



之前已经介绍过图片对嘴生成视频的开源工具:
DICE-Talk:https://www.cnblogs.com/cj8988/p/18957718 (带表情,比较慢)
ComfyUI_Sonic:https://www.cnblogs.com/cj8988/p/18952604 (基础版)
本章在介绍一个图片生成对嘴视频的开源框架,带表情,生成比较快的。
float : https://github.com/deepbrainai-research/float
我这里使用集合ComfyUI版本:https://github.com/yuvraj108c/ComfyUI-FLOAT
一:下载源码
地址:https://github.com/yuvraj108c/ComfyUI-FLOAT
下载到指定目录:\ComfyUI\custom_nodes\
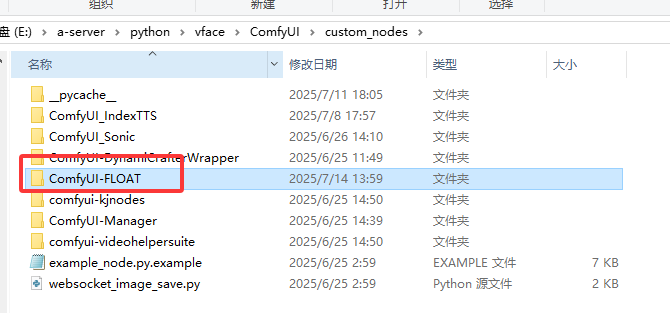
二:下载模型
地址:https://huggingface.co/yuvraj108c/float/tree/main
下载到指定目录:\ComfyUI\models\float\
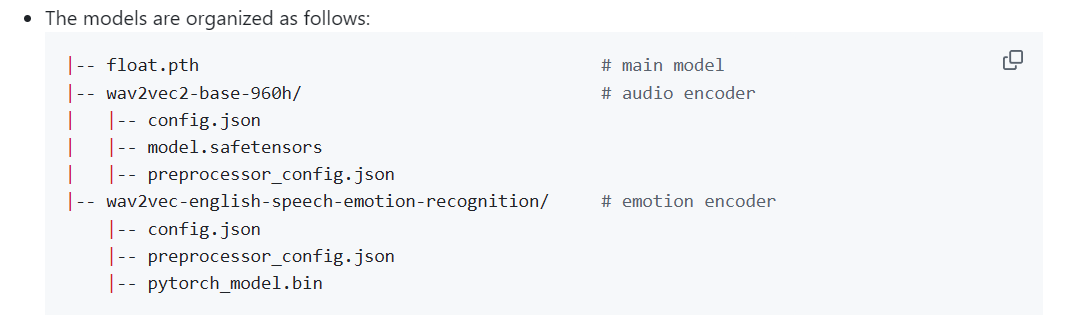
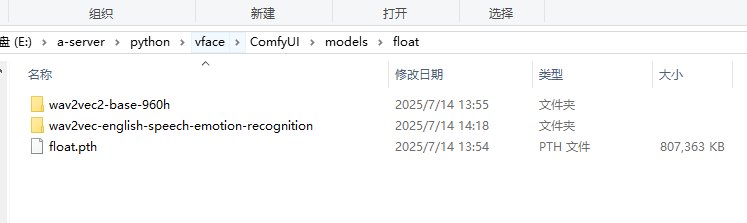
三:安装插件
cd ./ComfyUI-FLOAT
pip install -r requirements.txt
四:运行
python main.py
运行成功后,浏览器访问
http://127.0.0.1:8188/
然后将模板文件json拖拽进去:\ComfyUI\custom_nodes\ComfyUI-FLOAT\float_workflow.json
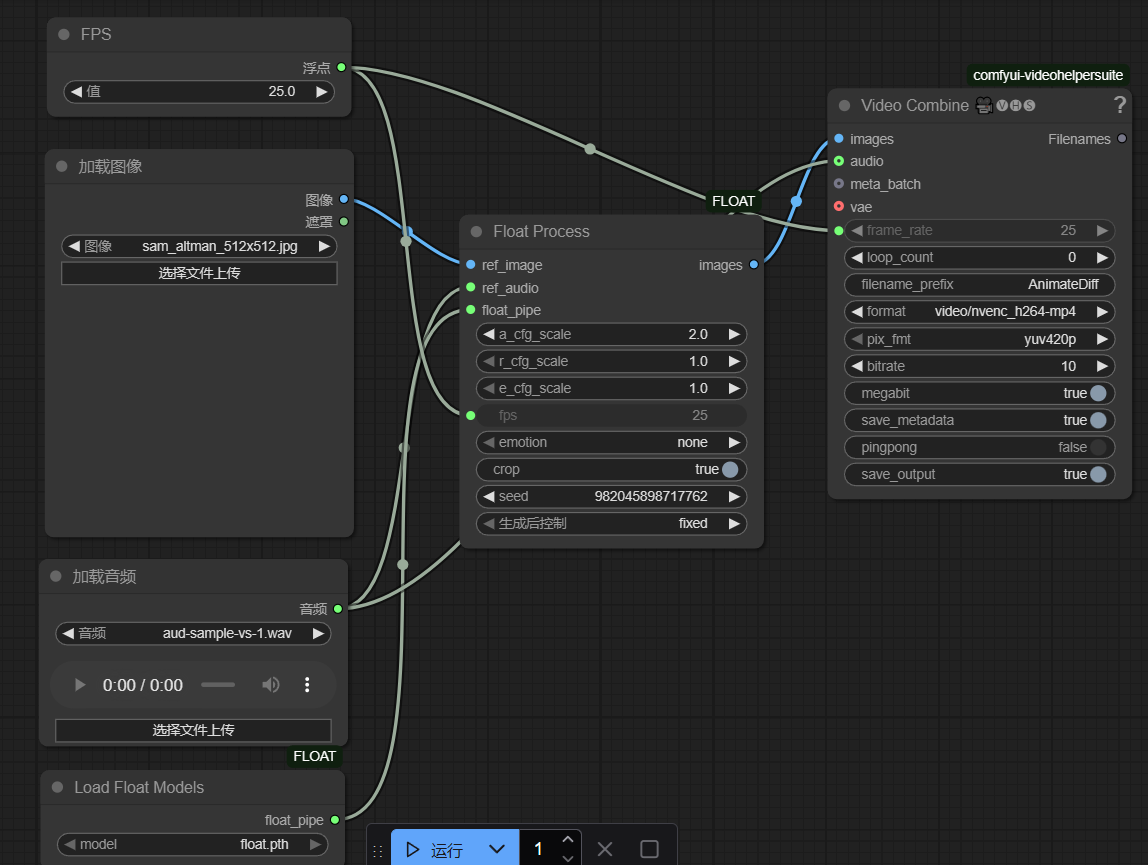
五:使用
上传一张图片,和一段音频,很快就生成了一个视频。图片必须是512*512尺寸的,其他尺寸都会被裁剪。
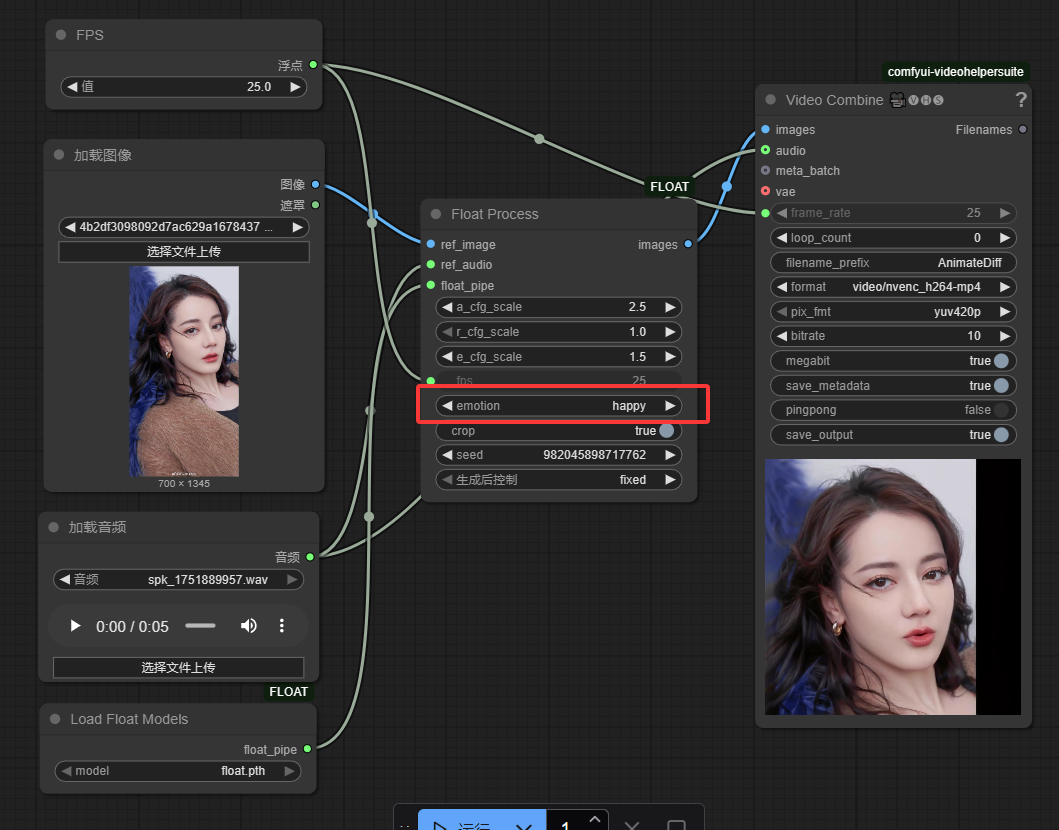
比较一下:
| 特性 | ComfyUI_Sonic (新一代) | ComfyUI-FLOAT (上一代) | 优胜者 & 原因 |
| 核心技术 | 与语言无关 (Language-Agnostic)。直接从音频波形提取特征 (HuBERT),驱动面部运动。 | 依赖于特定语言的ASR。将语音转为音素,再由音素驱动嘴唇。 | 🏆 Sonic: 先进的技术路线,使其天生支持任何语言。 |
| 中文支持 | ✅ 完美支持。无需任何修改,直接输入中文音频即可。 | ✅ 支持。其核心模块是为英语设计的,如果是中文,表情方面处理不好。 | 🏆 Sonic: 这是最关键的区别,Sonic 开箱即用。 |
| 生成速度 | 🚀 极快 (接近实时)。模型轻量、高效。 | 🐢 较慢。涉及多个串联的、较重的模型,流程更长。 | 🏆 Sonic: 效率上是碾压性的优势。 |
| 口型精度 | ✨ 非常高。能够捕捉细微的发音,口型清晰、准确。 | 😐 一般。基于音素的生成方式有时会产生“平均嘴型”,不够精细。 | 🏆 Sonic: 口型同步的质量更高。 |
| 资源占用 (VRAM) | 💧 较低。对硬件更友好。 | 🔥 较高。需要同时加载多个模型。 | 🏆 Sonic: 更适合大众用户的硬件配置。 |
| 头部姿态 | 头部基本静止。 | 头部会动,但是尺寸会裁剪为512*512。 | 🤝 平手: 两者默认都不生成头部运动。 |
| 面部表情 | 主要驱动口周区域,表情变化有限。 | ✅ 有专门的情感识别模块,可以驱动眉毛等表情。 | 🏆 FLOAT: 这是 FLOAT 理论上的唯一优势,但受限于其只支持英文。 |
| 安装与配置 | 简单,通过 ComfyUI Manager 一键安装,模型依赖清晰。 | 复杂,模型依赖多且容易出错(正如你遇到的问题)。 | 🏆 Sonic: 用户体验更好,更不容易出问题。 |
| Float | Sonic |

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









