




简介:哈夫曼编码是一种无损数据压缩技术,通过构建哈夫曼树为字符分配独特二进制编码。本文将详细阐述如何使用C++语言实现哈夫曼编码的过程,并以英文字母权值处理为例,引导读者理解哈夫曼树的构建原理和编码步骤。通过统计每个字母的出现频率,我们可以为它们分配权值,并构建相应的哈夫曼树来生成编码。最终,我们将编码后的数据存储在映射表中,以实现高效的数据压缩。此外,提供的压缩包文件将帮助读者更好地理解哈夫曼编码的构造和应用。 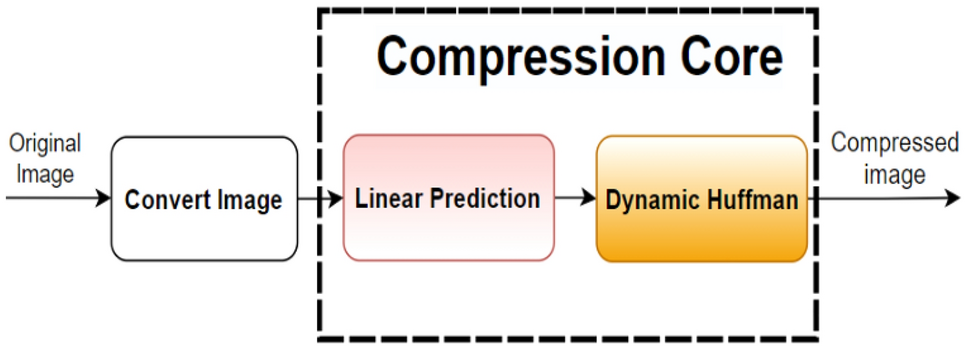
1. 哈夫曼编码原理与应用
简介
哈夫曼编码(Huffman Coding)是一种广泛应用于数据压缩的算法,它通过为不同的字符分配不同长度的二进制位,有效地减少了数据的存储空间。哈夫曼编码能够提供一种最优的前缀编码方法,使得编码的平均长度最短,从而达到压缩数据的目的。
哈夫曼编码的工作原理
哈夫曼编码的核心在于构造一棵哈夫曼树,这棵树依据字符的频率来构建。每个字符都会对应树上的一个叶子节点,而字符的频率则对应节点的权重。在编码过程中,频率高的字符会被分配较短的二进制代码,频率低的字符分配较长的代码,从而实现了压缩。
哈夫曼编码的应用
哈夫曼编码在数据压缩领域有着广泛的应用,它不仅被用在传统的文件压缩软件中,如ZIP和RAR格式的压缩工具,还被应用在数字信号处理、图像压缩(如JPEG标准)等领域。通过在数据压缩中使用哈夫曼编码,可以显著降低存储成本并提高传输效率。
在下一章中,我们将详细介绍构建哈夫曼树的过程,包括基本概念、算法流程和实例分析。
2. 构建哈夫曼树的过程
2.1 哈夫曼树的基本概念
2.1.1 树的定义与特性
在计算机科学中,树是一种广泛应用于数据组织的非线性数据结构,它模仿了自然界中的树木结构。树由节点(Node)和边(Edge)组成,节点间通过边连接,形成一个层次化的结构。树的每个节点都有一个值(Value)和若干个子节点(Children)。在哈夫曼树中,节点的值通常对应着数据中的字符频率或权重。
树的一些基本概念包括:
- 根节点(Root):没有父节点的节点,位于树的顶部。
- 叶节点(Leaf):没有子节点的节点,位于树的底部。
- 内部节点(Internal Node):至少有一个子节点的节点。
- 子树(Subtree):由节点及其后代组成的子集。
哈夫曼树的特点是:
- 它是一棵二叉树,即每个节点最多有两个子节点。
- 它是一棵带权路径长度最短的树,即权重与路径长度乘积的总和最小。
- 它的叶节点代表了待编码的字符,而内部节点表示合并的过程。
2.1.2 权重在树中的作用
在哈夫曼树中,权重通常与节点所代表的字符出现的频率成正比。构建哈夫曼树的过程是一个贪心算法的过程,目的是最小化整个树的带权路径长度(WPL)。带权路径长度是指树中所有叶节点的权重乘以其到根节点路径长度的总和。
权重在哈夫曼树构建过程中起到了决定性的作用,它指导了树的构建方向:
- 在每一步合并中,总是选择权重最小的两个节点合并成一个新的节点。
- 新节点的权重是两个子节点权重的和,这保证了树始终朝着带权路径长度最小的方向生长。
- 权重的合理分配可以显著地提高编码效率和压缩比率。
2.2 构建哈夫曼树的算法流程
2.2.1 算法的基本步骤
构建哈夫曼树的基本步骤如下:
- 创建一个优先队列(通常是最小堆),将所有字符及其频率作为叶节点插入队列中。
- 当队列中的节点数大于1时,执行以下操作:
- 从队列中取出两个权重最小的节点作为子节点。
- 创建一个新的内部节点,其权重为两个子节点权重之和。
- 将取出的两个节点设置为新节点的子节点。
- 将新节点插入优先队列中。
- 重复步骤2,直到队列中只剩下一个节点,这个节点即为哈夫曼树的根节点。
2.2.2 算法的时间复杂度分析
哈夫曼树的构建算法的时间复杂度取决于所使用的数据结构。在理想情况下,使用最小堆作为优先队列时,每次插入和删除操作的时间复杂度为O(log n),其中n是队列中的元素数量。由于构建哈夫曼树需要进行n-1次合并操作,因此整个算法的时间复杂度为O(n log n)。
2.2.3 算法的正确性证明
哈夫曼树的正确性可以通过数学归纳法来证明。基本的证明思路是:
- 归纳假设 :假设对于包含k个字符的子集,能够构建出一棵带权路径长度最小的最优树T。
- 归纳步骤 :证明当增加第k+1个字符时,仍然能够构建出一棵最优的哈夫曼树。
- 由归纳假设,前k个字符已经构成了最优树T。
- 增加的第k+1个字符与T中权重最小的两个节点合并,形成新的树T'。
- 证明T'的带权路径长度小于等于T加上新字符的权重,即WPL(T') <= WPL(T) + weight(char k+1)。
2.3 哈夫曼树构建的实例分析
2.3.1 具体案例的构建过程
假设我们有一组字符及其对应的频率如下:
- A: 5次
- B: 9次
- C: 12次
- D: 13次
- E: 16次
- F: 45次
构建哈夫曼树的步骤为:
- 将字符按照频率插入优先队列。
- 取出A和B,合并为一个新节点AB(频率为14),再将新节点插入优先队列。
- 取出AB和C,合并为一个新节点ABC(频率为26),再将新节点插入优先队列。
- 取出ABC和D,合并为一个新节点ABCD(频率为39),再将新节点插入优先队列。
- 取出ABCD和E,合并为一个新节点ABCDE(频率为55),再将新节点插入优先队列。
- 取出ABCDE和F,合并为一个新节点ABCDEF(频率为100),这是哈夫曼树的根节点。
最终构建出的哈夫曼树如下图所示:
graph TD
root(ABCDE100)
root --> abcd(ABCD39)
root --> f(F45)
abcd --> abc(ABC26)
abcd --> e(E13)
abc --> ab(AB14)
abc --> c(C12)
ab --> a(A5)
ab --> b(B9)
2.3.2 案例中可能出现的问题及解决方法
在构建哈夫曼树的过程中,可能遇到的问题包括:
- 优先队列的实现问题 :如果优先队列实现不当,可能会导致算法运行时间增加。解决方法是使用标准库中的优先队列,并确保所有节点的比较基于权重进行。
- 权重相同节点的处理 :如果两个节点权重相同,则可以根据需要选择任意节点进行合并,或者调整数据结构来避免这种情况。
- 内存管理问题 :在手动管理内存时,可能会出现内存泄漏或野指针。解决方法是使用智能指针来自动管理内存。
通过合理地处理这些问题,可以确保哈夫曼树的构建过程既高效又准确。
3. 哈夫曼编码表的生成与存储
3.1 哈夫曼编码表的生成原理
3.1.1 编码表的重要性
哈夫曼编码表是哈夫曼编码算法的核心组成部分,它记录了待编码字符及其对应的二进制编码。这种编码表的重要性在于其无歧义性和前缀性质,使得编码和解码过程高效且准确。无歧义性确保了编码后的数据能够被无损地还原,而前缀性质则保证了在解码过程中不需要额外的分隔符来区分各个字符的编码,从而在数据传输和存储中节省了空间和带宽。
3.1.2 编码表生成的具体步骤
编码表的生成遵循特定的步骤:
- 首先对输入数据中的字符进行统计,并计算每个字符出现的频率。
- 根据字符频率构建哈夫曼树,其中字符作为叶节点,频率作为权重。
- 然后从哈夫曼树中自底向上生成编码,从根节点到叶节点的路径上,左分支代表0,右分支代表1。
- 每个字符的编码就是从根节点到该字符节点路径上的二进制序列。
- 最后,将生成的编码序列与其对应的字符整理成表,即哈夫曼编码表。
生成过程可以通过以下伪代码表示:
function GenerateHuffmanCodeTable(inputData):
# 统计字符频率
frequencyMap = CalculateFrequency(inputData)
# 构建哈夫曼树
huffmanTree = BuildHuffmanTree(frequencyMap)
# 生成编码表
codeTable = {}
GenerateCodesFromTree(huffmanTree.root, "", codeTable)
return codeTable
3.2 编码表在数据压缩中的应用
3.2.1 数据压缩的基本原理
数据压缩是指减少数据的表示所需的比特数,同时尽量保持数据的完整性和可恢复性。基本原理是消除数据中的冗余部分,即重复或可预测的信息。压缩可以通过无损压缩和有损压缩两种方式进行,哈夫曼编码属于无损压缩技术。无损压缩算法保证压缩后的数据可以完全还原成原始数据,而有损压缩则允许一定程度的信息丢失,以达到更高的压缩比。
3.2.2 编码表如何提高压缩效率
哈夫曼编码表通过为出现频率高的字符分配较短的二进制编码,为出现频率低的字符分配较长的编码,从而实现整体数据的压缩。这种不等长的编码策略,使得平均编码长度小于或等于输入数据的熵(信息量的度量),从而达到压缩数据的目的。
在数据压缩的应用中,编码表通常以特定格式存储,以便压缩和解压缩时使用。存储格式的设计直接影响到压缩和解压缩的效率。优化存储格式可以减少编码表的存储空间需求,并提高编码和解码的速度。
3.3 编码表存储的优化策略
3.3.1 存储空间的优化
为了减少编码表的存储空间,可以采用以下优化策略:
- 差分编码 :存储字符编码与其前一个字符编码的差值,而不是整个编码。
- 霍夫曼编码 :使用自身的霍夫曼编码来压缩编码表,形成压缩后的压缩表。
- 索引访问 :对于大型数据集,使用索引树或散列表等数据结构来快速访问编码表项。
例如,可以将连续的编码值用差分表示,以减少存储位数。
3.3.2 存取效率的优化
存取效率的优化关系到数据压缩和解压的速度,可以采取以下措施:
- 树状结构存储 :利用前缀树(Trie)或二叉搜索树(BST)等树状结构,快速定位字符编码。
- 哈希表快速访问 :将字符编码映射到哈希表中,通过字符直接访问其编码,减少搜索时间。
- 内存映射文件 :利用内存映射文件技术,将大文件映射到内存中,直接操作内存以加快访问速度。
例如,可以使用哈希表来存储编码和字符的映射关系:
hashTable = {
"char1": "0",
"char2": "10",
...
}
这样,当需要查找字符的编码时,可以直接通过字符键来获取值,而不需要遍历整个表。
4. C++实现哈夫曼编码的方法
4.1 C++编程基础与哈夫曼编码的结合
4.1.1 C++基本语法回顾
在深入讨论如何用C++实现哈夫曼编码之前,我们先来回顾一下C++的一些基础语法。C++是一种静态类型、编译式、通用的编程语言,支持多种编程范式,包括面向对象、泛型和过程式编程。C++提供了丰富的数据类型和操作符,以及类和对象的概念,能够实现高度的代码复用和模块化。理解指针、引用、动态内存管理等概念对于编写高效的C++程序至关重要。
例如,C++中的类和对象允许程序员封装数据和函数,这样就可以创建可重用和易于维护的代码模块。以下是一个简单的类定义示例:
class HuffmanNode {
public:
char data; // 存储字符
int frequency; // 字符频率
HuffmanNode* left, * right; // 左右子树指针
};
在这个简单的例子中,我们定义了一个名为 HuffmanNode 的类,它代表哈夫曼树中的一个节点,并包含字符、频率和指向其左右子节点的指针。
4.1.2 哈夫曼编码算法在C++中的实现
哈夫曼编码算法的C++实现涉及到多个步骤,包括构建哈夫曼树、生成编码表和编码原始数据。在C++中,我们通常会使用类来表示哈夫曼树中的节点,并利用递归函数来构建整个树。之后,我们可以通过深度优先遍历或广度优先遍历来生成编码表。
下面是构建哈夫曼树的一个简化的C++函数示例:
void buildHuffmanTree(HuffmanNode* root, char data, int freq) {
root = new HuffmanNode();
root->data = data;
root->frequency = freq;
root->left = root->right = nullptr;
}
void mergeNodes(HuffmanNode** root) {
// 该函数用于合并两个最小频率的节点,并更新树的根节点
// 具体代码实现略
}
在这个例子中, buildHuffmanTree 函数用于创建一个新的节点,并初始化其数据和频率。 mergeNodes 函数则用于将两个节点合并成一个新的节点,这是构建哈夫曼树过程中的关键步骤。
4.2 C++实现中的关键技巧
4.2.1 内存管理和指针的使用
在使用C++实现哈夫曼编码时,合理管理内存至关重要,特别是涉及到大量动态分配的节点时。正确使用指针和动态内存分配可以保证内存的正确释放,避免内存泄漏。C++11引入的智能指针(如 std::unique_ptr 和 std::shared_ptr )可以自动管理内存,简化了内存管理的过程。
#include <memory>
std::unique_ptr<HuffmanNode> createNode(char data, int freq) {
return std::make_unique<HuffmanNode>(HuffmanNode{data, freq, nullptr, nullptr});
}
在这个例子中,我们使用 std::make_unique 来创建一个 HuffmanNode 的智能指针,这样就不需要手动释放内存。
4.2.2 类和对象在哈夫曼编码中的应用
类和对象在实现哈夫曼编码算法时发挥着关键作用。我们定义的 HuffmanNode 类可以用来表示哈夫曼树的节点,而哈夫曼树本身可以作为一个类的实例存在,其中包含构建树和生成编码的方法。例如:
class HuffmanTree {
public:
HuffmanNode* root;
HuffmanTree(std::vector<std::pair<char, int>> frequencyList) {
// 构建哈夫曼树
}
void generateCodes() {
// 生成哈夫曼编码
}
// 其他方法...
};
在这个类定义中,我们包含了哈夫曼树的根节点和一个构造函数,该构造函数接收一个字符及其频率的列表,并构建出哈夫曼树。 generateCodes 方法用于生成编码表。
4.3 C++实现哈夫曼编码的完整案例
4.3.1 案例代码展示与分析
接下来,我们将展示一个完整的案例代码,用于构建哈夫曼树并生成编码表。为了保持简洁性,我们只展示了核心方法的框架,实际代码会更加详细。
#include <iostream>
#include <vector>
#include <queue>
#include <map>
#include <algorithm>
// 假设我们已经定义了HuffmanNode和HuffmanTree类
int main() {
// 示例字符频率列表
std::vector<std::pair<char, int>> frequencyList = {
{'a', 5}, {'b', 9}, {'c', 12}, {'d', 13}, {'e', 16}, {'f', 45}
};
HuffmanTree tree(frequencyList);
// 构建哈夫曼树
tree.buildTree();
// 生成编码表
std::map<char, std::string> codes = tree.generateCodes();
// 打印编码表
for (const auto& pair : codes) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
return 0;
}
在这个例子中,我们首先创建了一个 HuffmanTree 对象,并传入了一个包含字符及其频率的列表。接着,我们调用 buildTree 方法构建哈夫曼树,最后通过 generateCodes 方法生成编码表,并打印出来。
4.3.2 案例中的调试和性能评估
调试和性能评估是确保代码质量的重要环节。调试过程中,我们应该确保所有边界条件都被测试,并且代码能够正确地处理各种异常情况。性能评估则需要我们对算法的执行时间、空间复杂度进行分析,确保算法在实际应用中能够高效运行。
例如,我们可以通过插入跟踪代码来打印出每个函数的执行时间,或者使用计时器来测量整个哈夫曼编码过程的耗时。代码中还可以加入断言(assert)来确保某些条件在运行时为真,从而帮助我们及早发现错误。
此外,性能优化可能涉及到数据结构的选择,例如使用优先队列来优化构建哈夫曼树的过程,以及合理地设计数据结构来最小化内存占用和提高数据访问效率。
通过上述案例分析,我们不仅了解了如何用C++实现哈夫曼编码,还学会了如何管理和优化内存、如何使用类和对象以及如何进行调试和性能评估。这些技巧和概念对于C++编程的其他领域同样适用,是每个C++程序员的宝贵财富。
5. 使用优先队列构建哈夫曼树
5.1 优先队列的数据结构分析
5.1.1 优先队列的基本原理
优先队列是一种特殊类型的队列,其特点是在进行删除操作时,优先取出其中优先级最高(或最低)的元素。在哈夫曼树的构建过程中,优先队列通常用来存储树中的节点,并且按照节点的权重(频率)进行排序,从而每次都能选取最小(或最大)权重的节点进行合并。优先队列在C++中的实现通常是基于堆(Heap)这种数据结构。
5.1.2 优先队列在哈夫曼树构建中的作用
在构建哈夫曼树时,我们需要多次从一组节点中选出两个权重最小的节点进行合并,以生成新的内部节点。如果没有使用优先队列,这一过程将变得非常繁琐,因为我们可能需要对节点集合进行多次排序。优先队列大大简化了这一过程,因为它的插入和删除操作可以在对数时间内完成,大大提高了构建效率。
5.2 优先队列的实现及其优化
5.2.1 标准库优先队列的使用
在C++标准库中, priority_queue 是一个容器适配器,它提供了一个优先队列的功能。默认情况下,优先队列基于最大堆实现,即最大的元素总是位于队列的前端。使用标准库优先队列实现哈夫曼树构建的基本步骤如下:
- 定义一个节点结构体,包含权重、字符以及指向左右子节点的指针。
- 将所有叶子节点(字符节点)添加到优先队列中。
- 当优先队列中的元素数量大于1时,循环执行以下操作:
- 弹出两个最小权重的节点,创建一个新的内部节点作为它们的父节点。
- 新节点的权重设置为两个子节点权重之和。
- 将新节点压入优先队列。
- 当优先队列中只剩一个元素时,该元素即为哈夫曼树的根节点。
5.2.2 自定义优先队列的优化策略
虽然标准库中的优先队列已经非常高效,但在某些场景下,为了进一步优化性能,我们可能会选择自定义优先队列的实现。优化策略可能包括:
- 使用多个优先队列来分别处理不同权重范围的节点,这可以减少整体的排序次数。
- 优化节点比较操作,通过减少比较次数来提高效率。
- 使用基于四叉堆或配对堆的优先队列实现来替代标准库的二叉堆,以期获得更好的时间复杂度。
5.3 优先队列在哈夫曼编码中的应用实例
5.3.1 实例代码解析
以下是一个使用C++标准库中的 priority_queue 来构建哈夫曼树的示例代码:
#include <iostream>
#include <queue>
#include <vector>
struct Node {
char data;
unsigned freq;
Node *left, *right;
Node(char data, unsigned freq) {
left = right = nullptr;
this->data = data;
this->freq = freq;
}
};
struct Compare {
bool operator()(Node* l, Node* r) {
return l->freq > r->freq;
}
};
void printCodes(struct Node* root, std::string str) {
if (!root) return;
if (root->data != '$') {
std::cout << root->data << ": " << str << "\n";
}
printCodes(root->left, str + "0");
printCodes(root->right, str + "1");
}
void HuffmanCodes(char data[], int freq[], int size) {
struct Node *left, *right, *top;
std::priority_queue<Node*, std::vector<Node*>, Compare> minHeap;
for (int i = 0; i < size; ++i) {
minHeap.push(new Node(data[i], freq[i]));
}
while (minHeap.size() != 1) {
left = minHeap.top();
minHeap.pop();
right = minHeap.top();
minHeap.pop();
top = new Node('$', left->freq + right->freq);
top->left = left;
top->right = right;
minHeap.push(top);
}
printCodes(minHeap.top(), "");
}
int main() {
char arr[] = { 'a', 'b', 'c', 'd', 'e', 'f' };
int freq[] = { 5, 9, 12, 13, 16, 45 };
int size = sizeof(arr) / sizeof(arr[0]);
HuffmanCodes(arr, freq, size);
return 0;
}
5.3.2 应用效果的评估与分析
在上述代码中,我们定义了一个简单的字符集以及对应的频率数组,并成功构建了一个哈夫曼树,最终打印出每个字符对应的哈夫曼编码。通过观察输出,我们可以验证哈夫曼树是否正确构建。
此外,我们可以使用更复杂的数据集来评估代码的性能。在构建哈夫曼树的过程中,优先队列的使用减少了比较和交换的次数,从而优化了整体的时间复杂度。通常情况下,构建哈夫曼树的时间复杂度为O(nlogn),其中n是不同字符的数量。在实际应用中,自定义优先队列的实现可能进一步优化这个时间复杂度,特别是在有大量数据的情况下。
在分析哈夫曼编码的应用实例时,我们可以看到,通过使用优先队列,我们可以快速高效地构建哈夫曼树,并从中生成编码表。这不仅提升了算法的执行效率,也为数据压缩提供了有力的技术支持。
6. 数据压缩技术的实现
6.1 数据压缩技术概述
数据压缩技术是计算机科学中的一个核心分支,旨在减少存储和传输数据所需的资源,从而提高效率。数据压缩通常分为无损压缩和有损压缩两大类。无损压缩保证了数据压缩和解压缩后的信息完全一致,而有损压缩则允许一定程度的信息损失以换取更高的压缩比。
6.1.1 数据压缩的分类和原理
- 无损压缩 :通过发现并利用数据中的冗余信息来减少存储空间。常见的无损压缩算法包括哈夫曼编码、游程编码和LZ77/LZ78等。
- 有损压缩 :在压缩过程中丢弃某些不重要的数据信息,主要应用于多媒体数据(如图像、音频、视频等)。典型的有损压缩算法有JPEG、MP3和MPEG等。
6.1.2 哈夫曼编码在数据压缩中的地位和作用
哈夫曼编码是一种广泛使用的无损数据压缩技术。它依据数据中各个字符的出现频率来构建最优的前缀码,使得压缩后的数据占用的空间最小。哈夫曼编码通过构建一棵特殊的哈夫曼树来实现,其中每个字符都对应一个唯一的二进制编码,高频字符编码较短,低频字符编码较长,从而达到压缩数据的目的。
6.2 数据压缩的具体实现方法
6.2.1 哈夫曼编码与其他压缩算法的比较
哈夫曼编码的一个显著特点是它能够根据数据中字符的实际频率动态地构建最优编码方案。与静态编码(如ASCII)相比,哈夫曼编码在处理具有不同字符频率的数据集时,通常能实现更高的压缩比。
哈夫曼编码与游程编码相比,虽然游程编码在处理具有大量重复字符的数据时非常高效,但对于字符频率分布均匀的数据集,其压缩效率则不如哈夫曼编码。
6.2.2 实现数据压缩的具体步骤和代码展示
以下是使用哈夫曼编码实现数据压缩的一个简化示例,使用C++编程语言:
#include <iostream>
#include <queue>
#include <vector>
#include <map>
struct Node {
char data;
int freq;
Node *left, *right;
Node(char data, int freq) : data(data), freq(freq), left(nullptr), right(nullptr) {}
};
// 优先队列按照频率优先排序
struct Compare {
bool operator()(Node* l, Node* r) {
return l->freq > r->freq;
}
};
// 递归函数来生成哈夫曼编码
void encode(Node* root, std::string str, std::map<char, std::string> &huffmanCode) {
if (!root) return;
if (!root->left && !root->right) {
huffmanCode[root->data] = str;
}
encode(root->left, str + "0", huffmanCode);
encode(root->right, str + "1", huffmanCode);
}
void compressData(const std::string &text) {
std::map<char, int> freqMap;
for (char ch : text) {
freqMap[ch]++;
}
std::priority_queue<Node*, std::vector<Node*>, Compare> minHeap;
for (auto pair : freqMap) {
minHeap.push(new Node(pair.first, pair.second));
}
// 构建哈夫曼树
while (minHeap.size() != 1) {
Node *left = minHeap.top();
minHeap.pop();
Node *right = minHeap.top();
minHeap.pop();
Node *top = new Node('$', left->freq + right->freq);
top->left = left;
top->right = right;
minHeap.push(top);
}
// 生成哈夫曼编码
std::map<char, std::string> huffmanCode;
encode(minHeap.top(), "", huffmanCode);
// 打印哈夫曼编码
for (auto pair : huffmanCode) {
std::cout << pair.first << " " << pair.second << std::endl;
}
}
int main() {
std::string text = "Huffman Coding Example";
compressData(text);
return 0;
}
上述代码首先统计文本中每个字符的频率,然后使用这些频率构建一个哈夫曼树。接着,根据这棵树生成哈夫曼编码,最后输出每个字符对应的编码。
6.3 数据压缩技术的应用前景与挑战
6.3.1 压缩技术在各领域的应用案例
数据压缩技术广泛应用于文件存储、网络传输和多媒体内容处理等领域。例如,ZIP和RAR格式在文件压缩领域的应用,JPEG格式在数字图像压缩领域的应用,以及MP3和AAC格式在数字音频压缩领域的应用。
6.3.2 压缩技术面临的挑战和未来发展趋势
随着数据量的爆炸性增长,数据压缩技术面临的挑战也随之增加,包括如何提高压缩效率、减少压缩和解压缩所需的时间以及适应不同类型的压缩需求。未来的发展趋势可能会包括:
- 优化算法 :改进现有算法以适应更复杂的数据类型和结构。
- 并行处理 :利用多核处理器和分布式计算环境实现压缩算法的并行化,以提高处理速度。
- 自适应压缩 :根据不同数据特点动态调整压缩策略,以达到最优压缩效果。
- 机器学习 :利用机器学习技术进一步优化压缩算法的性能和适应性。
以上章节展示了数据压缩技术的实现原理、具体方法以及未来可能的发展方向。随着技术的进步,我们期待看到更为高效、智能的压缩技术的出现。
简介:哈夫曼编码是一种无损数据压缩技术,通过构建哈夫曼树为字符分配独特二进制编码。本文将详细阐述如何使用C++语言实现哈夫曼编码的过程,并以英文字母权值处理为例,引导读者理解哈夫曼树的构建原理和编码步骤。通过统计每个字母的出现频率,我们可以为它们分配权值,并构建相应的哈夫曼树来生成编码。最终,我们将编码后的数据存储在映射表中,以实现高效的数据压缩。此外,提供的压缩包文件将帮助读者更好地理解哈夫曼编码的构造和应用。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









