






一、应用层协议:
1. 概念:
负责应用程序之间数据的沟通,而应用程序是程序员自己写的,因此应用层协议也是程序员自己定义的协议。
2. 自定义协议:
自己定义的协议,私有协议;
3. 序列化和反序列化:
(1)网络版计数器:
客户端向服务器传送两个数字和一个运算符,服务器进行运算,最后将结果进行返回。
例如:
-
①将三个数据对象进行格式组织,然后通过网络数据传输,传递给服务端;int num1 = 1, int num2 = 2, char op = ‘+’;
②先将三个数据对象组成一个字符串,例如:“10;20;+”;
③将三个数据在内存中进行二进制排列:九个字节空间,前八个放俩数字,最后一个字节放字符。这样就将数据组织起来了。
(2)序列化与反序列化:数据的组织和解析。
①序列化:将数据对象按照指定协议进行组织成可持久化存储/数据传输的二进制数据块;
②反序列化:将持久化存储/数据传输的二进制数据块按照指定协议解析出各个数据对象;
- 使用结构体进行数据对象的二进制结构体组织,进行数据传输/可持久化数据存储;使用结构体来组织就是其实就是数据对象的二进制序列化。
(3)序列化的种类:
①Json序列化:SON(JavaScript Object Notation) 是一种轻量级的数据交换格式。 易于人阅读和编写。同时也易于机器解析和生成。
-
JSON中的元素都是键值对——key:value形式,键值对之间以":"分隔,每个键需用双引号引起来,值的类型为String时也需要双引号。其中value的类型包括:对象,数组,值,每种类型具有不同的语法表示。
组织形式: -
{ "name": "json", "age": 18, "isEnable": false, "roles":null }
② Protobuf:是 Google 公司内部的混合语言数据标准,它是 一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
组织形式:
-
message RoleInfo { required string RoleName=1; required bool IsEnable=2; } message UserInfo { required string Name = 1; // ID required int32 Age = 2; // str optional bool IsRoot = 3; //optional field optional RoleInfo Roles = 4; //optional field }
③XML:可扩展标记语言(英语:Extensible Markup Language,简称:XML),是一种标记语言。标记指计算机所能理解的信息符号,通过此种标记,计算机之间可以处理包含各种信息的文章等。如何定义这些标记,既可以选择国际通用的标记语言,比如HTML,也可以使用像XML这样由相关人士自由决定的标记语言,这就是语言的可扩展性。
-
<?xml version="1.0" encoding="utf-8"?> <UserInfo xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <Name>xiangzhi.cheng</Name> <Age>18</Age> <IsRoot>true</IsRoot> <Roles> <RoleInfo> <RoleName>admin</RoleName> <IsEnable>true</IsEnable>
二、HTTP协议:
- 超文本传输协议;HTTP有一个很好的优点:给程序员一定的自制空间。
1.网址(url)
- 网址:统一资源定位符(定义玩过中唯一一份资源)—url。
(1)url如何定位网络中的资源:
①url格式及包含信息:
https://username:password @www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&ch=4&tn=78040160_14_pg&wd=C%2B%2B&fenlei=256#ch;
- https: 协议方案名称;https是加密的http。
- username:password:本次服务器的用户信息。
- www.baidu.com:80:域名,经过域名解析得到服务器的IP地址。80:端口信息。
- /s:请求的资源在服务器上的路径,不一定是实体资源。
- ie=utf-8&
f=8&rsv_bp=1&rsv_idx=1&ch=4&tn=78040160_14_pg&wd=C%2B%2B&fenlei=256&:查询字符串:当前客户端提交服务器的数据–有很多key-val形式键值对组成,键值对中由&隔开。 - #ch :片段标识符,指向html中的一个标签。
(2)url的编码与解码:
用户提交给服务器的查询字符串中的val需要进行url编码–因为url中有很多特殊字符具有特殊含义,若用户提交的数据中也包含一些相同的特殊字符就会造成歧义,因此需要对val进行url编码操作。
①url编码:将特殊字符的每一个字节,都转换为16进制数字的字符,例如 + —> 2b;为了与用户提交的2b 数据区别开。因此对每个数据转换后前面加上%。即:+ —> %2b。
②url解码:得到查询字符串后,在val中遇到%,则认为紧跟在其后面的两个字符需要解码,价码方式:%2b —> 2 11; 第一个数字左移四位或者第一个数字X16 + 第二个数字。即:2x16 + 11 = 43。
2.http协议格式:就是协议的实现。
请求抓包:

响应抓包:

(1)首行:
①请求首行:
-
请求方法 + url +协议版本:(空格进行间隔,以\r\n 作为结尾);
-
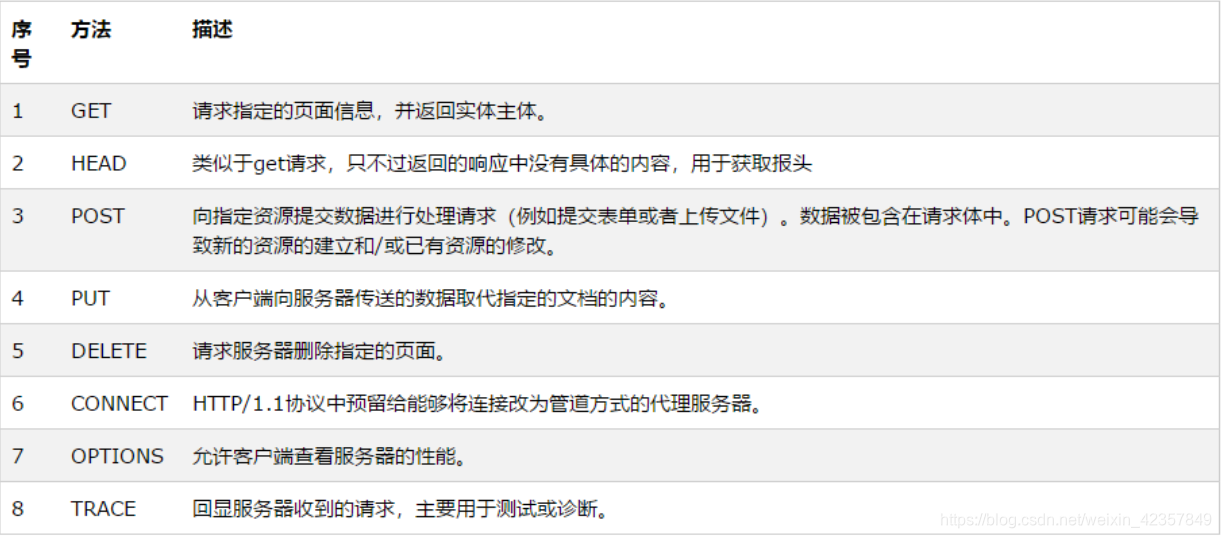
请求方法: 不同的方法,是由不同的负责功能。
GET:请求获取一个资源,并要求服务器返回实体资源。(不安全)
POST:向服务器提交表单数据。
HEAD:请求获取一个资源,但不需要服务器返回实体资源,只需要响应头部就行。
POST/GET:get也能向服务器提交数据,但提交的数据在url的查询字符串中,(get是没有正文的)受大小的限制;post提交是在正文中。
-
url:主要资源就是请求的资源路径以及查询字符串。
-
协议版本:HTTP/1.1 0.9 /1.0/1.1/2;不同的版本有不同的特性。
0.9 :默认支持get请求方法,并且是短链接(发送一个请求,得到响应后关闭连接),http在传输层使用tcp协议。
1.0 :支持了GET,POST,HEAD请求方法,并且支持长连接。
1.1 :支持更多的请求方法,新增很多特性,默认支持长连接,实现管线化传输。
2.0 :支持服务端给客户端推送消息。
-
②相应首行:
-
协议版本+响应状态码+状态码描述。(以空格间隔,以\r\n作为结尾);
- 协议版本: HTTP1.1 0.9/1.0/1.1/2.0
- 响应状态码:向客户端反应此次处理结果的状态。包含五大类:
1XX:一些描述信息;
2XX:本次请求正确处理;200-请求成功;
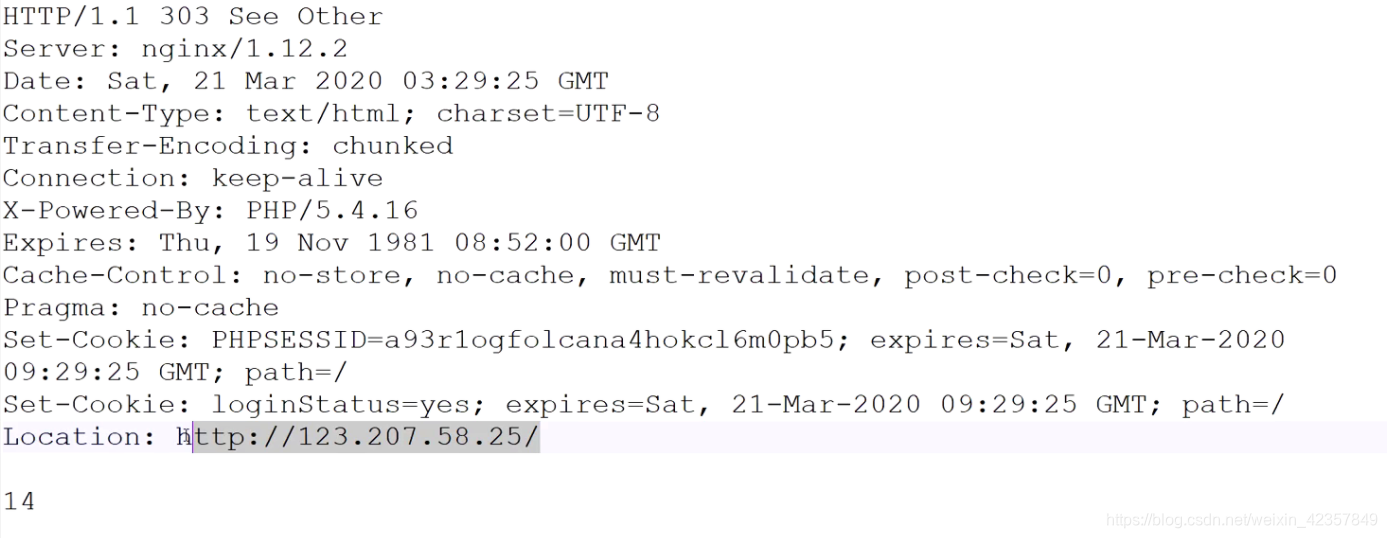
3XX:重定向,本次请求的资源可能移动到其他位置,请客户端重新请求新的位置。301-永久,302-临时,303- 查看其它。
4XX:客户端错误;404-服务器上没有请求资源;400-请求报文存在语法错误;403-没有权限访问该资源。
5XX:服务端错误;500- 服务器执行程序错误;
503-服务器处理超负荷,无法处理。 - 状态码描述:对于本次状态码的描述信息。
(2)头部:
-
由一些 key : val键值对组成;每个键值对以\r\n结束;
请求里面头部信息:
①Connection:close(短链接)/ keep-alive(长连接);
②Content-Length:表述当前正文的长度;(通过这个可以告诉对端本次请求接收多长的数据)。
③Content-Type:描述正文类型;(告诉对端应该如何处理数据)。
④Accept****:告诉对端自己能够接收数据的类型。
⑤Referer**:告诉服务器本次请求是从那个网页点击请求过来的。
响应里面头部的信息:
⑥Transfer-Enconding :chunked 正文的分块传输—将正文分为多块传输,每块再发送前要告诉对方这块数据有多长;常用于服务端本身不确定自己要响应的数据有多长的时候。
⑦Cookie/Set-Cokie : http协议是无状态协议,服务端为每一个登陆的客户端在服务端主机上创建一个session(会话),会话中描述了客户端的各种信息;将session保存在数据库中,然后通过Set-Cookie将sessionid以及重要的信息返回给客户端;客户端会把信息保存在cookie中,下一次请求服务端的时候,自动在cookie文件中读取信息,通过Cookie传递给服务端。
Cookie与Session区别:- Cookie:是服务端通过Set-Cookie响应给客户端的信息,保存在客户端,下次请求服务器的时候会携带有Cookie信息。
- Session是服务器为每个客户端单独创建的会话,保存在服务端,其中有客户端的认证信息。
⑧**Location:http://123.207.58.25/**搭配3XX状态码使用,通过描述的地址信息去告诉客户端重新请求的地址。
(3)空行:
\r\n:间隔头部和正文;
头部中最后一个信息也是\r\n;空行的主要作用是:判断是否接收到完整的头部信息。(双**\r\n**判断)。
- 通常接收http数据的流程:
①接收完整的头部信息—直到遇到\r\n\r\n;认为头部到此结束;
②解析头部,根据头部中Content-length决定正文应该接受多长;接收响应长度的正文。
(4)正文:
客户端提交给服务器的数据/服务器响应给客户端的数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









