




简介:本文档详细解析了Java Development Kit (JDK) 1.6的API,该版本为Java应用程序开发提供了丰富的类库和工具。包含了Java基础类、集合框架、I/O流、网络编程、多线程、反射等核心类库的用法和实践。文档以CHM格式的API.CHM文件形式提供,深入探讨了关键知识点,适用于学习和参考,尤其是在解决遗留系统问题时。 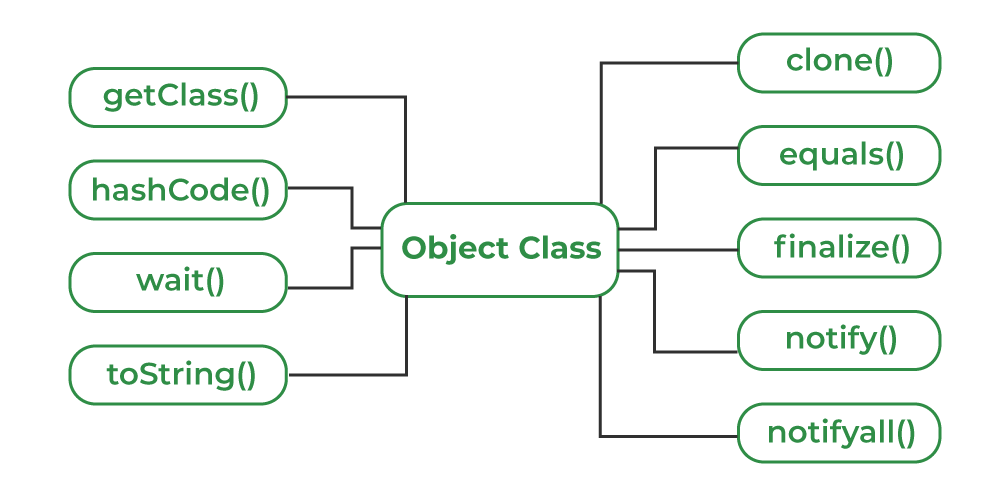
1. JDK 1.6版本概述
1.1 JDK 1.6的新特性
JDK 1.6,也被称为Java SE 6,是2006年发布的Java开发工具包版本,它在早期版本的基础上增加了一系列新特性,旨在简化开发流程,提高开发效率。其中包括了对J2SE 5.0中引入的一些特性的改进,如泛型、枚举类型、注解以及自动装箱和拆箱功能。此外,JDK 1.6还在性能和安全性方面做了大量改进,例如增加了对脚本语言的支持和改进了JVM的性能。
1.2 JDK 1.6的改进点
对于已经熟悉JDK 1.5的开发者来说,JDK 1.6的改进点显著。它引入了"Pluggable Annotation Processing API",这一特性允许开发者更容易地使用注解。同时,JDK 1.6也对Java的诊断和监控能力进行了增强,如引入了JVisualVM这样的工具,使得性能分析和故障排查更加直观和方便。
1.3 JDK 1.6的新增类库和工具
JDK 1.6还带来了一系列新的类库和工具,比如用于处理日志的java.util.logging包,提供了改进的HTTP服务器和客户端API,以及用于数据库访问的JDBC 4.0规范。另外,对于并发控制,添加了java.util.concurrent包,这在多线程和高并发场景中提供了更大的灵活性和性能优势。
总的来说,JDK 1.6在Java平台上引入的许多改进对整个Java社区有着深远的影响。尽管它距今已有一段时间,但许多特性至今仍被广泛使用,为Java开发者的工作提供了极大的便利。
2. 核心类库介绍与用法
2.1 Java核心类库概览
2.1.1 类库结构和组织
Java的核心类库是Java语言强大功能的基石,它为开发者提供了一系列标准的API,以处理各种常见的编程任务。类库按照功能可以划分为多个包,位于Java的 java.* 和 javax.* 命名空间下。其中, java.lang 是基础中的基础,它包含了Java语言的核心类,比如 String 、 Math 和 System ,这些类在编写任何Java程序时几乎都会用到。
以Java 1.6为例, java.util 包下包含了大量工具类,如集合框架、日期和时间的处理工具等; java.io 包则提供了丰富的输入输出处理类,用于实现文件读写、网络通信等; *** 包中的类和接口用于实现网络编程,包括URL和Socket编程等。
类库的组织不仅体现了功能模块的划分,还反映了Java的设计哲学——尽量提供通用工具类库,让开发者免于重复造轮子。
2.1.2 关键类库的发展与变迁
Java核心类库自1.0版本以来,经历了多次重要的更新和扩展。每个新版本的发布,都会引入新的功能,提升性能和安全性,同时改进开发者的工作效率。例如,Java 1.2版本引入了集合框架,大大提高了处理复杂数据结构的能力;Java 1.4版本则增加了日志记录API,方便开发者对应用程序进行监控和故障排查;Java 5(1.5版本)引入了泛型,减少了类型转换的错误,并使代码更加清晰。
在JDK 1.6版本中,核心类库进一步得到了增强,新增了对脚本语言的支持,并且提升了XML处理的能力。通过这些关键更新,JDK 1.6不仅强化了Java平台的稳定性和性能,还扩展了其在企业级应用中的适用范围。
2.2 核心类的详细解析
2.2.1 Object类及其实用方法
在Java中,所有的类都直接或间接地继承自 java.lang.Object 类。Object类提供了几个基本的方法,比如 toString() 、 equals() 和 hashCode() ,这些方法为所有Java对象定义了最起码的行为。
-
toString()方法用于返回对象的字符串表示,便于调试和日志记录。合理的toString()实现能够提供对象的关键信息。 -
equals()方法用于对象比较,是判断两个对象是否逻辑相等的基础。默认实现是基于引用的比较,但在自定义类中,通常需要根据业务逻辑重写此方法。 -
hashCode()方法则用于生成对象的哈希码,它与equals()方法通常需要一起重写,以保持一致的逻辑。
在实际编程中,重写 toString() 、 equals() 和 hashCode() 是常见的需求,尤其在集合操作和日志记录中非常关键。
2.2.2 Class类的反射功能
反射机制允许程序在运行时访问和操作对象的内部状态,而 java.lang.Class 类是Java反射机制的核心。它封装了Java类的元数据,例如类的名称、方法、构造函数、字段等信息。
通过反射,开发者可以动态地创建对象、调用方法、访问字段、获取数组的长度等。这对于框架开发、依赖注入、测试等方面尤其有用。
Class<?> clazz = Class.forName("com.example.MyClass");
Object myObject = clazz.newInstance();
Method method = clazz.getMethod("myMethod");
method.invoke(myObject);
上述代码展示了使用反射机制实例化一个类,并调用其方法的基本步骤。注意,为了安全和性能考虑,反射应当谨慎使用,避免滥用可能导致的安全问题和性能瓶颈。
2.2.3 System类的系统操作
java.lang.System 类提供了一些静态方法和字段,用于访问系统相关的功能。虽然 System 类的使用并不频繁,但它提供的几个工具方法对于系统级别的操作非常有用。
-
System.out、System.err和System.in分别代表标准输出、标准错误输出和标准输入流。 -
System.currentTimeMillis()可以获取当前时间的毫秒值,常用于计算程序执行的时间间隔。 -
System.exit(int status)方法用于终止当前运行的Java虚拟机,status参数表示退出状态。
System类还提供了对环境变量的访问,以及对内存管理的控制,比如垃圾回收器的控制等。
2.3 核心接口与实现
2.3.1 Collection和Map接口及其子接口
Java集合框架提供了用于存储和操作对象集合的接口和实现类。核心接口包括 Collection 、 Set 、 List 、 Map 和 SortedMap 等。
-
Collection是集合框架中所有集合的根接口,定义了基本的增删查等操作。 -
Set接口要求集合中的元素唯一,不允许重复,它主要有HashSet和TreeSet两种实现。 -
List接口是一个有序集合,它维护元素的插入顺序,主要的实现类有ArrayList和LinkedList。 -
Map接口存储键值对,允许快速查找,主要有HashMap和TreeMap等实现。
集合框架的这些接口和实现类构成了构建高效数据管理逻辑的基石,通过这些工具,开发者能够灵活地处理各种数据集合需求。
2.3.2 Comparator和Comparable接口
在Java集合框架中, Comparator 和 Comparable 接口用于定义对象的排序规则。 Comparable 接口通过 compareTo(T o) 方法提供自然排序,而 Comparator 接口则通过 compare(T o1, T o2) 方法实现自定义排序。
Comparable 是类的一种契约,它规定了类对象的自然排序,比如字符串的字典序排序。而 Comparator 则允许在运行时动态地定义排序规则,它更加灵活,比如可以实现逆序排序等。
// 实现Comparable接口的示例
public class Person implements Comparable<Person> {
private String name;
private int age;
@Override
public int compareTo(Person other) {
***pareTo(other.name);
}
}
// 使用Comparator接口
Comparator<Person> comparator = new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
***pare(p1.getAge(), p2.getAge());
}
};
以上代码展示了如何通过实现 Comparable 接口定义自然排序,以及如何使用 Comparator 接口定义自定义排序。通过这些机制,集合框架可以对元素进行排序,提供如 Collections.sort() 等排序方法。
总结
在本章节中,我们深入探讨了Java核心类库的概览和关键类的用法。首先,我们介绍了Java核心类库的结构和组织方式,然后重点解析了 Object 类、 Class 类的反射功能和 System 类的系统操作。随后,我们进一步探索了集合框架的核心接口和实现,以及如何使用 Comparator 和 Comparable 接口进行对象排序。通过这些丰富的类库和接口,Java开发者能够构建功能强大、高效和可维护的程序。
3. 基础类与接口
Java是一门面向对象的编程语言,它的基础类和接口为Java程序提供了强大的基础支持。在本章节中,我们将详细介绍Java基础数据类型包装类、异常处理类、输入输出接口等基础知识,帮助读者深入理解这些核心概念,并能够灵活运用在实际开发中。
3.1 基础数据类型包装类
Java为所有基本数据类型提供了对应的包装类,比如 Integer 对应基本类型 int , Double 对应 double 等。这些包装类是抽象类 Number 的子类,并实现了 Comparable 接口,使得它们能够用于通用的数据操作。
3.1.1 Integer和Double等类的特性
包装类除了提供类型转换的方法外,还支持一些通用的静态方法。以 Integer 类为例, Integer.parseInt() 能够将字符串转换为整数,而 Integer.valueOf() 可以返回对应的 Integer 对象实例。这些包装类对象还可以用在集合框架中,因为它们实现了 Comparable 接口,为集合的排序操作提供了基础。
public class WrapperClassDemo {
public static void main(String[] args) {
int i = Integer.parseInt("123"); // 字符串转整数
Integer iObj = Integer.valueOf(123); // 返回Integer实例
// 使用Comparable接口的compareTo方法进行比较
int comparisonResult = ***pareTo(120);
if (comparisonResult > 0) {
System.out.println("iObj is greater than 120");
}
}
}
3.1.2 自动装箱和拆箱机制
Java提供了自动装箱和拆箱的机制,使得基本类型与对应的包装类之间的转换更加便捷。这种机制大大简化了代码,并使得集合框架的使用更加自然。
public class BoxingAndUnboxingDemo {
public static void main(String[] args) {
int a = 100; // 基本类型
Integer b = a; // 自动装箱为Integer
int c = b; // 自动拆箱为int
// 使用自动装箱和拆箱,可以直接进行比较操作
System.out.println("a equals b? " + (a == b)); // true
System.out.println("b equals c? " + (b == c)); // true
}
}
3.2 异常处理类
异常处理是Java程序设计中非常重要的一个部分。在本节中,我们将解析 Exception 和 Error 的区别,以及如何自定义异常类并使用它们。
3.2.1 Exception和Error的区别
Exception 是程序可以处理的异常情况,如文件不存在、网络连接失败等。异常处理机制提供了捕获和处理这些异常的方法。而 Error 通常指不可恢复的系统错误,如虚拟机错误、系统崩溃等。
public class ExceptionHandlingDemo {
public static void main(String[] args) {
try {
int[] array = new int[10];
System.out.println(array[10]); // 抛出数组越界异常
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("Caught ArrayIndexOutOfBoundsException: " + e);
} finally {
System.out.println("This is the finally block.");
}
}
}
3.2.2 自定义异常类的编写和使用
在实际开发中,可能会遇到一些特定的问题,这时候我们可以通过自定义异常类来表示这些情况。
public class MyException extends Exception {
public MyException(String message) {
super(message);
}
}
public class CustomExceptionDemo {
public static void main(String[] args) {
try {
throw new MyException("自定义异常被抛出");
} catch (MyException e) {
System.out.println("Caught a MyException: " + e.getMessage());
}
}
}
3.3 输入输出接口
Java中, Serializable 接口用于对象的序列化存储和传输,而 Cloneable 接口则用于对象的复制。本节将详细介绍这两个接口的使用方法和内部机制。
3.3.1 Serializable接口的序列化机制
Serializable 接口是一个标记接口,不需要实现任何方法。当对象需要被序列化到文件或网络时,可以实现这个接口。
import java.io.*;
public class SerializableDemo implements Serializable {
private static final long serialVersionUID = 1L;
public static void main(String[] args) {
SerializableDemo instance = new SerializableDemo();
try (ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("object.ser"))) {
out.writeObject(instance);
} catch (IOException e) {
e.printStackTrace();
}
try (ObjectInputStream in = new ObjectInputStream(new FileInputStream("object.ser"))) {
SerializableDemo loadedInstance = (SerializableDemo) in.readObject();
System.out.println("Loaded instance from file.");
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
3.3.2 Cloneable接口的克隆机制
Cloneable 接口不包含任何方法,它的存在主要是为了标识类的对象能够被克隆。要实现对象的深拷贝,需要在 clone() 方法中实现具体的复制逻辑。
import java.io.*;
public class CloneableDemo implements Cloneable {
private int data;
public CloneableDemo(int data) {
this.data = data;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
public static void main(String[] args) {
try {
CloneableDemo original = new CloneableDemo(10);
CloneableDemo cloned = (CloneableDemo) original.clone();
System.out.println("Original data: " + original.data);
System.out.println("Cloned data: " + cloned.data);
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
在本章的介绍中,我们涵盖了Java基础类与接口的核心内容,深入探讨了包装类、异常处理以及输入输出接口的细节和应用。这些知识为编写健壮、高效的Java程序打下了坚实的基础。在下一章中,我们将探索Java集合框架的组成和高级特性,进一步提升数据结构的处理能力。
4. 集合框架详解
集合框架是Java编程语言中非常关键的一个部分,它为存储和操作对象集合提供了强大的数据结构。从Java 1.2版本开始,集合框架成为了Java类库的基础组成部分,它在后续版本中不断地被改进和优化,为开发者提供更为丰富和灵活的数据管理方式。
4.1 集合框架的组成
4.1.1 List, Set, Map三大集合
集合框架主要由三大接口组成:List、Set和Map。每个接口都有多种实现,适用于不同的场景。
List
List接口是一个有序的集合,它允许元素的重复,并且可以插入null值。List的主要实现类包括ArrayList和LinkedList。ArrayList基于动态数组实现,它支持快速的随机访问,但在中间插入和删除时性能较差。而LinkedList基于双向链表实现,它在插入和删除操作上表现更优,尤其是在列表的两端进行操作时。
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class ListExample {
public static void main(String[] args) {
// ArrayList 示例
List<Integer> arrayList = new ArrayList<>();
arrayList.add(1);
arrayList.add(2);
arrayList.add(3);
arrayList.get(1); // 访问第二个元素
// LinkedList 示例
List<Integer> linkedList = new LinkedList<>();
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
linkedList.addFirst(0); // 在头部插入元素
}
}
Set
Set接口是一个不允许重复元素的集合,它主要用于进行集合间操作,例如并集、交集、差集等。Set的主要实现类是HashSet和TreeSet。HashSet基于HashMap实现,提供了常数时间的插入、查找和删除操作。TreeSet则基于红黑树实现,它保持了元素的排序状态,并提供了对元素的排序功能。
import java.util.HashSet;
import java.util.TreeSet;
import java.util.Set;
public class SetExample {
public static void main(String[] args) {
// HashSet 示例
Set<String> hashSet = new HashSet<>();
hashSet.add("apple");
hashSet.add("banana");
// TreeSet 示例
Set<Integer> treeSet = new TreeSet<>();
treeSet.add(3);
treeSet.add(1);
treeSet.add(2);
treeSet.add(2); // 不会添加重复元素
System.out.println(treeSet); // 输出将按排序顺序显示
}
}
Map
Map接口是一个存储键值对的集合,其中每个键都映射到一个值。Map不允许重复的键,但允许重复的值。Map的主要实现类包括HashMap、TreeMap和Hashtable。HashMap提供了快速的键值对映射操作,但不保证映射的顺序。TreeMap则保持了键的自然排序或根据构造时提供的Comparator来排序。Hashtable是一个同步的Map实现,它不接受null键或值,但由于同步的开销,一般推荐使用ConcurrentHashMap代替。
import java.util.HashMap;
import java.util.TreeMap;
import java.util.Map;
import java.util.Hashtable;
public class MapExample {
public static void main(String[] args) {
// HashMap 示例
Map<String, Integer> hashMap = new HashMap<>();
hashMap.put("apple", 1);
hashMap.put("banana", 2);
// TreeMap 示例
Map<String, Integer> treeMap = new TreeMap<>();
treeMap.put("apple", 1);
treeMap.put("banana", 2);
System.out.println(treeMap); // 输出将按键的排序顺序显示
// Hashtable 示例(一般不推荐使用)
Map<String, Integer> hashtable = new Hashtable<>();
hashtable.put("apple", 1);
hashtable.put("banana", 2);
}
}
4.1.2 Iterator与ListIterator的使用
Iterator接口是Java集合框架的迭代器模式的实现,用于遍历集合中的元素。Iterator允许调用者删除集合中的元素,而不会抛出ConcurrentModificationException异常。ListIterator是Iterator的一个扩展,它支持双向迭代,并且可以修改遍历过的元素。
import java.util.Arrays;
import java.util.List;
import java.util.ListIterator;
public class IteratorExample {
public static void main(String[] args) {
List<String> list = Arrays.asList("apple", "banana", "cherry");
ListIterator<String> listIterator = list.listIterator();
while (listIterator.hasNext()) {
String element = listIterator.next();
if ("banana".equals(element)) {
listIterator.remove(); // 删除元素
}
}
listIterator.add("date"); // 在当前指针位置插入元素
System.out.println(list); // 输出修改后的列表
}
}
4.2 高级集合类
4.2.1 ConcurrentHashMap和ConcurrentMap的并发特性
ConcurrentHashMap是Java 5.0中引入的,它是一个线程安全的HashMap。它使用了一种分段锁的机制来提供高并发的访问支持,这比传统的同步HashMap效率要高得多。ConcurrentMap是一个接口,ConcurrentHashMap是它的其中一个实现,它扩展了Map接口并提供了额外的方法来帮助处理并发。
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample {
public static void main(String[] args) {
ConcurrentHashMap<String, Integer> conHashMap = new ConcurrentHashMap<>();
conHashMap.put("apple", 1);
conHashMap.put("banana", 2);
// 并发环境下使用***
***puteIfAbsent("orange", k -> 3); // 如果键不存在,则计算其值并加入到映射中
}
}
4.2.2 CopyOnWriteArrayList和CopyOnWriteArraySet的线程安全实现
CopyOnWriteArrayList和CopyOnWriteArraySet是线程安全的集合类,它们通过写入时复制的方式实现线程安全。这意味着每次修改集合内容时,都会创建底层数组的一个新副本,然后在这个新副本上进行修改。这种方式特别适用于读多写少的并发场景。
import java.util.concurrent.CopyOnWriteArrayList;
public class CopyOnWriteExample {
public static void main(String[] args) {
CopyOnWriteArrayList<String> copyOnWriteList = new CopyOnWriteArrayList<>();
copyOnWriteList.add("apple");
copyOnWriteList.add("banana");
// 并发环境下使用CopyOnWriteArrayList
copyOnWriteList.forEach(System.out::println); // 安全地遍历集合
}
}
4.3 集合的排序与比较
4.3.1 Comparable和Comparator接口的运用
集合的排序通常是通过实现Comparable或Comparator接口来完成的。Comparable接口的实现会自然地定义对象在排序中的顺序,而Comparator接口则允许在排序时插入一个外部的比较器。
import java.util.Collections;
***parator;
import java.util.List;
class Fruit implements Comparable<Fruit> {
private String name;
public Fruit(String name) {
this.name = name;
}
@Override
public int compareTo(Fruit o) {
***pareTo(o.name); // 自然排序
}
@Override
public String toString() {
return name;
}
}
class FruitNameComparator implements Comparator<Fruit> {
@Override
public int compare(Fruit f1, Fruit f2) {
***pareTo(f2.name); // 使用外部比较器
}
}
public class SortExample {
public static void main(String[] args) {
List<Fruit> fruits = Arrays.asList(new Fruit("banana"), new Fruit("apple"), new Fruit("orange"));
// 使用Comparable排序
Collections.sort(fruits);
System.out.println(fruits); // 输出自然排序后的列表
// 使用Comparator排序
Comparator<Fruit> comparator = new FruitNameComparator();
Collections.sort(fruits, comparator);
System.out.println(fruits); // 输出使用外部比较器排序后的列表
}
}
4.3.2 TreeSet和TreeMap的使用场景
TreeSet和TreeMap分别实现了Set和Map接口,并提供了元素的排序功能。它们基于红黑树实现,能够保证元素按照自然排序或指定的Comparator排序。这种类型的集合特别适合于需要有序访问集合元素的场景。
import java.util.TreeSet;
public class TreeSetExample {
public static void main(String[] args) {
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(3);
treeSet.add(1);
treeSet.add(2);
treeSet.add(2);
System.out.println(treeSet); // 输出排序后的集合
}
}
总结来说,集合框架提供了丰富多样的数据结构来满足不同的需求场景。开发者可以根据特定场景选择合适的集合类型,并且合理地利用接口和实现类来达到预期的功能和性能要求。通过上文的介绍,读者应该能够对Java集合框架有一个深入的理解,并在实际开发中灵活地运用各种集合。
5. I/O流操作
5.1 I/O流基础
5.1.1 输入输出流的概念和分类
Java的I/O流用于处理设备间的数据传输。I/O代表输入(input)和输出(output),在Java中,流的概念用于处理任何形式的数据源或目的地,这些数据源或目的地可以是文件、网络连接、内存缓冲区、控制台等。数据流可以被组织为两大类:字节流和字符流。字节流用于读写二进制数据,如图片、视频、音频等,而字符流用于读写字符数据,如文本文件。
字节流主要通过InputStream和OutputStream这两个抽象类来表示,它们的子类包括FileInputStream、FileOutputStream、ByteArrayInputStream、ByteArrayOutputStream等。字符流主要通过Reader和Writer这两个抽象类来表示,它们的子类包括FileReader、FileWriter、StringReader、StringWriter等。
字节流与字符流的主要区别在于它们处理数据的单位不同,字节流一次处理一个字节,而字符流一次处理一个字符。在处理文本文件时,字符流可以避免因编码转换导致的问题,因为字符流内部会处理字符编码和解码。
5.1.2 字节流与字符流的对比
字节流和字符流都用于数据的输入输出,但它们在处理方式和适用场景上存在差异。字节流是处理二进制数据的通用方法,不关心数据的编码格式,适用于所有数据类型。字符流则是处理文本数据的专门方法,使用字符编码来读写文本,保证了数据的准确性和一致性。
字节流的性能通常比字符流略高,因为它不需要额外的字符编码/解码过程。但是,如果直接使用字节流处理文本文件,可能会因为字符编码的不同而出现乱码。字符流则内部实现了字符编码的处理,更加方便和安全。
在选择使用字节流还是字符流时,主要取决于你要处理的数据类型。如果处理的是文本文件,推荐使用字符流,以避免编码问题。如果处理的是二进制文件,如图片或音频等,应使用字节流。
import java.io.*;
public class StreamComparison {
public static void main(String[] args) {
try {
// 字节流示例
FileInputStream fis = new FileInputStream("example.txt");
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = fis.read(buffer)) != -1) {
// 处理读取到的字节数据...
}
fis.close();
// 字符流示例
FileReader fr = new FileReader("example.txt");
char[] charBuffer = new char[1024];
int charsRead;
while ((charsRead = fr.read(charBuffer)) != -1) {
// 处理读取到的字符数据...
}
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
在上述代码示例中,我们分别使用FileInputStream(字节流)和FileReader(字符流)从文件中读取数据。在使用字节流时,我们处理的是字节数据,而在使用字符流时,我们处理的是字符数据。字节流读取后需要手动处理字符编码,而字符流则会自动处理。
5.2 高级I/O技术
5.2.1 缓冲流BufferedInputStream和BufferedOutputStream的使用
缓冲流提供了一种简便的方法来增加输入输出流的效率。它们通过在内部缓存数据来减少实际与物理设备的数据交换次数。常见的缓冲流有BufferedInputStream和BufferedOutputStream,它们分别用于对字节流进行包装,以提供缓冲功能。
BufferedInputStream提供了readLine()方法,可以一次性读取一行数据,这比直接使用InputStream的read()方法逐个字节读取更加高效。BufferedOutputStream则可以提供一个write方法的变种,允许将一系列数据一次性写入底层输出流。
使用缓冲流时,通常会看到性能上的显著提升,特别是当底层流涉及到I/O操作时(如磁盘或网络I/O)。在读写数据之前,缓冲流会填充内部的缓冲区,当缓冲区满了或者关闭时,它会将数据全部写入底层流。
import java.io.*;
public class BufferedStreamExample {
public static void main(String[] args) {
try {
// 使用BufferedInputStream读取数据
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("example.bin"));
int data;
while ((data = bis.read()) != -1) {
// 处理读取到的字节数据...
}
bis.close();
// 使用BufferedOutputStream写入数据
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("example.bin"));
byte[] buffer = new byte[1024];
int len;
while ((len = bis.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
在上面的代码中,我们首先创建了一个BufferedInputStream实例,它包装了一个FileInputStream实例。之后的读取操作将从内部缓冲区读取数据,直到缓冲区空或者文件结束。对于写操作,BufferedOutputStream实例包装了一个FileOutputStream实例,允许我们以缓冲的方式写入数据,这些数据会被暂存到内部缓冲区,直到缓冲区满或者手动调用flush()方法时才会被完全写入文件。
5.2.2 对象序列化与反序列化机制
对象序列化是将对象状态转换为可以存储或传输的形式的过程。在Java中,这通常意味着一个对象被转换成字节流,这样就可以存储在文件中或通过网络发送到另一个机器上。序列化后的对象可以使用Java的反序列化机制恢复到其原始状态。
ObjectOutputStream和ObjectInputStream类分别用于序列化和反序列化操作。ObjectOutputStream类中的writeObject()方法可以将对象状态写入流中,而ObjectInputStream类中的readObject()方法可以从流中恢复对象。
序列化可以用于多种场景,如永久存储对象,通过网络传输对象,或者将对象持久化到数据库。序列化的对象必须实现Serializable接口,这个接口是一个标记接口,它不需要包含任何方法。
反序列化过程中,如果对象的class文件在反序列化操作之后被修改,将抛出InvalidClassException异常。为了解决这个问题,Java允许对象类提供readResolve()方法来控制如何恢复引用。
import java.io.*;
public class SerializationExample implements Serializable {
private static final long serialVersionUID = 1L;
public static void main(String[] args) {
try {
// 序列化对象到文件
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("object.ser"));
SerializationExample obj = new SerializationExample();
oos.writeObject(obj);
oos.close();
// 反序列化对象从文件
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.ser"));
SerializationExample objRead = (SerializationExample) ois.readObject();
ois.close();
// 现在objRead是原始对象的一个副本
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
在上述代码中,我们创建了一个实现了Serializable接口的SerializationExample类的对象,并通过ObjectOutputStream将其写入到一个文件中。之后我们通过ObjectInputStream从文件中读取并反序列化了这个对象。注意,我们用static和transient修饰符定义了不希望序列化的类变量,这是序列化机制中的一些细节调整。
5.3 文件操作实战
5.3.1 文件读写与操作
文件操作是I/O流使用中最常见的一个场景。Java提供了多种方法来读写文件,包括低级别的File类操作和基于流的高级操作。File类提供了文件的创建、删除、目录浏览、重命名等操作。而文件的读写则可以使用InputStream和OutputStream或Reader和Writer的子类。
在处理文件读写时,推荐使用try-with-resources语句来自动关闭流。try-with-resources语句可以确保每项资源在语句结束时关闭,从而避免资源泄露。
一个常见的文件操作场景是逐行读取文件内容,这可以通过BufferedReader配合FileReader实现。对于文件写入,FileWriter类可以用来将文本数据写入到文件中。
import java.io.*;
public class FileReadWriteExample {
public static void main(String[] args) {
String sourceFile = "example.txt";
String destFile = "example_copy.txt";
try (
// 读取文件
BufferedReader br = new BufferedReader(new FileReader(sourceFile));
// 写入文件
BufferedWriter bw = new BufferedWriter(new FileWriter(destFile))
) {
String line;
while ((line = br.readLine()) != null) {
bw.write(line);
bw.newLine(); // 写入换行符
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
上面的示例代码中,我们使用BufferedReader和BufferedWriter来逐行读取和写入文件。BufferedReader的readLine()方法逐行读取文件,BufferedWriter的write()方法和newLine()方法将读取到的数据写入到新文件中。try-with-resources确保了文件流的自动关闭。
5.3.2 文件系统监控与管理
Java提供了用于文件系统监控和管理的类,主要包含java.nio.file包下的WatchService、Path、Files类等。WatchService用于监控文件系统的变化事件,如文件的创建、删除、修改等。Path类是一个通用的路径表示,可以用于构建文件系统路径,而Files类提供了很多便利的方法来进行文件操作,例如复制、移动、删除、读写等。
使用Path和Files类,可以轻松完成对文件系统的各种操作。Files类还支持文件属性的获取与修改,以及文件权限的检查与修改。
import java.io.IOException;
import java.nio.file.*;
public class FileSystemManagementExample {
public static void main(String[] args) {
Path path = Paths.get("example.txt");
try {
// 创建文件
if (Files.notExists(path)) {
Files.createFile(path);
}
// 读取文件内容
String content = new String(Files.readAllBytes(path));
System.out.println(content);
// 更新文件内容
Files.write(path, "Updated content".getBytes());
} catch (IOException e) {
e.printStackTrace();
}
}
}
在上面的代码中,首先检查文件是否存在,如果不存在则创建文件。然后使用Files类的readAllBytes()方法读取文件内容到字节数组,并将其转换为字符串打印出来。之后,使用write()方法将新内容写入文件。
通过结合使用Path、Files和WatchService类,可以实现复杂的文件系统操作和事件监听。例如,可以使用WatchService来监控特定目录下文件的变化,并作出响应,例如自动清理临时文件,或者在文件发生变化时通知用户。
import java.nio.file.*;
public class WatchServiceExample {
public static void main(String[] args) {
Path dirPath = Paths.get("some_directory");
try (WatchService watchService = FileSystems.getDefault().newWatchService()) {
dirPath.register(watchService, StandardWatchEventKinds.ENTRY_CREATE, StandardWatchEventKinds.ENTRY_DELETE);
WatchKey watchKey = null;
while ((watchKey = watchService.take()) != null) {
for (WatchEvent<?> event : watchKey.pollEvents()) {
WatchEvent.Kind<?> kind = event.kind();
Path fileName = (Path) event.context();
System.out.println("Event kind: " + kind.name() + ", File name: " + fileName);
}
watchKey.reset();
}
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}
在WatchService示例代码中,我们创建了一个WatchService实例,并注册了对目录中创建和删除事件的监控。通过循环等待WatchKey,当有事件发生时,程序会读取事件类型和文件名称,然后输出相关信息。这种方式可以用于需要实时响应文件系统变化的场景。
6. 网络编程能力
6.1 网络编程基础
6.1.1 网络通信模型与Socket编程
在Java中,网络通信是通过Socket编程来实现的。Socket是计算机网络数据传输的一个端点,可以看作是网络连接的一个端口。在Java中,常用的网络通信模型是基于TCP/IP协议的Socket通信模型。
TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。而Socket编程主要就是利用TCP/IP协议族中的这些协议来进行网络通信。主要步骤包括创建Socket连接、数据传输以及最后的连接关闭。
这里我们可以通过一个简单的TCP客户端例子来理解Socket通信的基本流程:
import java.io.*;
***.Socket;
public class SimpleTCPClient {
public static void main(String[] args) throws IOException {
String host = "localhost";
int port = 12345;
try (Socket socket = new Socket(host, port);
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()))) {
out.println("Hello, world!");
System.out.println("Received: " + in.readLine());
} catch (IOException e) {
e.printStackTrace();
}
}
}
在这个例子中,客户端首先建立与服务器的连接,然后向服务器发送一条消息,并等待服务器的响应。
6.1.2 URL和URLConnection的使用
URL(Uniform Resource Locator,统一资源定位符)是用于描述网络上一个资源的位置和访问方式的一种机制。它通常指的是一个特定的文件位置,例如网页、文件或者目录的路径。在Java中,我们可以使用 ***.URL 类和 ***URLConnection 类来处理URL和建立与URL之间的连接。
以下是一个简单的例子,演示如何使用 URL 和 URLConnection 来下载网络资源:
import java.io.*;
***.URL;
public class URLExample {
public static void main(String[] args) {
String urlAddress = "***";
try (URL url = new URL(urlAddress);
InputStream is = url.openStream();
FileOutputStream fos = new FileOutputStream("file.zip")) {
int contentLength = url.openConnection().getContentLength();
byte[] buffer = new byte[contentLength];
int bytesRead;
while ((bytesRead = is.read(buffer)) != -1) {
fos.write(buffer, 0, bytesRead);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
这段代码展示了如何从网络上下载一个文件,并将其保存到本地。
6.2 进阶网络技术
6.2.1 多线程在客户端和服务器端的应用
多线程是网络编程中提高效率和响应速度的关键技术之一。在服务器端,多线程可以使得服务器同时处理多个客户端的请求;在客户端,多线程可以用来同时执行多个网络请求,提高应用性能。
以下是一个简单的服务器端例子,使用多线程来处理客户端请求:
import java.io.*;
***.*;
public class SimpleTCPServer {
public static void main(String[] args) throws IOException {
int port = 12345;
ServerSocket serverSocket = new ServerSocket(port);
System.out.println("Server is listening on port: " + port);
while (true) {
new Handler(serverSocket.accept()).start();
}
}
}
class Handler extends Thread {
private Socket socket;
public Handler(Socket socket) {
this.socket = socket;
}
public void run() {
try (BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter out = new PrintWriter(socket.getOutputStream(), true)) {
String inputLine;
while ((inputLine = in.readLine()) != null) {
out.println("Echo: " + inputLine);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
在这个例子中,服务器为每个接受到的连接创建一个新的线程,通过该线程与客户端通信。
6.2.2 非阻塞I/O与Selector选择器的使用
Java提供了非阻塞I/O操作,这些操作允许应用程序在等待I/O操作完成时继续执行其他任务。 Selector 类是实现非阻塞I/O的关键,它允许单个线程处理多个网络连接。
以下是一个使用 Selector 的例子:
import java.io.IOException;
***.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Iterator;
public class SelectorExample {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(12345));
serverSocketChannel.configureBlocking(false);
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
int readyChannels = selector.select();
if (readyChannels == 0) continue;
Iterator<SelectionKey> keyIterator = selector.selectedKeys().iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
SocketChannel socketChannel = serverSocketChannel.accept();
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel socketChannel = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int bytesRead = socketChannel.read(buffer);
if (bytesRead > 0) {
buffer.flip();
// 处理接收到的数据...
}
}
keyIterator.remove();
}
}
}
}
这个例子展示了如何使用 Selector 来监听多个网络连接上的事件,并通过非阻塞方式处理它们。
6.3 网络安全与协议
6.3.1 SSL/TLS安全通信机制
SSL(Secure Sockets Layer,安全套接层)和TLS(Transport Layer Security,传输层安全)是用于保证网络通信安全的协议。SSL的最新版本为3.0,而TLS是SSL的继承者,其最新的版本为1.3。这些协议主要通过加密和身份验证机制来提供数据保密性和完整性,防止数据在传输过程中被窃取或篡改。
在Java中, SSLContext 类可以用来支持SSL/TLS协议的配置和初始化。以下是一个简单的SSL服务器和客户端连接的例子:
// 服务器端SSL上下文初始化的简化示例代码
SSLContext ctx = SSLContext.getInstance("TLS");
KeyManagerFactory kmf = KeyManagerFactory.getInstance("SunX509");
kmf.init(keyStore, keyStorePassword.toCharArray());
ctx.init(kmf.getKeyManagers(), null, null);
// 客户端SSL上下文初始化的简化示例代码
SSLContext ctx = SSLContext.getInstance("TLS");
TrustManagerFactory tmf = TrustManagerFactory.getInstance("SunX509");
tmf.init(trustStore);
ctx.init(null, tmf.getTrustManagers(), null);
// 之后使用初始化的SSLContext来创建SSLServerSocket或SSLSocket
6.3.2 HTTP协议的深入理解与应用
HTTP(Hypertext Transfer Protocol,超文本传输协议)是网络上应用最为广泛的协议之一。它是Web应用通信的基础,用于定义客户端和服务器端之间的通信规则。HTTP是无状态的,它通过请求-响应模型进行工作。HTTP请求和响应都包含状态信息和数据内容。
在Java中,HTTP协议的通信可以通过 ***.HttpURLConnection 类或者第三方库如Apache HttpClient来实现。
以下是一个使用 HttpURLConnection 发送HTTP GET请求的例子:
import java.io.BufferedReader;
import java.io.InputStreamReader;
***.HttpURLConnection;
***.URL;
public class HTTPGetExample {
public static void main(String[] args) throws IOException {
URL url = new URL("***");
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setRequestProperty("Accept", "text/html");
int responseCode = connection.getResponseCode();
if (responseCode == HttpURLConnection.HTTP_OK) {
BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String inputLine;
StringBuffer response = new StringBuffer();
while ((inputLine = in.readLine()) != null) {
response.append(inputLine);
}
in.close();
System.out.println(response.toString());
} else {
System.out.println("GET request not worked");
}
connection.disconnect();
}
}
这个例子演示了如何使用 HttpURLConnection 发送一个GET请求到指定的URL,并获取响应数据。
简介:本文档详细解析了Java Development Kit (JDK) 1.6的API,该版本为Java应用程序开发提供了丰富的类库和工具。包含了Java基础类、集合框架、I/O流、网络编程、多线程、反射等核心类库的用法和实践。文档以CHM格式的API.CHM文件形式提供,深入探讨了关键知识点,适用于学习和参考,尤其是在解决遗留系统问题时。

















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









