



 本文详细介绍了Oracle数据快速导出工具SQLuldr2的使用方法及参数配置,并对比了SQLldr的使用技巧,包括数据导出、导入的操作步骤及注意事项。
本文详细介绍了Oracle数据快速导出工具SQLuldr2的使用方法及参数配置,并对比了SQLldr的使用技巧,包括数据导出、导入的操作步骤及注意事项。
1、 sqluldr2介绍
sqlulr2是一款Oracle数据快速导出工具,包含32、64位程序,sqluldr2在大数据量导出方面速度超快,能导出亿级数据为excel、txt、csv等文件,另外它的导入速度也非常快。
2、 sqluldr的使用
使用sqluldr2之前需要先安装,然后设置好环境变量即可开始使用,可以使用 sqluldr2 –-help 查看帮助
3、 sqluldr数据导出
3.1、常规导出
sqluldr2 user_name/password@ip:port/server_name
charset=utf8 table=table_name field=”|” query=”select * from Table_name” file=path/file_name log=log_name record=” |0x0a”
3.2、参数介绍
head={yes|no} 是否输出表头
charset=字符集 输出字文件的字符集
table=table_name 指定导入目标表的名称(即默认生成的ctl中导入表的名称,注意=右边不能有空格)
field=“” 设置导出文件的字段间的分割符
record=“” 设置导出文件数据行的结束符(
回车=0x0d,换行=0x0a,TAB键=0x09,|=0x7c,&=0x26,双引号=0x22,单引号=0x27)
query={语句|.sql} 设置导出条件,可以是语句,也可以是.sql文件 例:query=a.sql
mode={truncate|insert|append|replace} 导入默认选择(这个也是决定生成ctl文件中导入的模式)
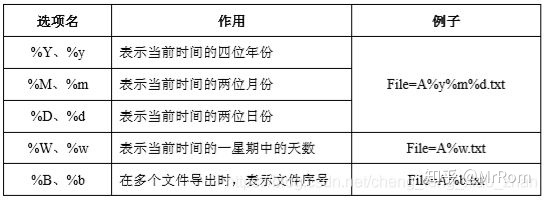
bacth={yes|no} 是否把大表输出到多个文件中,可以按行数rows= ,或者size= (MB)来分割文件,多个文件名可按照下表来生成:
sqluldr2和sqlldr笔记
1、 sqluldr2介绍
sqlulr2是一款Oracle数据快速导出工具,包含32、64位程序,sqluldr2在大数据量导出方面速度超快,能导出亿级数据为excel、txt、csv等文件,另外它的导入速度也非常快。
2、 sqluldr的使用
使用sqluldr2之前需要先安装,然后设置好环境变量即可开始使用,可以使用 sqluldr2 –-help 查看帮助
3、 sqluldr数据导出
3.1、常规导出
sqluldr2 user_name/password@ip:port/server_name
charset=utf8 table=table_name field=”|” query=”select * from Table_name” file=path/file_name log=log_name record=” |0x0a”
3.2、参数介绍
head={yes|no} 是否输出表头
charset=字符集 输出字文件的字符集
table=table_name 指定导入目标表的名称(即默认生成的ctl中导入表的名称,注意=右边不能有空格)
field=“” 设置导出文件的字段间的分割符
record=“” 设置导出文件数据行的结束符(
回车=0x0d,换行=0x0a,TAB键=0x09,|=0x7c,&=0x26,双引号=0x22,单引号=0x27)
query={语句|.sql} 设置导出条件,可以是语句,也可以是.sql文件 例:query=a.sql
mode={truncate|insert|append|replace} 导入默认选择(这个也是决定生成ctl文件中导入的模式)
bacth={yes|no} 是否把大表输出到多个文件中,可以按行数rows= ,或者size= (MB)来分割文件,多个文件名可按照下表来生成:
sqluldr2和sqlldr笔记
1、 sqluldr2介绍
sqlulr2是一款Oracle数据快速导出工具,包含32、64位程序,sqluldr2在大数据量导出方面速度超快,能导出亿级数据为excel、txt、csv等文件,另外它的导入速度也非常快。
2、 sqluldr的使用
使用sqluldr2之前需要先安装,然后设置好环境变量即可开始使用,可以使用 sqluldr2 –-help 查看帮助
3、 sqluldr数据导出
3.1、常规导出
sqluldr2 user_name/password@ip:port/server_name
charset=utf8 table=table_name field=”|” query=”select * from Table_name” file=path/file_name log=log_name record=” |0x0a”
3.2、参数介绍
head={yes|no} 是否输出表头
charset=字符集 输出字文件的字符集
table=table_name 指定导入目标表的名称(即默认生成的ctl中导入表的名称,注意=右边不能有空格)
field=“” 设置导出文件的字段间的分割符
record=“” 设置导出文件数据行的结束符(
回车=0x0d,换行=0x0a,TAB键=0x09,|=0x7c,&=0x26,双引号=0x22,单引号=0x27)
query={语句|.sql} 设置导出条件,可以是语句,也可以是.sql文件 例:query=a.sql
mode={truncate|insert|append|replace} 导入默认选择(这个也是决定生成ctl文件中导入的模式)
bacth={yes|no} 是否把大表输出到多个文件中,可以按行数rows= ,或者size= (MB)来分割文件,多个文件名可按照下表来生成:
file=file_name 设置导出文件名(当文件名以.gz结尾时,会直接将记录以GZIP的格式压缩,适用于进行归档)
text=(mysql、csv、oraclelines等) 导出类型
parameter=参数文件 从文件中读取命令选项
trace= 设置10046时间追踪
log=logfile 设置日志文件可以使用前缀加+模式,输入到同一个日志文件
ctl=ctl_name 设置控制文件名
4、 sqlldr使用
4.1、常规导入
sqlldr useid/password control=ctl_file log=log_file date=date_file ERRORS=0 ROWS=50000 readsize=214747364 bindsize=214747364
4.2参数介绍
errors 允许的错误记录数,超过则终止任务(默认50)
rows 设置加载多少条commit一次,该参数受bindsize参数限制,如果每行实际占用大小超出bindsize最大可用值,则rows自动降低达到bindsize
readsize 缓冲区大小,默认值:1048576,单位字节,最大不超过20M,该参数仅当从数据文件读取时有效
bindsize 为绑定数组指定的最大可用空间,用来存贮一次读取的rows的记录,该值不能太小,至少要存放一条逻辑记录,但设置太大也没什么作用,每次提交记录缓冲区的大小,默认值256000
log 日志
control 控制文件(包含表结构以及一些导入参数,导出是默认生成)
data 数据文件
parallel={true|false} 设置并发,默认false
5、 sqluldr2和sqlldr使用注意事项
5.1、sqluldr2使用
5.1.1、sqluldr2在使用时要实现确定到field参数的值,防止在导入过程中因为字段内容中有所使用的分割符导致导入出错 例:导出内容中有“#” 在field参数则不能使用“#”来作为分割符
5.1.2、sqluldr2在使用时最好确定导入的模式(insert、append等)来减少后面修改ctl文件的麻烦
5.1.3、sqluldr2导出是会自动生成一个.ctl文件,如果不是使用ctl参数则文件名默认为default.ctl
5.2、sqlldr使用
5.2.1、sqlldr在导入时会把错误数据生成一个.bad文件,可以查词问价来确定没有导入的数据
5.2.2、sqlldr导入时要确定数据文件和控制文件的读写权限,若无权限,会报sql*loader-522错误
file=file_name 设置导出文件名(当文件名以.gz结尾时,会直接将记录以GZIP的格式压缩,适用于进行归档)
text=(mysql、csv、oraclelines等) 导出类型
parameter=参数文件 从文件中读取命令选项
trace= 设置10046时间追踪
log=logfile 设置日志文件可以使用前缀加+模式,输入到同一个日志文件
ctl=ctl_name 设置控制文件名
4、 sqlldr使用
4.1、常规导入
sqlldr useid/password control=ctl_file log=log_file date=date_file ERRORS=0 ROWS=50000 readsize=214747364 bindsize=214747364
4.2参数介绍
errors 允许的错误记录数,超过则终止任务(默认50)
rows 设置加载多少条commit一次,该参数受bindsize参数限制,如果每行实际占用大小超出bindsize最大可用值,则rows自动降低达到bindsize
readsize 缓冲区大小,默认值:1048576,单位字节,最大不超过20M,该参数仅当从数据文件读取时有效
bindsize 为绑定数组指定的最大可用空间,用来存贮一次读取的rows的记录,该值不能太小,至少要存放一条逻辑记录,但设置太大也没什么作用,每次提交记录缓冲区的大小,默认值256000
log 日志
control 控制文件(包含表结构以及一些导入参数,导出是默认生成)
data 数据文件
parallel={true|false} 设置并发,默认false
5、 sqluldr2和sqlldr使用注意事项
5.1、sqluldr2使用
5.1.1、sqluldr2在使用时要实现确定到field参数的值,防止在导入过程中因为字段内容中有所使用的分割符导致导入出错 例:导出内容中有“#” 在field参数则不能使用“#”来作为分割符
5.1.2、sqluldr2在使用时最好确定导入的模式(insert、append等)来减少后面修改ctl文件的麻烦
5.1.3、sqluldr2导出是会自动生成一个.ctl文件,如果不是使用ctl参数则文件名默认为default.ctl
5.2、sqlldr使用
5.2.1、sqlldr在导入时会把错误数据生成一个.bad文件,可以查词问价来确定没有导入的数据
5.2.2、sqlldr导入时要确定数据文件和控制文件的读写权限,若无权限,会报sql*loader-522错误
file=file_name 设置导出文件名(当文件名以.gz结尾时,会直接将记录以GZIP的格式压缩,适用于进行归档)
text=(mysql、csv、oraclelines等) 导出类型
parameter=参数文件 从文件中读取命令选项
trace= 设置10046时间追踪
log=logfile 设置日志文件可以使用前缀加+模式,输入到同一个日志文件
ctl=ctl_name 设置控制文件名
4、 sqlldr使用
4.1、常规导入
sqlldr useid/password control=ctl_file log=log_file date=date_file ERRORS=0 ROWS=50000 readsize=214747364 bindsize=214747364
4.2参数介绍
errors 允许的错误记录数,超过则终止任务(默认50)
rows 设置加载多少条commit一次,该参数受bindsize参数限制,如果每行实际占用大小超出bindsize最大可用值,则rows自动降低达到bindsize
readsize 缓冲区大小,默认值:1048576,单位字节,最大不超过20M,该参数仅当从数据文件读取时有效
bindsize 为绑定数组指定的最大可用空间,用来存贮一次读取的rows的记录,该值不能太小,至少要存放一条逻辑记录,但设置太大也没什么作用,每次提交记录缓冲区的大小,默认值256000
log 日志
control 控制文件(包含表结构以及一些导入参数,导出是默认生成)
data 数据文件
parallel={true|false} 设置并发,默认false
5、 sqluldr2和sqlldr使用注意事项
5.1、sqluldr2使用
5.1.1、sqluldr2在使用时要实现确定到field参数的值,防止在导入过程中因为字段内容中有所使用的分割符导致导入出错 例:导出内容中有“#” 在field参数则不能使用“#”来作为分割符
5.1.2、sqluldr2在使用时最好确定导入的模式(insert、append等)来减少后面修改ctl文件的麻烦
5.1.3、sqluldr2导出是会自动生成一个.ctl文件,如果不是使用ctl参数则文件名默认为default.ctl
5.2、sqlldr使用
5.2.1、sqlldr在导入时会把错误数据生成一个.bad文件,可以查词问价来确定没有导入的数据
5.2.2、sqlldr导入时要确定数据文件和控制文件的读写权限,若无权限,会报sql*loader-522错误


















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









