






<摘要>
strcat是C标准库中的字符串连接函数,它像一位熟练的装配工人,将两个字符串首尾相连组合成一个更长的字符串。这个函数定义在string.h头文件中,属于C标准库的一部分。strcat将源字符串的副本追加到目标字符串的末尾,覆盖目标字符串的终止null字符,并在新字符串的末尾添加新的null终止符。虽然简单易用,但strcat存在缓冲区溢出的安全隐患,需要谨慎使用。本文将用生动的比喻和完整的代码示例,带你深入理解这个基础但重要的字符串处理函数。
<正文>
1. 函数的基本介绍与用途
想象一下,你正在玩拼图游戏,手中已经有一块拼好的图案(第一个字符串),现在你想把另一块新的图案(第二个字符串)拼接到它的后面,让整个图案变得更长、更完整。在C语言的字符串世界里,strcat函数就是这样一位技艺精湛的"拼图大师"!
strcat函数的全称是"string concatenate"(字符串连接),它的任务就是将两个字符串连接起来,把第二个字符串(源字符串)的内容追加到第一个字符串(目标字符串)的末尾。
生动比喻:火车车厢连接员
把字符串想象成一列火车,每个字符都是一节车厢,最后一节是特殊的"终点车厢"(null终止符’\0’)。现在有两列火车,我们想要把它们连接成一列更长的火车。strcat就像一位熟练的铁路工人:
- 找到第一列火车的终点车厢
- 拆掉这个终点车厢
- 把第二列火车的所有车厢(包括它的终点车厢)接上去
- 这样我们就得到了一列更长的完整火车!
常见使用场景
- 消息构建:将固定的消息头和可变的消息内容连接起来
- 路径组合:将目录路径和文件名连接成完整路径
- 日志记录:将时间戳、日志级别和日志内容组合成完整日志条目
- 数据序列化:将多个数据字段连接成单个字符串
- 用户界面:动态生成显示消息
2. 函数的声明与来源
strcat函数定义在string.h头文件中,属于C标准库(glibc)的一部分,同时也是POSIX标准定义的函数。
#include <string.h>
char *strcat(char *dest, const char *src);
这个简洁的声明背后隐藏着重要的安全考虑!让我用mermaid图来展示它的核心工作机制:
3. 参数详解:默契配合的搭档
strcat函数有两个参数,它们必须完美配合才能完成连接任务:
参数1:dest - 目标字符串
- 类型:
char* - 含义:指向目标数组的指针,该数组包含一个C字符串,并足够大以容纳连接后的结果
- 实际意义:这就是我们要扩展的"基础字符串"
- 关键要求:必须有足够的空间容纳连接后的新字符串!
- 重要警告:如果目标数组不够大,会导致缓冲区溢出,这是很多安全漏洞的根源!
参数2:src - 源字符串
- 类型:
const char* - 含义:要追加到目标字符串的源字符串
- 实际意义:这就是我们要添加到基础字符串后面的"附加内容"
- 注意事项:源字符串必须以null结尾
4. 返回值的含义:连接完成信号
strcat的返回值提供了重要的操作反馈:
成功情况
返回指向目标字符串的指针,也就是dest的值。这样设计是为了支持链式调用。
链式调用示例
char buffer[100] = "Hello";
strcat(strcat(buffer, " "), "World!");
// 结果是 "Hello World!"
潜在问题
- 函数本身没有错误返回值
- 如果发生缓冲区溢出,行为是未定义的
- 调用者必须确保目标缓冲区足够大
让我们通过一个更详细的流程图来理解整个连接过程:
5. 实例与应用场景:让理论在画面中落地
现在,让我们通过三个精心设计的实际案例,看看strcat如何在真实世界中发挥作用!
案例1:动态消息构建器
应用场景:在用户界面或日志系统中,我们需要根据不同的情况动态构建显示消息。比如在游戏中显示玩家状态,或者在应用中生成状态报告。
问题分析:我们需要将固定的消息模板和可变的数值或状态信息组合成完整的消息。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
/**
* @brief 构建玩家状态消息
*
* 根据玩家名称、等级和生命值动态构建状态消息。
* 演示了strcat的基本用法和缓冲区管理的重要性。
*
* @in:
* - player_name: 玩家名称
* - level: 玩家等级
* - health: 玩家生命值
*
* @out:
* - 返回新分配的状态消息字符串
*
* 返回值说明:
* 成功返回消息字符串指针,失败返回NULL
*/
char* build_player_status(const char* player_name, int level, int health) {
// 计算所需缓冲区大小
size_t needed_size = strlen("玩家: ") + strlen(player_name) +
strlen(" 等级: ") + 10 + // 等级数字
strlen(" 生命值: ") + 10 + // 生命值数字
1; // null终止符
char* message = malloc(needed_size);
if (message == NULL) {
return NULL;
}
// 初始化消息缓冲区
message[0] = '\0';
// 逐步构建消息
strcat(message, "玩家: ");
strcat(message, player_name);
strcat(message, " 等级: ");
// 转换数字为字符串
char level_str[10];
sprintf(level_str, "%d", level);
strcat(message, level_str);
strcat(message, " 生命值: ");
char health_str[10];
sprintf(health_str, "%d", health);
strcat(message, health_str);
return message;
}
/**
* @brief 安全字符串连接函数
*
* 在连接时检查目标缓冲区剩余空间,防止缓冲区溢出。
* 这是strcat的安全替代版本。
*
* @in:
* - dest: 目标缓冲区
* - src: 源字符串
* - dest_size: 目标缓冲区总大小
*
* @out:
* - dest: 连接后的字符串
*
* 返回值说明:
* 成功返回1,缓冲区不足返回0
*/
int safe_strcat(char* dest, const char* src, size_t dest_size) {
size_t dest_len = strlen(dest);
size_t src_len = strlen(src);
if (dest_len + src_len + 1 > dest_size) {
return 0; // 缓冲区不足
}
strcat(dest + dest_len, src);
return 1;
}
int main() {
printf("动态消息构建演示:\n");
printf("==================\n\n");
// 测试不同的玩家状态
char* status1 = build_player_status("张三", 15, 85);
char* status2 = build_player_status("李四", 23, 42);
char* status3 = build_player_status("王五", 8, 100);
if (status1) {
printf("状态1: %s\n", status1);
free(status1);
}
if (status2) {
printf("状态2: %s\n", status2);
free(status2);
}
if (status3) {
printf("状态3: %s\n", status3);
free(status3);
}
// 演示安全连接函数
printf("\n安全连接演示:\n");
char safe_buffer[20] = "Hello";
if (safe_strcat(safe_buffer, " World", sizeof(safe_buffer))) {
printf("安全连接成功: %s\n", safe_buffer);
} else {
printf("安全连接失败:缓冲区不足\n");
}
// 演示不安全的连接(注释掉,因为这是危险操作)
/*
char unsafe_buffer[10] = "Hi";
strcat(unsafe_buffer, " everyone!"); // 缓冲区溢出!
printf("不安全连接: %s\n", unsafe_buffer);
*/
return 0;
}
编译与运行:
创建Makefile:
CC = gcc
CFLAGS = -Wall -g -O2
TARGET = message_builder
SOURCES = message_builder.c
all: $(TARGET)
$(TARGET): $(SOURCES)
$(CC) $(CFLAGS) -o $(TARGET) $(SOURCES)
clean:
rm -f $(TARGET)
run: $(TARGET)
./$(TARGET)
.PHONY: all clean run
编译方法:
make
运行程序:
./message_builder
运行结果解读:
动态消息构建演示:
==================
状态1: 玩家: 张三 等级: 15 生命值: 85
状态2: 玩家: 李四 等级: 23 生命值: 42
状态3: 玩家: 王五 等级: 8 生命值: 100
安全连接演示:
安全连接成功: Hello World
这个案例展示了strcat的基本用法,同时引入了安全连接的概念,这是实际编程中非常重要的考虑因素。
案例2:文件路径构建器
应用场景:在文件管理、资源加载等场景中,我们需要将基础路径和文件名组合成完整的文件路径。这在游戏资源加载、应用配置文件读取等场景中非常常见。
问题分析:需要正确处理路径分隔符,确保生成的路径格式正确,同时要避免缓冲区溢出。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
/**
* @brief 构建完整文件路径
*
* 将基础路径和文件名组合成完整路径,自动处理路径分隔符。
* 支持检测和添加缺失的分隔符,确保路径格式正确。
*
* @in:
* - base_path: 基础目录路径
* - filename: 文件名
*
* @out:
* - 返回新分配的完整路径字符串
*
* 返回值说明:
* 成功返回路径字符串指针,失败返回NULL
*/
char* build_file_path(const char* base_path, const char* filename) {
if (base_path == NULL || filename == NULL) {
return NULL;
}
size_t base_len = strlen(base_path);
size_t file_len = strlen(filename);
// 计算所需缓冲区大小(考虑分隔符和null终止符)
size_t total_size = base_len + file_len + 2; // +1 分隔符, +1 null
char* full_path = malloc(total_size);
if (full_path == NULL) {
return NULL;
}
// 复制基础路径
strcpy(full_path, base_path);
// 检查是否需要添加路径分隔符
if (base_len > 0 && base_path[base_len - 1] != '/' &&
base_path[base_len - 1] != '\\') {
// 添加默认的Unix风格分隔符
strcat(full_path, "/");
}
// 添加文件名
strcat(full_path, filename);
return full_path;
}
/**
* @brief 跨平台路径构建器
*
* 根据当前操作系统自动选择合适的分隔符,
* 提供更好的跨平台兼容性。
*/
char* build_platform_path(const char* base_path, const char* filename) {
char* full_path = build_file_path(base_path, filename);
if (full_path == NULL) {
return NULL;
}
// 检测并统一分隔符(简化示例)
// 在实际项目中可能需要更复杂的分隔符处理
for (char* p = full_path; *p != '\0'; p++) {
if (*p == '\\') {
*p = '/'; // 统一使用Unix风格分隔符
}
}
return full_path;
}
int main() {
printf("文件路径构建演示:\n");
printf("==================\n\n");
// 测试用例
struct TestCase {
const char* base_path;
const char* filename;
const char* description;
} test_cases[] = {
{"/home/user/documents", "report.pdf", "Unix路径,需要添加分隔符"},
{"/var/log/", "system.log", "Unix路径,已有分隔符"},
{"C:\\Users\\John", "file.txt", "Windows路径,需要添加分隔符"},
{".", "config.ini", "当前目录"},
{"", "standalone.txt", "空基础路径"}
};
for (int i = 0; i < sizeof(test_cases) / sizeof(test_cases[0]); i++) {
char* full_path = build_platform_path(
test_cases[i].base_path,
test_cases[i].filename
);
if (full_path != NULL) {
printf("测试 %d (%s):\n", i + 1, test_cases[i].description);
printf(" 基础路径: \"%s\"\n", test_cases[i].base_path);
printf(" 文件名: \"%s\"\n", test_cases[i].filename);
printf(" 完整路径: \"%s\"\n\n", full_path);
free(full_path);
}
}
return 0;
}
程序流程图:
案例3:日志系统构建器
应用场景:在应用程序中,我们需要构建格式化的日志消息,包含时间戳、日志级别、模块名称和具体的日志内容。
问题分析:需要将多个信息片段组合成统一的日志格式,同时确保性能和安全。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <time.h>
/**
* @brief 构建格式化日志条目
*
* 将时间戳、日志级别、模块名和消息内容组合成标准化的日志格式。
* 使用安全的内存管理和字符串操作,防止缓冲区溢出。
*
* @in:
* - level: 日志级别(INFO, WARN, ERROR等)
* - module: 模块名称
* - message: 日志消息内容
*
* @out:
* - 返回新分配的日志字符串
*
* 返回值说明:
* 成功返回日志字符串指针,失败返回NULL
*/
char* build_log_entry(const char* level, const char* module, const char* message) {
if (level == NULL || module == NULL || message == NULL) {
return NULL;
}
// 获取当前时间
time_t now = time(NULL);
struct tm* timeinfo = localtime(&now);
char time_buffer[20];
strftime(time_buffer, sizeof(time_buffer), "%Y-%m-%d %H:%M:%S", timeinfo);
// 计算所需总大小
size_t total_size =
strlen("[") + strlen(time_buffer) + strlen("] [") +
strlen(level) + strlen("] [") + strlen(module) +
strlen("] ") + strlen(message) + 1;
char* log_entry = malloc(total_size);
if (log_entry == NULL) {
return NULL;
}
// 使用安全的方式构建日志(避免多次strcat)
char* current = log_entry;
// 构建: [时间戳] [级别] [模块] 消息
current = stpcpy(current, "[");
current = stpcpy(current, time_buffer);
current = stpcpy(current, "] [");
current = stpcpy(current, level);
current = stpcpy(current, "] [");
current = stpcpy(current, module);
current = stpcpy(current, "] ");
current = stpcpy(current, message);
return log_entry;
}
/**
* @brief 高性能日志构建器(避免多次strcat)
*
* 使用stpcpy等函数减少字符串遍历次数,提高性能。
* 对于需要高频调用的日志函数,性能优化很重要。
*/
char* build_log_entry_optimized(const char* level, const char* module, const char* message) {
// 时间获取和验证与之前相同...
time_t now = time(NULL);
struct tm* timeinfo = localtime(&now);
char time_buffer[20];
strftime(time_buffer, sizeof(time_buffer), "%Y-%m-%d %H:%M:%S", timeinfo);
// 计算各部分长度
size_t time_len = strlen(time_buffer);
size_t level_len = strlen(level);
size_t module_len = strlen(module);
size_t message_len = strlen(message);
// 固定部分长度
size_t fixed_len = strlen("[] [] [] "); // 包括空格
size_t total_size = fixed_len + time_len + level_len + module_len + message_len + 1;
char* log_entry = malloc(total_size);
if (log_entry == NULL) {
return NULL;
}
// 手动构建,避免多次遍历
char* ptr = log_entry;
*ptr++ = '[';
memcpy(ptr, time_buffer, time_len);
ptr += time_len;
*ptr++ = ']';
*ptr++ = ' ';
*ptr++ = '[';
memcpy(ptr, level, level_len);
ptr += level_len;
*ptr++ = ']';
*ptr++ = ' ';
*ptr++ = '[';
memcpy(ptr, module, module_len);
ptr += module_len;
*ptr++ = ']';
*ptr++ = ' ';
memcpy(ptr, message, message_len);
ptr += message_len;
*ptr = '\0';
return log_entry;
}
int main() {
printf("日志系统构建演示:\n");
printf("==================\n\n");
// 模拟不同模块的日志消息
struct LogEntry {
const char* level;
const char* module;
const char* message;
} logs[] = {
{"INFO", "NETWORK", "客户端 192.168.1.100 已连接"},
{"WARN", "DATABASE", "查询执行时间超过阈值: 2.3s"},
{"ERROR", "AUTH", "用户认证失败: 无效的凭据"},
{"DEBUG", "CACHE", "缓存命中率: 85%"},
{"INFO", "STARTUP", "系统启动完成,所有服务正常运行"}
};
printf("标准日志构建:\n");
for (int i = 0; i < sizeof(logs) / sizeof(logs[0]); i++) {
char* log = build_log_entry(logs[i].level, logs[i].module, logs[i].message);
if (log != NULL) {
printf("%s\n", log);
free(log);
}
}
printf("\n优化版本日志构建:\n");
for (int i = 0; i < sizeof(logs) / sizeof(logs[0]); i++) {
char* log = build_log_entry_optimized(logs[i].level, logs[i].module, logs[i].message);
if (log != NULL) {
printf("%s\n", log);
free(log);
}
}
return 0;
}
时序图展示日志构建过程:
6. 进阶技巧与注意事项
安全问题:缓冲区溢出
strcat最著名的安全问题就是缓冲区溢出。由于它不检查目标缓冲区的大小,很容易导致严重的安全漏洞。
危险示例:
char buffer[10] = "Hello";
strcat(buffer, " World!"); // 缓冲区溢出!
安全替代方案:
- 使用
strncat:
char buffer[20] = "Hello";
strncat(buffer, " World!", sizeof(buffer) - strlen(buffer) - 1);
- 使用
snprintf:
char buffer[20] = "Hello";
snprintf(buffer + strlen(buffer), sizeof(buffer) - strlen(buffer), " World!");
- 自定义安全函数(如前文示例中的
safe_strcat)
性能优化
多次调用strcat会导致性能问题,因为每次都需要重新计算字符串长度。
低效做法:
char result[100] = "";
strcat(result, "Hello");
strcat(result, " ");
strcat(result, "World");
strcat(result, "!");
高效做法:
char result[100];
char* ptr = result;
ptr = stpcpy(ptr, "Hello");
ptr = stpcpy(ptr, " ");
ptr = stpcpy(ptr, "World");
ptr = stpcpy(ptr, "!");
或者手动记录位置:
char result[100];
size_t pos = 0;
pos += sprintf(result + pos, "Hello");
pos += sprintf(result + pos, " ");
pos += sprintf(result + pos, "World");
pos += sprintf(result + pos, "!");
与相关函数的比较
| 函数 | 功能 | 安全性 | 性能 | 适用场景 |
|---|---|---|---|---|
strcat | 字符串连接 | 不安全 | 中等 | 已知安全的缓冲区 |
strncat | 带长度限制的连接 | 较安全 | 中等 | 需要边界检查 |
snprintf | 格式化输出 | 安全 | 稍慢 | 复杂格式或需要格式化 |
stpcpy | 复制并返回结尾 | 不安全但高效 | 高 | 高性能场景 |
7. 现代替代方案
在现代C编程中,建议使用更安全的替代方案:
C11 Annex K 边界检查函数
#define __STDC_WANT_LIB_EXT1__ 1
#include <string.h>
errno_t strcat_s(char *dest, rsize_t destsz, const char *src);
自定义安全包装器
#include <stdbool.h>
bool safe_strcat(char *dest, size_t dest_size, const char *src) {
size_t dest_len = strnlen(dest, dest_size);
size_t src_len = strlen(src);
if (dest_len + src_len + 1 > dest_size) {
return false;
}
memcpy(dest + dest_len, src, src_len + 1);
return true;
}
8. 总结
通过本文的详细讲解,相信你已经对strcat函数有了全面的理解。让我们用最后一个总结图来回顾这个函数的核心特性:
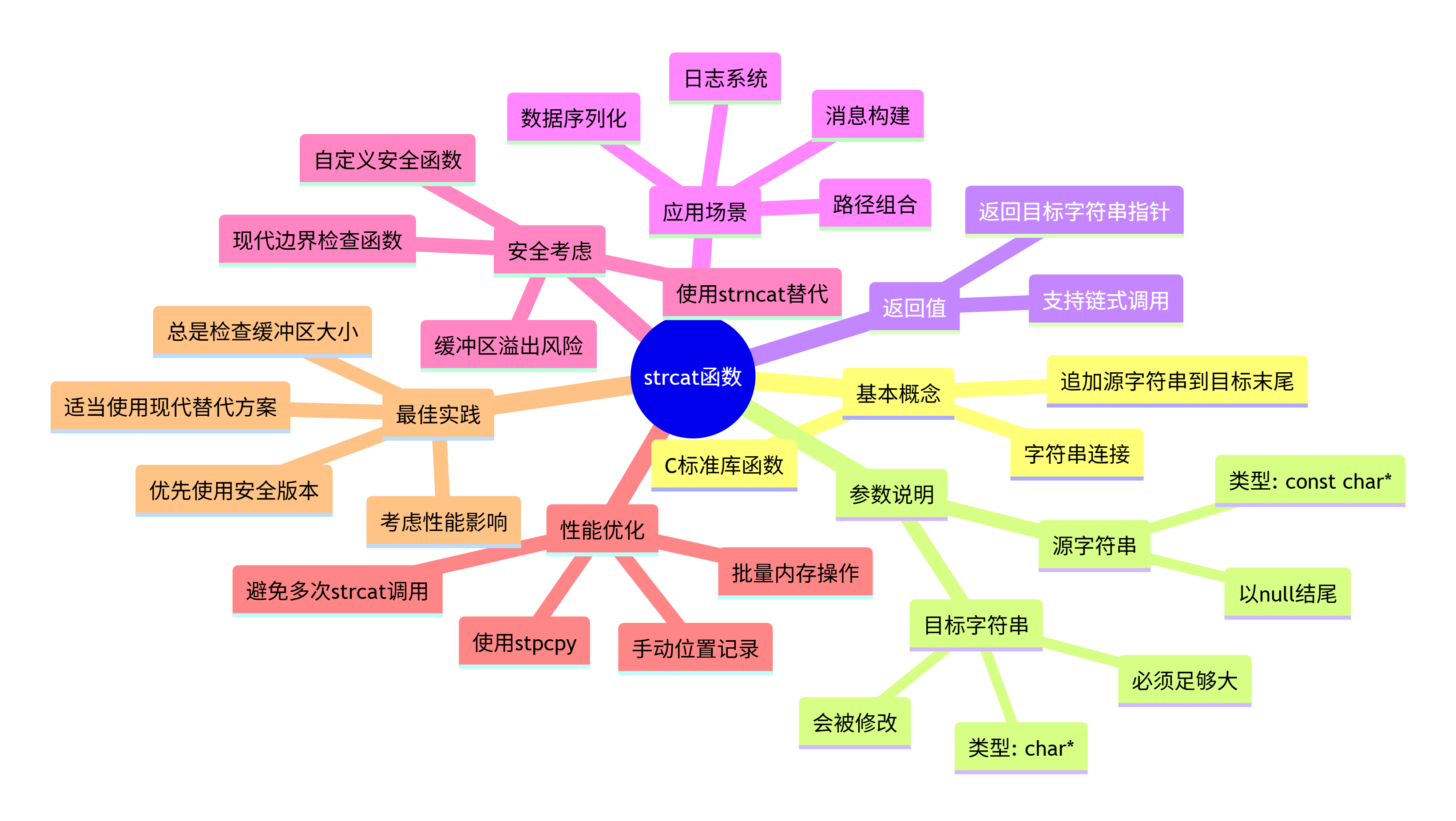
strcat是C语言字符串处理的基础函数之一,虽然简单但功能重要。然而,它的安全性问题让我们在现代编程中需要格外小心。理解它的工作原理、局限性和安全替代方案,是每个C程序员必备的技能。
记住,优秀的程序员不仅要让代码工作,更要让代码安全、健壮、高效地工作!在选择使用strcat时,请务必考虑缓冲区安全,在合适的场景中选择合适的替代方案。


















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











