无论做什么事,多尝试、找套路、然后刻意练习都是至关重要的。对信息科学竞赛(Olympiad in Informatics)爱好者来说,找套路的关键就是多刷题。然而题海茫茫,单以Codeforces来说,截止2017年1月3日,总共有3206道题。换言之,如果一个人足够勤奋,能够一天刷三道题,那也得快三年才能把题目刷完,而且题目数量还在扩充。所以盲目的刷题简直是浪费生命,本人从16年上半年一直按照题目解决人数从高到低排序,不断的刷水题。显然易见,刷水题的后果就是没有长进,熟悉的还是熟悉,不懂的还是不懂,唯一让自己开心的就是刷题数量的累积。所以科学刷题的本质在于不断挑战新高度,在一个平台练习足够久足够熟练之后,就要进入下一个难度平台。为了方便大家,我把Codeforces上截止2017年1月3日的所有题目的基本信息用爬虫收集了下来,并存储到excel里。更进一步,本文试图分析不同算法在不同难度等级上的出现频率分布,以及不同算法在不同难度等级上被解决次数的分布。最后,我会简要介绍的我的刷题观,以及如何爬取Codeforces上的信息。
1: import re 2: import urllib.request 3: from bs4 import BeautifulSoup 4: import os 5: import csv 6: import time
爬取Codeforces的所有算法题
1: #%% retrieve the problem set 2: defspider(url): 3: response = urllib.request.urlopen(url) 4: soup = BeautifulSoup(response.read()) 5: pattern = {'name': 'tr'} 6: content = soup.findAll(**pattern) 7: for row in content: 8: item = row.findAll('td') 9: try: 10: # get the problem id 11: id = item[0].find('a').string.strip() 12: col2 = item[1].findAll('a') 13: # get the problem title 14: title = col2[0].string.strip() 15: # get the problem tags 16: tags = [foo.string.strip() for foo in col2[1:]] 17: # get the number of AC submissions 18: solved = re.findall('x(\d+)', str(item[3].find('a')))[0] 19: # update the problem info 20: codeforces[id] = {'title':title, 'tags':tags, 'solved':solved, 'accepted':0,} 21: except: 22: continue 23: return soup 24: 25: codeforces = {} 26: wait = 15# wait time to avoid the blocking of spider 27: last_page = 33# the total page number of problem set page 28: url = ['http://codeforces.com/problemset/page/%d' % page for page in range(1,last_page+1)] 29: for foo in url: 30: print('Processing URL %s' % foo) 31: spider(foo) 32: print('Wait %f seconds' % wait) 33: time.sleep(wait)
标记已解决的算法题
1: #%% mark the accepted problems 2: defaccepted(url): 3: response = urllib.request.urlopen(url) 4: soup = BeautifulSoup(response.read()) 5: pattern = {'name':'table', 'class':'status-frame-datatable'} 6: table = soup.findAll(**pattern)[0] 7: pattern = {'name': 'tr'} 8: content = table.findAll(**pattern) 9: for row in content: 10: try: 11: item = row.findAll('td') 12: # check whether this problem is solved 13: if'Accepted'in str(row): 14: id = item[3].find('a').string.split('-')[0].strip() 15: codeforces[id]['accepted'] = 1 16: except: 17: continue 18: return soup 19: 20: wait = 15# wait time to avoid the blocking of spider 21: last_page = 10# the total page number of user submission 22: handle = 'Greenwicher'# please input your handle 23: url = ['http://codeforces.com/submissions/%s/page/%d' % (handle, page) for page in range(1, last_page+1)] 24: for foo in url: 25: print('Processing URL %s' % foo) 26: accepted(foo) 27: print('Wait %f seconds' % wait) 28: time.sleep(wait)
输出爬取信息到csv文本
1: #%% output the problem set to csv files 2: root = os.getcwd() 3: with open(os.path.join(root,"CodeForces-ProblemSet.csv"),"w", encoding="utf-8") as f_out: 4: f_csv = csv.writer(f_out) 5: f_csv.writerow(['ID', 'Title', 'Tags', 'Solved', 'Accepted']) 6: for id in codeforces: 7: title = codeforces[id]['title'] 8: tags = ', '.join(codeforces[id]['tags']) 9: solved = codeforces[id]['solved'] 10: accepted = codeforces[id]['accepted'] 11: f_csv.writerow([id, title, tags, solved, accepted]) 12: f_out.close()
分析题目难度以及算法分类的关系
1: #%% analyze the problem set 2: # initialize the difficult and tag list 3: difficult_level = {} 4: tags_level = {} 5: for id in codeforces: 6: difficult = re.findall('([A-Z])', id)[0] 7: tags = codeforces[id]['tags'] 8: difficult_level[difficult] = difficult_level.get(difficult, 0) + 1 9: for tag in tags: 10: tags_level[tag] = tags_level.get(tag, 0) + 1 11: import operator 12: tag_level = sorted(tags_level.items(), key=operator.itemgetter(1))[::-1] 13: tag_list = [foo[0] for foo in tag_level] 14: difficult_level = sorted(difficult_level.items(), key=operator.itemgetter(0)) 15: difficult_list = [foo[0] for foo in difficult_level] 16: 17: # initialize the 2D relationships matrix 18: # matrix_solved: the number of AC submission for each tag in each difficult level 19: # matrix_freq: the number of tag frequency for each diffiicult level 20: matrix_solved, matrix_freq = [[[0] * len(difficult_list) for _ in range(len(tag_list))] for _ in range(2)] 21: 22: 23: # construct the 2D relationships matrix 24: for id in codeforces: 25: difficult = re.findall('([A-Z])', id)[0] 26: difficult_id = difficult_list.index(difficult) 27: tags = codeforces[id]['tags'] 28: solved = codeforces[id]['solved'] 29: for tag in tags: 30: tag_id = tag_list.index(tag) 31: matrix_solved[tag_id][difficult_id] += int(solved) 32: matrix_freq[tag_id][difficult_id] += 1








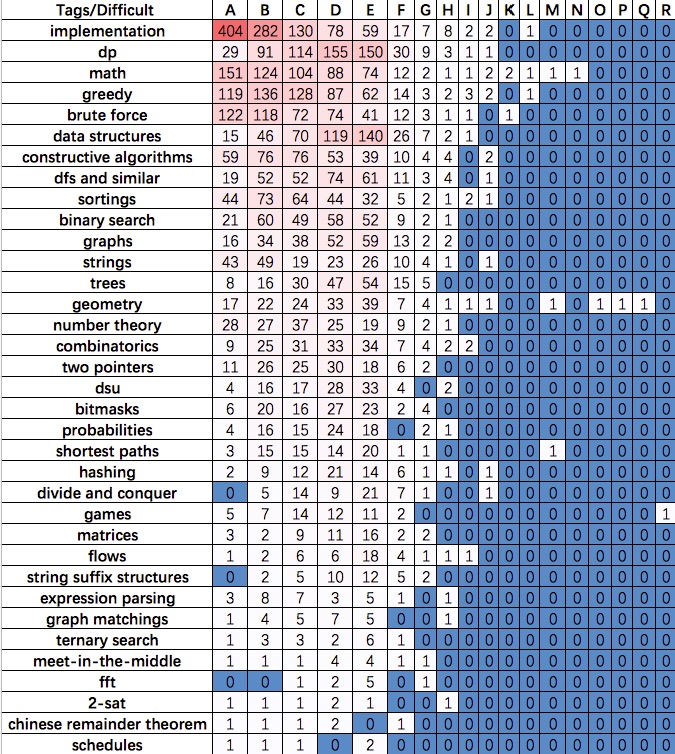
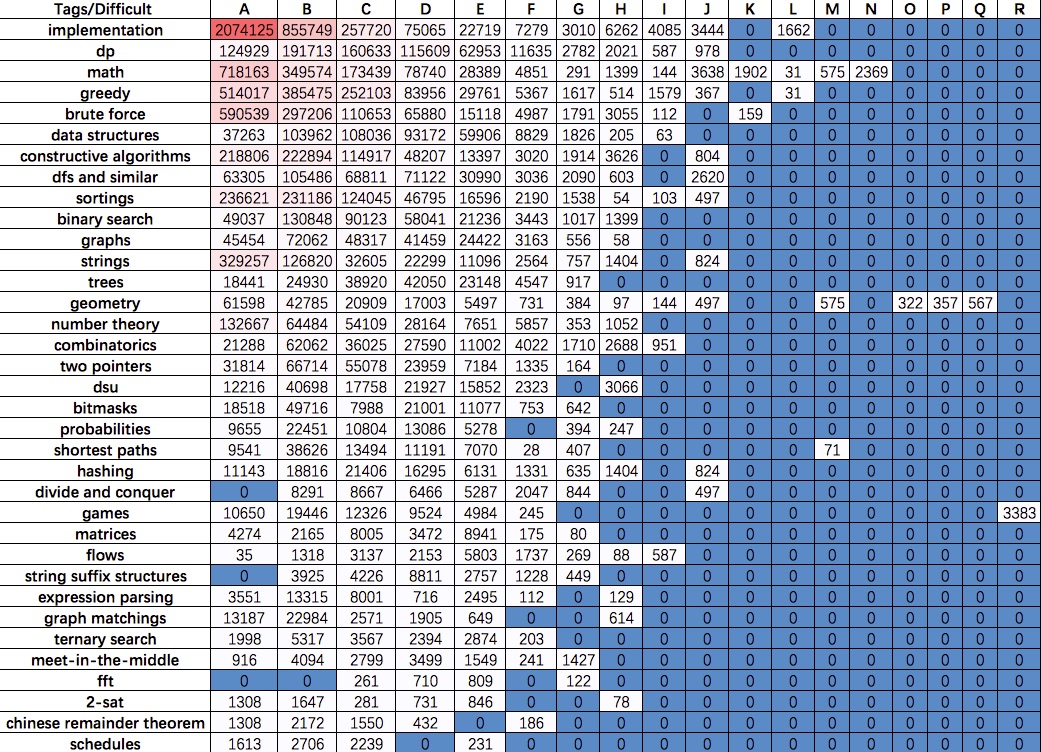 Codeforces_Algorithms_Tag_Solved.jpg
Codeforces_Algorithms_Tag_Solved.jpg
 tourist.jpg
tourist.jpg


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









