







 本文深入介绍了Ceph存储系统中的OSDMap和PGMap概念,详细阐述了OSDMap的机制,包括OSD状态变化、OSDMap更新和传播、OSDMap数据结构,以及PG的创建、删除和迁移过程。同时,文章还探讨了OSDMap在监控OSD状态和PG分布中的关键作用,以及OSDMap在集群扩展和故障恢复中的重要性。
本文深入介绍了Ceph存储系统中的OSDMap和PGMap概念,详细阐述了OSDMap的机制,包括OSD状态变化、OSDMap更新和传播、OSDMap数据结构,以及PG的创建、删除和迁移过程。同时,文章还探讨了OSDMap在监控OSD状态和PG分布中的关键作用,以及OSDMap在集群扩展和故障恢复中的重要性。
目录
作者bandaoyu,随时更新本文链接:https://blog.youkuaiyun.com/bandaoyu/article/details/123097837
本文主要介绍ceph分布式存储架构中OSDMap和PGMap的原理及相关重要信息。
什么是OSDMap 和 PGMap
(摘自:https://blog.51cto.com/wendashuai/2511361,源文:Analizar Ceph: OSD, OSDMap y PG, PGMap - programador clic)
Monitor 作为Ceph的 Metada Server 维护了集群的信息,它包括了6个 Map,分别是 MONMap,OSDMap,PGMap,LogMap,AuthMap,MDSMap。其中 PGMap 和 OSDMap 是最重要的两张Map,本文会重点介绍。
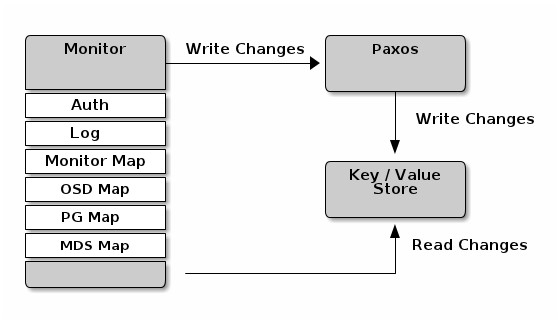
OSDMap
OSDMap 是 Ceph 集群中所有 OSD 的信息,所有 OSD 状态的改变如进程退出,OSD的加入和退出或者OSD的权重的变化都会反映到这张 Map 上。这张 Map 不仅会被 Monitor 掌握,OSD 节点和 Client 也会从 Monitor 得到这张表,因此实际上我们需要处理所有 “Client” (包括 OSD,Monitor 和 Client)的 OSDMap 持有情况。
实际上,每个 “Client” 可能会具有不同版本的 OSDMap,当 Monitor 所掌握的权威 OSDMap 发生变化时,它并不会发送 OSDMap 给所有 “Client” ,而是需要那些感知到集群变化的 “Client” 会被 Push,比如一个新的 OSD 加入集群会导致一些 PG 的迁移,那么这些 PG 的 OSD 会得到通知。除此之外,Monitor 也会随机的挑选一些 OSD 发送 OSDMap。
那么如何让 OSDMap 慢慢传播呢?
比如 OSD.a, OSD.b得到了新的 OSDMap,那么 OSD.c 和 OSD.d 可能部分 PG 也会在 OSD.a, OSD.b 上,这时它们的通信就会附带上 OSDMap 的 epoch,如果版本较低,OSD.c 和 OSD.d 会主动向 Monitor pull OSDMap,而部分情况 OSD.a, OSD.b 也会主动向 OSD.c 和 OSD.d push 自己的 OSDMap (如果更新)。因此,OSDMap 会在接下来一段时间内慢慢在节点间普及。在集群空闲时,很有可能需要更长的时间完成新 Map的更新,但是这并不会影响 OSD 之间的状态一致性,因为OSD没有得到新的Map,所以它们不需要知晓新的OSDMap变更。
Ceph 通过管理多个版本的 OSDMap 来避免集群状态的同步,这使得 Ceph 丝毫不会畏惧在数千个 OSD 规模的节点变更,而导致集群可能出现的状态同步的问题。
新OSD启动OSDMap的变化
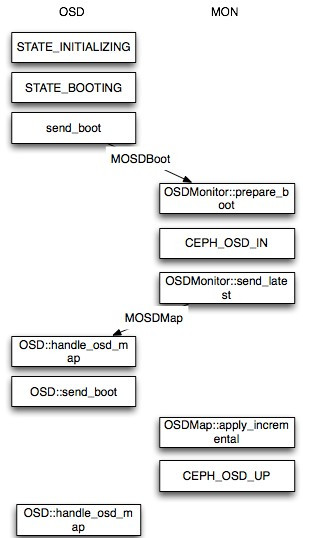
当一个新的 OSD 启动时,这时 Monitor 的最新 OSDMap 并没有该 OSD 的情况,因此该 OSD 会向 Monitor 申请加入,Monitor 在验证其信息后会将其加入 OSDMap 并标记为IN,并且将其放在 Pending Proposal 中会在下一次 Monitor “讨论”中提出,OSD 在得到 Monitor 的回复信息后发现自己仍然没在 OSDMap 中会继续尝试申请加入,接下来 Monitor 会发起一个 Proposal ,申请将这个 OSD 加入 OSDMap 并且标记为 UP 。然后按照 Paxos 的流程,从 proposal->accept->commit 到最后达成一致,OSD 最后成功加入 OSDMap 。当新的 OSD 获得最新 OSDMap 发现它已经在其中时。这时,OSD 才真正开始建立与其他OSD的连接,Monitor 接下来会开始给他分配PG。
OSD crash
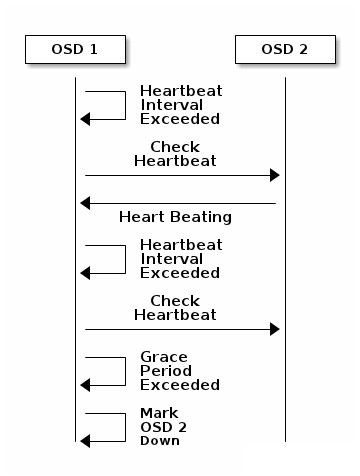
图C: OSD down过程
当一个 OSD 因为意外 crash 时,其他与该 OSD 保持 Heartbeat 的 OSD 都会发现该 OSD 无法连接,在汇报给 Monitor 后,该 OSD 会被临时性标记为 OUT,所有位于该 OSD 上的 Primary PG 都会将 Primary 角色交给其他 OSD(下面会解释)。
PG 和 PGMap
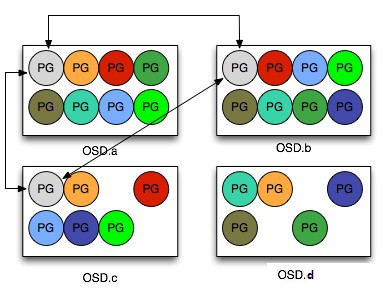
图D: PG和PGMap
PG(Placement Group)是 Ceph 中非常重要的概念,它可以看成是一致性哈希中的虚拟节点,维护了一部分数据并且是数据迁移和改变的最小单位。它在 Ceph 中承担着非常重要的角色,在一个 Pool 中存在一定数量的 PG (可动态增减),这些 PG 会被分布在多个 OSD ,分布规则可以通过 CRUSH RULE 来定义。
Monitor 维护了每个Pool中的所有 PG 信息,比如当副本数是三时,这个 PG 会分布在3个 OSD 中,其中有一个 OSD 角色会是 Primary ,另外两个 OSD 的角色会是 Replicated。Primary PG负责该 PG 的对象写操作,读操作可以从 Replicated PG获得。而 OSD 则只是 PG 的载体,每个 OSD 都会有一部分 PG 角色是 Primary,另一部分是 Replicated,当 OSD 发生故障时(意外 crash 或者存储设备损坏),Monitor 会将该 OSD 上的所有角色为 Primary 的 PG 的 Replicated 角色的 OSD 提升为 Primary PG,这个 OSD 所有的 PG 都会处于 Degraded 状态。然后等待管理员的下一步决策,所有的 Replicated 如果原来的 OSD 无法启动, OSD 会被踢出集群,这些 PG 会被 Monitor 根据 OSD 的情况分配到新的 OSD 上。
PG的peering过程
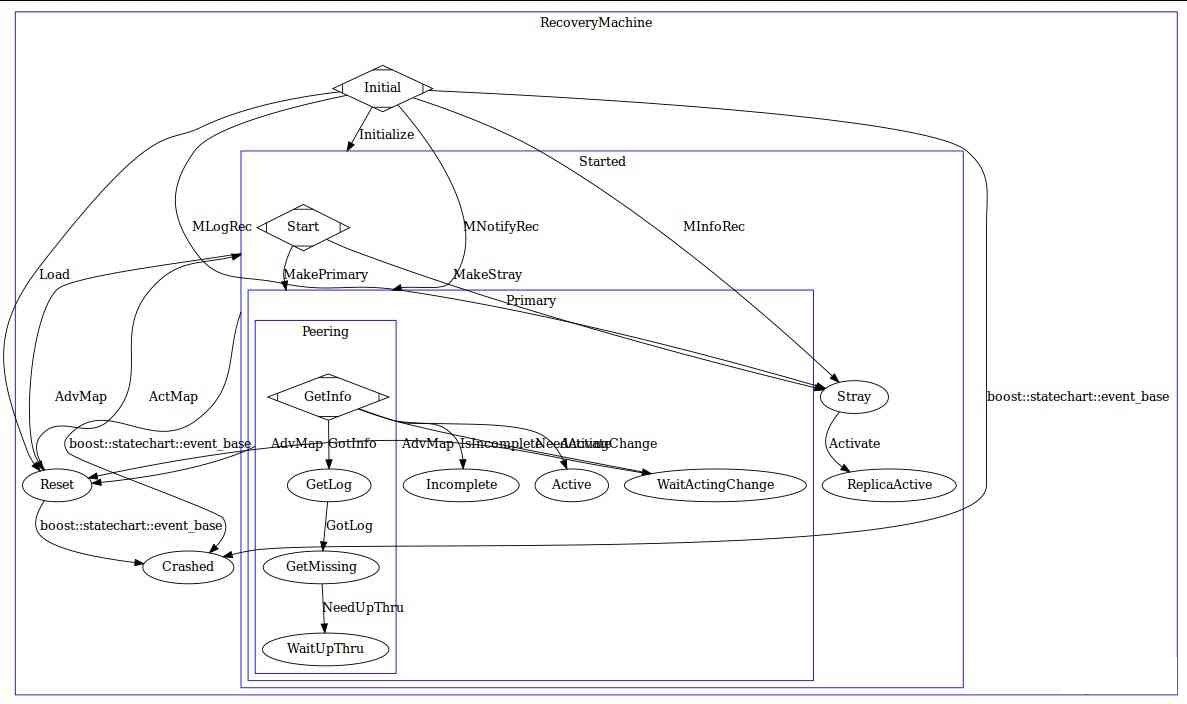
图E: PG的peering过程
在 Ceph 中,PG 存在多达十多种状态和数十种事件的状态机去处理 PG 可能面临的异常, Monitor 掌握了整个集群的 OSD 状态和 PG 状态,每个PG都是一部分 Object 的拥有者,维护 Object 的信息也每个 PG 的责任,Monitor 不会掌握 Object Level 的信息。因此每个PG都需要维护 PG 的状态来保证 Object 的一致性。但是每个 PG 的数据和相关故障恢复、迁移所必须的记录都是由每个 PG 自己维护,也就是存在于每个 PG 所在的 OSD 上。
PGMap 是由 Monitor 维护的所有 PG 的状态,每个 OSD 都会掌握自己所拥有的 PG 状态,PG 迁移需要 Monitor 作出决定然后反映到 PGMap 上,相关 OSD 会得到通知去改变其 PG 状态。在一个新的 OSD 启动并加入 OSDMap 后,Monitor 会通知这个OSD需要创建和维护的 PG ,当存在多个副本时,PG 的 Primary OSD 会主动与 Replicated 角色的 PG 通信并且沟通 PG 的状态,其中包括 PG 的最近历史记录。通常来说,新的 OSD 会得到其他 PG 的全部数据然后逐渐达成一致,或者 OSD 已经存在该 PG 信息,那么 Primary PG 会比较该 PG 的历史记录然后达成 PG 的信息的一致。这个过程称为 Peering ,它是一个由 Primary PG OSD 发起的“讨论”,多个同样掌握这个 PG 的 OSD 相互之间比较 PG 信息和历史来最终协商达成一致。
OSDMap 机制浅析
(摘自:https://cloud.tencent.com/developer/article/1664568)
OSDMap 机制是 Ceph 架构中非常重要的部分,PG 在 OSD 上的分布和监控由 OSDMap 机制执行。OSDMap 机制和 CRUSH 算法一起构成了 Ceph 分布式架构的基石。
OSDMap 机制主要包括如下3个方面:
1、Monitor 监控 OSDMap 数据,包括 Pool 集合,副本数,PG 数量,OSD 集合和 OSD 状态。
2、OSD 向 Monitor 汇报自身状态,以及监控和汇报 Peer OSD 的状态。
3、OSD 监控分配到其上的 PG , 包括新建 PG , 迁移 PG , 删除 PG 。
在整个 OSDMap 机制中,OSD充分信任 Monitor, 认为其维护的 OSDMap 数据绝对正确,OSD 对 PG 采取的所有动作都基于 OSDMap 数据,也就是说 Monitor 指挥 OSD 如何进行 PG 分布。
在 OSDMap 数据中 Pool 集合,副本数,PG 数量,OSD 集合这 4 项由运维人员来指定,虽然 OSD 的状态也可以由运维人员进行更改,但是实际运行的 Ceph 集群 A 中,从时间分布来看,运维人员对 Ceph 集群进行介入的时间占比很小,因此 OSD 的故障(OSD 状态)才是 Monitor 监控的主要目标。
OSD 故障监控由 Monitor 和 OSD 共同完成,在 Monitor 端,通过名为 OSDMonitor 的 PaxosService 线程实时的监控 OSD 发来的汇报数据(当然,也监控运维人员对 OSDMap 数据进行的操作)。在 OSD 端,运行一个 Tick 线程,一方面周期性的向 Monitor 汇报自身状态;另外一方面,OSD 针对 Peer OSD 进行 Heartbeat 监控,如果发现 Peer OSD 故障,及时向 Monitor 进行反馈。具体的 OSD 故障监控细节本文不做分析。
OSDMap 机制中的第1点和第2点比较容易理解,下面本文主要针对第3点进行详细分析。
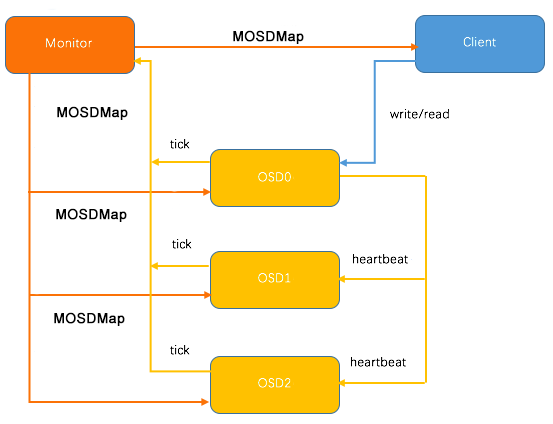
如上图所示,在3个 OSD 的 Ceph 集群中,Pool 的副本数为3,某个 PG 的 Primary OSD 为 OSD0, 当 Monitor 检测到 3 个 OSD 中的任何一个 OSD 故障,则发送最新的 OSDMap 数据到剩余的 2 个 OSD 上,通知其进行相应的处理。
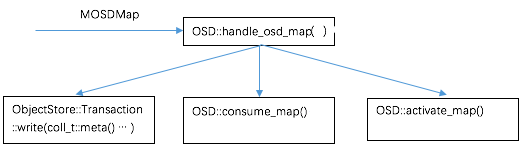
如上图所示,OSD 收到 MOSDMap 后,主要进行3个方面的处理
- ObjectStore::Transaction::write(coll_t::meta()) 更新 OSDMap 到磁盘,保存在目录 /var/lib/ceph/OSD/ceph-<id>/current/meta/,将 OSDMap 数据持久化,起到类似于 log 的作用。
- OSD::consume_map() 进行 PG 处理,包括删除 Pool 不存在的 PG; 更新 PG epoch(OSDmap epoch) 到磁盘(LevelDB); 产生 AdvMap 和 ActMap 事件,触发 PG 的状态机 state_machine 进行状态更新。
- OSD::activate_map() 根据需要决定是否启动 recovery_tp 线程池进行 PG 恢复。
在OSD端,PG 负责 I/O 的处理,因此 PG 的状态直接影响着 I/O,而 pgstate_machine 就是 PG 状态的控制机制,但里面的状态转换十分的复杂,这里不做具体分析。
下面开始分析 PG 的创建,删除,迁移
PG 的创建由运维人员触发,在新建 Pool 时指定 PG 的数量,或增加已有的 Pool 的 PG 数量,这时 OSDMonitor 监控到 OSDMap 发生变化,发送最新的 MOSDMap 到所有的 OSD。
在 PG 对应的一组 OSD 上,OSD::handle_pg_create() 函数在磁盘上创建 PG 目录,写入 PG 的元数据,更新 Heartbeat Peers 等操作。
PG 的删除同样由运维人员触发,OSDMonitor 发送 MOSDMap 到 OSD, 在 PG 对应的一组 OSD 上,OSD::handle_PG _remove() 函数负责从磁盘上删除PG 所在的目录,并从 PGMap 中删除 PG ,删除 PG 的元数据等操作。
PG 迁移较为复杂,涉及到两个OSD与monitor的协同处理。例如,向已有3个OSD的集群中新加入OSD3,导致 CRUSH 重新分布 PG , 某个 PG 的分配变化结果为 [0, 1, 2 ] -> [3, 1, 2]。当然,CRUSH 的分
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









