




 博客介绍了正则表达式,它是处理字符串的规则,由元字符和修饰符组成。阐述了创建正则的两种方式,介绍元字符、中括号细节、分组等内容。还讲解了正则捕获,包括解决懒惰性和贪婪性的方法,以及exec、test、replace等捕获方法,最后给出时间字符串格式化和URL地址问号传参解析的应用示例。
博客介绍了正则表达式,它是处理字符串的规则,由元字符和修饰符组成。阐述了创建正则的两种方式,介绍元字符、中括号细节、分组等内容。还讲解了正则捕获,包括解决懒惰性和贪婪性的方法,以及exec、test、replace等捕获方法,最后给出时间字符串格式化和URL地址问号传参解析的应用示例。
正则:处理字符串的规则
场景:1.正则匹配;2.正则捕获
每一个正则都是由“元字符”、“修饰符”两部分组成
1.创建正则的两种方式
let reg1 = /^\d+$/g; //=>字面量
let reg2 = new RegExp("^\\d+$", "g");//=>构造函数
2.正则两个斜杠之间包起来的都是"都是元字符",斜杠后面出现的都是“修饰符”
- 元字符
具有特殊意义的元字符
\d 匹配0-9的数字,相当于[0-9]
\D 匹配除了0-9的任意字符
\w 匹配0-9、a-z、A-Z、_ 的数字或字符,相当于[0-9a-zA-Z_]
\W 匹配不是字母、数字、下划线的字符
\s 匹配任意不可见字符, 包括空格、制表符、换行符等
\S 匹配任意可见字符
\b 匹配单词的边界
\t 匹配制表符
\n 匹配换行
^ 匹配字符串的开始位置
$ 匹配字符串的结束位置
\ 转义字符
. 匹配除换行符以外的任意字符
限定元字符
- 重复1次或更多次, 相当于{1,}
? 重复0次或1次, 相当于{0,1}
- 重复任意次, 相当于{0,}
{n} 重复n次
{n,} 重复n次或者大于n次
{n,m} 重复n到m次
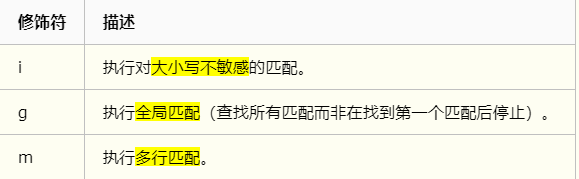
修饰符
3.中括号的一些细节
1.中括号中出现的元字符一般都是代表本身含义的
let reg = /^.$/; //=>一个正则设置了^和$,那么代表的含义其实就是只能是xxx
reg.test('n'); //true
reg.test('\n'); //false
let reg = /^[\d]+$/;
reg.test(0);
```js
let reg = /^[12-65]+$/;
reg.test(7);//false
```js
4.分组
作用:
1、改变默认的优先级
2、分组捕获
let reg = /^(\d{6})(\d{4})(\d{2})(\d{2})\d{2}(\d)(\d|X)$/
3、分组引用
let reg = /^([a-z])([a-z])\2\1$/
// \1代表第一个分组规则 \2代表第二个分组规则
常用正则表达式
- 中文汉字 [\u4E00-\u9FA5]
let reg = /^\w+([-.]\w+)*@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$/;
5.正则捕获:把一个字符串中和正则匹配读部分获取到
【正则】
exec
test
【字符串】
replace
match
//基于exec方法是实现match效果
RegExp.prototype.myExecAll = function(str){
if(!this.global) {
return this.exec(str);
}
let result = [],
valAry = this.exec(str);
while(valAry) {
result.push(valAry[0]);
valAry = this.exec(str);
}
return result;
}
小结:
- 解决懒惰性:加g
- 解决贪婪性:尾部加?
- 另外,?在正则的作用:
1.量词元字符:出现零次或者一次
/-?/让减号出现一次或者不出现
2.取消贪婪性
/\d+/捕获的时候只捕获最短匹配的内容
3.?:只匹配不捕获
4.?=正向预查
5.?!正向否定预查 - 基于test进行匹配的时候,如果设置了g,test匹配相当于捕获,修改了last-index的值
- 在正则捕获的时候,如果正则中存在分组,捕获的时候不仅仅把大正则匹配到的字符捕获到(数组第一项),而且把小分组匹配的内容也单独抽取出来。但是match不会把这个小分组单独抽取出来
-
基于exec可以实现正则读捕获:
1.如果当前正则和字符串不匹配,捕获的结果是null
2.如果匹配,捕获的结果是一个数组
0:正则捕获的内容
index:正则捕获的起始索引
input:原始操作读字符串
…
3.执行一次exec只能捕获到第一个和正则匹配读内容,其余匹配的内容还没有捕获到。而且执行多次并没有什么用=>正则的捕获具有懒惰性:只能捕获第一个匹配的内容,剩余的默认捕获不到
解决正则懒惰性,我们需要加全局修饰符(这是唯一的方案) - RegExp.$1把上一次匹配(test,exec)到的结果获取到,获取的是第一个小分组匹配的内容,大正则匹配的内容无法获取到,他是一个全局的值,浏览器$1只有一个,其他的正则会覆盖这个值
replace: 实现正则捕获的方法(本身是字符串替换)
1.reg和str匹配多少次,函数就被触发执行多少次
2.每一次正则匹配到结果,都把函数执行,然后基于exec把本次匹配的信息捕获,将捕获的信息传递给这个函数
3.返回值为替换结果
6.应用
时间字符串格式化:
let str = "2019/5/4 12:12:22",
//第一种方式
let ary = str.split(/(?:\/| |:)/g);
console.log(ary);
//第二种方式
let ary = str.match(/\d+/g).map(item => {
return item < 10 ? '0' + item : item;//map相对于foreach多了返回值,返回值即为替代值
});
//最终封装
String.prototype.myFormatTime = function myFormatTime(template='{0}年{1}月{2}日{3}时{4}分{5}秒'){
let ary = this.match(/\d+/g).map(item => (item < 10 ? '0'+item:item));
return template.replace(/\{(\d)}/g, (...[, index]) => ary[index] || '00');
}
2.url地址问号传参解析
有一个url地址 http:www.baidu.com/?name=‘11’&age=12#teacher
正则法
var str = "http:www.baidu.com/?name='11'&age=12#teacher";
function (pro) {
pro.queryURLParameter = function () {
var obj = {},
reg= /([^?=&#]+)(?:=([^?=&#]+)?)/g;
this.replace(reg, function () {
var key = arguments[1],
value = arguments[2] || null;
obj[key] = value;
})
return obj;
}
}(String.prototype)

















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









