




引言:从一条“拥堵的公路”说起
想象一下,你负责管理一条连接两座繁华城市的超级高速公路。你的目标很简单:让货物(数据)尽可能快地送达,但又不能发生堵车(网络拥塞)。你会怎么做?
- 野蛮生长:不管不顾,让所有货柜车一口气全部冲上高速。结果?必然在某个匝道口堵死,所有车都动弹不得,效率为零。
- 小心翼翼:一次只发一辆车,等它到了对面确认收货后,再发下一辆。绝对安全,但效率极低,大部分时间公路都是空的。
这两种策略显然都不明智。真正的智慧,在于找到那个 “恰到好处的并发量” —— 一次性能让多少辆车上路,既能保证路面的满载率,又不会引发拥堵。
TCP窗口,就是这条“数据公路”上那位看不见的、智慧无比的交通总指挥。 它动态地调整着“在途货车”的数量,这个数量,就是“窗口大小”。
第一章:基石与蓝图——TCP为何需要窗口?
在深入细节前,我们必须回到源头,理解TCP的设计哲学。
1.1 TCP的核心承诺:可靠、有序的字节流
TCP对应用程序的承诺是:“你给我一串字节,我保证原封不动、按顺序地送到对方手里,哪怕中间的物理网络一团糟。” 这就像你通过一个嘈杂的电话线传递一条重要口信,你需要不断确认“你听清了吗?我刚说到哪了?”
为了实现这个承诺,TCP有三块基石:
- 确认应答(ACK):接收方每收到一个数据包,都必须回一个“收到确认”(ACK)。就像快递签收。
- 超时重传:发送方发出一个包后就开始计时,如果一段时间没收到对应的ACK,就认为包丢了,重新发一次。
- 序列号:每个字节都被编号。接收方凭此重组乱序到达的数据,确保顺序正确。
1.2 停等协议的困局:那位“一次只发一辆车”的保守经理
在最简单的想象中,TCP可以这样工作:发送方发出包1 -> 等待ACK1 -> 收到ACK1 -> 发出包2 -> … 这就是“停等协议”。
它的效率有多低呢?我们来算一笔账。假设网络延迟(RTT)是100ms,发送一个包需要1ms。
timeline
title 停等协议效率低下
section 发送方时间线 (100ms RTT)
0ms : 发送数据包1
1ms : 等待... (99ms 空闲!)
100ms : 收到ACK1
101ms : 发送数据包2
... : ... (如此循环)
在100ms里,只有1ms在干活,效率约为1%!这简直是灾难。为了解决这个问题,天才的工程师们想出了 “流水线” 技术,而TCP窗口,就是实现流水线的核心机制。
第二章:透视TCP窗口——三位一体的交通指挥体系
很多人以为TCP窗口只有一个,其实不然。它是由三个相互关联、各司其职的“指挥官”共同构成的复杂系统。让我们用一张图来总览它们的关系:
如图所示,发送方能发出的数据量,被两个“上司”同时管着:接收方(rwnd)和网络(cwnd)。真正的发送窗口大小,是这两者中的较小值:swnd = min(cwnd, rwnd)。
接下来,我们逐一拜访这三位指挥官。
2.1 接收窗口(RWND)——接收方的“胃口”
接收窗口是接收方主动告诉发送方的:“我这边还能吃下多少数据”。它反映了接收方应用层的处理能力和TCP缓冲区的剩余空间。
- 工作原理:在每个ACK包中,都有一个“窗口大小”字段,它就是当前的
rwnd。发送方必须遵守这个限制,绝不能发送超过“已确认序列号 +rwnd”的数据。 - 零窗口困境:如果接收方缓冲区满了,它会发送一个
rwnd = 0的ACK。这会暂停发送方的数据传输。这就像接收方说:“我吃撑了,歇会儿!”- 零窗口探查:发送方不会永远等待。它会定时发送一个小包(探查报文)去询问:“嘿,胃口好点了吗?”一旦接收方缓冲区有空位,就会回复一个非零的
rwnd,数据传输恢复。
- 零窗口探查:发送方不会永远等待。它会定时发送一个小包(探查报文)去询问:“嘿,胃口好点了吗?”一旦接收方缓冲区有空位,就会回复一个非零的
rwnd的核心是“端到端的流量控制”,防止快的发送方淹没慢的接收方。
2.2 拥塞窗口(CWND)——发送方的“路况感应器”
拥塞窗口是发送方自己维护的一个状态变量,是它对当前网络拥堵程度的估算。这是一个虚拟的、在发送方内存中的限制,不存在于TCP报文头中。
- 为什么需要它? 即使接收方胃口很大(
rwnd很大),如果网络中间的路由器、交换机不堪重负,盲目发送大量数据只会导致更严重的拥堵和丢包。cwnd就是发送方自我约束,避免成为“网络公敌”的机制。 - 核心挑战:发送方如何知道网络到底有多“宽”?答案是——不知道。所以,TCP设计了一套极其精巧的算法来动态探测这个值,这就是TCP拥塞控制的核心,我们将在下一章详谈。
cwnd的核心是“基于网络的拥塞控制”,防止发送方把网络堵死。
2.3 发送窗口(SWND)——最终的“发车指令”
发送窗口是发送方在任意时刻,真正被允许发送的最大数据量。如上所述,swnd = min(cwnd, rwnd)。
这个简单的min()函数,是TCP设计的精髓之一。它完美地协调了接收方处理能力和网络传输能力这两个可能相互矛盾的目标。
- 当网络畅通但接收方处理慢时,
rwnd主导,保护接收方。 - 当接收方处理快但网络拥堵时,
cwnd主导,保护网络。
第三章:灵魂算法——拥塞控制的智慧(附详图解析)
如果说TCP窗口是引擎,那拥塞控制算法就是它的灵魂和ECU(行车电脑)。它的目标是:在不引起网络崩溃的前提下,尽可能快地传输数据。
这个过程就像一个谨慎的司机在陌生道路上探索最高安全车速:先慢慢给油(慢启动),感觉稳定了就匀速加油(拥塞避免),一有颠簸就立刻猛踩刹车(快速重传/恢复)。
3.1 经典TCP Tahoe/Reno算法四部曲
让我们通过一个完整的连接生命周期,来看看cwnd是如何演变的:
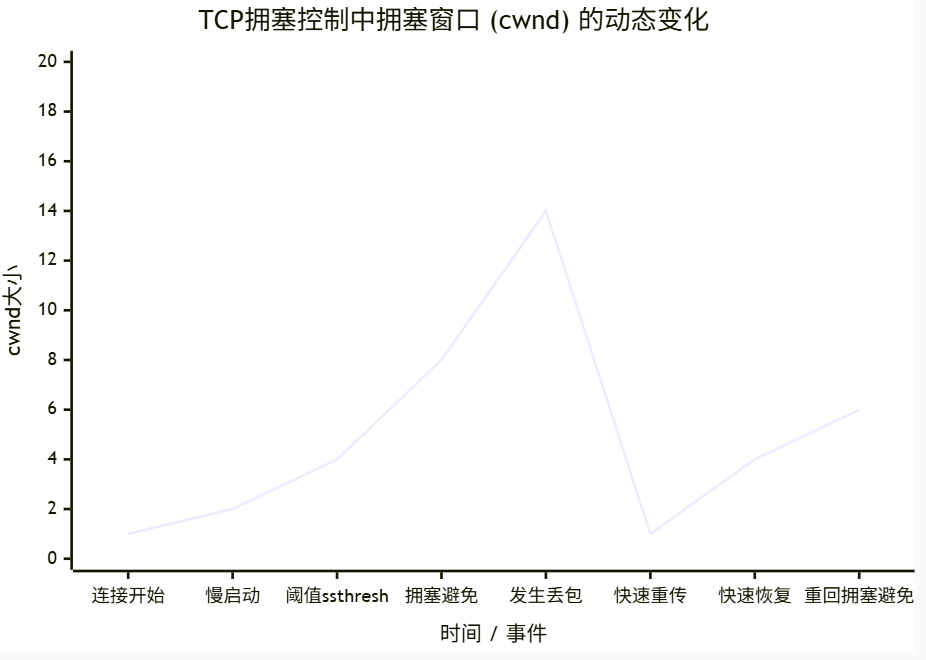
阶段一:慢启动——指数增长的狂飙
- 起点:连接刚建立时,
cwnd被初始化为一个很小的值(如1-2个MSS)。 - 规则:每收到一个新的ACK,
cwnd就增加一个MSS。这意味着每个RTT,cwnd会翻倍! - 目的:快速探测网络的可用带宽。就像赛车起步时,转速拉满,快速升档。
- 终点:慢启动不会永远持续。它会在两种情况下结束:
- 当
cwnd增长到**慢启动阈值(ssthresh)**时。 - 当检测到丢包时(图中转折点)。
- 当
阶段二:拥塞避免——线性增长的谨慎
- 规则:进入此阶段后,发送方变得保守。改为每收到一个ACK,
cwnd增加 1/cwnd。这样,每个RTT,cwnd大约只增加1个MSS。 - 目的:以平稳、线性的方式缓慢增加
cwnd,小心翼翼地逼近网络的极限容量,但尽量避免跨过它。
阶段三:快速重传与快速恢复——面对丢包的优雅降速
这是最精妙的部分!传统的超时重传(Timeout)太慢了,TCP设计了一种更智能的机制。
- 触发条件:发送方连续收到3个重复的ACK。
- 这意味什么? 网络确实发生了丢包,但后续的数据包还能到达接收方。说明网络不是完全瘫痪,只是出现了局部拥堵。
- 快速重传:发送方不等超时,立刻重传那个被认为丢失的数据包。
- 快速恢复:
- 大幅降速:将
ssthresh设置为当前cwnd的一半(ssthresh = cwnd / 2)。这是新的“安全车速”上限。 - 平滑过渡:不同于慢启动时的“重启”,快速恢复会将
cwnd设为新的ssthresh(有些实现会加3,因为收到了3个重复ACK)。然后重新进入拥塞避免阶段。
- 大幅降速:将
这种“快速”机制,避免了效率低下的超时等待,让连接能快速从丢包中恢复,是现代TCP高效的关键。
小知识:后来的算法如TCP Cubic(Linux默认)、BBR(Google)等,都试图更智能地探测带宽、更低延迟地应对拥塞,但慢启动、拥塞避免、快速恢复这个经典框架至今仍是基石。
第四章:理论照进现实——三个案例中的窗口博弈
理论说了一大堆,现在让我们看看它们如何在真实的网络世界中起舞。
案例一:从旧金山到上海的大文件传输(长肥管道)
- 场景:你在美国的服务器需要向上海的服务器传输一个10GB的巨型文件。两者之间RTT高达200ms。
- 挑战:要跑满10Gbps的带宽,需要多大的发送窗口?
- 计算:带宽延迟积(BDP) = 带宽 × RTT = (10 × 10^9 bits/s) × (0.2 s) = 2 × 10^9 bits = 250 MB。
- 解读:这意味着,在任何一刻,都有高达250MB的数据“在飞”。TCP的窗口大小必须至少能达到这个量级(
rwnd和cwnd都要大)。
- 现实问题:在旧系统中,TCP窗口字段只有16位,最大值是64KB。这对于长肥管道来说是致命的瓶颈。
- 解决方案:RFC 1323的窗口缩放选项。通过在握手阶段协商一个缩放因子,可以将窗口最大值提升到1GB!这是现代高速传输的必备特性。
案例二:你正在刷的短视频(流量突发与控制)
- 场景:你滑动抖音,一个短视频开始加载。
- 过程:
- 连接建立:你的手机(客户端)与服务器经过三次握手。在
SYN和ACK包中,双方就通告了自己的rwnd,并协商了窗口缩放因子。 - 慢启动:服务器开始发送视频数据。
cwnd从10个MSS开始,在第一个RTT内翻到20,第二个RTT翻到40……数据流从涓涓细流迅速变成滔滔江水,所以你感觉视频开头加载条走得飞快。 - 稳定传输:很快进入拥塞避免,以稳定速度传输。如果网络良好,视频数据会很快下载完毕。
- 空闲与重启:你看完这个视频,停顿了几秒才刷下一个。此时,连接可能进入保活状态。为了不给网络带来突然冲击,TCP会使用慢启动重启机制,将
cwnd重置为一个较小的值,重新开始慢启动过程。
- 连接建立:你的手机(客户端)与服务器经过三次握手。在
案例三:糟糕的Wi-Fi下的在线会议(丢包与恢复)
- 场景:你在家开视频会议,有人正在用微波炉,Wi-Fi干扰严重,导致随机丢包。
- 过程:
- 正常传输:服务器持续发送你的会议音频流。
- 发生丢包:一个数据包在无线链路中丢失。
- 快速重传触发:你的客户端收到了后续的数据包,发现序列号不连续,于是连续发回3个重复的ACK给服务器。
- 快速恢复生效:服务器立刻重传丢失的音频包,并将
ssthresh和cwnd减半。由于cwnd没有重置为1,数据传输只是速度放缓,而没有中断。 - 用户体验:你可能只会听到一刹那的轻微卡顿或爆音,但通话很快恢复正常。如果没有快速恢复,而是等待超时,你可能会经历长达数秒的静音,体验极差。
尾声:不只是结束——窗口的未来与启示
朋友,我们的TCP窗口深度之旅至此已接近尾声。我希望它带给你的,不仅仅是那些术语和算法,更是一种对互联网底层设计哲学的惊叹。
- 它的精髓在于“适应性”:TCP窗口不是一个固定的阀门,而是一个能与网络环境和接收端实时对话的、活生生的系统。它谦逊(慢启动)、它谨慎(拥塞避免)、它坚韧(快速恢复)。这种“基于反馈的自适应控制”思想,远远超出了网络领域,成为系统设计的典范。
- 持续的进化:经典的Reno算法只是起点。今天,我们有:
- Cubic:更平滑地处理高速网络下的拥塞控制,是Linux的默认选择。
- BBR:Google提出的革命性算法。它不再以“丢包”作为拥塞的主要信号,而是直接测量链路的最小RTT和最大带宽,从而构建一个显式的网络模型。它在高丢包、长延迟的网络中表现惊人,正代表着下一代拥塞控制的方向。
最后,让我们用一个比喻来收官:
TCP连接,就像两个聪明人之间的一场合作。接收窗口(rwnd)是其中一人不断地说‘我还能处理多少信息’;拥塞窗口(cwnd)是另一人根据环境的嘈杂程度自我调整着‘我应该说多快’;而最终的发送窗口,就是他们在那个瞬间达成的、最和谐也最高效的沟通节奏。
希望这次关于TCP窗口的解析,不仅让你透彻理解了技术本身,也让你感受到了工程设计中那种平衡与优雅之美。如果日后你再遇到网络延迟、吞吐量这些问题时,能想起今天的故事,并知道在数据的洪流之下,有一位勤勤恳恳的“交通指挥官”正在为你默默工作,那么,我这万余字的耕耘,便有了最大的价值。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











