




 本文详细介绍正则表达式的应用场景及使用方法,包括如何验证手机号码、邮箱地址、身份证号码等常见需求,并通过实例演示了如何用Python进行数据抓取与处理。
本文详细介绍正则表达式的应用场景及使用方法,包括如何验证手机号码、邮箱地址、身份证号码等常见需求,并通过实例演示了如何用Python进行数据抓取与处理。
场景
在发短信前应该先来验证一下手机号码是不是正确
邮箱地址
身份证号码
爬虫
访问一个网页, 网页源代码
对于python来说,是一串字符串
从一大段文字当中提取你想要的数据
正则表达式的常见使用场景
1 判断某一个字符串是否符合规则 注册页 判断手机号,身份证号是否合法
2 将符合规则的内容从一个庞大的字符串体系当中提取出来 爬虫,日志分析
什么是正则表达式,只和字符串打交道
是一种规则来约束字符串的规则
[1234567890]
字符组 是元字符中的一个
在字符组中所有的字符都可以匹配任意一个字符位置上能出现的内容
如果在字符串中有任意一个字符是字符组中的内容,那么就是匹配上的项
[0-9]
[a-z]
[A-Z]
ascii编码小的值指向一个大的值
[0-9a-zA-Z]
[1-9][0-9]
\d表示匹配一个数字 [0-9]
元字符 就是一个字符的意思如一个字母,数字,标点符号,
\w word \W # \是转义的意思,把这些东西转化为对应的值
\d digit \D
\s space \S
\n next
\t tab
元字符
\w \d \s \W \D \S \n \t 匹配特殊字符
^ $ \b 匹配边界 ^匹配开始 $ 匹配结尾
[] [^] 字符组相关的 # [^]非字符组中的字符
| 或
() 分组 括号里面的是一组 整体来看
. 匹配除了换行符以外的任意字符
量词
? + * {n} {n,} {n,m}
\d+整数
\d+\.\d+ 小数
\d+\.\d+|\d+ 整数或小数
\d+(\.\d+)?
贪婪匹配: 正则会尽量多得帮我们匹配
默认贪婪:回溯算法
非贪婪匹配: 会尽量少的为我们匹配
量词?表示非贪婪,惰性匹配
身份证号码是一个长度为15或18个字符的字符串
如果是15位则全部是数字组成,首位不能为0 [1-9]\d{14}
如果是18位,首位不能为0 前17位全部是数字,末位可能是数字或x [1-9]\d{16}[\dx]
[1-9]\d{16}[\dx]|[1-9]\d{14}
[1-9]\d{14}(\d{2}{\dx]})?
匹配网址
www\.(baidu)\.com
元字符
元字符 量词
?在量词的范围内尽量少的匹配这个元字符
或把长的放前面
转义符
pattern = r'\\n'
s = r'\n'
例
# 1、匹配整数或者小数(包括正数和负数)
import re
ret = re.findall('(?:\-)?\d+(?:\.\d+)?', '854ffd96fdds-86yte-8.34dgf9.76') #
print(ret)
# ['854', '96', '-86', '-8.34', '9.76']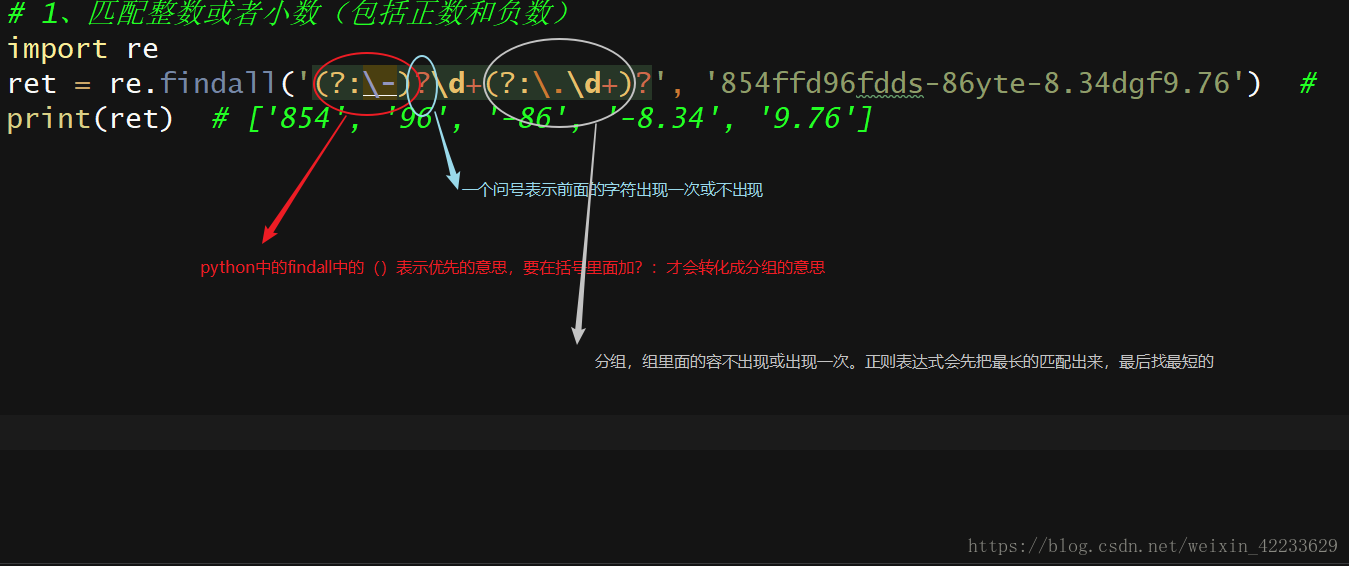

















 2971
2971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









