




 本文介绍了机器学习的基础概念,包括回归模型与分类模型的区别,线性回归的数学表达及误差计算方式,并探讨了如何通过梯度下降法来降低损失。此外还提到了TensorFlow的基本使用流程,以及模型泛化的重要性。
本文介绍了机器学习的基础概念,包括回归模型与分类模型的区别,线性回归的数学表达及误差计算方式,并探讨了如何通过梯度下降法来降低损失。此外还提到了TensorFlow的基本使用流程,以及模型泛化的重要性。
课程来源Google机器学习速成:https://developers.google.cn/machine-learning/crash-course/
样本:有标签(x,y){特征,标签}
无标签(x,?){特征,?}
回归模型:预测连续值
分类模型:预测离散值
线性回归:y=w1x1+b
误差:L2误差(方差)=(观测值-预测值)^2
L2Loss=Sigma(x,y)∈D (y-prediction(x))^2
mean squared error:MSE=L2Loss/N
root mean squared error:RMSE
降低损失:计算梯度(导数)
迭代试错
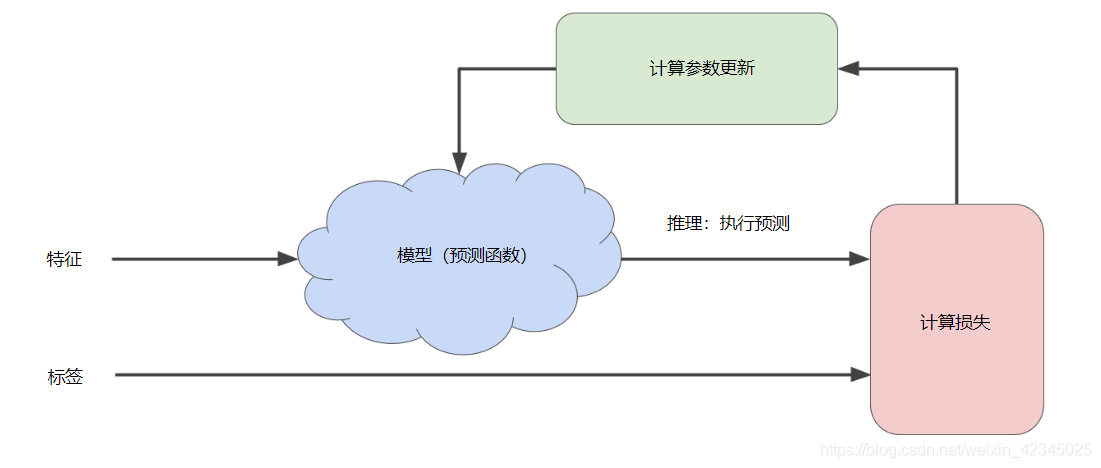
梯度下降法:依赖于负梯度
学习速率:可自定义的超参数
随机梯度下降法:一次抽取一个样本
小批量梯度下降版:10-1000个样本,损失和梯度在整批范围内达到平衡
tensorflow tf.estimated API
pandas intro:DataFrame(数据表),Series(单一列)
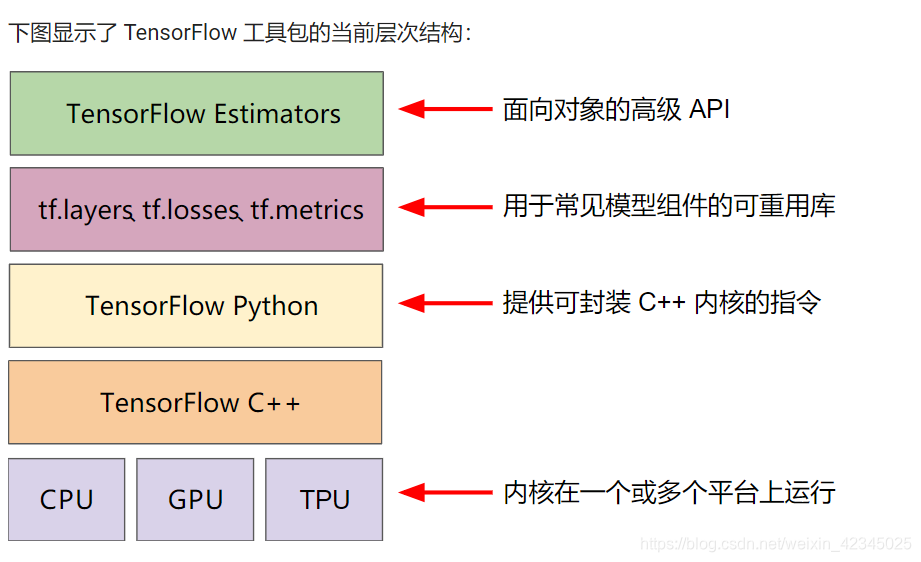
tensorflow入门:
1、定义特征并配置特征列
2、定义目标
3、配置LinearRegressor
4、定义输入函数
5、训练模型
6、评估模型
调整模型超参数、尝试其他特征
synthetic features and outliers
超参数:steps:训练迭代总次数;batch size:单步样本数量;方便变量:periods:控制报告的粒度
泛化:过拟合
模型是否出色?
理论上:泛化;直觉:奥卡姆剃刀定律;经验:测试集
三项假设(不是一成不变):
1、样本抽取独立同分布
2、分布平稳,不随时间变化
3、从同一分布中抽取样本


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









