 Elasticsearch实战
Elasticsearch实战




 本文深入讲解Elasticsearch的核心概念,包括索引、类型、文档和字段等,探讨其作为搜索工具的优势,如分布式处理能力、高实时性及简便的备份机制。文章还详细介绍了索引操作、映射配置、数值操作、匹配查询、词条查询、搜索过滤、高级查询、过滤、排序和聚合等功能。
本文深入讲解Elasticsearch的核心概念,包括索引、类型、文档和字段等,探讨其作为搜索工具的优势,如分布式处理能力、高实时性及简便的备份机制。文章还详细介绍了索引操作、映射配置、数值操作、匹配查询、词条查询、搜索过滤、高级查询、过滤、排序和聚合等功能。
1.基本概念
索引:相当于数据库
类型:相当于表
文档:相当于行
字段:相当于列
映射配置:字段的数据类型,属性,是否存储等特性。


2.为什么要使用elasticsearch作为搜索工具?
(1)es是分布式的搜索引擎,可处理大规模的数据。
(2)es的实时性比较高,可快速的查询数据。
(3)es采用 Gateway 的概念,使得完备份更加简单。
2.索引基本操作
put /heima //创建索引
{
“settings”:{
“number_of_shards”:1, //设置分片为1片
“number_of_replicas”:0 //设置副本为0
}
}
get /heima //查询索引
delete /heima //删除索引
3.映射的配置(创建类型)
(1)创建映射
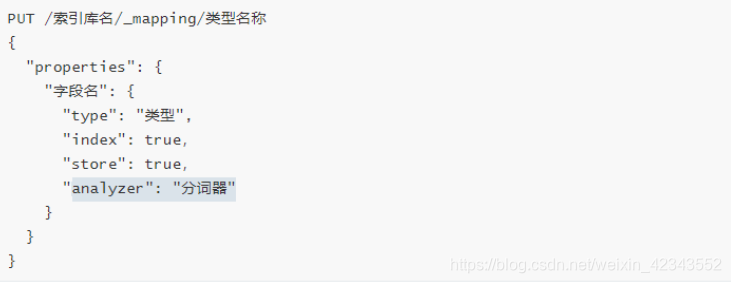
store


类型:text(会被分词),keyword(不会被分词)
analyzer:分词器,“ik_max_word” 固定写法
数值类型

(2)查询映射
get /heima/_mapping
4.数值的操作
(1)新增
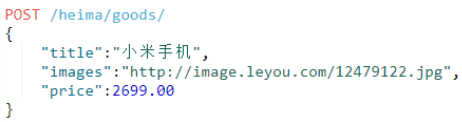
elasticSearch比较智能的一点:可根据值推断字段类型是什么,从而自动创建该字段。
(2)查询所有

(3)删除
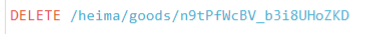
5.匹配查询
get /heima/_source
{
“query”:{
“match”:{
“title”:’‘小米手机" //根据title查询。
}
}
}
如果这样查询的话由于设置的title是text,可分词。因此会将小米手机,小米电视等都会查询出来。
若只想查询出小米手机则:
get /heima/_source
{
“query”:{
“match”:{
“title”:{
“query”:’'小米手机" ,
“operator”:“and”
}
}
}
}
设置最小匹配度:
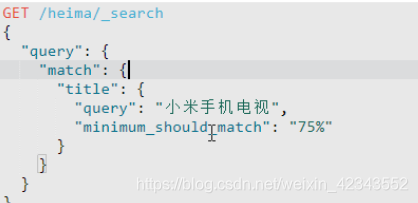
多字段匹配查询

6.词条查询
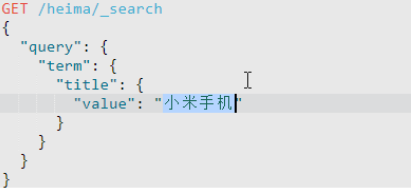
词条查询的词条必须是最小的不可分割的分词,如上所示,不会查询出任何结果,但如果将value写为小米,则会查询出。
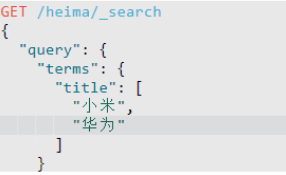
多词条查询(只要满足一个就能查询出)
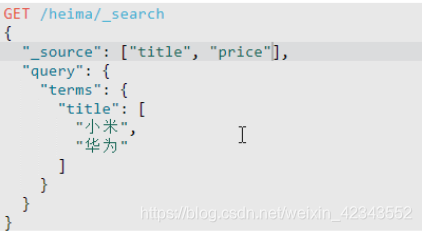
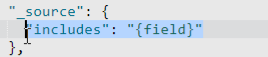
7.搜索过滤
结果集的过滤,即只能查询出指定的字段的值

8.高级查询
(1)布尔查询


(2)范围查询
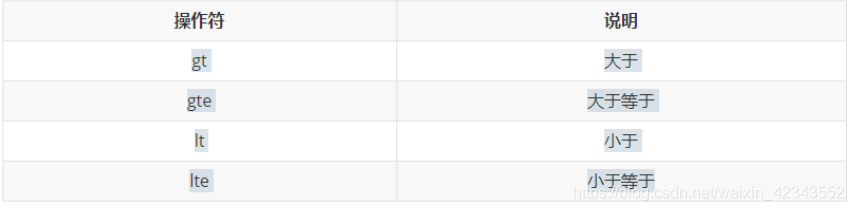
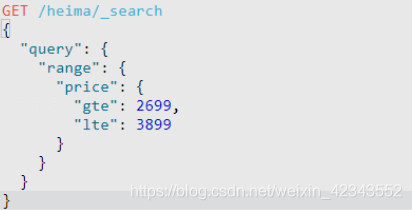
(3)模糊查询

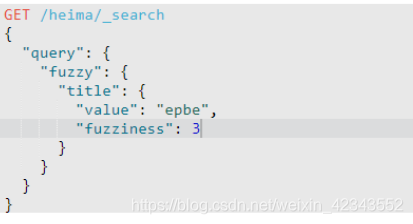
此处的fuzziness指的是允许的偏差数,最大为2.
9.过滤(精准查询)
此处的过滤和之前的结果过滤是不一样的,之前的_source过滤的是字段,即将不需要的字段过滤掉,查询结果中不出现。
而,此处的过滤是精度的过滤


当进行精确值查找时, 我们会使用过滤器(filters)。过滤器很重要,因为它们执行速度非常快,不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存。不过现在只要记住:请尽可能多的使用过滤式查询。
10.排序
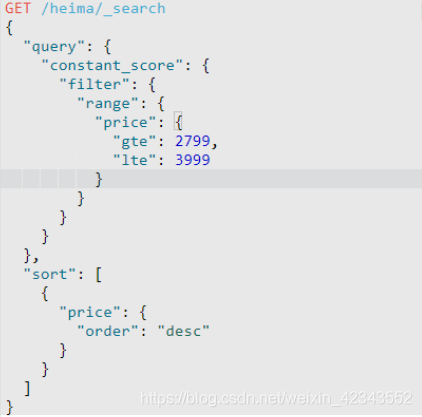

11.聚合





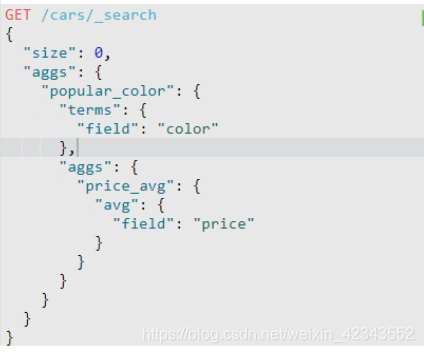
运行结果为:
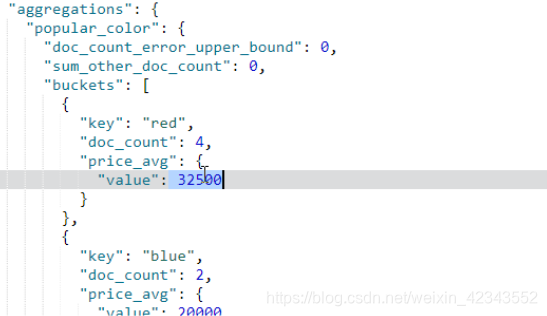
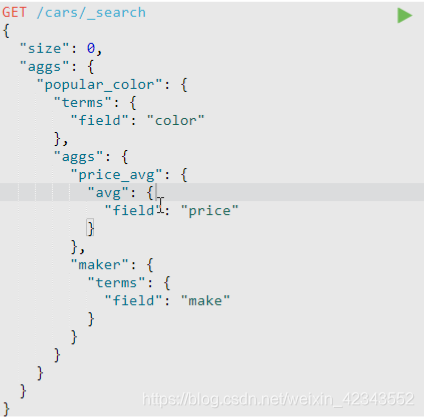
桶内嵌套桶
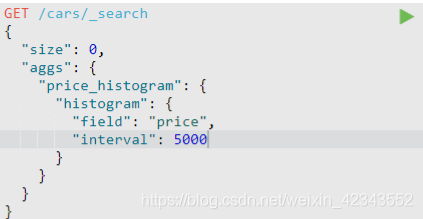
阶梯分组聚合


















 2171
2171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









