






 本文详细介绍了Pandas库中多层索引的创建、操作及应用,包括多层索引的创建方式、索引交换、排序、堆叠与取消堆叠、设置与重置索引,以及分组与聚合等高级功能。
本文详细介绍了Pandas库中多层索引的创建、操作及应用,包括多层索引的创建方式、索引交换、排序、堆叠与取消堆叠、设置与重置索引,以及分组与聚合等高级功能。
文章目录
1. 多层索引
多层索引(MultiIndex),具有多个层次索引,有些类似于根据索引进行分组的形式。通过多层次索引,我们可以使用高层次索引,来操作整个索引组的数据。
1.1 创建方式
第一种
我们在创建Series或者DataFrame时,通过 index(columns) 参数传递多维数组,进而创建多级索引。多级索引可以通过names属性设置名称,每级索引的元素个数相同。
第二种
我们 MultiIndex 类的方法创建 MultiIndex 对象,然后作为Sereis或者DataFrame的index(columns)参数值。同样可以通过names参数指定多层索引的名称
- from_arrays:接收一个多维数组参数,高维指定高层索引,低纬指定底层索引
- from_tuples:接收一个元素作为列表,每个元祖指定每个索-引->(高维索引,低纬索引)
- from_product:接收一个可迭代对象列表,根据可迭代对象列表中元素的笛卡尔积创建多级索引
1.2. 多层索引操作
对于多层索引,同样支持单层索引的相关操作,例如,索引元素、切片、索引数组选择元素等。我们也可以根据多级索引,按照层次逐级选择元素。多层元素优势,通过高层次索引,来操作整个索引组的数据
操作语法:
-
s[操作] -
s.loc[操作] -
s.iloc[操作]
操作可以是索引、切片、数组索引
1.2.1. Series 多层索引
-
loc:标签索引操作,通过多层索引,获取该索引对应的一组值 -
iloc:位置索引操作,获取对应位置的元素值,与是否多层索引无关 -
s[操作]的操作逻辑见下,不推荐使用!- 对于索引(单级),首先按照标签选择,如标签不存在,按照位置选择
- 对于多级索引,按照标签进行选择
- 对于切片,如果提供的是整数,按照位置选择,否则按照标签选择
- 对于数组索引,如果数组元素都是整数,根据位置进行索引,否则根据标签索引
1.2.2. DataFrame 多层索引
-
loc:标签索引操作,通过多层索引,获取该索引对应的一组值 -
iloc:位置索引操作,获取对应位置的一行数据,与是否多层索引无关 -
s[操作]的操作逻辑见下,不推荐使用!- 对于索引,根据标签获取相应列。如果是多层索引,获得多列
- 对于数组索引,根据标签,获取相应列。如果是多层索引,获得多列
- 对于切片,先按照标签索引,然后再按照位置进行索引,获取行的数据
import numpy as np
import pandas as pd

- Series 创建多级索引:
# Series创建多级索引,通过index参数指定
# 单层索引,index参数指定一维数组
# s = pd.Series([1,2,3,4],index=['a','b','c','d'])
# display(s)
### 方式01 ###
# 1.多级 索引,index参数值指定多维数组
# s = pd.Series([1,2,3,4],index=[['湖南','湖南','北京','北京'],['长沙','衡阳','海淀','昌平']])
# display(s)
# # 多级索引,为每一层索引指定名称
# s.index.names=['省份','城市']
# display(s)
### 方式02 ###
# 2.Series创建多级索引,通过创建MultiIndex对象,设置给index参数
# from_arrays,通过列表的方式创建:[[第1级索引],[第2级索引],.....[第n级索引]]
# m = pd.MultiIndex.from_arrays([['湖南','湖南','北京','北京'],['长沙','衡阳','海淀','昌平']])
# s = pd.Series([1,2,3,4],index=m)
# display(s)
### 方式03 ###
# 3.from_tuples:通过元祖构成列表,[(第1级索引元素,第2级索引元素),(第1级索引元素,第2级索引元素)....]
# m = pd.MultiIndex.from_tuples([('湖南','长沙'),('湖南','衡阳'),('北京','海淀'),('北京','昌平')])
# s = pd.Series([1,2,3,4],index=m)
# display(s)
### 方式04 ###
# 4.from_product:通过笛卡尔积方式创建MultiIndex对象设置给index参数,但是结果不合理!
m = pd.MultiIndex.from_product([['湖南','北京'],['长沙','衡阳','海淀','昌平']])
s = pd.Series([1,2,3,4,5,6,7,8],index=m)
display(s)
- DataFrame 行多级索引:
# DataFrame行多级索引
# 它和Series多级索引创建没有区别,方式1:index参数多维数组。
# 方式2:通过MultiIndex类的方法(from_arrays from_tuples from_product)创建MultiIndex对象,设置index。
### 方式01 ###
# df = pd.DataFrame(np.arange(1,9).reshape(4,2),index=[['湖南','湖南','北京','北京'],['长沙','衡阳','海淀','昌平']])
# display(df)
### 方式02 ###
# from_arrays
# m = pd.MultiIndex.from_arrays([['湖南','湖南','北京','北京'],['长沙','衡阳','海淀','昌平']])
# df = pd.DataFrame(np.arange(1,9).reshape(4,2),index=m)
# display(df)
### 方式03 ###
# from_tuples
# m = pd.MultiIndex.from_tuples([('湖南','长沙'),('湖南','衡阳'),('北京','海淀'),('北京','昌平')])
# df = pd.DataFrame(np.arange(1,9).reshape(4,2),index=m)
# display(df)
### 方式04 ###
# from_product
m = pd.MultiIndex.from_product([['湖南','北京'],['长沙','衡阳','海淀','昌平']])
df = pd.DataFrame(np.arange(1,17).reshape(8,2),index=m)
display(df)
- 创建 DataFrame 列多级索引:
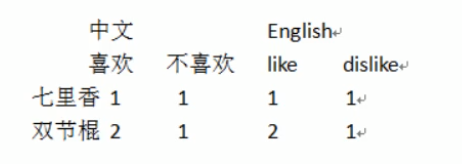
# DataFrame创建列多层索引和行创建多层索引类似,区别在创建DataFrame设置给参数columns
df = pd.DataFrame(np.array([[1,1,1,1],[2,1,2,1]]),index=['七里香','双节棍'],columns=[['中文','中文','English','English'],['喜欢','不喜欢','like','dislike']])
display(df)
- Series 多层索引操作:
# Sereis多层索引操作
# 1.loc标签操作
s = pd.Series([1,2,3,4],index=[['湖南','湖南','北京','北京'],['长沙','衡阳','海淀','昌平']])
display(s)
# 直接使用外层索引访问,可以获得外层索引对应的一组值
# display(s.loc['湖南'])
# 多层索引访问中,不支持直接使用内层索引访问
# 因为多层索引访问中,首先从外层索引找,外层没有‘长沙’标签,报错!
# display(s.loc['长沙'])
# 使用外层+内存索引逐层访问
# display(s.loc['湖南','长沙'])
# 2.iloc位置操作
# 根据位置访问,与是否存在多层索引没有关系的
# display(s.iloc[0])
# 3.切片操作
# 根据【标签】来切片,注意切片的标签需要排好序(字典顺序),否则报错!(详见下段代码)
# s = s.sort_index()
# display(s)
# display(s.loc['北京':'湖南'])
# 根据【位置】切片
# display(s.iloc[0:2])
# 4.数组索引,也许要对索引进行进行排序
s = s.sort_index()
display(s.loc[['北京','湖南']])
- 注意:标签来切片,注意切片的标签需要排好序(字典顺序),否则报错。使用
sort_index方法对索引进行排序(字典顺序),再切片!
# 标签来切片,注意切片的标签需要排好序(字典顺序),否则报错。使用sort_index方法对索引进行排序(字典顺序),再切片
s= pd.Series([1,2,3,4],index=[['b','a','a','b'],['长沙','衡阳','海淀','昌平']])
display(s)
s = s.sort_index()
display(s)
display(s.loc['b':'a'])
- DataFrame 多层索引操作:

m =pd.MultiIndex.from_product([['湖南','北京'],['2017','2018']])
df = pd.DataFrame(np.array([[8000],[8100],[1200],[1150]]),index=m)
display(df)
# 1.loc 标签的访问
# 直接使用外层索引访问
# display(df.loc['湖南'])
# 不支持直接使用内层索引访问
# display(df.loc['2017'])
# 外层+内层逐层访问,得到一行数据
# display(df.loc['湖南','2017'])
# display(df.loc[('湖南','2017')])
# 2.iloc位置访问,是否存在多层索引没有关系的
# display(df.iloc[0])
# 3.切片操作
# 标签的切片
# 先对索引进行排序
# df = df.sort_index()
# display(df)
# # display(df.loc['北京':'湖南'])
# # 混合操作,设置axis=0,否则2017当做列索引名称。但是Series不需要!(见下方代码)
# display(df.loc(axis=0)[:,'2017'])
# 4.位置切片
# display(df.iloc[0:2])
# 5.数组索引,也需要索引有序
df = df.sort_index()
display(df)
display(df.loc[['北京','湖南']])
- 注意:混合操作,设置
axis=0,否则2017当做列索引名称。但是Series不需要!
# Series 不需要设置 axis=0
m =pd.MultiIndex.from_product([['湖南','北京'],['2017','2018']])
s = pd.Series(np.array([8000,8100,1200,1150]),index=m)
display(s.loc[:,'2017'])
2. 交换索引 swaplevel
我们可以调用DataFrame对象的swaplevel方法交换两个层级索引。该方法默认对倒数第2层和倒数第1层进行交换。
我们可以指定交换层级,层次从0开始,由外向内递增,也可以指定负值,负值表示倒数第n层。
我们可以通过层级索引的名称进行交换。

df = pd.DataFrame(np.arange(1,9).reshape(4,2),index=[['A','A','B','B'],['a1','a1','b1','c1'],['a2','b2','b2','c2']])
display(df)
### 方式01 ###
# 默认交换最里面2个层级索引
# display(df.swaplevel())
# 索引的层级从外到内,第0层,第1层,第2层
display(df.swaplevel(0,2)) # 第0层和第2层叫唤
# 索引的层级可以为负值,-1,-2,-3,-1最内层
display(df.swaplevel(-3,-1))
### 方式02 ###
# 根据层级索引名称交换
df.index.names=['layer0','layer1','layer2']
display(df.swaplevel('layer0','layer2'))
3. 索引排序 sort_index
我们可以使用 sort_index 对索引进行排序处理。
参数:
level:指定根据哪一层排序,默认最外层。level值可以是数值,索引名或者二者构成的列表。inplace:是否就地修改,默认为False。
# 对行进行多层索引排序:
df = pd.DataFrame(np.arange(1,9).reshape(4,2),index=[['B','A','B','A'],['a1','a1','b1','c1'],['a2','b2','b2','c2']])
display(df)
# 索引排序,默认对最外层的索引排序(字典升序)
# display(df.sort_index())
# 自定义对哪个层级的索引排序
# df.sort_index(level=1)
df.sort_index(level=1,ascending=False)
# inplace参数:
df.sort_index(inplace=True)
display(df)
- 对列进行多层索引排序:
# 对列进行多层索引排序:
df = pd.DataFrame(np.array([[1,1,1,1],[2,1,2,1]]),index=['七里香','双节棍'],columns=[['Chinese','Chinese','English','English'],['喜欢','不喜欢','like','dislike']])
display(df)
display(df.sort_index(axis=1,ascending=False))
4. 索引堆叠 stack/unstack
-
通过 DataFrame 对象的
stack方法,可以进行索引堆叠,即将指定成绩的列转换成行。- level参数:指定转换的层级,默认为- 1。
-
通过 DataFrame 对象的
unstack方法,可以取消索引堆叠,即将指定层级的行转换成列。-
level参数:指定转换的层级,默认为 -1。
-
fill_value参数:指定填充值,默认为NaN。
-
# 对索引进行堆叠操作,会将列索引堆加在行最内层索引上。
# 当对索引进行取消堆叠的操作,将行索引堆加列的最内层索引上
# 索引堆叠使得访问数据更加灵活
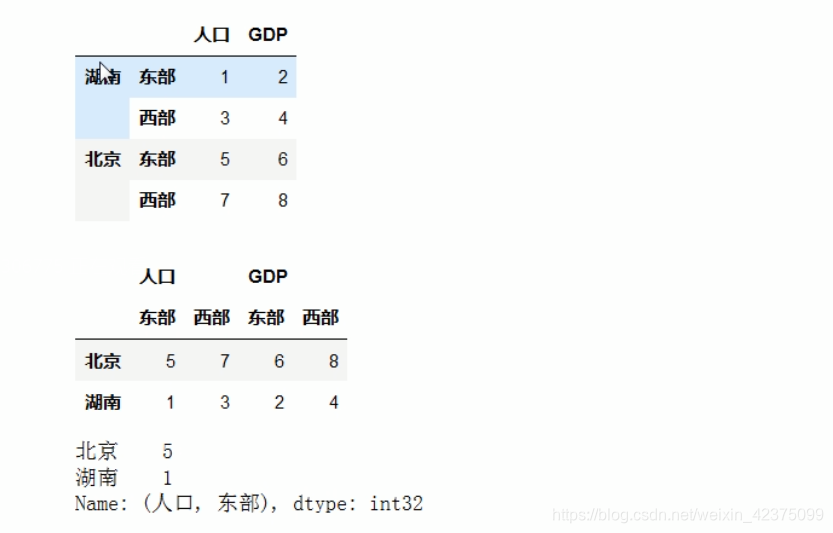
m = pd.MultiIndex.from_arrays([['湖南','湖南','北京','北京'],['东部','西部','东部','西部']])
df = pd.DataFrame(np.arange(1,9).reshape(4,2),index=m,columns=['人口','GDP'])
display(df)
# 当对索引进行取消堆叠的操作,将行索引堆加列的最内层索引上
df = df.unstack()
display(df)
# # 访问人口是东部的数据
display(df['人口','东部'])
df = pd.DataFrame(np.arange(1,9).reshape(4,2),index=[['B','A','B','A'],['a1','a1','b1','c1'],['a2','b2','b2','c2']])
df.index.names=['layer0','layer1','layer2']
df.sort_index(inplace=True)
display(df)
# 取消堆叠操作,可能会产生NaN,避免空值,填充数据使用fill_value
# df = df.unstack(fill_value=0)
# display(df)
# level参数自定义层级,默认是行最内层索引
# df = df.unstack(level=1,fill_value=0)
# display(df)
# 除了自定义层级数值,还可以指定索引的名称
df = df.unstack(level='layer0',fill_value=0)
display(df)
- 列索引堆叠:
# 索引的堆叠操作 对索引进行堆叠操作,会将列索引堆加在行最内层索引上
df = pd.DataFrame(np.array([[1,1,1,1],[2,1,2,1]]),index=['七里香','双节棍'],columns=[['中文','中文','English','English'],['喜欢','不喜欢','like','dislike']])
display(df)
# 七里香歌曲中中文信息
df = df.stack(0)
display(df)
display(df.loc['七里香','中文'])
5. 索引设置 set_index
在DataFrame中,如果我们需要将现有的某一或者多列作为行索引,可以调用set_index方法实现。
参数:
drop:是否丢弃作为新索引列,默认为Trueappend:是否以追加方式设置索引,默认为Falseinplace:是否就地修改,默认为False
df = pd.DataFrame({'stuno':[1,2,3],'name':['zs','ls','ww'],'age':[20,21,2]})
display(df)
# 1.set_index设置索引,设置参数指定列,充当索引
# display(df.set_index('stuno'))
# 2.设置层级行索引
# display(df.set_index(['stuno','name']))
# 3.默认情况下,充当行索引的列数据丢弃,设置drop=false保留列数据
# display(df.set_index('stuno',drop=False))
# 4.append用来设置是否以追加的方式设置索引,默认False(取代之前的索引)
df.set_index('stuno',inplace=True)
display(df)
df.set_index('name',inplace=True,append=True)
display(df)
6. 重置索引 reset_index
调用DataFrame的reset_index重置索引(将行索引取消),与set_index正相反。
参数:
level:重置索引层级,默认重置所有层级的索引。如果重置所有索引,将会创建默认整数序列索引。drop:是否丢弃重置索引列,默认为False。inplace:是否就地修改,默认为False。
df = pd.DataFrame({'stuno':[1,2,3],'name':['zs','ls','ww'],'age':[20,21,2]})
# display(df)
# 设置层级行索引
df.set_index(['stuno','name'],inplace=True)
display(df)
# 1.重置索引,默认重置所有层级的行索引,重新生成整数序列为行索引
# display(df.reset_index())
# 2.level指定重置索引的层级,将重置的行索引充当回新的列
# display(df.reset_index(1))
# 3.重置索引后,默认将重置的行索引充当回新的列,如果不想将重置的行索引充当回新的列,指定drop=True
display(df.reset_index(1,drop=True))
7. 分组与聚合
分组与聚合操作与数据库分组和聚合类似
7.1. groupby分组
我们可以通过groupby方法对Series或DataFrame对象实现分组操作。该方法返回一个分组对象。
分组对象属性和方法:
groups属性:返回一个字典类型对象,包含分组信息size方法:返回每组记录数量describe方法:分组查看统计信息
7.2. 迭代
使用for循环对分组对象进行迭代。迭代每次返回一个元祖(tuple);第1个元素为分组的key,第2个为改组对应的数据(value)。
df = pd.DataFrame({'部门':['研发','财务','研发','财务'],'项目组':['一组','二组','二组','一组'],
'姓名':['张三','李四','王五','赵六'],'年龄':[20,22,23,24],'利润':[5,10,10,25]})
display(df)
# 根据单个列索引分组,返回分组对象
group = df.groupby('部门')
# 分组对象不像列表,可以将分组后内容直接输出,其类型是DataFrameGroupBy
display(group)
# 分组对象是一个可迭代的对象,通过for循环来查看分组信息
# for item in group:
# display(type(item)) # 返回的是tuple
# 对分组对象迭代返回的元组对象(key,value)
for k,v in group:
display(k,v)
# 查看分组对象属性和方法
# groups属性得到分组信息字典 key:分组数据的索引
display(group.groups)
# 得到每组记录条数
display(group.size())
display(group.describe())
7.3. 分组方式
使用groupby进行分组时,分组参数可以是如下形式:
-
索引名:根据该索引进行分组。
-
函数:函数需要有一个参数,用来接收行索引值。函数还需要具有返回值,用来指定组。
-
索引名构成的数组:根据数组中多个索引进行分组。
-
字典或者Series:key指定索引,value指定分组依据,value值相等的分为一组。
df = pd.DataFrame({'部门':['研发','财务','研发','财务'],'项目组':['一组','二组','二组','一组'],
'姓名':['张三','李四','王五','赵六'],'年龄':[20,22,23,24],'利润':[5,10,10,25]})
display(df)
# 根据单个列说明分组,返回分组对象
# group = df.groupby('部门')
# for k,v in group:
# display(k,v)
### 方式01 ###
# 1.多个索引列分组
# group = df.groupby(['部门','项目组'])
# for k,v in group:
# display(k,v)
### 方式02 ###
# 2.根据函数分组
# df = df.set_index('利润')
# display(df)
# # 函数需要有一个参数,用来接收行索引值。函数还需要具有返回值,用来指定组
# def group_handle(index):
# if index<10:
# return 0
# return 1
# # 需求:将利润<10和利润>=10的人员分组
# group = df.groupby(group_handle)
# for k,v in group:
# display(k,v)
### 方式03 ###
# 3.字典
# 根据行索引分组
# group = df.groupby({0:0,1:0,2:1,3:1})
# for k,v in group:
# display(k,v)
# 4.根据列索引值分组
group = df.groupby({'姓名':0,'利润':0,'部门':1,'项目组':1},axis=1)
for k,v in group:
display(k,v)
* 分组后统计:
- 对分组数据统计(聚合):利润、年龄、数值型进行统计;姓名、项目组是字符串,不会统计;部门属于分组字段,不参与统计。
- 对 DataFrame:所有数值型数据相加,字符串做拼接;设置DataFrame只对数值型数据统计,指定参数numeric_only=True。
- 对分组数据中指定列数据进行统计。
df = pd.DataFrame({'部门':['研发','财务','研发','财务'],'项目组':['一组','二组','二组','一组'],
'姓名':['张三','李四','王五','赵六'],'年龄':[20,22,23,24],'利润':[5,10,10,25]})
display(df)
group= df.groupby('部门')
for k,v in group:
display(k,v)
# 1.对分组数据统计(聚合)
# 利润、年龄、数值型进行统计;姓名、项目组是字符串,不会统计;部门属于分组字段,不参与统计
display(group.sum())
# 2.对比DataFrame
# 所有数值型数据相加,字符串做拼接
display(df.sum())
# 设置DataFrame只对数值型数据统计,指定参数numeric_only=True
display(df.sum(numeric_only=True))
# 3.对分组数据中指定列数据进行统计
display(group['利润'].sum())
7.4. apply
对分组对象,可以调用apply函数,该函数接收每个组的数据,返回操作之后的结果。apply最后将每个组的操作结果进行合并(concat)。
df = pd.DataFrame({'部门':['研发','财务','研发','财务'],'项目组':['一组','二组','二组','一组'],
'姓名':['张三','李四','王五','赵六'],'年龄':[20,22,23,24],'利润':[5,10,10,25]})
display(df)
group= df.groupby('部门')
for k,v in group:
display(k,v)
# 对分组对象进行apply,apply接收函数实现对分组数据操作
# 函数具有一个参数,依次接收分组数据,返回每一个分组处理的结果,
# 注意点,apply对于第一个分组数据会调用2次,但是不会影响操作结果
# group.apply(lambda x:display(x,type(x)))
# 对每组数据进行求和统计
display(group.apply(lambda x:x.sum(numeric_only=True)))
7.5. 聚合
可以在分组对象进行聚合(多个值变成一个值)。例如,mean(),sum()等。
-
除此之外,我们可调用
agg方法,实现自定义聚合方式。函数接收一行或者一列数据,返回该行或者列聚合后的结果。 -
agg方法实现对DataFrame、分组对象的聚合,可以传入4种类型参数,字符串、列表、字典以及函数。
示例:
- agg 方法实现DataFrame对象的聚合:
### agg方法实现DataFrame对象的聚合 ###
df = pd.DataFrame({'部门':['研发','财务','研发','财务'],'项目组':['一组','二组','二组','一组'],
'姓名':['张三','李四','王五','赵六'],'年龄':[20,22,23,24],'利润':[5,10,10,25]})
# display(df)
# 使用mean sum这些统计方法得到聚合信息
# display(df.mean(numeric_only=True),df.sum(numeric_only=True))
### agg方法实现对DataFrame、分组对象的聚合,可以传入4种类型参数,字符串、列表、字典以及函数 ###
# 1.字符串
# display(df.agg('mean',numeric_only=True),df.agg('sum',numeric_only=True))
# 2.多个字符串构成的列表
# 优点:可以将mean和sum这两个聚合信息合并起来展示
# display(df.agg(['mean','sum']))
# display(df.agg(['mean','sum']),numeric_only=True)
# 3.字典:{k1:v1,k2:v2};k:指定索引名称,value:指定统计函数名
# 针对不同的列,提供不同统计聚合方法
display(df.agg({'利润':['mean','sum'],'年龄':['max','min']}))
# 4.函数
# 自定义聚合方式,函数具有一个参数,用来DateFrame传递过每一列(行),返回操作后结果
# display(df.agg(lambda x:display(x,type(x))))
display(df.agg(lambda x:x.mean() if x.name=='利润' else None))
- agg 方法实现对分组对象的聚合:
### agg方法实现对分组对象的聚合 ###
df = pd.DataFrame({'部门':['研发','财务','研发','财务'],'项目组':['一组','二组','二组','一组'],
'姓名':['张三','李四','王五','赵六'],'年龄':[20,22,23,24],'利润':[5,10,10,25]})
# display(df)
group= df.groupby('部门')
for k,v in group:
display(k,v)
# 1.字符串
# display(group.agg('mean'))
# 2.列表
# display(group.agg(['mean','sum']))
# 3.字典
# display(group.agg({'利润':['mean','sum'],'年龄':['max','min']}))
# 4.函数
# 函数的参数是分组后得到的DataFrame的每列的数据
# display(group.agg(lambda x:display(x,type(x))))
display(group.agg(lambda x:x.mean() if x.name=='利润' else None))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









