




简介
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。 Hibernate可以应用在任何使用JDBC的场合,既可以在Java的客户端程序使用,也可以在Servlet/JSP的Web应用中使用。
什么是orm
对象关系映射(英语:Object Relation Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。
对象-关系映射,是随着面向对象的软件开发方法发展而产生的。面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。因此,对象-关系映射(ORM)系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射。
ORM模型的简单性简化了数据库查询过程。使用ORM查询工具,用户可以访问期望数据,而不必理解数据库的底层结构
简单使用流程
- 创建数据库与表
- 创建实体类
- 导入hibernate依赖jar包
- 创建映射文件
<hibernate-mapping package="com.itheima.domain">
<class name="Customer" table="t_customer" catalog="hibernateTest">
<id name="id" column="id">
<!-- 主键生成策略 -->
<generator class="native"></generator>
</id>
<!-- 使用property字段描述属性与字段之间的关系 -->
<property name="name" column="name" length="20"></property>
<property name="address" column="address" length="50"></property>
</class>
</hibernate-mapping>- 创建hibernate核心配置文件
<hibernate-configuration>
<session-factory>
<!-- 配置数据库连接的四个项 -->
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql:///hibernatetest</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">1234</property>
<!-- 设置连接池提供者 -->
<property name="hibernate.connection.provider_class">org.hibernate.connection.C3P0ConnectionProvider</property>
<!-- 设置连接池 -->
<property name="hibernate.c3p0.max_size">20</property>
<property name="hibernate.c3p0.min_size">5</property>
<property name="hibernate.c3p0.timeout">100</property>
<property name="hibernate.c3p0.idle_test_period">3000</property>
<!-- 可以将像数据库发送的数据显示出来 -->
<property name="hibernate.show_sql">true</property>
<!-- 格式化sql -->
<property name="hibernate.format_sql">true</property>
<!-- hibernate方言 -->
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- 如果数据库中有表,不创建,没有表创建,如果映射不匹配,会自动更新表结构 -->
<property name="hibernate.hbm2ddl.auto">update</property>
<!-- 设置事物自动提交 -->
<property name="hibernate.connection.autocommit">true</property>
<!-- 配置hibernate映射所在 -->
<mapping resource="com/itheima/domain/Customer.hbm.xml"/>
</session-factory>
</hibernate-configuration>- 编写测试代码
//插入数据
@Test
public void addCustomer(){
Customer c=new Customer();
c.setName("薛仁贵");
c.setAddress("高丽都护府");
c.setSex("男");
Configuration configure = new Configuration().configure();// 加载hibernate.cfg.xml
//configure.addResource("com/itheima/domain/Customer.hbm.xml");手动加载映射
configure.addClass(Customer.class);
SessionFactory sessionFactory = configure.buildSessionFactory();
//configure.addClass(Customer.class);
Session session = sessionFactory.openSession();
Transaction transaction = session.beginTransaction();
session.save(c);
transaction.commit();
session.close();
sessionFactory.close();
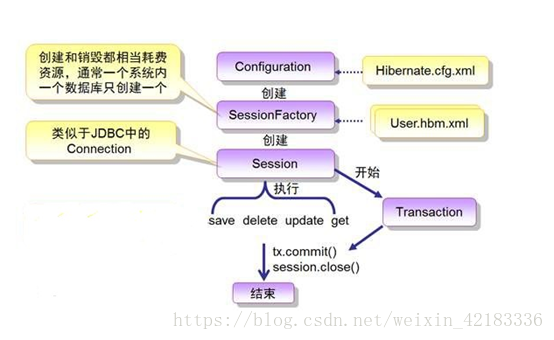
Hibernate 工作原理总结
1、通过Configuration().configure();读取并解析hibernate.cfg.xml配置文件。
2、由hibernate.cfg.xml中的<mappingresource="xx/xx/xxx.hbm.xml"/>读取解析映射信息。
3、通过config.buildSessionFactory();//得到sessionFactory。
4、sessionFactory.openSession();//得到session。
5、session.beginTransaction();//开启事务。
6、persistent operate;
7、session.getTransaction().commit();//提交事务
8、关闭session;
9、关闭sessionFactory;
Query
使用HQL
、Query接口让你方便地对数据库及持久对象进行查询,它可以有两种表达方式:HQL语言或本地数据库的SQL语句。Query经常被用来绑定查询参数、限制查询记录数量,并最终执行查询操作。
无名称参数 from Customer where name=?
对其进行赋值 query.setParameter(0,”张三”)
有名称参数 from Customer where name=:myname;
对其进行赋值 query.setParameter(“myname”,”李四”);
如果查询结果可以保证就是唯一 的,我们可以使用
query. uniqueResult()来得到一个单独对象.
SQLQuery
要想执行本地sql SQLQuery sqlQuery=session.createSqlQuery(String sql);
使用addEntity方法来将结果封装到指定的对象中,如果不封装,得到的是List<Object>
如果sql中有参数,我们使用setParameter方法完成参数传递。如果结果就是一个可以使用uniqueResult()来得到一个单独对象。
Criteria
Criteria接口与Query接口非常类似,允许创建并执行面向对象的标准化查询。值得注意的是Criteria接口也是轻量级的,它不能在Session之外使用。
首先我想使用Criteria,必须得到Criteria Criteria criteria=Session.createCriteria()
Session session =HibernateUtils.getSession();
session.beginTransaction();
Criteria criteria = session.createCriteria(Customer.class);
//查询所有
List<Customer> list = criteria.list();
System.out.println(list);
session.getTransaction().commit();
session.close();
//分页查询
criteria.setFirstResult(10);
criteria.setMaxResults(10);
List<Customer> list = criteria.list();
System.out.println(list);
//多条件查询
criteria.add(Restrictions.eq("name", "李孝恭"));
session.getTransaction().commit();
session.close();
持久化类类三种状态介绍
瞬时态:也叫做临时态或自由态,它一般指我们new出来的对象,它不存在OID,与hibernate session无关联,在数据库中也无记录。它使用完成后,会被jvm直接回收掉,它只是用于信息携带。
简单说:无OID 与数据库中的信息无关联,不在session管理范围内。
持久态:在hibernate session管理范围内,它具有持久化标识OID它的特点,在事务未提交前一直是持久态,当它发生改变时,hibernate是可以检测到的。
简单说:有OID 由session管理,在数据库中有可能有,也有可有没有。
托管态:也叫做游离态或离线态,它是指持久态对象失去了与session的关联,托管态对象它存在OID,在数据库中有可能存在,也有可能不存在。
对于托管态对象,它发生改变时hibernet不能检测到。
三种状态切换
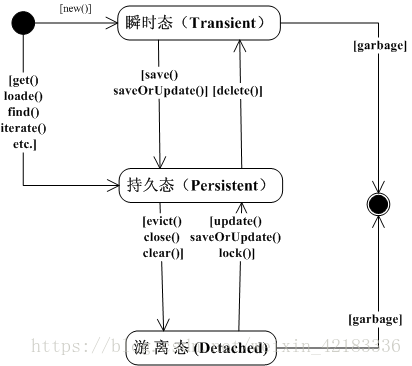
瞬时态(new 出来的)
瞬时------à持久 save saveOrUpdate
瞬时-----à脱管(游离) 手动设置oid
.持久态 它是由session管理
持久-------à瞬时 delete() 被删除后持久化对象不在建议使用
持久-----à脱管 注意:session它的缓存就是所说的一级缓存
evict(清除一级缓存 中指定的一个对象)
clear(清空一级缓存)
close(关闭,清空一级缓存)
.脱管态 (它是无法直接获取)
脱管-----à瞬时 直接将oid删除
脱管----à持久 update saveOrUpdate lock(过时)
Hibernate一级缓存
Hibernate的一级缓存就是指session缓存。
actionQueue它是一个行列队列,它主要记录crud操作的相关信息
persistenceContext它是持久化上下文,它其实是真正缓存。
在session中定义了一系列的集合来存储数据,它们构成session缓存。只要session没有关闭,它就会一直存在。
当我们通过hibernate中的session提供的一些API例如 save get update等进行操作时,就会将持久化对象保存到session中,当下一次在去查询缓存中具有的对象(OID值来判断),就不会去从数据库查询,而是直接从缓存中获取。
Hibernate的一级缓存存在的目的就是为了减少对数据库访问。
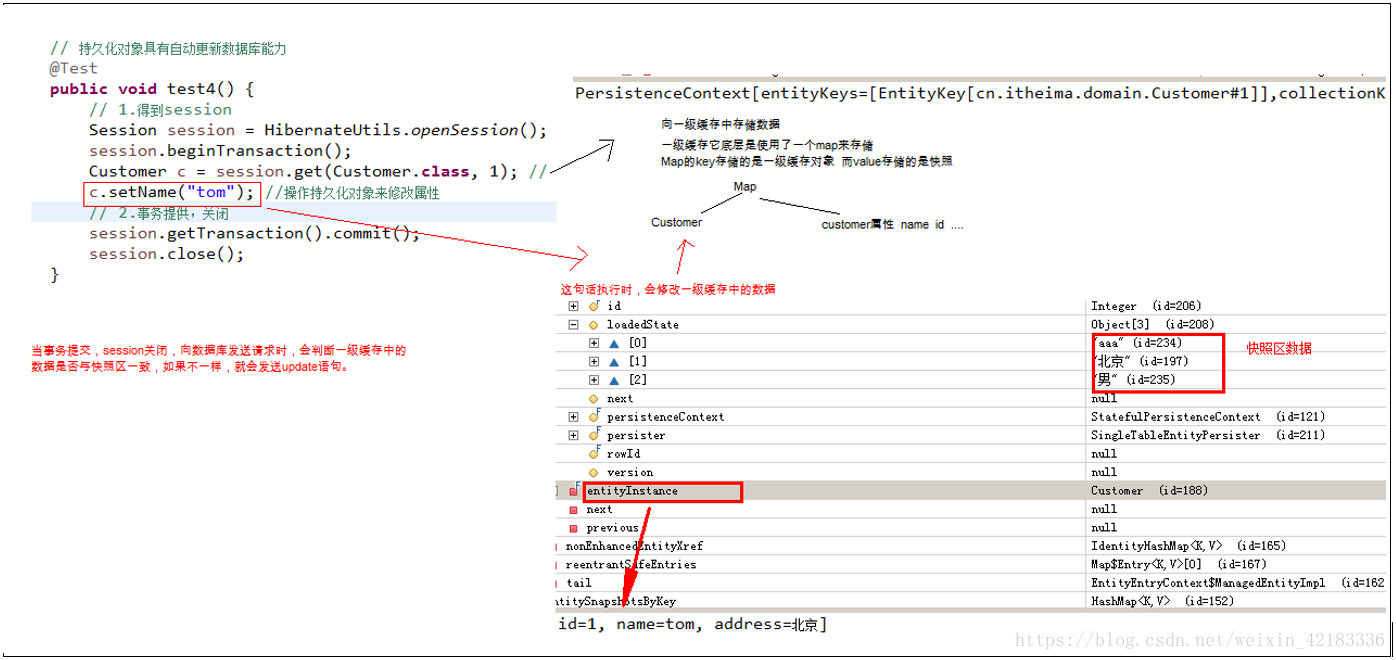
持久化对象具有自动更新数据库能力
一级缓存常用API
一级缓存特点:
- 当我们通过session的save,update saveOrupdate进行操作时,如果一级缓存中没有对象,会将这些对象从数据库中查询到,存储到一级缓存。
- 当我们通过session的load,get,Query的list等方法进行操作时,会先判断一级缓存中是否存在,如果没有才会从数据库获取,并且将查询的数据存储到一级缓存中。
- 当调用session的close方法时,session缓存清空。
clear 清空一级缓存.
evict 清空一级缓存中指定的一个对象。
refresh重新查询数据库,用数据库中信息来更新一级缓存与快照
public void test5() {
// 1.得到session
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 操作
List<Customer> list = session.createQuery("from Customer").list(); // 会存储数据到一级缓存
session.clear(); // 清空一级缓存
Customer c = session.get(Customer.class, 1); // 会先从session一级缓存
// 中获取,如果不存在,才会从数据库获取
session.evict(c); // 从一级缓存 中删除一个指定的对象
Customer cc = session.get(Customer.class, 1);
cc.setName("kkkk");
session.refresh(cc); // 重新查询数据库,用数据库中信息来更新一级缓存与快照
// 2.事务提供,关闭
session.getTransaction().commit();
session.close();
}
Hibernate关联映射-数据对象三种关系介绍
Hibernate框架基于ORM设计思想,它将关系型数据库中的表与我们java中的类进行映射,一个对象就对应着表中的一条记录,而表中的字段对应着类中的属性。
数据库中表与表之间存在着三种关系,也就是系统设计中的三种实体关系。
<!-- 一个客户关联多个订单 -->
<set name="orders" inverse="true" cascade="save-update">
<key column="c_customer_id" />
<one-to-many class="cn.itheima.oneToMany.Order" />
</set>
<!-- 使用set来描述在一的一方中关联的多 Set<Order>,它的name属性就是set集合的名称 key:它主要描述关联的多的一方产生的外键名称,注意要与多的一方定义的外键名称相同one-to-many 描述集合中的类型 -->Inverse它的值如果为true代表,由对方来维护外键。
Inverse它的值如果为false代表,由本方来维护外键。
关于inverse的取值: 外键在哪一个表中,我们就让哪一方来维护外键。
使用cascade可以完成级联操作
它可常用取值:
none这是一个默认值
save-update,当我们配置它时,底层使用save update或save-update完成操作,级联保存临时对象,如果是游离对象,会执行update.
delete 级联删除
delete-ophan 删除与当前对象解除关系的对象。
all 它包含了save-update delete操作
all-delete-orphan 它包信了delete-orphan与all操作
Hibernate注解开发
@Entity 声明一个实体
@Table来描述类与表对应
@Id来声明一个主键
@GenerateValue 用它来声明一个主键生成策略 默认情况下相当于native 可以选择的主键生成策略 AUTO IDENTITY SEQUENCE
@Column来定义列
@Temporal来声明日期类型
@Transient声明不生成在表中
@OneToMany一对多
@ManyToOne多对一
@Joinclum添加列
@Cascade级联操作
mappedBy主键由哪一方维护
我们在Customer中配置了mappedBy=”c”它代表的是外键的维护由Order方来维护,而Customer不维护,这时你在保存客户时,级联保存订单,是可以的,但是不能维护外键
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
@ManyToMany(targetEntity = Teacher.class)
// 使用JoinTabl来描述中间表,并描述中间表中外键与Student,Teacher的映射关系
// joinColumns它是用来描述Student与中间表中的映射关系
// inverseJoinColums它是用来描述Teacher与中间表中的映射关系
@JoinTable(name = "s_t", joinColumns = {
@JoinColumn(name = "c_student_id", referencedColumnName = "id") }, inverseJoinColumns = {
@JoinColumn(name = "c_teacher_id", referencedColumnName = "id") })
@Cascade(CascadeType.ALL)
private Set<Teacher> teachers = new HashSet<Teacher>();HQL
HQL是我们在hibernate中是常用的一种检索方式。
HQL(Hibernate Query Language)提供更加丰富灵活、更为强大的查询能力
因此Hibernate将HQL查询方式立为官方推荐的标准查询方式,HQL查询在涵盖Criteria查询的所有功能的前提下,提供了类似标准SQL语 句的查询方式,同时也提供了更加面向对象的封装。完整的HQL语句形式如下: Select/update/delete…… from …… where …… group by …… having …… order by …… asc/desc 其中的update/delete为Hibernate3中所新添加的功能,可见HQL查询非常类似于标准SQL查询。
基本步骤:
- 得到Session
- 编写HQL语句
- 通过session.createQuery(hql)创建一个Query对象
- 为Query对象设置条件参数
- 执行list查询所有,它反胃的是List集合 uniqueResut()返回一个查询结果。
public class HQLTest {
// 命名查询
@Test
public void test9() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.我要查询张龙这个客户的订单
Customer c = session.get(Customer.class, 1);
Query query = session.getNamedQuery("findOrderByCustomer"); // from Order where c=:c
// 2.现在hql它的参数是一个实体
List<Order> list = query.setEntity("c", c).list();
System.out.println(list);
session.getTransaction().commit();
session.close();
}
// 命名查询
@Test
public void test8() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
Query query = session.getNamedQuery("myHql");
List<Customer> list = query.list();
System.out.println(list);
session.getTransaction().commit();
session.close();
}
// 投影查询
@Test
public void test7() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.查询出所有的Customer的name
// String hql = "select name from Customer";
// List list = session.createQuery(hql).list();
// System.out.println(list); // [张龙, 张三丰]
// 如果只查询一个列,得到的结果List<Object>
// 2.查询所有的Customer的id,name
// String hql = "select id,name from Customer";
// List<Object[]> list = session.createQuery(hql).list();
// for(Object[] objs:list){
// for(Object obj:objs){
// System.out.print(obj+" ");
// }
// System.out.println();
// }
// 如果是查询多列,得到的结果是List<Object[]>
// 3.使用投影将查询的结果封装到Customer对象
String hql = "select new Customer(id,name) from Customer"; // 必须在PO类中提供对应的构造方法
List<Customer> cs = session.createQuery(hql).list();
System.out.println(cs);
session.getTransaction().commit();
session.close();
}
// 分组统计操作
@Test
public void test6() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 统计操作----统计一共有多少订单 count
// String hql="select count(*) from Order";
// Object count = session.createQuery(hql).uniqueResult();
// System.out.println(count);
// 分组统计----每一个人的订单总价
String hql = "select sum(money) from Order group by c";
List list = session.createQuery(hql).list();
System.out.println(list);
session.getTransaction().commit();
session.close();
}
// 分页检索
@Test
public void test5() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
Query query = session.createQuery("from Order");
// 每页显示6条件 ,我们要得到第二页数据
query.setFirstResult((2 - 1) * 6); // 设定开始位置
query.setMaxResults(6); // 设置条数
List<Order> list = query.list();
System.out.println(list);
session.getTransaction().commit();
session.close();
}
// 条件查询
@Test
public void test4() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.根据位置来绑定参数
// 1.1创建hql
// String hql = "from Order where money>? ";
// 1.2.执行hql
// List<Order> list = session.createQuery(hql).setParameter(0,
// 2000d).list();
// 可以使用例如setString() setDouble这样的方法去添加参数,参数的序号是从0开始.
// 2.根据名称来绑定
// 1.1创建hql
String hql = "from Order where money>:mymoney ";
// 1.2.执行hql
List<Order> list = session.createQuery(hql).setParameter("mymoney", 2000d).list();
// 可以使用例如setString() setDouble这样的方法去添加参数
System.out.println(list);
session.getTransaction().commit();
session.close();
}
// 排序检索--//查询订单,根据订单的价格进行排序
@Test
public void test3() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.定义hql
String hql = "from Order order by money desc"; // desc 降序 默认是asc 升序
// 2.执行hql查询订单,根据价格进行排序
List<Order> list = session.createQuery(hql).list();
System.out.println(list);
session.getTransaction().commit();
session.close();
}
// 基本检索
@Test
public void test2() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.编写HQL
String hql = "from Customer"; // from是关键字,后面是类名,关键字是不区分大小写,但是类名是区分
// 2.通过session.createQuery(hql)
// Query query = session.createQuery(hql);
// 3.通过list方法得到数据
// List<Customer> list = query.list();
List<Customer> list = session.createQuery(hql).list();
System.out.println(list.get(0));
session.getTransaction().commit();
session.close();
}
// 准备数据(2个Customer,每一个Customer有10个Order)
@Test
public void test1() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 操作
Customer c = new Customer();
c.setName("张三丰");
for (int i = 0; i < 10; i++) {
Order order = new Order();
order.setMoney(2000d + i * 10);
order.setReceiverInfo("上海");
order.setC(c);
session.save(order);
}
session.getTransaction().commit();
session.close();
}QBC
QBC(query by criteria),它是一种更加面向对象的检索方式。
QBC步骤:
1.通过Session得到一个Criteria对象 session.createCriteria()
2.设定条件 Criterion实例 它的获取可以通过Restrictions类提供静态。Criteria的add方法用于添加查询条件
3.调用list进行查询 criterfia.list.
public class QBCTest {
// 离线的检索
@Test
public void test6() {
// 1.得到一个DetachedCriteria
DetachedCriteria dc = DetachedCriteria.forClass(Customer.class);
dc.add(Restrictions.like("name", "张_"));
// 2.生成Criteria执行操作
Session session = HibernateUtils.openSession();
session.beginTransaction();
Criteria criteria = dc.getExecutableCriteria(session);
List<Customer> list = criteria.list();
System.out.println(list);
session.getTransaction().commit();
session.close();
}
// 统计检索
@Test
public void test5() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.统计订单总数
Criteria criteria = session.createCriteria(Order.class);
// Object obj =
// criteria.setProjection(Projections.rowCount()).uniqueResult();
// //统计总行数 count(id)
// System.out.println(obj);
// 2.订单的总价格----分组统计根据客户
// criteria.setProjection(Projections.sum("money")); //统计总金额
criteria.setProjection(
Projections.projectionList().add(Projections.sum("money")).add(Projections.groupProperty("c")));
List<Object[]> list = criteria.list(); // 在这个集合中保存的是Object[money的统计信息,客户信息]
for (Object[] objs : list) {
for (Object obj : objs) {
System.out.println(obj);
}
}
session.getTransaction().commit();
session.close();
}
// 分页检索
@Test
public void test4() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
Criteria criteria = session.createCriteria(Order.class);
criteria.setFirstResult((2 - 1) * 6);
criteria.setMaxResults(6);
List<Order> list = criteria.list();
System.out.println(list);
session.getTransaction().commit();
session.close();
}
// 条件检索
@Test
public void test3() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.查询名称叫张某客户 张_
Criteria criteria = session.createCriteria(Customer.class);
Criterion like = Restrictions.like("name", "张_"); // 其它的条件 lt < gt > le
// <= ge>= eq==
criteria.add(like);// 添加条件
Customer c = (Customer) criteria.uniqueResult();
System.out.println(c);
// 2.查询订单价格在1050以上的,并且它的客户是张某
Criteria cri = session.createCriteria(Order.class);
SimpleExpression lt = Restrictions.gt("money", 1050d); // >1050
SimpleExpression eq = Restrictions.eq("c", c); // 与c客户相同
LogicalExpression and = Restrictions.and(lt, eq);
cri.add(and);
// List<Order> orders =
// cri.add(Restrictions.and(Restrictions.gt("money", 1050d),
// Restrictions.eq("c", c))).list();
List<Order> orders = cri.list();
System.out.println(orders);
session.getTransaction().commit();
session.close();
}
// 排序检索
@Test
public void test2() {
// 查询订单信息 根据订单的价格进行排序
Session session = HibernateUtils.openSession();
session.beginTransaction();
Criteria criteria = session.createCriteria(Order.class);
// 指定排序
// criteria.addOrder(org.hibernate.criterion.Order.desc("money")); // 降序
criteria.addOrder(org.hibernate.criterion.Order.asc("money")); // 升序
List<Order> list = criteria.list();
System.out.println(list);
session.getTransaction().commit();
session.close();
}
// 基本检索
@Test
public void test1() {
// 查询所有Customer
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.得到一个Criteria对象
Criteria criteria = session.createCriteria(Customer.class);
// 2.调用list方法
List<Customer> list = criteria.list();
System.out.println(list);
session.getTransaction().commit();
session.close();
}
}Hibernate事务管理
Hibernate中设置事务隔离级别
它可取的值有 1 2 4 8
1代表的事务隔离级别为READ UNCOMMITTED
2代表的事务隔离级别为READ COMMITTED
4.代表的事务隔离级别为 REPEATABLE READ
8代表的事务隔离级别为 SERIALIZABLE
<!-- 设置事务隔离级别 -->
<property name="hibernate.connection.isolation ">4</property>Hiberante优化方案
HQL优化
1.使用参数绑定
1.使用绑定参数的原因是让数据库一次解析SQL,对后续的重复请求可以使用用生成好的执行计划,这样做节省CPU时间和内存。
2.避免SQL注入
2.尽量少全长NOT
如果where子句中包含not关键字,那么执行时该字段的索引失效。
3.尽量使用where来替换having
Having在检索出所有记录后才对结果集进行过滤,这个处理需要一定的开销,而where子句限制记录的数目,能减少这方面的开销
4.减少对表的查询
在含有子查询的HQL中,尽量减少对表的查询,降低开销
5.使用表的别名
当在HQL语句中连接多个表时,使用别名,提高程序阅读性,并把别名前缀与每个列上,这样一来,可以减少解析时间并减少列歧义引起的语法错误。
6.实体的更新与删除
在hibernate3以后支持hql的update与delete操作
一级缓存管理
一级缓存也叫做session缓存,在一个hibernate session有效,这级缓存的可干预性不强,大多于hibernate自动管理,但它提供清除缓存的方法,这在大批量增加(更新)操作是有效果的,例如,同时增加十万条记录,按常规进行,很可能会出现异常,这时可能需要手动清除一级缓存,session.evict以及session.clear.
检索策略
延迟加载
延迟加载 是hibernate为提高程序执行的效率而提供的一种机制,即只有真正使用该对象的数据时才会创建。
load方法采用的策略延迟加载.
get方法采用的策略立即加载。
检索策略分为两种:
- 类级别检索
- 关联级别检索
set上的fetch与lazy它主要是用于设置关联的集合信息的抓取策略。
Fetch可取值有:
- SELECT 多条简单的sql (默认值)
- JOIN 采用迫切左外连接
- SUBSELECT 将生成子查询的SQL
lazy可取值有:
- TURE 延迟检索 (默认值)
- FALSE 立即检索
- EXTRA 加强延迟检索(及其懒惰)

















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









