




 本文介绍了一种新型的人脸识别算法SphereFace,通过提出angular softmax损失函数,使CNN能学习到更具区分性的角度特征。在多个数据集上的实验表明,该方法在人脸识别任务中表现出优越性。
本文介绍了一种新型的人脸识别算法SphereFace,通过提出angular softmax损失函数,使CNN能学习到更具区分性的角度特征。在多个数据集上的实验表明,该方法在人脸识别任务中表现出优越性。
SphereFace: Deep Hypersphere Embedding for Face Recognition
SphereFace: Deep Hypersphere Embedding for Face Recognition
本文讨论了open-set protocol下的深度人脸识别(FR)问题,在适当选择的度量空间下,理想人脸特征的最大类内距离比最小类间距离要小。然而,很少现有的算法可以有效地达到这个标准。为此,我们提出了angular softmax(A-Softmax)损失,使卷积神经网络(CNN)能够学习angularly discriminative features。几何上,a-Softmax损失可以看作是对超球面流形施加判别约束,它本质上与流形上所面临的先验条件相匹配。此外,角余量的大小可以通过参数m进行定量调整。我们进一步推导出具体的M来近似理想的特征准则。 在Labeled Face in the Wild(LFW)、YouTube Faces(YTF)和MegaFace Challenge的广泛分析和实验表明了A-Softmax损失在FR任务中的优越性。
- open-set:
- closed-set:
softmax loss
假设一个二分类问题,那么下面的公式1和2分别表示样本x属于类别1和类别2的概率。
(
公
式
1
)
p
1
=
e
x
p
(
W
1
T
×
x
+
b
1
)
e
x
p
(
W
1
T
×
x
+
b
1
)
+
e
x
p
(
W
2
T
×
x
+
b
2
)
(公式1) p1=\frac{exp(W_{1}^T\times\ x+b_1)}{exp(W_{1}^T\times x+b_1)+exp(W_{2}^T\times x+b_2)}
(公式1)p1=exp(W1T×x+b1)+exp(W2T×x+b2)exp(W1T× x+b1)
(
公
式
2
)
p
2
=
e
x
p
(
W
2
T
×
x
+
b
2
)
e
x
p
(
W
1
T
×
x
+
b
1
)
+
e
x
p
(
W
2
T
×
x
+
b
2
)
(公式2)p2=\frac{exp(W_{2}^T\times\ x+b_2)}{exp(W_{1}^T\times x+b_1)+exp(W_{2}^T\times x+b_2)}
(公式2)p2=exp(W1T×x+b1)+exp(W2T×x+b2)exp(W2T× x+b2)
Wi and bi are weights and bias of last fully connected layer corresponding to class i, respectively.
当p1=p2的情况,此时W1x+b1=W2x+b2。如果p1>p2,从p1和p2的公式可以看出二者的分母是一样的,分子都是以e为底的指数函数,是递增的,因此就相当于W1x+b1>W2x+b2。所以softmax的decision boundary为:
(
W
1
−
W
2
)
x
+
b
1
−
b
2
(W_1-W_2)x+b_1-b_2
(W1−W2)x+b1−b2
softmax loss的公式如下:
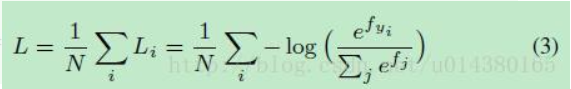
这里 f j f_j fj表示向量f的第j个元素(1<=j<=K,K就是类别数),N就是训练样本的个数。在CNN中,f通常就是全连接层W的输出,所以, f j = W j T x i + b j , f y i = W y i T x i + b y i f_j=W_{j}^Tx_i+b_j,f_{yi}=W_{yi}^Txi+b_{yi} fj=WjTxi+bj,fyi=WyiTxi+byi,这里 x i x_i xi是第i个训练样本, w j w_j wj表示w的第j列, w y i w_{yi} wyi表示w的第 y i y_i yi列。
Modified Softmax Loss
公式4是将Li展开来写,并且引入了角度参数:
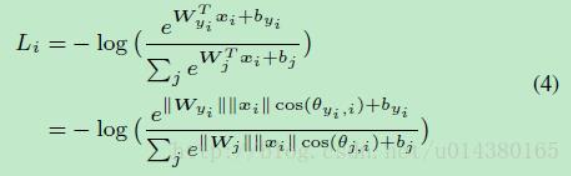
公式四上下两个等式成立的原因:
W i T x + b i = ∣ ∣ W i T ∣ ∣ ∣ ∣ x ∣ ∣ c o s ( Θ i ) + b i W_{i}^Tx+b_i=|| W_{i}^T ||||x||cos(\Theta_i)+b_i WiTx+bi=∣∣WiT∣∣∣∣x∣∣cos(Θi)+bi
如果加入条件: ∣ ∣ W 1 ∣ ∣ = ∣ ∣ W 2 ∣ ∣ = 1 , b 1 = b 2 = 0 ||W_1||=||W_2||=1,b_1=b_2=0 ∣∣W1∣∣=∣∣W2∣∣=1,b1=b2=0,则公式3就会变成:
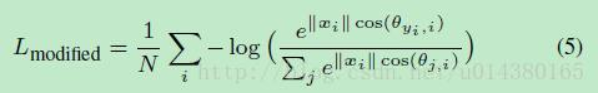
引入以上两个条件后,decision boundary就变成了 ∣ ∣ x ∣ ∣ ( c o s Θ 1 − c o s Θ 2 ) = 0 ||x||(cos\Theta_1-cos\Theta_2)=0 ∣∣x∣∣(cosΘ1−cosΘ2)=0
也就是说边界的确定变成只取决于角度了,这样就能简化很多问题。
A_Softmax Loss
但是,仅仅这样是不够的,我们希望类内更紧凑些,于是采用一个margin来对theta进行约束之前是cos(θ1)>cos(θ2),现在加一个margin m,变成cos(mθ1)>cos(θ2) ,这样就会约束θ1变得更小,也就是类内更加紧凑。
在这两个限制条件的基础上,作者又添加了和large margin softmax loss一样的角度参数,使得公式5变成如下的公式6:
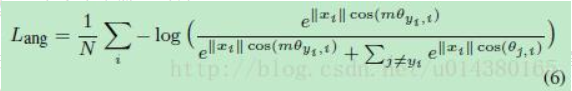
显然m值越大,优化的难度也越大,但类别之间的angular margin也越大,也就是类间距离越大,同时类内距离越小,因此模型效果越好。本文中参数m默认取4。
这里需要注意的是,如果实际优化的时候仅仅使用cos,那么需要对 Θ \Theta Θ的范围(θy的范围为[0,π/m])进行约束以保证cos单调递减,而为了摆脱这一约束实现cnn的直接优化,实际使用的是cos的近似函数:单调递减的一个函数.
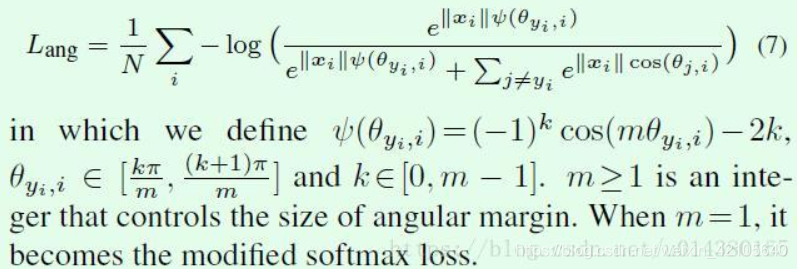
公式7也就是作者文中最终使用的loss公式。因此A-softmax loss可以看成是large margin softmax loss的改进版,也就是在large margin softmax loss的基础上添加了两个限制条件。
关于这个 ψ \psi ψ: 参考博客
在代码中引入了超参数 λ \lambda λ,
λ = m a x ( λ m i n , λ m a x 1 + 0.1 × i t e r a t o r ) \lambda=max(\lambda_{min},\frac{\lambda_{max}}{1+0.1×iterator}) λ=max(λmin,1+0.1×iteratorλmax)其中 λ m i n = 5 , λ m a x = 1500 \lambda_{min}=5,\lambda_{max}=1500 λmin=5,λmax=1500是为程序预先设定的值,所以实际上 ψ ( θ y i ) = ( − 1 ) k c o s ( m θ y i ) − 2 k + λ c o s ( θ y i ) 1 + λ = c o s ( θ y i ) − c o s ( θ y i ) 1 + λ + ψ ( θ y i ) 1 + λ \psi(\theta_{yi})=\frac{(-1)^k cos(m\theta_{yi})-2k+\lambda cos(\theta_{yi})}{1+\lambda}=cos(\theta_{yi})-\frac{cos(\theta_{yi})}{1+\lambda}+\frac{\psi(\theta_{yi})}{1+\lambda} ψ(θyi)=1+λ(−1)kcos(mθyi)−2k+λcos(θyi)=cos(θyi)−1+λcos(θyi)+1+λψ(θyi)
综上我们在代码中实现如下:

Table1是关于本文提到的3个loss的分类界限(decision boundary)对比,可以看出softmax loss的优化是对W和x的内积进行的;modified softmax loss(也就是限制Wi的模为1,bi为0)的优化是对角度θi进行的;A-softmax loss的优化也是对θi进行,而且优化目标更加难(引入m参数,优化后在类别之间会得到angular margin)
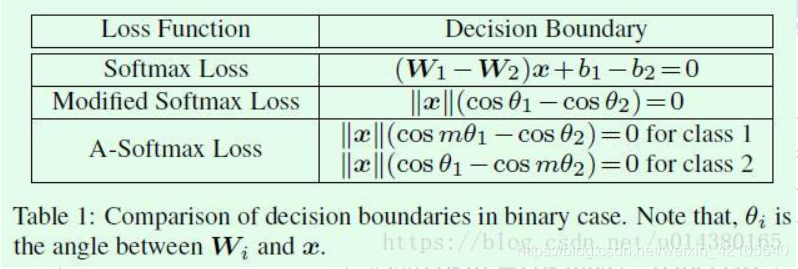
以上信息参考的博客1, 博客2
experiments
exerimental Settings
- RGB图像中的每个像素([0,255])通过减去127.5进行归一化,然后除以128。
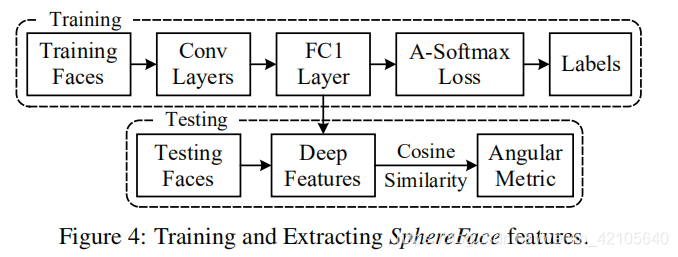
- 训练和提取SphereFace特征的一般框架如图4所示。
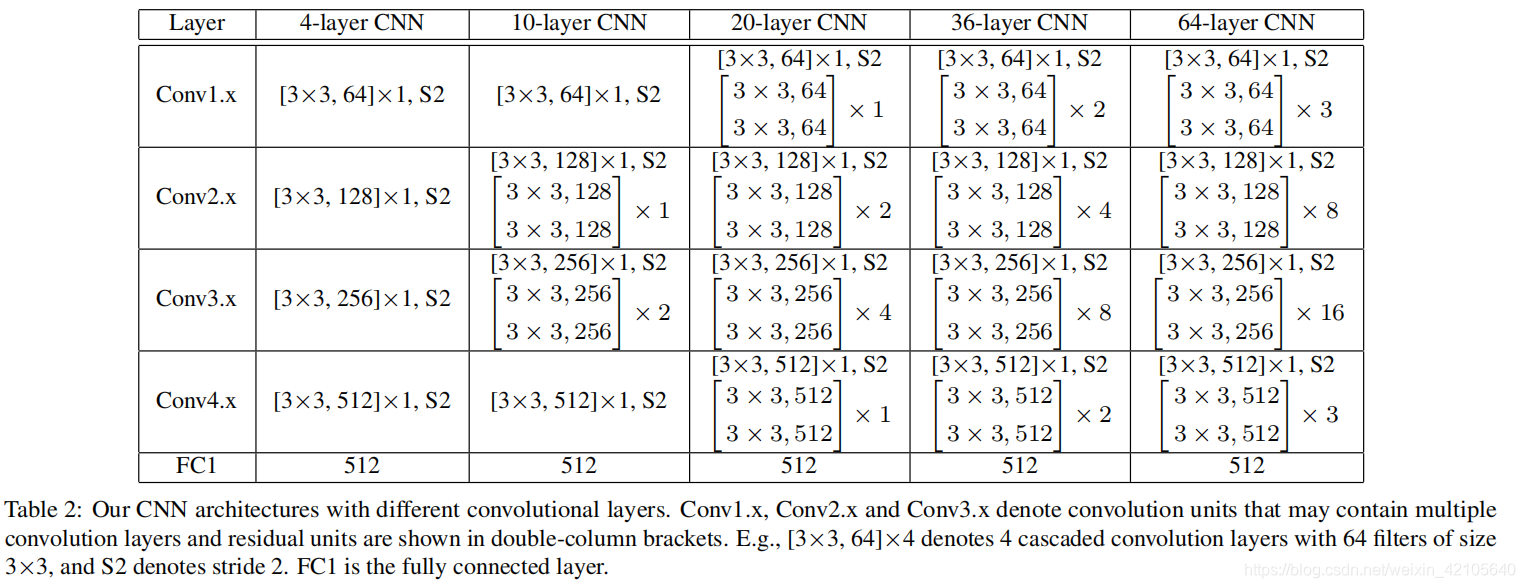
- 使用不同深度的CNN(4、10、20、36、64)可以更好地评价我们的方法。表2给出了我们使用的不同CNN的具体设置。
其中我们设置m=4;batchsize=128;learning rate从0.1开始,在迭代到16K,24K时除以10,训练在迭代到28K的时候结束。
**Training data:**我们使用公开提供的网络收集的培训数据集Casia-WebFace(排除测试集中出现的标识图像后)来训练我们的CNN模型。
- Casia-WebFace拥有来自10575个不同个体的494414张面部图像。这些面部图像被水平翻转以进行数据增强。
**Testing:**我们从FC1层的输出中提取深度特征。the final representation of a testing face是通过将original face features和其horizontally flipped features 连接(concatenate)起来得到的。分数(度量)由两个特征的余弦距离计算。(最近邻分类器和阈值分别用于人脸识别和验证。)
4.2. Exploratory(探究性) Experiments
对m值设定的研究:
- 我们在CASIA-WebFace中使用了6个样本最多的个体来训练A-Softmax loss。
- 我们将输出特征维数(Fc1)设为3。
- use 64-layer CNN
实验结果如下: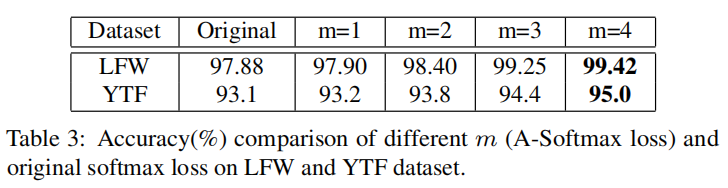
对cnn最佳层数的研究:
- m=4
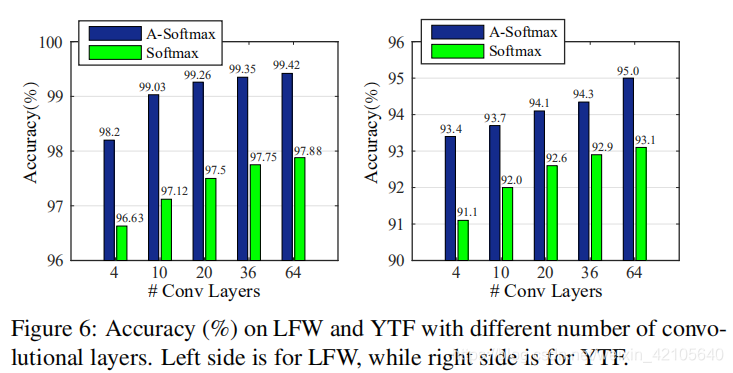
4.3 Experiments on LFW and YTF
- LFW数据集包括来自5749个不同身份的13233张人脸图像,YTF数据集包括来自1595个不同个人的3424段视频。
在LFW的6000对人脸和YTF的5000对视频中,对SphereFace的性能进行了评价。结果如下图: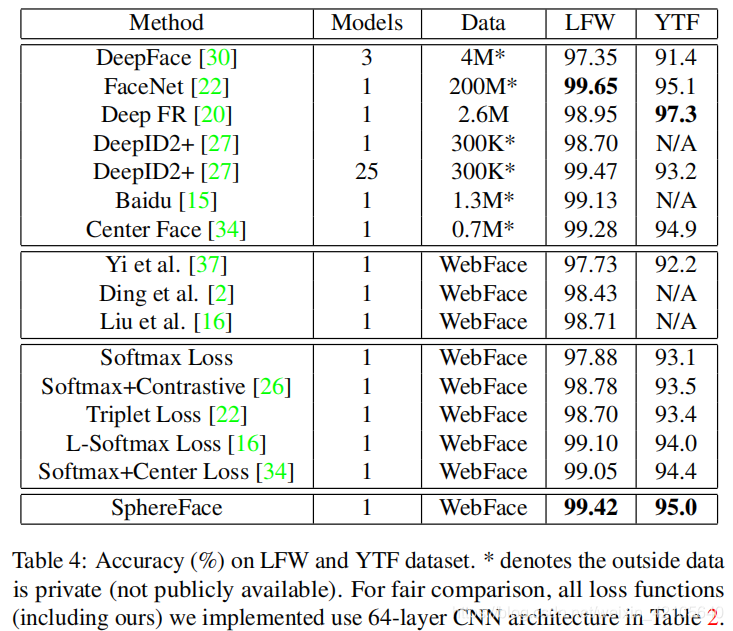
FAR
- 误识率(FAR)是指在标准指纹数据库上测试指纹识别算法时,不同指纹的匹配分数大于给定阈值,从而被认为是相同指纹的比例,简单地说就是“把不应该匹配的指纹当成匹配的指纹”的比例。
举个例子:
假定有110个人,每人的大拇指的8幅指纹图片共110*8=880幅的指纹数据库,即110类,每类8幅图片。当然,我们希望类内的任意两幅图片匹配成功,类间的任意图片匹配失败。现在我们让库中的每一幅图片除开它自身之外与其他的所有图片进行匹配,分别计算误识率,与拒识率。
误识率(FAR):假定由于指纹识别算法性能的原因,把本应该匹配失败的判为匹配成功,若假定这种错误次数为1000次。理论情况下,来自同一个指纹的图像都成功匹配,次数为78110=6160次,匹配的总次数,即880×(880-1)=773520次。匹配失败次数应为773520-6160=767360次。则误识率FAR为1000/767360*100%=0.13%。

















 2053
2053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









