






原标题:HTML5前端技术分享 百度图片爬取
语言:python 2.7
Library:urllib2,re
爬取流程:
1. 运用Chrome开发者东西,剖析百度图片
a) 翻开浏览器,在百度图片输入查找关键【昆虫】,如下图
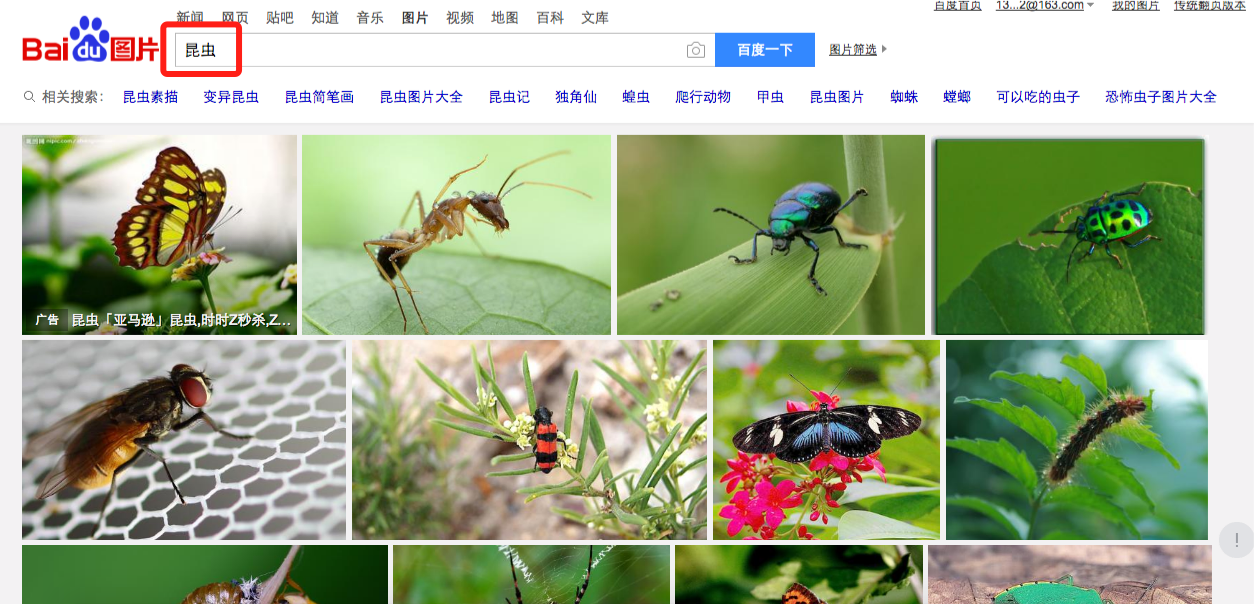
由于百度图片具有懒加载的特性,当页面向下翻滚时,会从服务器加载新的图片资源。而这一进程,通常是用ajax完成的。因此咱们估测,图片能够经过发送ajax恳求(本质上便是http恳求)来得到。
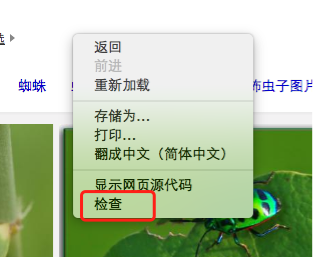
b) 在浏览器界面,鼠标右键挑选【审查】,翻开chrome开发者东西
c) 挑选【network】标签页,剖析网络恳求
d) 从头改写页面,并向下翻滚页面,触发懒加载。涉及到的网络恳求如下图所示,咱们要点重视xhr恳求,由于有很大可能,便是恳求图片信息的ajax恳求。
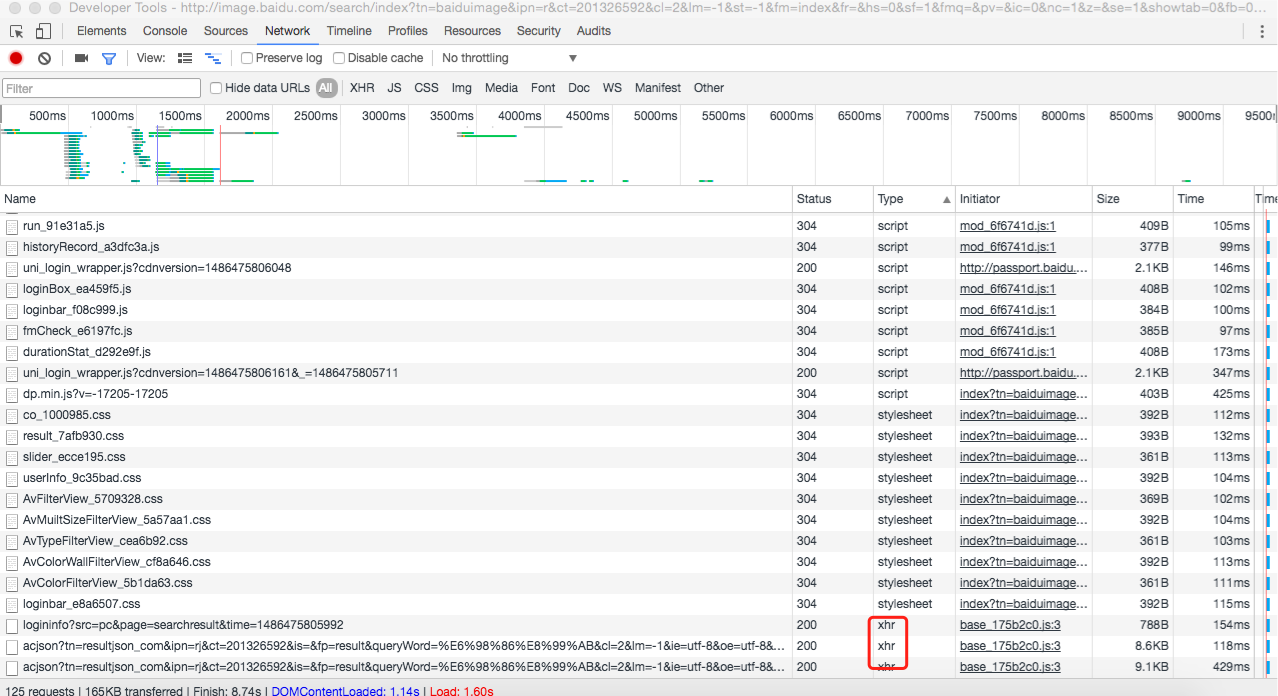
e) 咱们注意到第一个xhr恳求的地址,是logininfo,所以不太可能是恳求图片。所以咱们将焦点放到第二和第三个xhr恳求上。点击第二个xhr恳求,详细信息如下所示:

从上图信息能够发现,这个xhr恳求中有一些关于查找相关的参数,【queryWord=%E6%98%86%E8%99%AB】经过将信息进行URL解码,得出的成果为【queryWord=昆虫】,证明这个便是咱们所要的,获得图片的xhr恳求。
解码成果如图:
复制整个xhr恳求的url地址,粘贴到浏览器的地址栏中,得到了该恳求的呼应数据。数据片段如下图:

我们需要注意到,数据中有一个data数组,而且每个元素中,都有一个objURL的特点,其值为:
”ippr_z2C$qAzdH3FAzdH3Frtv_z&e3Bcbrtv_z&e3Bv54AzdH3FcbrtvAzdH3F8cAzdH3Fn9AzdH3FbcAzdH3FddbcbPICRhY_8ad9_z&e3B3r2”
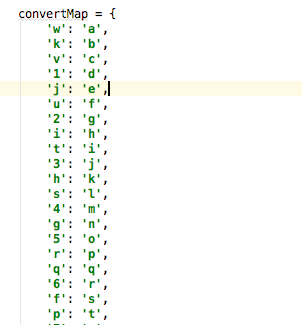
能够估测出,其值为加密后的url,详细加密后和加密前对应联系如下所示:
_z2C$q → :
AzdH3F → /
_z&e3B → .
w → a
k → b
v → c
1 → d
j → e
u → f
2 → g
i → h
t → i
3 → j
h → k
s → l
4 → m
g → n
5 → o
r → p
q → q
6 → r
f → s
p → t
7 → u
e → v
o → w
8 → 1
d → 2
n → 3
9 → 4
c → 5
m → 6
0 → 7
b → 8
l → 9
a → 0
依据对应联系,得出上面objURL所对应的图片途径为:
http://pic.58pic.com/58pic/15/34/85/22858PICRkY_1024.jpg
数据一切objURL进行解密操作,得出一切图片所对应的实在途径。
经过http恳求图片,再将返回的数据,保存到文件中,就完成了图片的爬取。
2. 代码完成:
a) 发送xhr恳求的代码片段
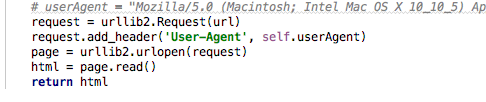
b) 经过正则表达式,在返回的字符串中,萃取出一切的objURL所对应的值
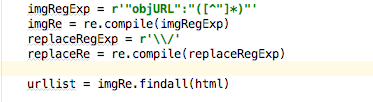
c) 将提取出的objURL,进行解密
d) 下载图片,并保存到文件中
责任编辑:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









