



 本文介绍了阿里云前端智能化项目Dumbo如何利用目标检测算法进行前端图片上的坐标连线,通过SSD300算法进行组件识别。Dumbo通过动态样本生成、模型预测等步骤实现自动化,并探讨了未来规划,包括增强模型算法能力和组件探索。
本文介绍了阿里云前端智能化项目Dumbo如何利用目标检测算法进行前端图片上的坐标连线,通过SSD300算法进行组件识别。Dumbo通过动态样本生成、模型预测等步骤实现自动化,并探讨了未来规划,包括增强模型算法能力和组件探索。
前言
《我在阿里云做前端智能化》系列文章来了,本期智能识别篇。今日前端早读课文章由阿里云@行仁投稿分享。
正文从这开始~~
在开始介绍之前,我想和大家一起探讨一个问题:为什么同样是编写代码,智能化开发在前端领域有许多发声,而在后端开发中却鲜有听闻呢?我个人是这样认为的:现阶段的机器学习工程包括深度学习,其本质是一种统计工具,并非真正的人工智能,编程需要的创造性思维是其不具备的。而在前端开发中,我们的输入往往从一张设计稿开始,如果设计稿中包含的前端组件种类和样式是基本可枚举的,那么就可以利用机器学习的方法做识别和分类,再通过后处理完成代码搭建。中后台的场景开发正好符合这种特征。
自动化的前提是标准化,在阿里云控制台的前端开发中,我们逐渐形成了visage开发标准 + xconsole视觉标准的双重规范。可以看到集团内部有许多优秀的搭建系统,这是一种自动化的实现方式。而我们选择的是智能化,智能化存在许多优势,比如我们可以灵活的选择设计稿的任意部分进行截图识别,输出模块化的代码;也可以进行智能纠错,产品画的不那么标准的交互稿也可以直接转换成符合视觉规范的前端代码。当然,有优势就有挑战,以下,我将介绍在dumbo中是如何实践的。

目标检测
目标检测算法,即输入一张图片,输出图片中感兴趣物体的坐标信息的一种算法。如下图所示。

常见的目标检测算法有两种,one-stage与two-stage。one-stage算法即只对图片处理一次,它的速度通常优于two-stage算法,代表算法有yolo系列。而two-stage算法会对图片处理两次,先找到可能存在目标的区域,再对该区域做一次预测。这类算法速度较慢但准确率更好,代表算法有Faster R-CNN。
dumbo使用了阿里云智能视觉(Ivision)作为其底层算法能力平台。其内置的目标检测算法是SSD300。SSD300是2016年提出的一种目标检测算法,它是一种one-stage算法,同时吸收了yolo和Faster R-CNN的优点,兼具速度和准确率。虽然在最新的目标检测算法排名中,SSD已不再具有优势,但我认为,在前端场景的目标检测中,组件并没有复杂的特征形态,算法不是最重要的因素,样本集和超参数的设置往往比算法本身更重要。以下是SSD300与yolo的模型对比图。
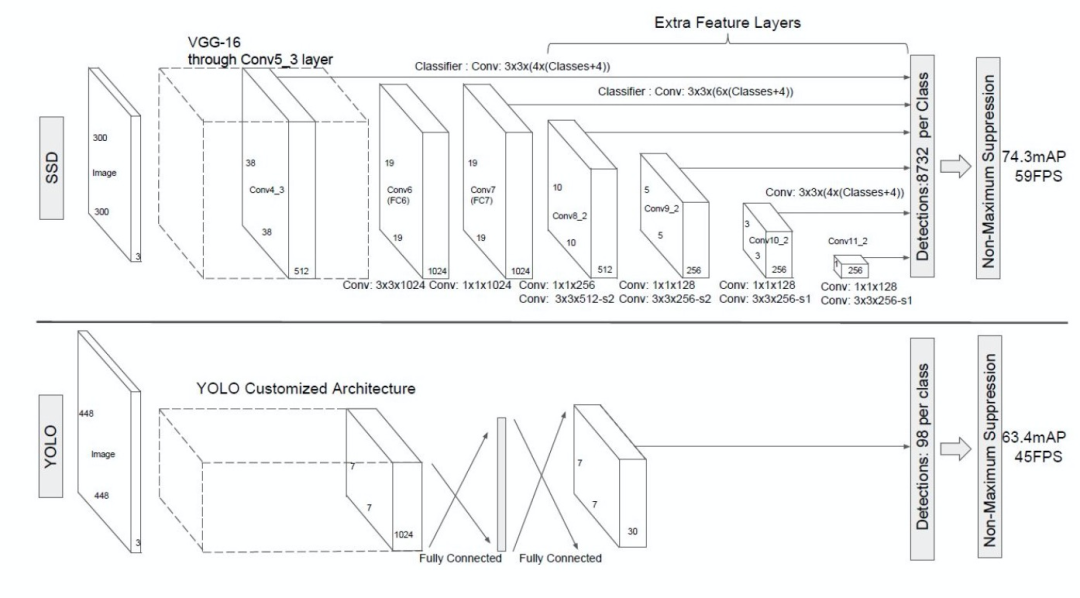
可以看到,SSD算法在经过一次VGG-16转换后,得到一个38 * 38 * 512的特征图,之后的每一次卷积运算的同时都会输出一次预测结果,这么做可以兼顾大目标和小目标的检测,感受野小的feature map检测小目标,感受野大的feature map检测大目标。SSD同时引入了Faster RCNN中的Anchor,提出了相似的Prior box概念,在对样本做标记时,也是基于Prior box的偏移来做的。如下图所示。
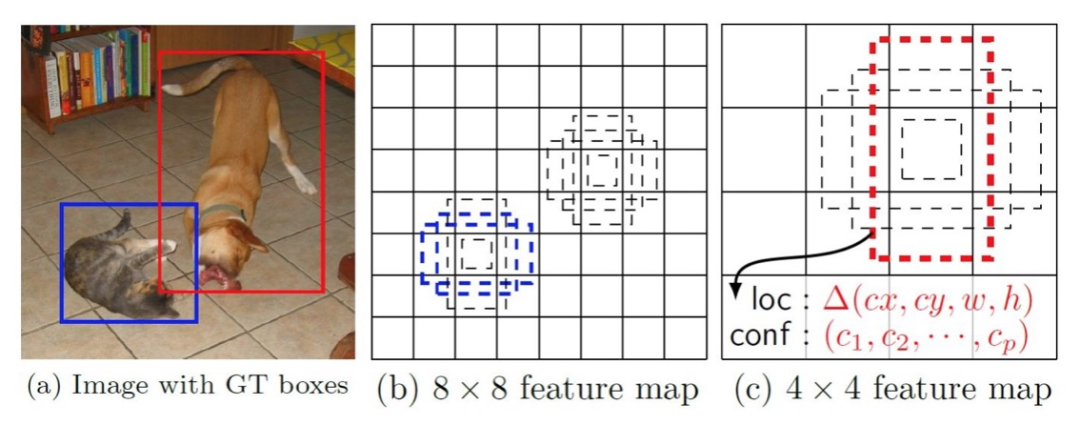
在每一个不同尺寸的feature map中,都预先设置好了多个Prior box,这些先验框可通过人为规定或统计学方法计算得到。在对目标做标记时,SSD要求找到与待检测目标真实框交并比最大的先验框,由它负责预测该目标,标记的数据为两个框之间差值。预测的时候也是同理,因此,在SSD中,会多出一步转换的过程,用来还原真实框的位置信息。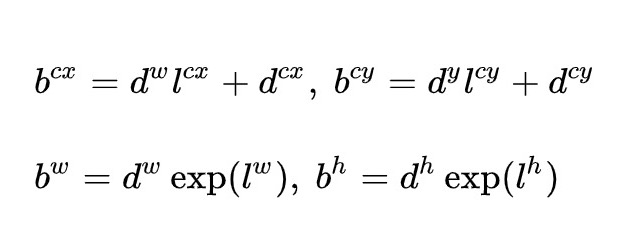
样本生成
目标检测的模型训练,样本集尤为重要。对于中后台场景而言,样本集就是各种各样的控制台页面截图。
想要识别的组件,需要在图片中标注出来,标注格式有多种,常见的格式有xml、json、csv等。在ivision中,由于已经封装成了标准open api,不用处理SSD算法的标准细节,我们直接采用json格式对组件进行标注。以Button为例,标注信息包括组件的左上角顶点坐标、组件的长度和宽度。不同的目标检测算法需要的数据可能不同,有的需要组件中心点的坐标数据,有的则需要组件占图片的比例数据。这些数据都可以通过计算相互转换,本质并没有发生变化。
将图片中所有组件都标注完成后,我们得到了一对样本图片与标注文件的集合,大量这样的集合便构成了样本集。仅使用真实控制台页面截图是远远不够的,并且手动标注费时又容易出错。因此,我们分别使用了fusion与antd构建了两套动态样本数据集。fusion风格样本主要以xconsole标准为主,用于训练阿里云控制台场景模型,antd风格样本则用于训练更加宽泛的中后台管控系统场景模型。
下图是使用fusion构建的一个随机控制台页面,目前,各类型的组件分布算法采用的是围绕xconsole视觉规范为均值的正太分布。这么做可以在少量样本条件下训练出表现更好的模型。后续我们将使用更加均匀的分布算法改造样本集,但我们认为,在前端领域的目标检测中,并不适合完全均匀分布的布局算法。举个例子,PageHeader组件,位置信息是其自身的一项特征,如果在页面底部出现了一个和PageHeader一模一样的组件,我们也不应该将其标注为PageHeader。
组件内部属性的随机化,也要遵循一些约束,比如Select组件,边框、右侧的arrow-down Icon是其主要特征,在使用代码生成时,最好不要忽略它们。而是否有圆角、边框颜色等则不是主要特征,可以尽量随机化,让训练出的模型更具鲁棒性。

一个值得思考的特征是placeholder,“请选择xxx”,这里的“请选择”实际上也是一项重要的特征,思考一下,如果一个组件,除了右侧没有arrow-down图标,其他特征和Select组件一致,那么,我们应该将其判断为Select呢还是Input呢?

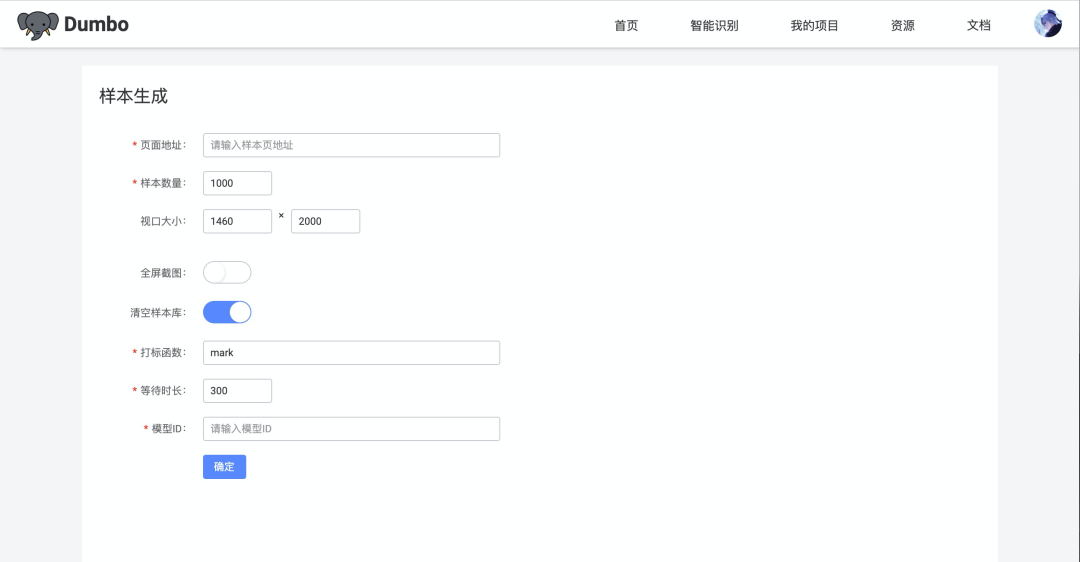
总结起来,我们训练模型的过程其实是让模型挖掘到组件的完整特征信息,并根据各项特征的重要程度做权重优化的过程。有了样本图片,还需要标注信息。在dumbo中,我们使用js方法获取了每个组件的位置和长宽数据,在通过puppeteer截图的过程中,自动导出标注文件。下图是dumbo的样本生成服务,只需要提供样本页面地址及ivision的模型id,我们就能自动生成对应的数据集并进行模型训练。
模型预测
Ivison提供了一键部署服务,可以方便的将训练好的模型部署到生产环境。在dumbo的fusion场景中,我们训练了整页模型、表单模型、图表模型、详情页模型、Icon模型等多个模型用于识别服务。识别过程同时采用了递归识别和组合识别。这是为了提高小组件的识别准确率。同时将识别任务拆分到多个模型中,可降低各个模型的训练难道。比如,当我们识别如下页面时:
会先调用整页模型识别出AppMenu、PageHeader、Nav、Form组件,如下图所示。
再针对Form组件,调用表单模型,识别出内部的组件,这是递归识别的过程。如下图所示。
对于图片中存在的Icon等小微组件,我们采用了切割识别的形式。先将图片切割成大小在300 * 300左右的小图片,分别输入到Icon模型中进行预测,将输出的结果再进行组合,转化成原始图片大小对应的数据,这是组合识别的过程。
未来规划
由于ivision未来会做一些调整,dumbo的训练任务将部署到阿里云另一个智能化平台VCS中。届时,dumbo会加入自定义模型算法能力,紧跟业内最新研究成果步伐。同时,我们也会加强与imgcook的共建,在数据集层面进行打通,实现相互赋能,以期训练出更加通用、组件覆盖率更高、识别率更准确的模型。
有的同学可能会认为这种智能化方式仅能识别和处理已有的公共组件,复杂一点的场景就无法应对了。我们同样意识到了这个问题,因此,我们会尝试使用强化学习与生成对抗网络实现组件探索,自主生成复杂的业务组件,摆脱现有的模型能力限制。在交互层面,我们也计划增加交互稿识别、多帧检测,生成自带交互的前端代码。当然,智能化不仅仅只有图像识别一个方向,我们期待探索更多的方式为前端开发赋能。

为你推荐
【第2175期】我在阿里云做前端智能化(Dumbo)- 介绍
【第2005期】闪电智能创作平台项目前端总结
欢迎自荐投稿,前端早读课等你来

















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









