建议使用大写
- 3种注释
- 单行注释:-- 注释内容 或 # 注释内容(mysql特有)
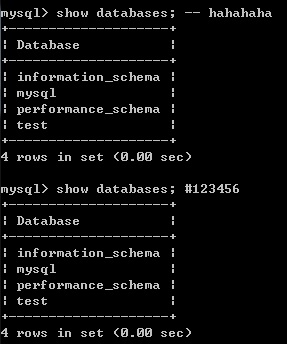
- 多行注释:/* 注释 */
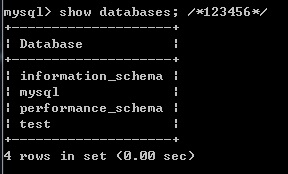
- 多行注释:/* 注释 */
- 单行注释:-- 注释内容 或 # 注释内容(mysql特有)
3,SQL分类
- ① DDL(Data Definition Language)数据定义语言
- 用来定义数据库对象:数据库、表、列等。关键字:create,drop,alter等
- ② DML(Data Manipulation Language)数据操作语言
- 用来对数据库中表的数据进行增删改。关键字:insert,delete,update等
- ③ DQL(Data Query Language)数据查询语言
- 用来查询数据库中表的记录(数据)。关键字:select,where等
- ④ DCL(Data Control Language)数据控制语言
- 用来定义数据库的访问权限和安全级别,及创建用户。关键字:GRANT,REVOKE 等
DDL:操作数据库、表
1,操作数据库:CURD
- C(Create):创建
- create database 想要创建的数据库名;
- create database if not exists 数据库名;(先判断该数据库是否存在,存在则跳过,不存在则建立)
- create database 数据库名 character set gbk;(指定字符编码创建数据库)
- create database if not exusts 数据库名 character set gbk;
- R(Retrieve):查询
- 查询所有数据库的名称
- show databases;
- 查询某个数据库的字符集:查看某个数据库的创建语句
- show create database 数据库的名称;

- 查询所有数据库的名称
- U(Update):修改
- alter database 数据库名称 character set 字符集名称;
- D(Delete):删除
- drop database 数据库名称;
- drop database if exists 数据库名称;(判断数据库是否存在,存在删除)
- 使用数据库
- 查询当前正在使用的数据库名称
- select database();
- 使用数据库
- use 数据库名称;
- 查询当前正在使用的数据库名称
2,操作表
-
C(Create):创建
- 语法
- create table 表名(
列名1 数据类型1,
列名2 数据类型2,
…
列名n 数据类型n
); - 注意:最后一列,不需要加逗号。
- 数据库类型(常用)
- 1,int:整数类型
- age int,
- 2,double:小数类型
- score double(5,2),
- 3,date:日期,只包含年月日,yyyy-MM-dd
- 4,datetime:日期,包含年月日时分秒,yyyy-MM-dd HH:mm:ss
- 5,timestamp:时间戳类型,包含年月日时分秒,yyyy-MM-dd HH:mm:ss
- 如果将来不给这个字段赋值,或赋值为null,则默认使用当前的系统时间,来自动赋值。
- 6,varchar:字符串
- name varchar(20):表示姓名最大20个字符
- 1,int:整数类型
- create table 表名(
- 创建表
- create table student(
id int,
name varchar(32),
age int,
score double(4,1),
birthday date,
insert_time timestamp
);
- create table student(
- 复制表
- create table 表名 like 被复制的表名;
- 语法
-
R(Retrieve):查询
- 查询某个数据库中所有的表名称
- show tables;
- 查询表结构
- desc 表名;
- 查询某个数据库中所有的表名称
-
U(Update):修改
- 1,修改表名
- alter table 表名 rename to 新的表名;
- 2,修改表的字符集
- alter table 表名 character set 字符集名称;
- 3, 添加一列
- alter table 表名 add 列名 数据类型;
- 4,修改列名称、类型
- alter table 表名 change 列名 新列名 新数据类型;
- alter table 表名 modify 列名 新数据类型;
- 5,删除列
- alter table 表名 drop 列名;
- 1,修改表名
-
D(Delete):删除
- drop table 表名;
- drop table if exists 表名 ;
DML:增删改表中的数据
1,添加数据
- 语法:
- insert into 表名(列名1,列名2,…列名n) values(值1,值2,…值n);
- 注意:
- 1,列名和值要一一对应
- 2,如果表名后,不定义列名,则默认给所有列添加值
- insert into 表名 values(值1,值2,…值n);
- 3,除了数字类型,其他类型需要引号引起来,单双引号都可以
2,删除数据
- 语法:
- delete from 表名 [where 条件]; ------ delete from stu where id=1;
- 注意:
- 1,如果不加条件,则删除表中所有记录
- 2,如果要删除所有记录
- 1,delete from 表名; – 不推荐使用。有多少条记录就会执行多少次删除操作
- 2,TRUNCATE TABLE 表名; – 推荐使用,效率更高,先删除表,然后再创建一张一样的表
3,修改数据
- 语法:
- update 表名 set 列名1 = 值1,列名2 = 值2,…[where 条件];
- 注意:
- 如果不加任何条件,则会将表中所有记录全部修改。
DQL:查询表中的记录
-
1,语法:select 字段列表
from 表名列表
where 条件列表
group by 分组字段
having 分组之后的条件
order by 排序
limit 分页限定 -
2,基础查询
-
多个字段的查询
- select 字段名1,字段名2…from 表名;
- 示例:select name,age from student;
- 注意:如果查询所有字段,则可以使用*来替代字段列表
-
去除重复
- distinct
- select distinct address from student;
-
计算列
- 一般可以使用四则运算计算一些列的值。(一般只会进行数值型的计算)
- ifnull(表达式1,表达式2):null参与运算,计算结果都为null
- 表达式1:哪个字段需要判断是否为null
- 表达式2:如果该字段为null后的替换值
- 示例:select name,math,english,math + english from student;
- 示例:select name,math,english,math + ifnull(english,0) from student;
-
起别名
- as :as也可以省略
- select name,math,english,math + ifnull(english,0) as 总分 from student;
-
-
3,条件查询
- 1,where子句后跟条件
- 2,运算符
- <、>、<=、>=、=、<>(不等于)
- BETWEEN…AND
- IN(集合)
- LIKE
- 占位符
- _:单个任意字符
- %:多个任意字符
- and 或 &&
- or 或 ||
- not 或 |
DQL:查询语句
1,排序查询
- 语法:order by 子句
- order by 排序字段1 排序方式1,排序字段2 排序方式2…;
- 示例1:select * from student order by math DESC;
- 示例2:select * from student order by math ASC,english ASC;
- 排序方式:
- ASC:升序排列,默认的
- DESC:降序排列
- 注意:
- 如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件。
2,聚合函数:将一列数据作为一个整体,进行纵向的计算
-
count:计算个数
- 1,一般选择非空的列:主键 count(id)
- 示例:select count(id) from student;
- 2,count(*) ----- 不推荐使用
- 1,一般选择非空的列:主键 count(id)
-
max:计算最大值
- 示例:select max(math) from student;
-
min:计算最小值
- 示例:select min(math) from student;
-
sum:求和
- 示例:select sum(math) from student;
-
avg:计算平均值
- 示例:select avg(math) from student;
- 注意:聚合函数的计算,排除null值。
- 解决方案:
- 1,选择非空的列进行计算
- 2,IFNULL函数
3,分组函数
- 语法:group by 分组字段
- 1,分组之后查询的字段:分组字段、聚合函数
- 示例1:select sex,avg(math) from student group by sex;
- 示例2:select sex,avg(math) from student where math>70 group by sex;
- 示例1:select sex,avg(math) from student group by sex having count(id)>2;
- 2,where和having的区别
- where在分组之前进行限定,如果不满足,则不参与分组。having在分组之后进行限定,如果不满足结果,则不会被查询出来。
- where 后不可以跟聚合函数,having可以进行聚合函数的判断。
- 1,分组之后查询的字段:分组字段、聚合函数
4,分页查询
- 语法:limit 开始的索引,每页查询的条数;
- 示例:select * from student limit 0,3; —每页显示三条记录,第一页
- 示例:select * from student limit 3,3; —第二页
- 公式:开始的索引 = (当前的页码-1) * 每页显示的条数
约束
- 概念:对表中的数据进行限定,保证数据的正确性、有效性和完整性
- 分类:
- 1,主键约束:primary key
- 2,非空约束:not null
- 3,唯一约束:unique
- 4,外键约束:foreign key
非空约束:not null
- 1,创建表时添加约束
create table map(
id int,
name varchar(20) not null -- name为非空
);`
-
2,创建表完后,添加非空约束
alter table map modify name varchar(20) not null;
-
3,删除name的非空约束
alter table map modify name varchar(20);
唯一约束:unique
- 值不能重复
- 1,创建表时,添加唯一约束
- 注意:mysql中,唯一约束限定的列的值可以有多个null
create table jsp(
id int,
phone_number varchar(20) unique -- 添加唯一约束
);
- 2,删除唯一约束
alter table jsp drop index phone_number;
- 3,在创建表后,添加唯一约束
alter table jsp modify phone_number varchar(20) unique;
主键约束:primary key
-
1,注意:
- 含义:非空且唯一
- 一张表只能有一个字段为主键
- 主键就是表中记录的唯一标识
-
2,在创建表时,添加主键约束
create table jsp(
id int primary key, -- 给id添加主键约束
name varchar(20)
);
- 3,删除主键
alter table jsp drop primary key;
- 4,创建完表后,添加主键
alter table jsp modify id int primary key;
- 5,自动增长
- 概念:如果某一列是数值类型的,使用auto_increment可以来完成值的自动增长
- 在创建表时,添加主键约束,并且完成自动增长
create table jsp( id int primary key auto_increment, name varchar(20) );-
删除自动增长
alter table jsp modify id int;
-
生成表后添加自动增长
alter table jsp modify id int auto_increment;
外键约束:foreign key
- 1,在创建表时,可以添加外键
- 语法:
cretate table 表名(
........
外键列
constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称)
);
-
2,删除外键
- 语法:alter table 表名 drop foreign key 外键名称;
- 示例:alter table employee drop foreign key emp_dept_fk;
-
3,创建表之后,添加外键
- 语法:alter table 表名 add constraint 外键名称 foreign key (外键字段) references 主表名称(主表列名称);
- 示例:alter table employee add constraint emp_dept_fk foreign key (dep_id) references department(id);
-
4,级联操作
- 添加级联操作
- 语法:alter table 表名 add constraint 外键名称
foreign key (外键字段名称) references 主表名称(主表列名称) on update cascade on delete cascade; - 级联更新:on update cascade
- 级联删除:on delete cascade
- 语法:alter table 表名 add constraint 外键名称
- 添加级联操作
数据库的设计
一,多表之间的关系
- 1,一对一关系:
- 如:人和身份证
- 分析:一个人只有一个身份证,一个身份证只能对应一个人
- 2,一对多(多对一):
- 如:部门和员工
- 分析:一个部门有多个员工,一个员工只能对应一个部门
- 3,多对多关系:
- 如:学生和课程
- 分析:一个学生可以选择很多门课程,一个课程也可以被很多学生选择
实现上述关系
- 1,一对多(多对一):
- 实现方式:在多的一方建立外键 ,指向一的一方的主键。
- 2,多对多:
- 多对多关系实现需要借助第三张中间表。中间表至少包含两个字段,这两个字段作为第三张表的外键,分别指向两张表的主键
- 3,一对一:
- 可以在任意一方添加唯一外键指向另一方的主键。
多表查询
- 查询语法:
select
列名列表
from
表名列表
where......
示例:
# 创建部门表
CREATE TABLE dept(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
INSERT INTO dept (NAME) VALUES ('开发部'),('市场部'),('财务部');
# 创建员工表
CREATE TABLE emp(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
gender CHAR(1), -- 性别
salary DOUBLE, -- 工资
join_date DATE, -- 入职日期
dept_id INT,
FOREIGN KEY (dept_id) REFERENCES dept(id) -- 外键,关联部门表主键
);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('孙悟空','男',7200,'2013-02-24',1);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('猪八戒','男',3600,'2010-12-02',2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('唐僧','男',9000,'2008-08-08',2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('白骨精','女',5000,'2015-10-07',3);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('蜘蛛精','女',4500,'2011-03-14',1);
- 多表查询的分类
-
1,内连接查询
- 隐式内连接:使用where条件
-- 查询员工标的名称,性别、部门表的名称 SELECT emp.name,gender,dept.name FROM emp,dept WHERE emp.dept_id=dept.id; SELECT t1.name, -- 员工表的姓名 t1.gemder,-- 员工表的性别 t2.name -- 部门表的姓名 FROM emp t1, dept t2 WHERE t1.dept_id = t2.id;-
显式内连接
- 语法:select 字段列表 from 表名1 inner join 表名2 on 条件
SELECT * FROM emp INNER JOIN dept ON emp.dept_id=dept.id; SELECT * FROM emp JOIN dept ON emp.dept_id=dept.id;
-
2,外连接查询
-
3,子查询
-
概念:查询中嵌套查询,称嵌套查询为子查询
– 查询工资最高的员工信息
SELECT MAX(salary) FROM emp;
– 查询员工信息,并且工资等于9000
SELECT * FROM emp WHERE emp.salary=9000;
– 一条语句完成操作
SELECT * FROM emp WHERE emp.salary = (SELECT MAX(salary) FROM emp);
-
-

















 1914
1914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









